全链路追踪:前后端、多语言、跨云部署的挑战与解决方案
发表时间: 2021-10-06 10:00

链路追踪的价值在于“关联”,终端用户、后端应用、云端组件(数据库、消息等)共同构成了链路追踪的轨迹拓扑大图。这张拓扑覆盖的范围越广,链路追踪能够发挥的价值就越大。而全链路追踪就是覆盖全部关联 IT 系统,能够完整记录用户行为在系统间调用路径与状态的最佳实践方案。
完整的全链路追踪可以为业务带来三大核心价值:端到端问题诊断,系统间依赖梳理,自定义标记透传。
全链路追踪的价值与覆盖的范围成正比,它的挑战也同样如此。为了最大程度地确保链路完整性,无论是前端应用还是云端组件,无论是 Java 语言还是 Go 语言,无论是公有云还是自建机房,都需要遵循同一套链路规范,并实现数据互联互通。多语言协议栈统一、前/后/云(多)端联动、跨云数据融合是实现全链路追踪的三大挑战,如下图所示:
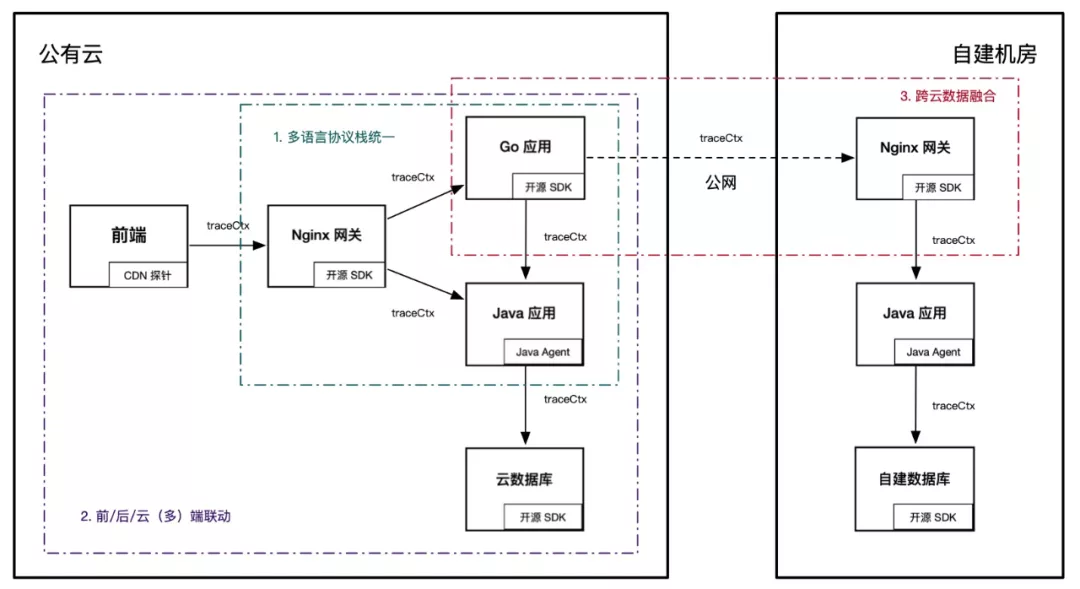
1 多语言协议栈统一
在云原生时代,多语言应用架构越来越普遍,利用不同语言特性,实现最佳的性能和研发体验成为一种趋势。但是,不同语言的成熟度差异,使得全链路追踪无法做到完全的能力一致。目前业界的主流做法是,先保证远程调用协议层格式统一,多语言应用内部自行实现调用拦截与上下文透传,这样可以确保基础的链路数据完整。
但是,绝大部分线上问题无法仅通过链路追踪的基础能力就能够有效定位并解决,线上系统的复杂性决定了一款优秀的 Trace 产品必须提供更加全面、有效的数据诊断能力,比如代码级诊断、内存分析、线程池分析、无损统计等等。充分利用不同语言提供的诊断接口,最大化的释放多语言产品能力是 Trace 能够不断向前发展的基础。
2 前后云(多)端联动
目前开源的链路追踪实现主要集中于后端业务应用层,在用户终端和云端组件(如云数据库)侧缺乏有效的埋点手段。主要原因是后两者通常由云服务商或三方厂商提供服务,依赖于厂商对于开源的兼容适配性是否友好。而业务方很难直接介入开发。
上述情况的直接影响是前端页面响应慢,很难直接定位到后端哪个应用或服务导致的,无法明确给出确定性的根因。同理,云端组件的异常也难以直接与业务应用异常划等号,特别是多个应用共享同一个数据库实例等场景下,需要更加迂回的手段进行验证,排查效率十分低下。
为了解决此类问题,首先需要云服务商更好的支持开源链路标准,添加核心方法埋点,并支持开源协议栈透传与数据回流(如阿里云 ARMS 前端监控支持 Jaeger 协议透传与方法栈追踪)。
其次,由于不同系统可能因为归属等问题,无法完成全链路协议栈统一,为了实现多端联动,需要由 Trace 系统提供异构协议栈的打通方案。
异构协议栈打通
为了实现异构协议栈(Jaeger、SkyWalking、Zipkin)的打通,Trace 系统需要支持两项能力:一是协议栈转换与动态配置,比如前端向下透传了 Jaeger 协议,新接入的下游外部系统使用的则是 ZipKin B3 协议。在两者之间的 Node.js 应用可以接收 Jaeger 协议并向下透传 ZipKin 协议,保证全链路标记透传完整性。二是服务端数据格式转换,可以将上报的不同数据格式转换成统一格式进行存储,或者在查询侧进行兼容。前者维护成本相对较小,后者兼容性成本更高,但相对更灵活。
3 跨云数据融合
很多大型企业,出于稳定性或数据安全等因素考虑,选择了多云部署,比如国内系统部署在阿里云,海外系统部署在 AWS 云,涉及企业内部敏感数据的系统部署在自建机房等。多云部署已经成为了一种典型的云上部署架构,但是不同环境的网络隔离,以及基础设施的差异性,也为运维人员带来了巨大的挑战。
由于云环境间仅能通过公网通信,为了实现多云部署架构下的链路完整性,可以采用链路数据跨云上报、跨云查询等方式。无论哪种方式,目标都是实现多云数据统一可见,通过完整链路数据快速定位或分析问题。
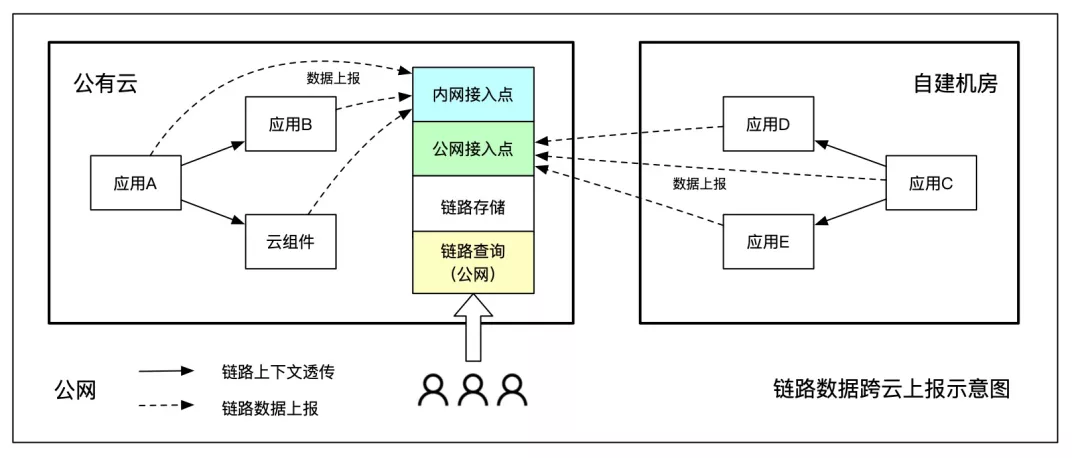
跨云上报
链路数据跨云上报的实现难度相对较低,便于维护管理,是目前云厂商采用的主流做法,比如阿里云 ARMS 就是通过跨云数据上报实现的多云数据融合。
跨云上报的优点是部署成本低,一套服务端便于维护;缺点是跨云传输会占用公网带宽,公网流量费用和稳定性是重要限制条件。跨云上报比较适合一主多从架构,绝大部分节点部署在一个云环境内,其他云/自建机房仅占少量业务流量,比如某企业 toC 业务部署在阿x云,企业内部应用部署在自建机房,就比较适合跨云上报的方式,如下图所示。
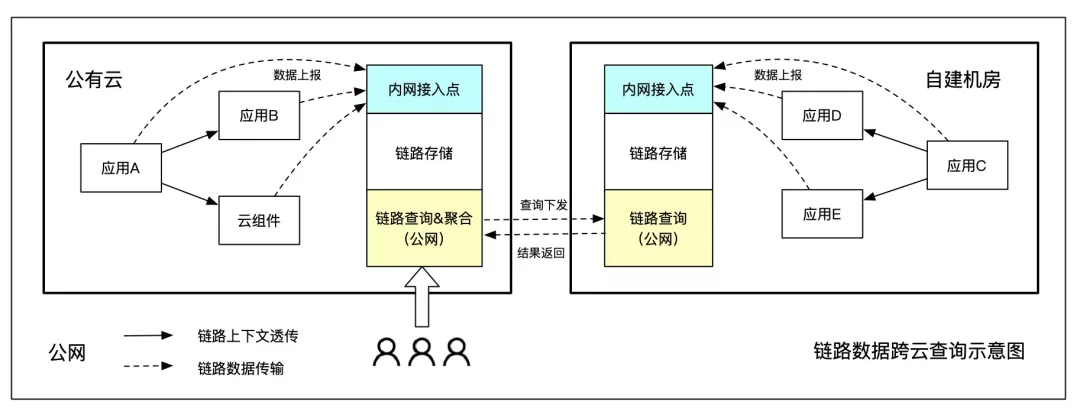
跨云查询
跨云查询是指原始链路数据保存在当前云网络内,将一次用户查询分别下发,再将查询结果聚合进行统一处理,减少公网传输成本。
跨云查询的优点就是跨网传输数据量小,特别是链路数据的实际查询量通常不到原始数据量的万分之一,可以极大地节省公网带宽。缺点是需要部署多个数据处理终端,不支持分位数、全局 TopN 等复杂计算。比较适合多主架构,简单的链路拼接、max/min/avg 统计都可以支持。
跨云查询实现有两种模式,一种是在云网络内部搭建一套集中式的数据处理终端,并通过内网专线打通用户网络,可以同时处理多个用户的数据;另一种是为每个用户单独搭建一套 VPC 内的数据处理终端。前者维护成本低,容量弹性更大;后者数据隔离性更好。
其他方式
除了上述两种方案,在实际应用中还可以采用混合模式或仅透传模式。
混合模式是指将统计数据通过公网统一上报,进行集中处理(数据量小,精度要求高),而链路数据采用跨云查询方式进行检索(数据量大,查询频率低)。
仅透传模式是指每个云环境之间仅保证链路上下文能够完整透传,链路数据的存储与查询独立实现。这种模式的好处就是实现成本极低,每朵云之间仅需要遵循同一套透传协议,具体的实现方案可以完全独立。通过同一个 TraceId 或应用名进行人工串联,比较适合存量系统的快速融合,改造成本最小。
前文详细介绍了全链路追踪在各种场景下面临的挑战与应对方案,接下来以阿里云 ARMS 为例,介绍一下如何从 0 到 1 构建一套贯穿前端、网关、服务端、容器和云组件的完整可观测系统。
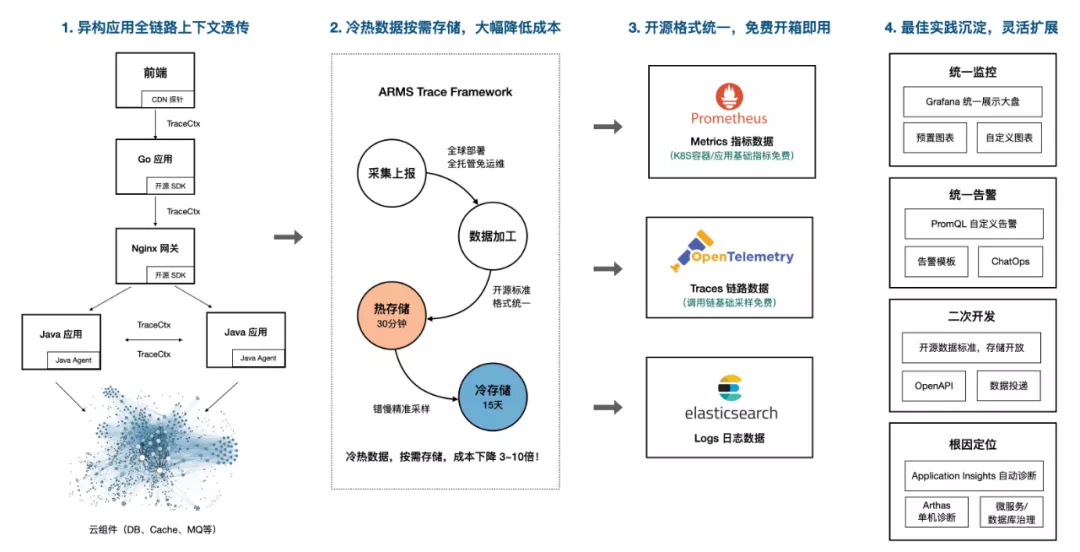
阿里云 ARMS 目前的全链路追踪方案是基于 Jaeger 协议,正在开发 SkyWalking 协议,以便支持 SkyWalking 自建用户的无损迁移。前端、Java 应用与非 Java 应用全链路追踪的调用链效果如下图所示:

1 前端接入实践
ARMS 前端监控支持 Web/H5、Weex、支付宝和微信小程序等,本文以 Web 应用通过 CDN 方式接入 ARMS 前端监控为例,简要说明接入流程,详细接入指南参考 ARMS 前端监控官网文档。

为了实现前后端链路打通,上述探针代码中必须包含以下两个参数:
另外,如果 API 与当前应用非同源,还需要添加 enableApiCors: true 这个参数,并且后端服务器也需要支持跨域请求及自定义header 值,详情参考前后端链路关联文档。如需验证前后端链路追踪配置是否生效,可以打开控制台查看对应 API 请求的 Request Headers 中是否有 uber-trace-id 这个标识。
2 Java 应用接入实践
Java 应用推荐接入 ARMS JavaAgent,无侵入式探针开箱即用,无需修改业务代码,详细接入指南参考 ARMS 应用监控官网文档。
3 非 Java 应用接入实践
非 Java 应用可以通过开源 SDK(比如 Jaeger)将数据上报至 ARMS 接入点,详细接入指南参考 ARMS 应用监控官网文档。
从 2010 年谷歌发表 Dapper 论文开始,链路追踪已经发展了十多年。但是关于链路追踪的书籍或深度文章一直都比较少,大部分博客只是简单介绍一些开源的概念或 QuickStart,一个大型企业如何建设一套真正可用、好用、易用的链路追踪系统,需要填哪些坑,避哪些雷,很难找到比较系统、全面的答案。
全链路追踪接入只是 Tracing 的起点,选择适合自身业务架构的方案,可以避免一些弯路。但链路追踪不仅仅只是看看调用链和服务监控,如何向上赋能业务,衍生至业务可观测领域辅助业务决策?如何向下与基础设施可观测联动,提前发现资源类风险?后面还有很多的工作要做,期待更多同学一起加入分享。
链接:
1、 ARMS 前端监控官网文档:
https://help.aliyun.com/document_detail/106086.html?spm=
ata.21736010.0.0.5d3a7f117o1Lty
2、 前后端链路关联文档:
https://help.aliyun.com/document_detail/91409.html#title-6rx-0lb-p1o
3、ARMS 应用监控官网文档:
https://help.aliyun.com/document_detail/97924.html
4、ARMS 应用监控官网文档:
https://help.aliyun.com/document_detail/118912.html
5、ARMS 控制台:
https://arms.console.aliyun.com/?spm=
ata.21736010.0.0.5d3a7f117o1Lty
作者 | 涯海
原文链接:
http://click.aliyun.com/m/1000298815/
本文为阿里云原创内容,未经允许不得转载。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号