提升Java代码可读性的秘诀
发表时间: 2021-10-06 15:00
我们经常感叹“面试造火箭,进厂拧螺丝”,日常开发中大部分工作都是写简单的业务代码。实际上,写好业务代码也是有技术难度的,并不是所有人都能写出可读性较高的业务代码。
可读性高的代码能够降低后续的维护成本,提升后续开发的效率。
接下来和大家分享下我的经验,这些方法能够在一定程度上提升代码的可读性。
Martin Fowler曾经在一篇文章中曾经引用过Phil Karlton的话:There are only two hard things in Computer Science: cache invalidation and naming things. “
在 CS 领域中,有两件事是非常难的,一个是缓存失效,一个是命名。”
一致性
大项目中都是分工合作,不同领域由不同团队负责,同一领域也可能由多个人一起开发,因此即使对同一个事物命名,不同人也有不同的理解,因此对于关键业务名称的命名需要统一,使整个链路保持一致性。
这个责任最好由项目PM担起,在写技术方案的时候,统一关键业务事物的命名。
有意义且简短
首先需要保证命名有意义,只要命名合理,不要担心方法名称太长,但方法名称过长常常又意味着该方法干的事太多了,则需要思考是否可以拆分方法,这也反映了"职责单一"设计原则。
保证命名有意义的前提之下,尽量保证命名的简短,删除一些不影响表达的单词,或者采用缩写。举几个例子:
遵循命名规范
Java的命名规范参考《阿里巴巴开发规约》中的命名规约,下面摘抄几条命名规范复习下:
区分作用范围
作用范围可以分为应用、包、类、方法、代码块,在大的作用域范围应该尽量使用完整有意义的命名,但是在方法和代码块内可以考虑使用短名称,因为变量作用范围有局限性,上下文一眼可知,变量的含义也就无需过多说明。
如果小作用范围依然使用长命名会导致很容易超过列宽,即使折行也难以阅读。如下所示,方法内采用简短的命名方式。
void updateRule4Revision(String ruleStr) { ActivityRule rule = toActivityRule(ruleStr); int oldVersion = rule.getVersion(); rule.setVersion(++oldVersion); activityRuleRepository.save(rule);}体现副作用
如果方法实现会产生副作用,该副作用需要体现在方法名称,举个可能不太恰当的例子,下面的方法在验证规则的同时去激活规则的状态,如果规则已经是激活状态则状态没有变化,如果规则不是激活状态则状态被改变。
一般我们应该保持方法的单一职责,但是有些特殊情况导致了妥协,那么一定要在方法命名上面体现。
boolean verifyRuleAndActivateStatus(Rule rule) { // verify rule ...... rule.activateStatus() ......}阅读优秀的开源代码
英语不是我们的母语,这导致我们命名更加困难,我们可以通过阅读优秀的开源代码提升词汇量,熟悉英语母语开发者的命名思维习惯。
也并不是所有的开源项目的代码可读性都很高,有些为了追求极致的性能损失了部分可读性,如果不知道学习哪个开源项目,那就学习spring-boot项目,下面截图是spring-boot项目中的代码,命名方式值得学习。
优雅判空
NullPointerException是Java程序员无法言语的痛,为了避免空指针异常,我们通常需要做非常多的防御性编程,if判空是最简单的方式,但是充斥大量着if判空的代码会淹没核心代码逻辑,导致可读性差。
下面举一个例子:
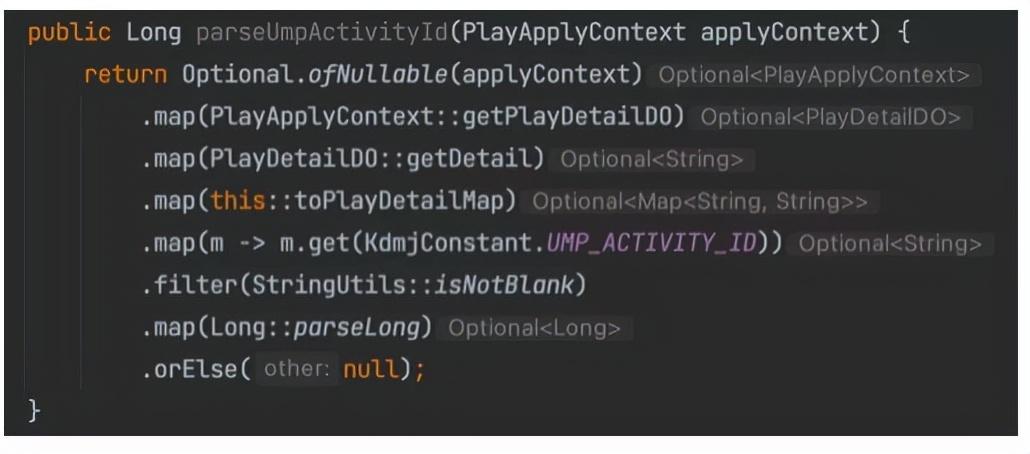
public Long parseUmpActivityId(PlayApplyContext applyContext) { if (applyContext == null || applyContext.getPlayDetailDO() == null || StringUtil.isBlank(applyContext.getPlayDetailDO().getDetail())) { return null; } Map<String, String> playDetailMap = toPlayDetailMap(applyContext.getPlayDetailDO().getDetail()); if (playDetailMap == null) { return null; } String umpActivityIdStr = playDetailMap.get(Constant.UMP_ACTIVITY_ID); if (StringUtils.isBlank(umpActivityIdStr)) { return null; } return Long.parseLong(umpActivityIdStr);}public Long parseUmpActivityId(PlayApplyContext applyContext) { return Optional.ofNullable(applyContext) .map(PlayApplyContext::getPlayDetailDO) .map(PlayDetailDO::getDetail) .map(this::toPlayDetailMap) .map(m -> m.get(Constant.UMP_ACTIVITY_ID)) .filter(StringUtils::isNotBlank) .map(Long::parseLong) .orElse(null);}分支判断
Optional的orElse具有分支判断的能力,可以在一些情况下代替if,提升代码的可读性,如下场景所示,经过三目运算符的优化依然可读性不强,Optional优化后才具有较高可读性。
...... Result<Long> result = apply(juItem); if (result == null || !result.isSuccess()) { if (result != null && result.getMsg() != null) { return Result.buildErrorResult(result.getMsg()); } return Result.buildErrorResult("创建失败"); } ...... ...... Result<Long> result = apply(juItem); if (result == null || !result.isSuccess()) { return Result.buildErrorResult( result != null && result.getMsg() != null ? result.getMsg() : "创建失败"); } ...... ...... Result<Long> result = apply(juItem); if (result == null || !result.isSuccess()) { return Result.buildErrorResult( Optional.ofNullable(result).map(Result::getMsg).orElse("创建失败")); } ......陷阱
在使用Optional的orElse时候可能会误入陷阱,举一个具体的例子,如下所示的代码存在问题吗?
这段代码的作用是,当传入参数中activity不为空则取传入的activity,否则通过接口根据活动ID查询,避免了无谓的查询。
Result applyActivity(Params params) { Activity activity = Optional.ofNullable(params) .map(Params::getActivity) .orElse(activityManager.findById(params.getActivityId())); ......}以上代码存在两个问题,第一,params.getActivityId()可能出现空指针异常,第二,activityManager.findById一定会被调用,无法达到预期的效果。
而这两个问题的根本原因都是因为orElse方法传入的是语句执行之后的结果。
所以在orElse方法中最好不要传入执行语句,而应该是默认值。
上面应该这种情况正确应该使用orElseGet,orElseGet传入的是函数。
正确换行
Optional方式编程很大程度提升了代码的可读性,写代码如行云流水一般,为了更好的阅读,需要采用正确的换行方式,最好是一行一条Optional语句,如下图所示,这样换行的好处就是,一行做一件事情,阅读流畅。
而且最重要的是IDEA在每条语句后面提示了返回结果的类型,这个提示不仅仅对阅读有帮助,对编写代码也有很大帮助。这个原则同样适用于Lambda表达式的编写。
当然,对于非常简单链式语句可以打破以上原则,比如context.setActivityId(Optional.ofNullable(activityId).orElse(0L));
关于Lambda表达式编程的好处和用法想必大部分人都清楚,正确使用Lambda表达式可以很大程度提升代码的可读性,但是不正确使用Lambda表达式会给可读性带来更大的灾难。
拒绝匿名函数
如下函数的功能是根据活动信息获取活动中的所有报名记录,采用了普通的for循环编写,嵌套比较深,代码含义不是很明确,有优化的空间,接下来采用Lambda表达式进行优化。
private List<Record> obtainRecords(List<Campaign> campaignList) { List<Record> recordList = Lists.newArrayList(); for (Campaign campaign : campaignList) { if (campaign.getStartTime() != null && campaign.getStartTime().getTime() < System.currentTimeMillis() && campaign.getStatus() > 0) { Params params = new Params(); params.setCampaignId(campaign.getId()); params.setStartTime(campaign.getStartTime()); params.setStatus(campaign.getStatus()); List<Record> originRecordList = campaignRecordFacade.query(params); for (Record record : originRecordList) { if ((record.getStatus() <= INIT && PLAY_TYPE.equals(record.getType())) || record.getStatus() == AUDIT_PASS) { recordList.add(record); } } } } return recordList;}采用Lambda表达式重新编写后如下所示,一定程度上提升了代码的可读性,是否还具有提升空间呢。
其中匿名函数占据了大部分代码逻辑,导致主流程不清晰,在使用Lambda表达式的时候应该尽量不要使用匿名函数。
private List<Record> obtainRecords(List<Campaign> campaignList) { return campaignList.stream() .filter(campaign -> campaign.getStartTime() != null && campaign.getStartTime().getTime() < System.currentTimeMillis() && campaign.getStatus() > 0) .map(campaign -> { Params params = new Params(); params.setCampaignId(campaign.getId()); params.setStartTime(campaign.getStartTime()); params.setStatus(campaign.getStatus()); return campaignRecordFacade.query(params); }) .flatMap(Collection::stream) .filter(record -> (record.getStatus() <= INIT && PLAY_TYPE.equals(record.getType())) || record.getStatus() == AUDIT_PASS) .collect(Collectors.toList());}去除匿名函数优化后如下所示,主流程非常清晰,没有阅读障碍,函数名解释了所做的具体事情,通过阅读函数名而不是具体的代码去了解这块做了什么事情,具体阅读某个函数时,只需要保证代码逻辑符合函数名表达的含义。
private List<Record> obtainRecords(List<Campaign> campaignList) { return campaignList.stream() .filter(this::isValidAndAlreadyStarted) .map(this::queryRecords) .flatMap(Collection::stream) .filter(this::isInitializedPlayOrAuditPass) .collect(Collectors.toList());}private boolean isValidAndAlreadyStarted(Campaign campaign) { return campaign.getStartTime() != null && campaign.getStartTime().getTime() < System.currentTimeMillis() && campaign.getStatus() > 0;}private List<Record> queryRecords(Campaign campaign) { Params params = new Params(); params.setCampaignId(campaign.getId()); params.setStartTime(campaign.getStartTime()); params.setStatus(campaign.getStatus()); return campaignRecordFacade.query(params);}private boolean isInitializedPlayOrAuditPass(Record record) { return (record.getStatus() <= INIT && PLAY_TYPE.equals(record.getType())) || record.getStatus() == AUDIT_PASS;}结合Optional使用
Lambda表达式结合Optional使用可以更加简洁,如下所示查询报名记录后获取报名记录的ID,不使用Optional的时候需要判空等其他操作,Optional让语句更加连贯。
这里需要注意一点,Collections.emptyList()返回的是一个不可变的内部类,不允许添加元素,如果返回的结果需要添加元素,需要使用Lists.newArrayList()。
Optional.ofNullable(playRecordReadService.query(query)) .orElse(Collections.emptyList()) .stream .fileter(this::isValid) .map(Record::getId) .collect(Collectors.toList());用好异常
Checked Exception是Lambda表达式的天敌,因为在Lambda表达式中必须捕获Checked Exception,这样会导致Lambda表达式特别累赘。
针对这种情况,在系统内部最好使用Runtime Exception,如果是外部接口申明了Checked Exception,那我们应该在基础设施层将外部接口封装一个facade,facade只抛出Runtime Exception。
有一种系统设计,提倡系统内部接口也使用Result作为返回结果,这种设计导致了很难流畅地使用Lambda表达式,因为你的代码里面会充斥着大量if (!result.isSuccess())的判断,如下代码所示,queryRecordsByCampaign是一个RPC接口,可以看到代码逻辑非常啰嗦,核心逻辑不明确。
Result<List<Record>> queryRecordsByCampaign(Campaign campaign) { Result<Void> checkResult = checkCampaign(campaign); if (!checkResult.isSuccess()) { return Result.buildErrorResult(checkResult.getErrorMsg()); } Result<Context> contextResult = buildContext(campaign); if (!contextResult.isSuccess()) { return Result.buildErrorResult(contextResult.getErrorMsg()); } Result<List<Record>> queryResult = queryRecords(contextResult.getValue()); if (!queryResult.isSuccess()) { return Result.buildErrorResult(queryResult.getErrorMsg()); } if (CollectionUtils.isEmpty(queryResult.getValue())) { return Result.buildSuccessResult(Lists.newArraysList()); } List<Record> records = queryResult.getValue().stream() .filter(this::isValid) .map(this::compensateRecord) .collect(Collectors.toList()); return Result.buildSuccessResult(records);}private Result<Void> checkCampaign(Campaign campaign) { if (campaign == null) { return Result.buildErrorResult("活动不能为空"); } if (campaign.getId <= 0) { return Result.buildErrorResult("活动ID非法"); } return Result.buildSuccessResult();}另外一种系统设计,提倡系统内部使用Runtime Exception控制异常流程,RPC接口不抛任何异常,使用Result表示返回结果。
上面的代码经过这种思想修改后的代码如下所示,代码简洁明了,Optional与Lambda完美配合。
其中关于参数校验和断言可以参考apache工具包中的Validate设计适合自己应用的工具类,通过Validate做校验非常简洁,并且可以自定义ExceptionCode来区分错误类型。
但是,一定不要使用异常来控制正常流程。
Result<List<Record>> queryRecordsByCampaign(Campaign campaign) { try { checkCampaign(campaign); List<Record> records = Optional.ofNullable(campaign) .map(this::buildContext) .map(this::queryRecords) .orElse(Collections.emptyList()) .stream() .filter(this::isValid) .map(this::compensateRecord) .collect(Collectors.toList()); return Result.buildSuccessResult(records); } catch (Throwable t) { log.error("an exception occurs ", t) return Result.buildErrorResult(t.getMessage()); }}private void checkCampaign(Campaign campaign) { Validate.notNull(campaign, "活动不能为空"); Validate.gtzero(campaign.getId(), "活动ID非法")}陷阱
《阿里巴巴开发规约》中提了两点关于使用toMap()方法的陷阱,如下所示:
另外,我们需要注意toList()可能导致FullGC,因为集合经过map后变成的类型可能占用很大内存,流量高的时候会导致FullGC,这个时候需要采用forEach方式编程。
电商场景中最常见的大内存对象就是ItemDO,一定不要批量获取ItemDO保存在内存中。
以上只是从语言特性方面列出了一些简单的快速的提升代码可读性方法,其实还可以从很多方面入手,比如设计模式、架构设计、事物抽象等。
关于架构设计提升代码可读性方法,我比较认同“领域驱动设计”思想,充血模型能够解决复杂业务逻辑使代码可读性变差的问题。
提升写代码的水平,是我们孜孜不倦的追求,从简单的业务代码出发,写出诗一样的代码。
作者:默达
原文链接:
http://click.aliyun.com/m/1000298831/
本文为阿里云原创内容,未经允许不得转载。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号