源"大模型开源共训:从“为你写诗”到“与你共创奇迹”
发表时间: 2023-12-01 11:13
“大浪淘沙始见金,风云际会玉龙吟”,这两句诗恰如其分地描述了当下的大模型时代。
如今的市场号称“百模大战”亦不为过,几乎所有的大型互联网品牌、企业都有自己的大模型平台,并且按照不同行业进行了划分。在日前举行的AICC2023人工智能大会上,我们就看到了包括制造业、智能驾驶、自然语言等多种行业和场景下的大模型应用。这其中,引起不少人驻足尝试的则是浪潮信息刚刚发布的“源2.0”大模型,它也是目前业界为数不多的开源大模型之一。
许多人都听过“源1.0”的大名,我们在之前的文章中不止一次介绍过它——源1.0名为巨量中文AI模型,其参数规模为2457亿,训练采用的中文数据集达5000GB,相当于26万亿汉字,几乎囊括了当时所有的中文互联网内容。考虑到“源1.0”诞生在2021年9月,其性能甚至可以与当时的GPT3.0分庭抗礼。随着GPT4.0的春风吹过,最近“源1.0”的升级版本“源2.0”也已经发布,实现了从中文到中英双语的大幅度跨越。
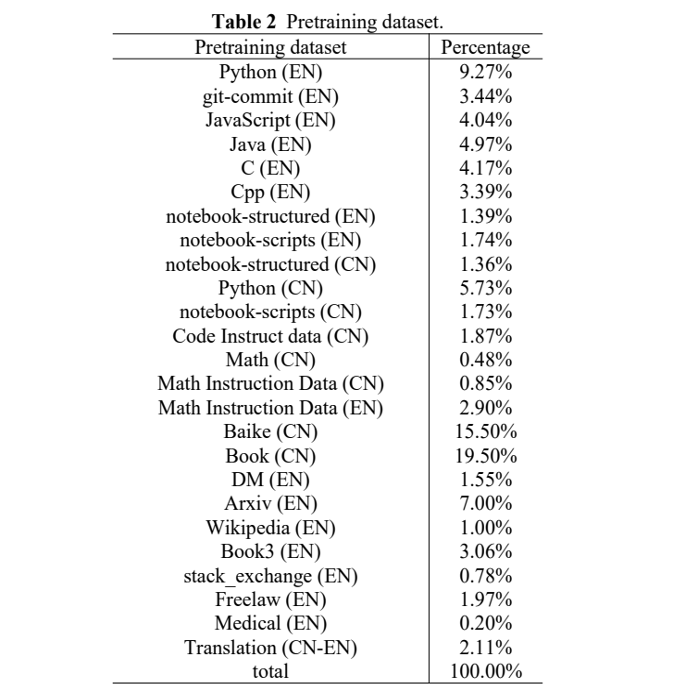
全新升级的“源2.0”包括102B(1026亿)、51B(518亿)、2B(21亿)三种参数规模的模型,在编程、推理、逻辑等方面展示出了先进的能力。“为了获取中文数学数据,源2.0清洗了从2018年至今12PB的互联网数据,但仅获取到了约10GB的数学数据”,在谈到数据获取难度的时候,浪潮信息人工智能软件研发总监吴韶华深有感触,如此巨大的投资却收效甚微。这一方面是因为中文互联网的数据资源相比英文互联网在规模上小很多,更重要的是浪潮信息对于数据质量的高要求,也侧面体现了训练数据的压缩率之高。
为解决这一问题,吴韶华在多方测算与慎重考虑之后,选择了一种可持续发展的循环方式——让大模型自己产生数据。“我们相信数据质量越好,模型训练的效果也会越好”,吴韶华解释说。因此,他将事先清洗好的数据输入大模型,通过大模型的日常计算产生数据,然后用这部分数据对模型进行再训练。通过这种循环的方式,吴韶华解决了“源2.0”大模型数据来源的困难,也通过不断的迭代与进化,让“源2.0”更加智能,更贴合应用的实际场景。
“尤其是近期有一些进展,有一些小模型在质量非常高的数据上,比如说在代码数据和数学数据上训练出来的结果,超过了比它参数量大10倍的模型。这些都是很好的例子,说明了大模型的训练不应该一味去追求数据的体量。在这个过程中,数据的质量应该是更关键的因素。”重质而不重量,这是吴韶华在访谈过程中强调的一个重要因素,这也是为什么浪潮信息将12PB的数学数据压缩到最终10GB,就是希望真正的“大浪淘沙”,筛选出有价值的、金子般的数据。
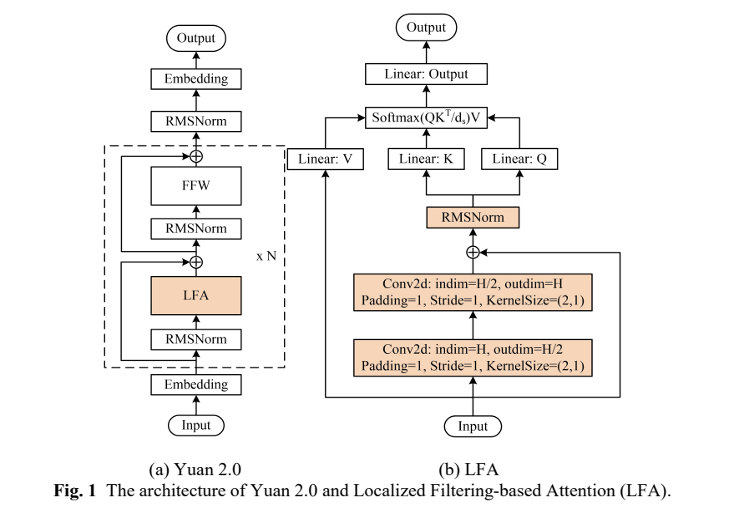
除了数据之外,“源2.0”还提出并采用了一种新型的注意力算法结构——局部注意力过滤增强机制(LFA:Localized Filtering-based Attention)。LFA通过先学习相邻词之间的关联性,然后再计算全局关联性的方法,能够更好地学习到自然语言的局部和全局的语言特征,对于自然语言的关联语义理解更准确、更人性,提升了模型的自然语言表达能力,进而提升了模型精度。
“我们认为,我们提出了这个结构,它其实是代表一个新的方向。现在我们是用一个相对来说比较小的卷积kernel来模拟局部的相关性,或者说局部的依赖性。事实上沿着这个方向走下去,它有着非常多的探索空间,我们可以用卷积来模拟,我们也可以构建另外的、更精致的结构来模拟局部的相关性。甚至我们还可以有其他的引入方式”,在谈到新架构特点的时候,吴韶华表示这是一次大胆的尝试,而事实证明这种尝试是很有必要而且非常有效的。
他还引用了“源1.0”的对比来说明新架构的优势。“源2.0最大的参数只有1026亿,但是跟2457亿的源1.0相比,它的loss值远远低于源1.0的训练loss值。这也就意味着源2.0对于我们训练数据的特征学习得更好。这样的学习能力很大程度来自我们模型结构方面的改进”,吴韶华解释说。
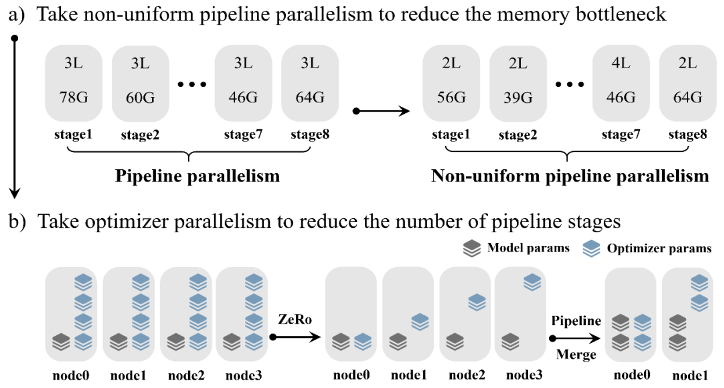
同样发生变化的还有算力调度方式。在这一方面,“源2.0”采用非均匀流水并行的方法,综合运用“流水线并行+优化器参数并行+数据并行”的策略,让模型在流水并行各阶段的显存占用量分布更均衡,避免出现显存瓶颈导致的训练效率降低的问题,该方法显著降低大模型对芯片间P2P带宽的需求,为硬件差异较大的训练环境提供了一种高性能的训练方法。
这意味着,从训练数据、算法架构与算力调度等多个方面,“源2.0”都带来了大跨步的变革,如果从AI三要素的关系看来,“源2.0”相比“源1.0”不能说是毫不相关,至少有了脱胎换骨的改变。一个最直观的感觉就是,在“源1.0”时代,我们对于其应用更多聚焦在中文层面,比如之前我们演示过许多诗歌创作,而如今的“源2.0”则可以处理更多的文字工作,不仅是作诗和写文件,包括代码生成、数学问题求解、事实问答等多维度的应用都能胜任,也就成为了具备广泛应用基础的大模型平台。
更重要的则在于开源。别看现在大模型应用众多,据不完全统计,目前共有180多个大模型面市,但这其中绝大部分大模型都是基于开放接口而并非开源平台实现的。相比之下,浪潮信息的“源2.0”最大特性就在于“掌握核心科技”,并希望通过开源的方式让更多人用上大模型平台,并完善这一平台,打造适合中国市场、中国客户的大模型应用。
“所谓开源,就是‘我为人人,人人为我’。回顾过去我们所有成功的开源项目,实际上都是整个社区的共同贡献才成就了大的项目成果。所以我们把整个代码、整个模型全开源出来,就是希望更多的ISV、开发者、用户在模型上取得良好的表现,产生出来非常棒的用户端应用体验,丰富开源社区生态,最终服务于更多的行业和应用”,在谈到开源的意义时,浪潮信息高级副总裁刘军如是说。
他同时表示,其实早在“源1.0”时代,浪潮信息就已经将其开源,如今“源1.0”已经应用在50多家大模型平台中,并通过浪潮元脑生态伙伴平台,让更多的开发者、企业参与其中,推动业务的智能化落地。不仅如此,在刘军看来,大模型可以帮助人类从更高的角度审视这个世界——“我认为同时它还起到一个帮助我们去打开思维边界的作用,毕竟人自己的所看所学所思比较有限。但是有了大模型这个强大的工具,大家能站在大模型巨人的肩膀上面去看待这个世界和科学的创新”。
此外,在AICC 2023人工智能计算大会上,浪潮信息还公布了源大模型共训计划,针对开发者自己的应用或场景需求,通过自研数据平台生成训练数据并对源大模型进行增强训练。
如果说“源1.0”时代,大模型的价值还仅限于“为你写诗、为你静止”的话,那么“源2.0”时代的大模型则可以“为你做不可能的事”。正如刘军强调的,未来的AI时代只有两种人:会用大模型的人和不会用大模型的人。而浪潮信息正在做的,就是希望让大模型深入行业、深入场景,让越来越多的人体验到它带来的高效与便捷。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12




 鲁公网安备37020202000738号
鲁公网安备37020202000738号