深入理解Golang中的反射机制与应用
发表时间: 2022-08-23 15:00
赵燕辉
首先来一段简单的代码逻辑热身,下面的代码大家觉得应该会打印什么呢?
type OKR struct { id int content string}func getOkrDetail(ctx context.Context, okrId int) (*OKR, *okrErr.OkrErr) { return &OKR{id: okrId, content: fmt.Sprint(rand.Int63())}, nil}func getOkrDetailV2(ctx context.Context, okrId int) (*OKR, okrErr.OkrError) { if okrId == 2{ return nil, okrErr.OKRNotFoundError } return &OKR{id: okrId, content: fmt.Sprint(rand.Int63())}, nil}func paperOkrId(ctx context.Context) (int, error){ return 1, nil}func Test001(ctx context.Context) () { var okr *OKR okrId, err := paperOkrId(ctx) if err != nil{ fmt.Println("#### 111 ####") } okr, err = getOkrDetail(ctx, okrId) if err != nil { fmt.Println("#### 222 ####") } okr, err = getOkrDetailV2(ctx, okrId) if err != nil { fmt.Println("#### 333 ####") } okr, err = getOkrDetailV2(ctx, okrId + 1) if err != nil { fmt.Println("#### 444 ####") } fmt.Println("#### 555 ####") fmt.Printf("%v", okr)}func main() { Test001(context.Background())}
在讲反射之前,先来看看 Golang 关于类型设计的一些原则
接下来要说的反射,就是能够在运行时更新变量和检查变量的值、调用变量的方法和变量支持的内在操作,而不需要在编译时就知道这些变量的具体类型。这种机制被称为反射。Golang 的基础类型是静态的(也就是指定 int、string 这些的变量,它的 type 是 static type),在创建变量的时候就已经确定,反射主要与 Golang 的 interface 类型相关(它的 type 是 concrete type),只有运行时 interface 类型才有反射一说。
当程序运行时,我们获取到一个 interface 变量, 程序应该如何知道当前变量的类型,和当前变量的值呢?
当然我们可以有预先定义好的指定类型, 但是如果有一个场景是我们需要编写一个函数,能够处理一类共性逻辑的场景,但是输入类型很多,或者根本不知道接收参数的类型是什么,或者可能是没约定好;也可能是传入的类型很多,这些类型并不能统一表示。这时反射就会用的上了,典型的例子如:json.Marshal。
再比如说有时候需要根据某些条件决定调用哪个函数,比如根据用户的输入来决定。这时就需要对函数和函数的参数进行反射,在运行期间动态地执行函数。
举例场景:
比如我们需要将一个 struct 执行某种操作(用格式化打印代替),这种场景下我们有多种方式可以实现,比较简单的方式是:switch case
func Sprint(x interface{}) string { type stringer interface { String() string } switch x := x.(type) { case stringer: return x.String() case string: return x case int: return strconv.Itoa(x) // int16, uint32... case bool: if x { return "true" } return "false" default: return "wrong parameter type" }}type permissionType int64但是这种简单的方法存在一个问题, 当增加一个场景时,比如需要对 slice 支持,则需要在增加一个分支,这种增加是无穷无尽的,每当我需要支持一种类型,哪怕是自定义类型, 本质上是 int64 也仍然需要增加一个分支。
在 Golang 中为我们提供了两个方法,分别是 reflect.ValueOf 和 reflect.TypeOf,见名知意这两个方法分别能帮我们获取到对象的值和类型。Valueof 返回的是 Reflect.Value 对象,是一个 struct,而 typeof 返回的是 Reflect.Type 是一个接口。我们只需要简单的使用这两个进行组合就可以完成多种功能。
type GetOkrDetailResp struct { OkrId int64 UInfo *UserInfo ObjList []*ObjInfo}type ObjInfo struct { ObjId int64 Content string}type UserInfo struct { Name string Age int IsLeader bool Salary float64 privateFiled int}// 利用反射创建structfunc NewUserInfoByReflect(req interface{})*UserInfo{ if req == nil{ return nil } reqType :=reflect.TypeOf(req) if reqType.Kind() == reflect.Ptr{ reqType = reqType.Elem() } return reflect.New(reqType).Interface().(*UserInfo)}// 修改struct 字段值func ModifyOkrDetailRespData(req interface{}) { reqValue :=reflect.ValueOf(req).Elem() fmt.Println(reqValue.CanSet()) uType := reqValue.FieldByName("UInfo").Type().Elem() fmt.Println(uType) uInfo := reflect.New(uType) reqValue.FieldByName("UInfo").Set(uInfo)}// 读取 struct 字段值,并根据条件进行过滤func FilterOkrRespData(reqData interface{}, objId int64){// 首先获取req中obj slice 的valuefor i := 0 ; i < reflect.ValueOf(reqData).Elem().NumField(); i++{ fieldValue := reflect.ValueOf(reqData).Elem().Field(i)if fieldValue.Kind() != reflect.Slice{continue } fieldType := fieldValue.Type() // []*ObjInfo sliceType := fieldType.Elem() // *ObjInfo slicePtr := reflect.New(reflect.SliceOf(sliceType)) // 创建一个指向 slice 的指针 slice := slicePtr.Elem() slice.Set(reflect.MakeSlice(reflect.SliceOf(sliceType), 0, 0)) // 将这个指针指向新创建slice// 过滤所有objId == 当前objId 的structfor i := 0 ;i < fieldValue.Len(); i++{if fieldValue.Index(i).Elem().FieldByName("ObjId").Int() != objId {continue } slice = reflect.Append(slice, fieldValue.Index(i)) }// 将resp 的当前字段设置为过滤后的slice fieldValue.Set(slice) }}func Test003(){// 利用反射创建一个新的对象var uInfo *UserInfo uInfo = NewUserInfoByReflect(uInfo) uInfo = NewUserInfoByReflect((*UserInfo)(nil))// 修改resp 返回值里面的 user info 字段(初始化) reqData1 := new(GetOkrDetailResp) fmt.Println(reqData1.UInfo) ModifyOkrDetailRespData(reqData1) fmt.Println(reqData1.UInfo)// 构建请求参数 reqData := &GetOkrDetailResp{OkrId: 123} for i := 0; i < 10; i++{ reqData.ObjList = append(reqData.ObjList, &ObjInfo{ObjId: int64(i), Content: fmt.Sprint(i)}) }// 输出过滤前结果 fmt.Println(reqData)// 对respData进行过滤操作 FilterOkrRespData(reqData, 6)// 输出过滤后结果 fmt.Println(reqData)}大家都或多或少听说过反射性能偏低,使用反射要比正常调用要低几倍到数十倍,不知道大家有没有思考过反射性能都低在哪些方面,我先做一个简单分析,通过反射在获取或者修改值内容时,多了几次内存引用,多绕了几次弯,肯定没有直接调用某个值来的迅速,这个是反射带来的固定性能损失,还有一方面的性能损失在于,结构体类型字段比较多时,要进行遍历匹配才能获取对应的内容。下面就根据反射具体示例来分析性能:
测试反射结构体初始化
// 测试结构体初始化的反射性能func Benchmark_Reflect_New(b *testing.B) { var tf *TestReflectField t := reflect.TypeOf(TestReflectField{}) for i := 0; i < b.N; i++ { tf = reflect.New(t).Interface().(*TestReflectField) } _ = tf}// 测试结构体初始化的性能func Benchmark_New(b *testing.B) { var tf *TestReflectField for i := 0; i < b.N; i++ { tf = new(TestReflectField) } _ = tf}运行结果:

可以看出,利用反射初始化结构体和直接使用创建 new 结构体是有性能差距的,但是差距不大,不到一倍的性能损耗,看起来对于性能来说损耗不是很大,可以接受。
测试结构体字段读取/赋值
// --------- ------------ 字段读 ----------- ----------- -----------// 测试反射读取结构体字段值的性能func Benchmark_Reflect_GetField(b *testing.B) { var tf = new(TestReflectField) var r int64 temp := reflect.ValueOf(tf).Elem() for i := 0; i < b.N; i++ { r = temp.Field(1).Int() } _ = tf _ = r}// 测试反射读取结构体字段值的性能func Benchmark_Reflect_GetFieldByName(b *testing.B) { var tf = new(TestReflectField) temp := reflect.ValueOf(tf).Elem() var r int64 for i := 0; i < b.N; i++ { r = temp.FieldByName("Age").Int() } _ = tf _ = r}// 测试结构体字段读取数据的性能func Benchmark_GetField(b *testing.B) { var tf = new(TestReflectField) tf.Age = 1995 var r int for i := 0; i < b.N; i++ { r = tf.Age } _ = tf _ = r}// --------- ------------ 字段写 ----------- ----------- -----------// 测试反射设置结构体字段的性能func Benchmark_Reflect_Field(b *testing.B) { var tf = new(TestReflectField) temp := reflect.ValueOf(tf).Elem() for i := 0; i < b.N; i++ { temp.Field(1).SetInt(int64(25)) } _ = tf}// 测试反射设置结构体字段的性能func Benchmark_Reflect_FieldByName(b *testing.B) { var tf = new(TestReflectField) temp := reflect.ValueOf(tf).Elem() for i := 0; i < b.N; i++ { temp.FieldByName("Age").SetInt(int64(25)) } _ = tf}// 测试结构体字段设置的性能func Benchmark_Field(b *testing.B) { var tf = new(TestReflectField) for i := 0; i < b.N; i++ { tf.Age = i } _ = tf}测试结果:

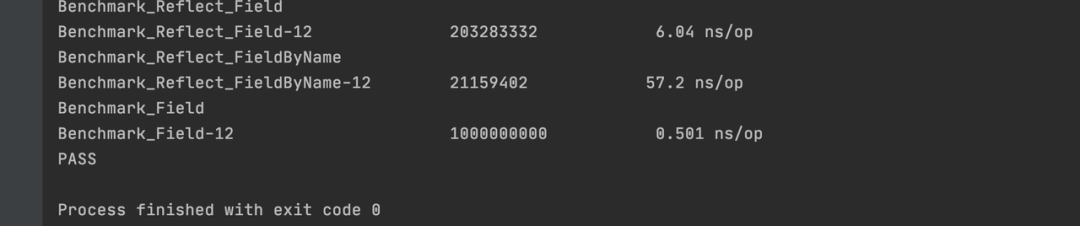
从上面可以看出,通过反射进行 struct 字段读取耗时是直接读取耗时的百倍。直接对实例变量进行赋值每次 0.5 ns,性能是通过反射操作实例指定位置字段的 10 倍左右。使用 FieldByName("Age") 方法性能比使用 Field(1) 方法性能要低十倍左右,看代码的话我们会发现,FieldByName 是通过遍历匹配所有的字段,然后比对字段名称,来查询其在结构体中的位置,然后通过位置进行赋值,所以性能要比直接使用 Field(index) 低上很多。
建议:
1.如果不是必要尽量不要使用反射进行操作, 使用反射时要评估好引入反射对接口性能的影响。
2.减少使用 FieldByName 方法。在需要使用反射进行成员变量访问的时候,尽可能的使用成员的序号。如果只知道成员变量的名称的时候,看具体代码的使用场景,如果可以在启动阶段或在频繁访问前,通过 TypeOf() 、Type.FieldByName() 和 StructField.Index 得到成员的序号。注意这里需要的是使用的是 reflect.Type 而不是 reflect.Value,通过 reflect.Value 是得不到字段名称的。
测试结构体方法调用
// 测试通过结构体访问方法性能func BenchmarkMethod(b *testing.B) { t := &TestReflectField{} for i := 0; i < b.N; i++ { t.Func0() }}// 测试通过序号反射访问无参数方法性能func BenchmarkReflectMethod(b *testing.B) { v := reflect.ValueOf(&TestReflectField{}) for i := 0; i < b.N; i++ { v.Method(0).Call(nil) }}// 测试通过名称反射访问无参数方法性能func BenchmarkReflectMethodByName(b *testing.B) { v := reflect.ValueOf(&TestReflectField{}) for i := 0; i < b.N; i++ { v.MethodByName("Func0").Call(nil) }}// 测试通过反射访问有参数方法性能func BenchmarkReflectMethod_WithArgs(b *testing.B) { v := reflect.ValueOf(&TestReflectField{}) for i := 0; i < b.N; i++ { v.Method(1).Call([]reflect.Value{reflect.ValueOf(i)}) }}// 测试通过反射访问结构体参数方法性能func BenchmarkReflectMethod_WithArgs_Mul(b *testing.B) { v := reflect.ValueOf(&TestReflectField{}) for i := 0; i < b.N; i++ { v.Method(2).Call([]reflect.Value{reflect.ValueOf(TestReflectField{})}) }}// 测试通过反射访问接口参数方法性能func BenchmarkReflectMethod_WithArgs_Interface(b *testing.B) { v := reflect.ValueOf(&TestReflectField{}) for i := 0; i < b.N; i++ { var tf TestInterface = &TestReflectField{} v.Method(3).Call([]reflect.Value{reflect.ValueOf(tf)}) }}// 测试访问多参数方法性能func BenchmarkMethod_WithManyArgs(b *testing.B) { s := &TestReflectField{} for i := 0; i < b.N; i++ { s.Func4(i, i, i, i, i, i) }}// 测试通过反射访问多参数方法性能func BenchmarkReflectMethod_WithManyArgs(b *testing.B) { v := reflect.ValueOf(&TestReflectField{}) va := make([]reflect.Value, 0) for i := 1; i <= 6; i++ { va = append(va, reflect.ValueOf(i)) } for i := 0; i < b.N; i++ { v.Method(4).Call(va) }}// 测试访问有返回值的方法性能func BenchmarkMethod_WithResp(b *testing.B) { s := &TestReflectField{} for i := 0; i < b.N; i++ { _ = s.Func5() }}// 测试通过反射访问有返回值的方法性能func BenchmarkReflectMethod_WithResp(b *testing.B) { v := reflect.ValueOf(&TestReflectField{}) for i := 0; i < b.N; i++ { _ = v.Method(5).Call(nil)[0].Int() }}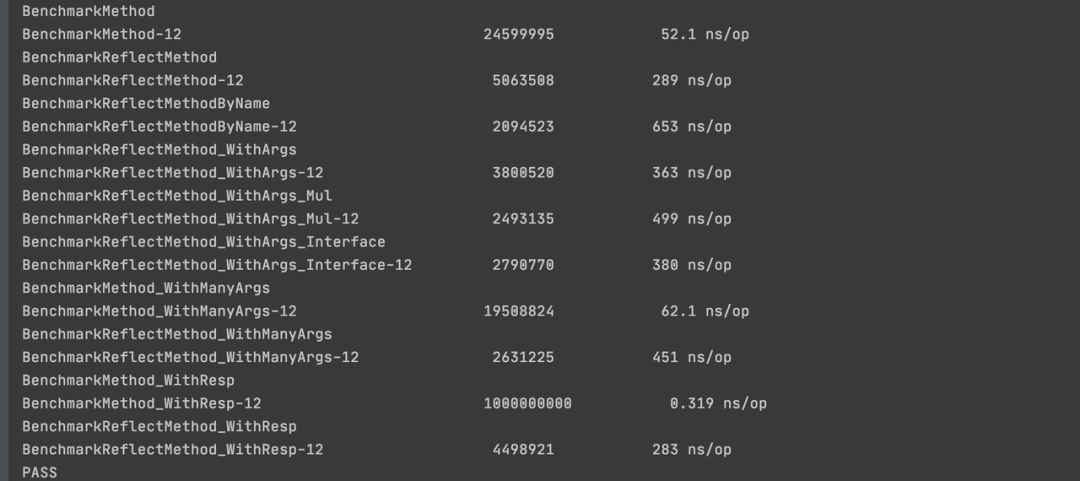
这个测试结果同上面的分析相同
优缺点:
优点:
缺点:
func OkrBaseMW(next endpoint.EndPoint) endpoint.EndPoint { return func(ctx context.Context, req interface{}) (resp interface{}, err error) { if req == nil { return next(ctx, req) } requestValue := reflect.ValueOf(req) // 若req为指针,则转换为非指针值 if requestValue.Type().Kind() == reflect.Ptr { requestValue = requestValue.Elem() } // 若req的值不是一个struct,则不注入 if requestValue.Type().Kind() != reflect.Struct { return next(ctx, req) } if requestValue.IsValid() { okrBaseValue := requestValue.FieldByName("OkrBase") if okrBaseValue.IsValid() && okrBaseValue.Type().Kind() == reflect.Ptr { okrBase, ok := okrBaseValue.Interface().(*okrx.OkrBase) if ok { ctx = contextWithUserInfo(ctx, okrBase) ctx = contextWithLocaleInfo(ctx, okrBase) ctx = contextWithUserAgent(ctx, okrBase) ctx = contextWithCsrfToken(ctx, okrBase) ctx = contextWithReferer(ctx, okrBase) ctx = contextWithXForwardedFor(ctx, okrBase) ctx = contextWithHost(ctx, okrBase) ctx = contextWithURI(ctx, okrBase) ctx = contextWithSession(ctx, okrBase) } } } return next(ctx, req) }}使用反射必定会导致性能下降,但是反射是一个强有力的工具,可以解决我们平时的很多问题,比如数据库映射、数据序列化、代码生成场景。在使用反射的时候,我们需要避免一些性能过低的操作,例如使用 FieldByName() 和MethodByName() 方法,如果必须使用这些方法的时候,我们可以预先通过字段名或者方法名获取到对应的字段序号,然后使用性能较高的反射操作,以此提升使用反射的性能。
我们来自字节跳动飞书商业应用研发部(Lark Business Applications),目前我们在北京、深圳、上海、武汉、杭州、成都、广州、三亚都设立了办公区域。我们关注的产品领域主要在企业经验管理软件上,包括飞书 OKR、飞书绩效、飞书招聘、飞书人事等 HCM 领域系统,也包括飞书审批、OA、法务、财务、采购、差旅与报销等系统。
欢迎各位加入我们。扫码发现职位&投递简历(二维码如下)官网投递:

点击「链接」,欢迎各位加入我们
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号