C++系列之三:面向对象概念透彻解析
发表时间: 2021-02-23 19:46
见下文
学习C语言时,我们知道,结构体的作用是把一些具有不同类型的变量组合一起
struct Student{ char _name[20]; char _gender[3]; int _age;}123456而在C++中,其结构体内不止可以定义变量,而且还可以定义函数、
struct Student{ char _name[20]; char _gender[3]; int _age; void SetStudentInfo(const char* name,const char* gender,int age) { strcpy(_name,name); strcpy(_gender,gender); _age=age; }};int main(){ Student s; s.SetStudentInfo("Bob","男",18); return 0;}这样定义后,结构体就可以被称为类,只不过在C++中,我们更喜欢使用class代替struct
根据以上叙述,所以在C++中,类是这样定义的
class className{ //成员函数 //成员变量 };//注意分号所以简单来说,类就是属性和方法的集合,属性就是类中的数据,方法就是调用这些数据进行操作的函数
要注意,成员函数如果在类中定义,编译器会将其当作内联函数处理。
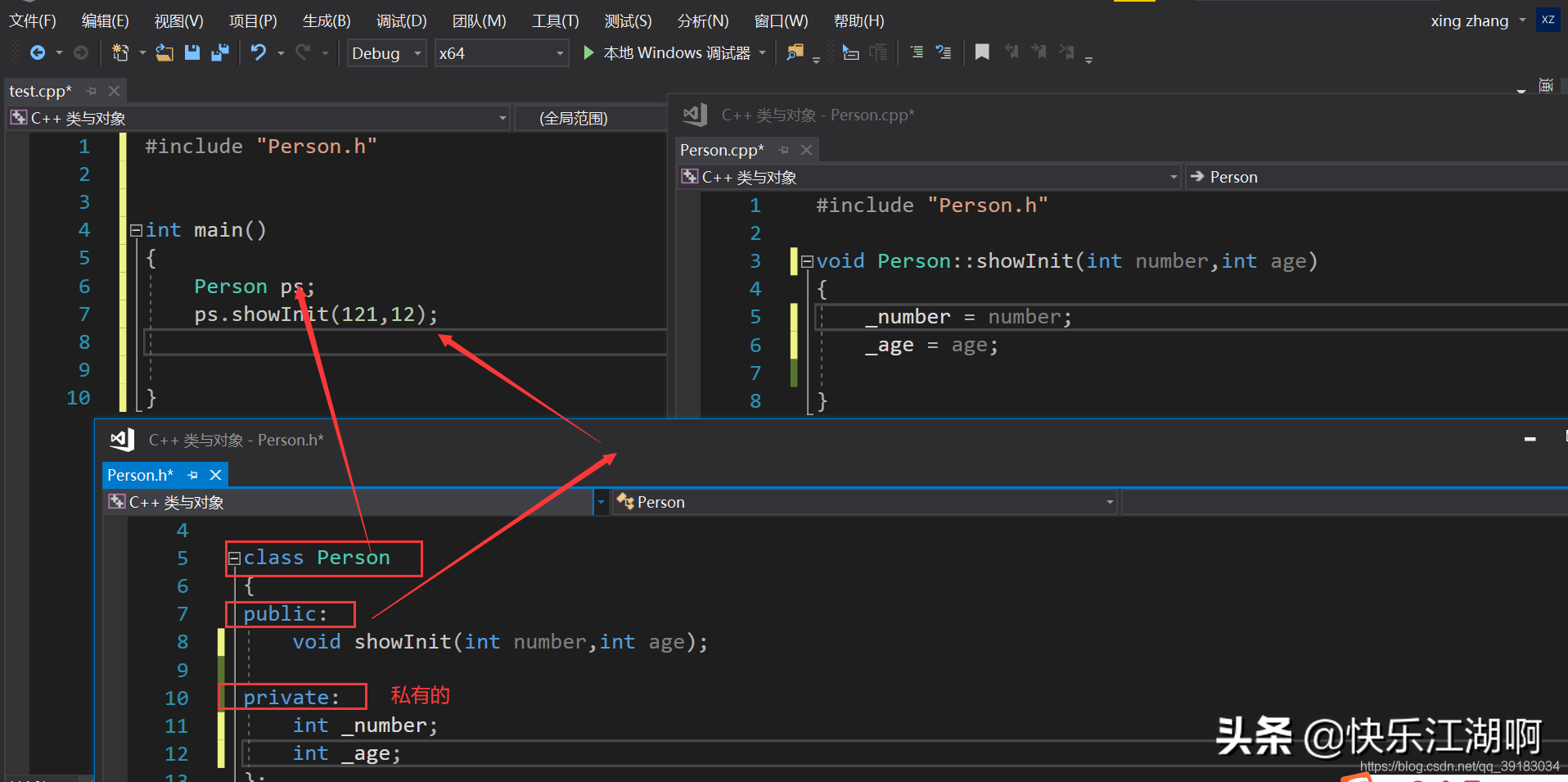
class Person//人就是一个类{public://成员函数 void showinfo()//显示这个人的信息 { std::cout<<_name<<std::endl; std::cout<<_sex<<std::endl; std::cout<<_age<<std::endl; }public://成员变量 char* _name; char* _sex; int _age;这种方式最常采用
在前面类的定义中,有一个public,它属于访问限定符,除了public(公有)还有protected(保护),private(私有),他们用于修饰成员,比如public修饰的成员可以在类的外面直接被访问,而是用protected和private修饰的在类的外面不可以被直接访问
注意以下几点
我们知道面向对象三大特性:封装,继承,多态
封装本质是一种管理手段,将属性(数据)和方法(接口)有机结合起来,再隐藏他们,只对外公开接口(函数)来和对象进行交互。不想给别人看的,使用protected/private进行修饰,而开放一些公有函数对成员进行合理访问。合理访问可以理解为阅读,不合理访问可以理解为改写(不准确)。
这里也就能说明,为什么C语言不支持大型项目的编写,因为它不支持面向对象,管理能力较弱,不是函数就是数据,就拿struct来说,其默认就是public的,安全性也堪忧,总的来说,用C语言编写项目,会感觉很乱,模块与模块独立性很差。
之前使用C语言实现过很多数据结构,比如说栈,我们都是新建一个工程然后分别建立它的声明,实现等文件,也就是说数据和方法是分离的,是自由的,如果换到C++中,按照面向对象考虑,一个栈就可以作为一个对象,这个对象有它的数据(动态增长的数组,长度,容量),还有它的方法(栈的初试线,压栈,出栈等等)。像这些数据,应该就是私有的,因为要防止外部操作改变数据,一旦数据出错,那么方法也就会受到相应的波及,然后这些操作按照实际需求让外部使用。
如:
//stack.hclass Stack//类{public: void Init(int capacity=4);//缺省参数。声明private: //数据私有 int* _arr; int _length; int _capacity;//stack.cppvoid Stack::Init(int capacity)//该方法的实现{ _arr=(int*)malloc(sizeof(int)*capacity); _length=0; _capactiy=capacity;}类可以理解为一个房屋的图纸,这个图纸规定了一些基本信息,比如说这个房子朝向是什么,有几扇窗户,房子材料是什么等等。但是图纸终归就是图纸,纸上谈兵永远不会成为现实,要把这个图纸现实化,就要根据这个图纸的规定,修出相应的房子。当然,不按照图纸也能修,只不过修出来的房子可能成为四不像,或者不安全。这也就像C语言,没有图纸,接口随意写,数据任你改,是很自由,但是稍有不慎,房子就可能用不久了。
所以说根据图纸建造房子的过程,称为类的实例化,就像前面的栈一样,实例化出一个真正的栈,什么叫做真正的栈——这个栈它占用实际空间。一个图纸不可能只能造出一个房子,而是可以造出千千万万个房子,这个诸多房子本原都是一个,要想让他们之间有所区别,这取决于使用者,比如你和我都按照这个图纸了建造了相同的房子,但是我们对房子的装饰不同,所以看起来也就像两个不同的房子。回到栈,我们可以实例化出许许多多的栈,但是有些栈用于进行非递归操作,有些栈用于排序操作,他们就不是一样的了。
比如前面的栈可以实例化为
//stack.hclass Stack//类{public: void Init(int capacity=4);//缺省参数。声明private: //数据私有 int* _arr; int _length; int _capacity; //stack.cppvoid Stack::Init(int capacity)//该方法的实现{ _arr=(int*)malloc(sizeof(int)*capacity); _length=0; _capactiy=capacity;}//test.cppint main(){ Stack stack; stack._arr=4;//操作非法,成员是private的 stack.Init();//初始化这个栈}面向对象编程:其实很多学习编程的人,对于面向过程编程和面向对象编程这两个概念总是搞不清,具体的专业的定义在这里也不去说了,根据上面的叙述,我们可以这样去通俗的解释面向对象。
举个例子:我去洗澡,如果按照面向过程的角度考虑,那么我先进入浴室,然后打开水龙,然后洗漱,然后把身体擦干,也就是说面向过程关注的是解决问题的步骤;如果用面向对象考虑,只需记住一句话,万物皆对象,你是对象,水龙头也是对象,所以我先传递力的参数给浴室门,然后门就开了,然后我再传递消息给水龙头,水龙头得到消息,放水,最后传递消息给毛巾,毛巾利用它吸水的特性,调用吸水方法擦干身体,也就是说面向对象关注的是对象,将一个问题拆分为不同对象,依靠参数完成对象之间的交互。
**为什么要进行面向对象编程?**这也是一个很值得思考的问题。举个例子,活字印刷术发明之前使用的是雕版印刷,这种方式弊端太大,如果需要改稿,那么雕版就必须重新雕刻,而活字印刷术则解决了这样的问题,需要改动,有可能只需改动几处。面向过程正如雕版印刷一样,也正如做数学题一样,中间某个环节一旦出现需求变更,那么整个工程几乎需要大改,要耗费大量时间精力。面向对象正如活字印刷术一样,如果需求变化了,可能只是修改其中一部分,也就是一个对象,而且最关键的一点是这些对象可以服用,进行活字印刷术一样,不是说这个对象在这个工程中发挥完之后,它就没有价值了,它还可能被其他工程所用。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号