MySQL执行计划深度解析
发表时间: 2023-08-15 11:07
本文基于MySQL 8.0编写,理论支持MySQL 5.0及更高版本。
{EXPLAIN | DESCRIBE | DESC} tbl_name [col_name | wild]{EXPLAIN | DESCRIBE | DESC} [explain_type] {explainable_stmt | FOR CONNECTION connection_id}{EXPLAIN | DESCRIBE | DESC} ANALYZE select_statement explain_type: { FORMAT = format_name}format_name: { TRADITIONAL | JSON | TREE}explainable_stmt: { SELECT statement | TABLE statement | DELETE statement | INSERT statement | REPLACE statement | UPDATE statement}EXPLAIN format = TRADITIONAL json SELECT tt.TicketNumber, tt.TimeIn, tt.ProjectReference, tt.EstimatedShipDate, tt.ActualShipDate, tt.ClientID, tt.ServiceCodes, tt.RepetitiveID, tt.CurrentProcess, tt.CurrentDPPerson, tt.RecordVolume, tt.DPPrinted, et.COUNTRY, et_1.COUNTRY, do.CUSTNAMEFROM tt, et, et AS et_1, doWHERE tt.SubmitTime IS NULL AND tt.ActualPC = et.EMPLOYID AND tt.AssignedPC = et_1.EMPLOYID AND tt.ClientID = do.CUSTNMBR;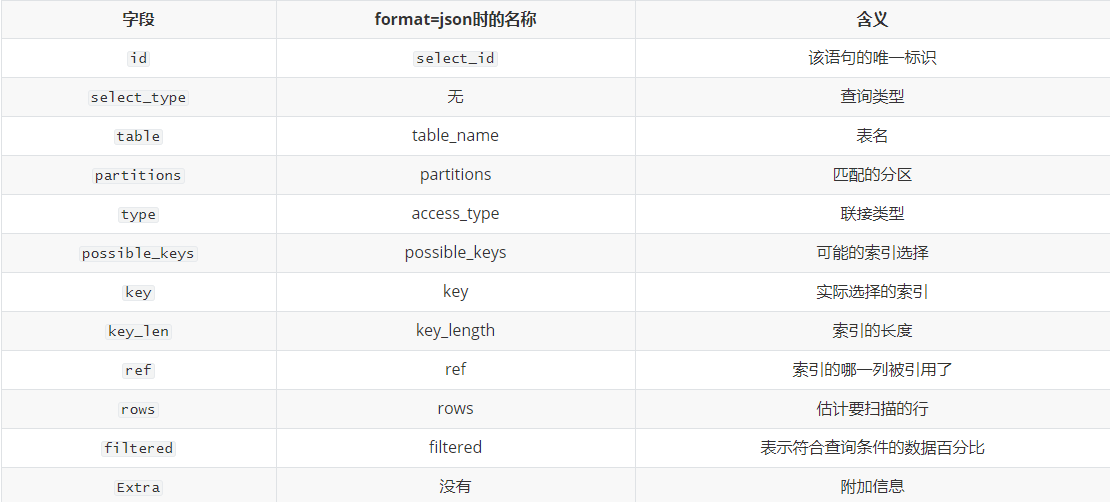
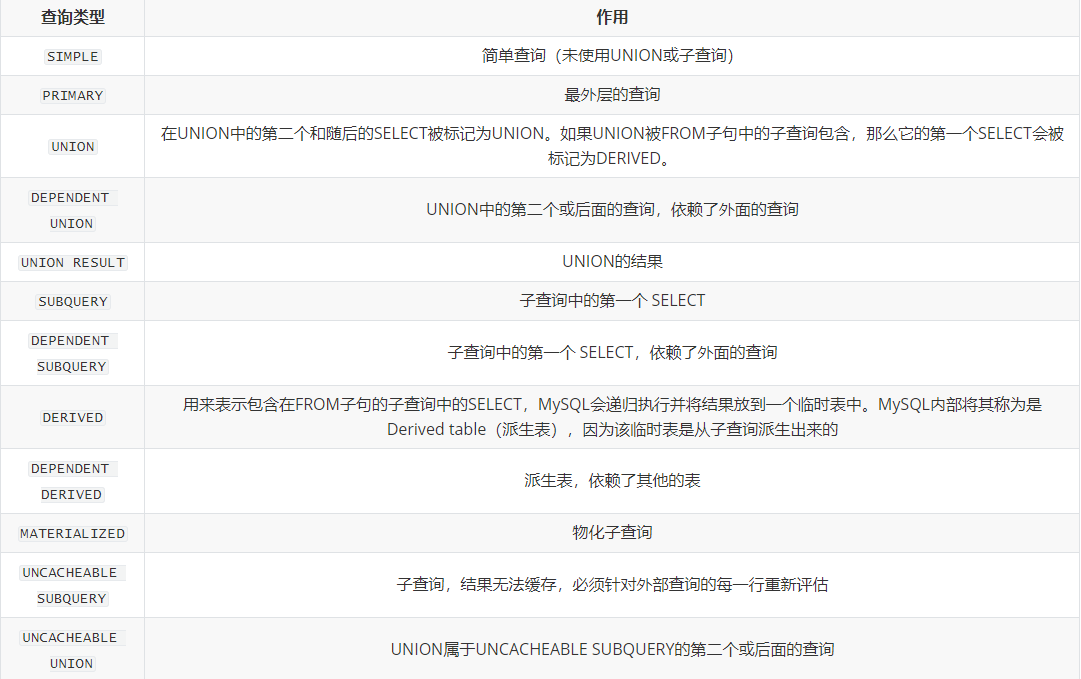
◦system:该表只有一行(相当于系统表),system是const类型的特例
◦const:针对主键或唯一索引的等值查询扫描, 最多只返回一行数据. const 查询速度非常快, 因为它仅仅读取一次即可
◦eq_ref:当使用了索引的全部组成部分,并且索引是PRIMARY KEY或UNIQUE NOT NULL 才会使用该类型,性能仅次于system及const。
-- 多表关联查询,单行匹配SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column;-- 多表关联查询,联合索引,多行匹配SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;◦ref:当满足索引的最左前缀规则,或者索引不是主键也不是唯一索引时才会发生。如果使用的索引只会匹配到少量的行,性能也是不错的。
-- 根据索引(非主键,非唯一索引),匹配到多行SELECT * FROM ref_table WHERE key_column=expr;-- 多表关联查询,单个索引,多行匹配SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column;-- 多表关联查询,联合索引,多行匹配SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1;TIPS最左前缀原则
指的是索引按照最左优先的方式匹配索引。比如创建了一个组合索引(column1, column2, column3),那么,如果查询条件是: WHERE column1 = 1、WHERE column1= 1 AND column2 = 2、WHERE column1= 1 AND column2 = 2 AND column3 = 3 都可以使用该索引; WHERE column1 = 2、WHERE column1 = 1 AND column3 = 3就无法匹配该索引。
◦fulltext:全文索引ref_or_null:该类型类似于ref,但是MySQL会额外搜索哪些行包含了NULL。这种类型常见于解析子查询
SELECT * FROM ref_tableWHERE key_column=expr OR key_column IS NULL;◦index_merge:此类型表示使用了索引合并优化,表示一个查询里面用到了多个索引
◦unique_subquery:该类型和eq_ref类似,但是使用了IN查询,且子查询是主键或者唯一索引。例如:value IN (SELECT primary_key FROM single_table WHERE some_expr)
◦index_subquery:和unique_subquery类似,只是子查询使用的是非唯一索引。value IN (SELECT key_column FROM single_table WHERE some_expr)
◦range:范围扫描,表示检索了指定范围的行,主要用于有限制的索引扫描。比较常见的范围扫描是带有BETWEEN子句或WHERE子句里有>、>=、<、<=、IS NULL、<=>、BETWEEN、LIKE、IN()等操作符。
SELECT * FROM tbl_name WHERE key_column BETWEEN 10 and 20;SELECT * FROM tbl_name WHERE key_column IN (10,20,30);◦index:全索引扫描,和ALL类似,只不过index是全盘扫描了索引的数据。当查询仅使用索引中的一部分列时,可使用此类型。有两种场景会触发:
▪如果索引是查询的覆盖索引,并且索引查询的数据就可以满足查询中所需的所有数据,则只扫描索引树。此时,explain的Extra 列的结果是Using index。index通常比ALL快,因为索引的大小通常小于表数据。
▪按索引的顺序来查找数据行,执行了全表扫描。此时,explain的Extra列的结果不会出现Uses index。
◦ALL:全表扫描,性能最差。
◦key_len计算公式:
https://www.cnblogs.com/gomysql/p/4004244.html
TIPS
在MySQL 5.7之前,想要显示此字段需使用explain extended命令; MySQL.5.7及更高版本,explain默认就会展示filtered
◦Child of ‘table’ pushed join@1:此值只会在NDB Cluster下出现。
◦const row not found:例如查询语句SELECT … FROM tbl_name,而表是空的
◦Deleting all rows:对于DELETE语句,某些引擎(例如MyISAM)支持以一种简单而快速的方式删除所有的数据,如果使用了这种优化,则显示此值
◦Distinct:查找distinct值,当找到第一个匹配的行后,将停止为当前行组合搜索更多行
◦FirstMatch(tbl_name):当前使用了半连接FirstMatch策略,详见
https://mariadb.com/kb/en/firstmatch-strategy/ ,翻译
https://www.cnblogs.com/abclife/p/10895624.html
◦Full scan on NULL key:子查询中的一种优化方式,在无法通过索引访问null值的时候使用
◦Impossible HAVING:HAVING子句始终为false,不会命中任何行
◦Impossible WHERE:WHERE子句始终为false,不会命中任何行
◦Impossible WHERE noticed after reading const tables:MySQL已经读取了所有const(或system)表,并发现WHERE子句始终为false
◦LooseScan(m…n):当前使用了半连接LooseScan策略,详见
https://mariadb.com/kb/en/loosescan-strategy/ ,翻译 http://www.javacoder.cn/?p=39
◦No matching min/max row:没有任何能满足例如 SELECT MIN(…) FROM … WHERE condition 中的condition的行
◦no matching row in const table:对于关联查询,存在一个空表,或者没有行能够满足唯一索引条件
◦No matching rows after partition pruning:对于DELETE或UPDATE语句,优化器在partition pruning(分区修剪)之后,找不到要delete或update的内容
◦No tables used:当此查询没有FROM子句或拥有FROM DUAL子句时出现。例如:explain select 1
◦Not exists:MySQL能对LEFT JOIN优化,在找到符合LEFT JOIN的行后,不会为上一行组合中检查此表中的更多行。例如:
SELECT * FROM t1 LEFT JOIN t2 ON t1.id=t2.idWHERE t2.id IS NULL;◦假设t2.id定义成了NOT NULL ,此时,MySQL会扫描t1,并使用t1.id的值查找t2中的行。 如果MySQL在t2中找到一个匹配的行,它会知道t2.id永远不会为NULL,并且不会扫描t2中具有相同id值的其余行。也就是说,对于t1中的每一行,MySQL只需要在t2中只执行一次查找,而不考虑在t2中实际匹配的行数。
◦在MySQL 8.0.17及更高版本中,如果出现此提示,还可表示形如 NOT IN (subquery) 或 NOT EXISTS (subquery) 的WHERE条件已经在内部转换为反连接。这将删除子查询并将其表放入最顶层的查询计划中,从而改进查询的开销。通过合并半连接和反联接,优化器可以更加自由地对执行计划中的表重新排序,在某些情况下,可让查询提速。你可以通过在EXPLAIN语句后紧跟一个SHOW WARNING语句,并分析结果中的Message列,从而查看何时对该查询执行了反联接转换。
◦Note:两表关联只返回主表的数据,并且只返回主表与子表没关联上的数据,这种连接就叫反连接Plan isn’t ready yet:使用了EXPLAIN FOR CONNECTION,当优化器尚未完成为在指定连接中为执行的语句创建执行计划时, 就会出现此值。MySQL没有找到合适的索引去使用,但是去检查是否可以使用range或index_merge来检索行时,会出现此提示。index map N索引的编号从1开始,按照与表的SHOW INDEX所示相同的顺序。 索引映射值N是指示哪些索引是候选的位掩码值。 例如0x19(二进制11001)的值意味着将考虑索引1、4和5。
◦MySQL没有找到合适的索引去使用,但是去检查是否可以使用range或index_merge来检索行时,会出现此提示。index map N索引的编号从1开始,按照与表的SHOW INDEX所示相同的顺序。 索引映射值N是指示哪些索引是候选的位掩码值。 例如0x19(二进制11001)的值意味着将考虑索引1、4和5。
◦示例:下面例子中,name是varchar类型,但是条件给出整数型,涉及到隐式转换。图中t2也没有用到索引,是因为查询之前我将t2中name字段排序规则改为utf8_bin导致的链接字段排序规则不匹配。
explain select a.* from t1 a left join t2 bon t1.name = t2.namewhere t2.name = 2;
SELECT ...FROM t, LATERAL (derived table that refers to t) AS dt...explainselect min(id)from t1;◦Skip_open_table:无需打开表文件,信息已经通过扫描数据字典获得
◦Open_frm_only:仅需要读取数据字典以获取表信息
◦Open_full_table:未优化的信息查找。表信息必须从数据字典以及表文件中读取Start temporary, End temporary:表示临时表使用Duplicate Weedout策略,详见
https://mariadb.com/kb/en/duplicateweedout-strategy/ ,翻译
https://www.cnblogs.com/abclife/p/10895531.html
SET optimizer_switch = 'index_condition_pushdown=off'; SET optimizer_switch = 'index_condition_pushdown=on';explain SELECT * FROM peopleWHERE zipcode='95054'AND lastname LIKE '%etrunia%'AND address LIKE '%Main Street%';-- name字段有索引explain SELECT name FROM t1 group by name-- name无索引explain SELECT name FROM t1 group by nameexplain SELECT * FROM t1 where id > 5在MySQL 8.0.12及更高版本,扩展信息可用于SELECT、DELETE、INSERT、REPLACE、UPDATE语句;在MySQL 8.0.12之前,扩展信息仅适用于SELECT语句; 在MySQL 5.6及更低版本,需使用EXPLAIN EXTENDED xxx语句;而从MySQL 5.7开始,无需添加EXTENDED关键词。
mysql> EXPLAIN SELECT t1.a, t1.a IN (SELECT t2.a FROM t2) FROM t1\G*************************** 1. row *************************** id: 1 select_type: PRIMARY table: t1 type: indexpossible_keys: NULL key: PRIMARY key_len: 4 ref: NULL rows: 4 filtered: 100.00 Extra: Using index*************************** 2. row *************************** id: 2 select_type: SUBQUERY table: t2 type: indexpossible_keys: a key: a key_len: 5 ref: NULL rows: 3 filtered: 100.00 Extra: Using index2 rows in set, 1 warning (0.00 sec)mysql> SHOW WARNINGS\G*************************** 1. row *************************** Level: Note Code: 1003Message: /* select#1 */ select `test`.`t1`.`a` AS `a`, <in_optimizer>(`test`.`t1`.`a`,`test`.`t1`.`a` in ( <materialize> (/* select#2 */ select `test`.`t2`.`a` from `test`.`t2` where 1 having 1 ), <primary_index_lookup>(`test`.`t1`.`a` in <temporary table> on <auto_key> where ((`test`.`t1`.`a` = `materialized-subquery`.`a`))))) AS `t1.a IN (SELECT t2.a FROM t2)` from `test`.`t1`1 row in set (0.00 sec)◦<auto_key>:自动生成的临时表key
◦<cache>(expr):表达式(例如标量子查询)执行了一次,并且将值保存在了内存中以备以后使用。对于包括多个值的结果,可能会创建临时表,你将会看到 <temporary table> 的字样
◦<exists>(query fragment):子查询被转换为 EXISTS
◦<in_optimizer>(query fragment):这是一个内部优化器对象,对用户没有任何意义
◦<index_lookup>(query fragment):使用索引查找来处理查询片段,从而找到合格的行
◦<if>(condition, expr1, expr2):如果条件是true,则取expr1,否则取expr2
◦<is_not_null_test>(expr):验证表达式不为NULL的测试
◦<materialize>(query fragment):使用子查询实现
◦
materialized-subquery.col_name:在内部物化临时表中对col_name的引用,以保存子查询的结果
◦<primary_index_lookup>(query fragment):使用主键来处理查询片段,从而找到合格的行
◦<ref_null_helper>(expr):这是一个内部优化器对象,对用户没有任何意义
◦/* select#N */ select_stmt:SELECT与非扩展的EXPLAIN输出中id=N的那行关联
◦outer_tables semi join (inner_tables):半连接操作。inner_tables展示未拉出的表。详见 “Optimizing Subqueries, Derived Tables, and View References with Semijoin Transformations”
◦<temporary table>:表示创建了内部临时表而缓存中间结果
作者:京东物流 柳宏
来源:京东云开发者社区 自猿其说Tech 转载请注明来源
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号