探索向量数据库的未知领域:一种独特的体验 | 快公司
发表时间: 2022-12-29 08:00

图片来源@视觉中国
人工智能的突破是建立在数据、算力、算法三个层面,彼此发展相辅相成。这是业界普遍共识。
从近些年的进展来看,深度学习大模型有效提升AI任务的训练效果,但也对计算和存储资源提出了极大需求。哪怕是只能带来一两个性能点的提升,只要最终能获得超强的效益回报,巨头科技公司往往会加大投入。性能提升的背后,是成本的代价。
但对于更多的创业公司而言,大模型做微调或二次开发的路径,且不说仍需要大量算力的支持,在实际场景中,能不能等到成熟落地也需要时间成本。是否可以替换为其他解决方案?在训练时外挂领域知识库,加强数据生产的标准化,将计算扩展到多个GPU实现分布式训练等等,均为业内在探索的方向。
Zilliz构建了一套向量数据库,虽然听起来是个新事物,但解决的问题却是上述已经存在的问题。
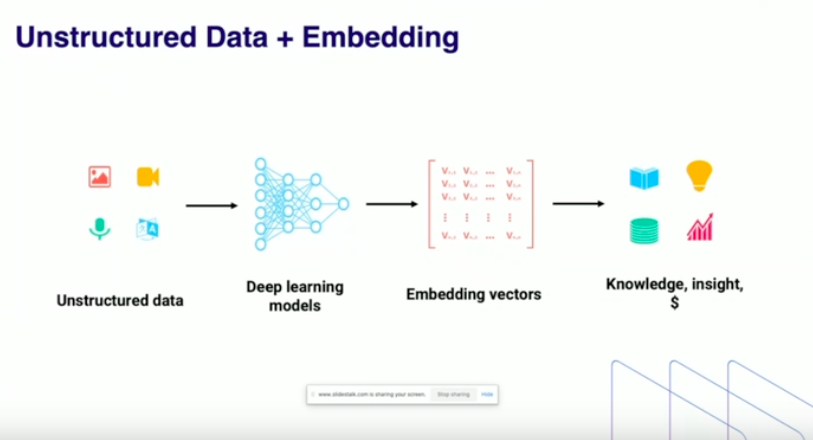
向量数据,顾名思义是Embedding Data。作为AI模型训练的基石,Embedding从最开始的用于文本表达的词向量,到后来可用于表达图片、视频、语音等非结构化数据转化的深层语义,这些向量数据可被计算机识别、使用,且在转化的过程中不丢失信息。
向量数据库,则是将向量数据在存储、分析等方面的问题解决,极大降低数据处理成本,帮助AI工程师获得AI数据价值。在这个过程中,相当于在非结构化数据和结构化数据层之上又加了一个新的数据层,这个数据层中的信息主要以向量的方式存在。为此向量数据库具备与ElasticSearch等传统搜索引擎对数据检索的的功能,但前者可对非结构化数据进行快速精准检索。
据Zilliz创始人Charles Xie(星爵)的观察,2013年前后,Embedding方兴未艾,但当时处理的数据量比较小,基本仍处于实验室小规模验证的阶段,也出现了很多提取算法、运算库,“数据库系统本质是帮助企业管理大量数据,如果数据量不够大,其实用不上数据库系统。”
真正的改变则来自于2017年前后,伴随深度学习在工业界的广泛落地,实际应用场景下的数据量级开始直线增加。想要高效处理这些海量的向量数据,就需要更细分、更专业的数据基础设施,为向量构建专门的数据库处理系统。
AI时代,数据处理的类型和计算体系架构都发生了较大变化,如GPU、FPGA、ARM架构芯片等层出不穷。但当时团队对最终产品形态是什么,并不是很清晰。
“因英伟达初创企业加速计划的契机,我们后来接触到了很多全球化AI企业。不断交流的过程中,我们意识到企业对海量非结构化数据管理的需求。”星爵表示,向量作为一个新型数据类型,其数据量已经达到了一定规模,对数据管理的要求如可用性、数据一致性、管理的复杂度等层面会越来越高。

星爵(Charles Xie)
一个专用的数据库系统需求呼之欲出。
不过,业内对向量数据库的认知和应用仍属于少数,并且当前多在大厂、互联网、人工智能企业,作为基础软件,数据库系统本身在技术上十分复杂,国内的技术公司虽然此前也有数十载的自研历史但目前在产业规模上尚未达到巅峰之势,传统数据库依然有很多存量业务。在品牌和生态尚未成熟之前,商业价值挑战是多方面的。
一是成本,需要挖掘软硬件对向量数据处理的加速能力。
例如,微软bing搜索引擎,在2000年就宣布用向量实现搜索引擎的增强,可处理2000多亿张网页的向量数据。相比这些领先互联网公司,一般的企业还是很少会用到如此多的数据。
星爵指出,“从行业的普遍场景来看,大概是在千万到十亿级别的规模,但这类非结构化数据,从人类企业能够分析利用的总量相比,还是非常小的部分。随着硬件成本的进一步降低,和计算效率的进一步提升,是可以以更低的成本、更高的效率去接触更多的非结构化数据。”
在他看来,AI算法和模型训练来的Embedding会有一个很好的效率提升,但是它的计算量也比较大,这导致计算成本也比较高。如果想要降低成本,就一定需要有硬件方面的创新,包括更快的处理器、CPU、GPU加速处理数据,也需要有更好的存储体系,以及更低成本的网络带宽进行支撑。加之在软件层面的创新如索引基础、调度算法等,都将提升厂商应用的ROI。
目前,Zilliz在积极拥抱异构计算的能力,让向量数据库比较好地适配GPU,包括英伟达、苹果基于ARM架构的M1/M2、亚马逊自研的ARM芯片等。
二是在数据库本身的稳定性、性能、成本等方面寻找一个技术方案最优解,进行全新的设计思路和研发方案。
从技术架构上讲,所有的数据库都会有其通用挑战,比如在数据调度、数据管理、执行引擎、数据的存储格式、缓存、分布式、数据的一致性和高可用性等方面都存在挑战。MongoDB、时序数据库、文档数据库、分布式数据库等数据库的出现,相比传统关系型数据库在各自的细分场景下有了一个更好的效能提升。
这些数据库需要因地制宜,找到适合它的应用场景。
因此,向量数据库,跟过去十年出现的各类新兴数据库遇到的挑战一样,要在一个完整的数据库系统组件里,综合向量数据、AI数据处理的特点,做全新的设计研发和探索。最终将这些技术组件能够紧密地联系在一起,为向量数据、AI数据处理提供一种更高性能、更高ROI的具有竞争优势的产品。
三是使用场景的探索与挖掘。向量数据库主要应用在与全文检索场景时,可提升检索的精准性。
举个例子,将ElasticSearch(ES)与向量数据库进行对比参照能够发现:
一是处理的数据类型不一样,ES处理的更多是文本分析、日志检索,而向量搜索处理的是复杂的自然语言交互,如图片视频的理解,比较粗颗粒度;
二是后者使用的是深度学习技术,更加不需要人工干预,可更加精准、智能地进行搜索,在精确值上会有比较大的提升(如天安门、故宫、紫禁城可以通过深刻语义理解后明确是同一个事物),但这也导致其需要更加复杂的计算和更多的计算资源,成本会略高。在检索速度上,向量数据库都能对延时和QPS都能达到很高的水平,延时在毫秒级别,QPS单节点在上千量级。
所以,选择哪类技术路径是跟业务场景是比较强相关的,ES这类传统的搜索引擎跟向量搜索引擎需要相辅相成。
整体来看,Zilliz主要关注的行业分布在互联网、电商、传统金融、以及新药研发等新兴领域,涉及计算机视觉、图片检索、视频分析、自然语言处理、推荐系统、定向广告、个性化搜索、智能客服、欺诈检测等具体场景。
目前数据库本身又具备很强的通用性,市场空间足够大,在云与智能时代,传统结构化数据库已经无力支撑很多新兴负载,企业如果继续按照原有的技术路线,在时间和成本上的消耗将非常之高,这给了细分领域数据库新的发展机会。
2019年,Zilliz公司开源了向量数据库Milvus,2020年项目加入Linux基金会旗下LF AI&Data基金会进行孵化,2021年毕业成为顶级项目。截至目前,Milvus已经积累了上千家企业用户使用,为其在数据库领域的持续探索指引了方向。
“大公司往往有足够多的用户生态和资源投入去实现这一点,但创业公司不行。技术创业者最怕的就是拿着锤子找钉子,开源的一个核心目的就是要找到PMF,快速获得用户反馈,让企业快速跨越从技术到产品的鸿沟,然后再推动产品迭代。”星爵表示。
开源虽然改变了数据库领域,提升了软件商业的天花板,但如果只靠开源,只有少数企业才能盈利。一家商业公司做开源数据库,是不会为了开源而开源。
星爵看的是,开源商业化在北美地区已经有很长的历史,在之外的地区,市场的担心和顾虑是存在的,仅在过去两三年有很大的改变,尤其在中国,市场和投资人的热情非常高涨,“但稍微有点过热了。因为开源不是万能钥匙,不是说开源就一定会成功。”
中国开源软件的起步是比较晚的,且基础也比较薄弱,例如在开源治理方面包括法规、合规性、开源运营的效率和方法论,这导致开源精神在开发者群体中的渗透,并没有一个很深刻的土壤。开源精神植入人心,需要时间沉淀。
“开源应该是是帮助企业运营者更自然地获客、获得用户反馈,然后自然而然就能实现商业化。”
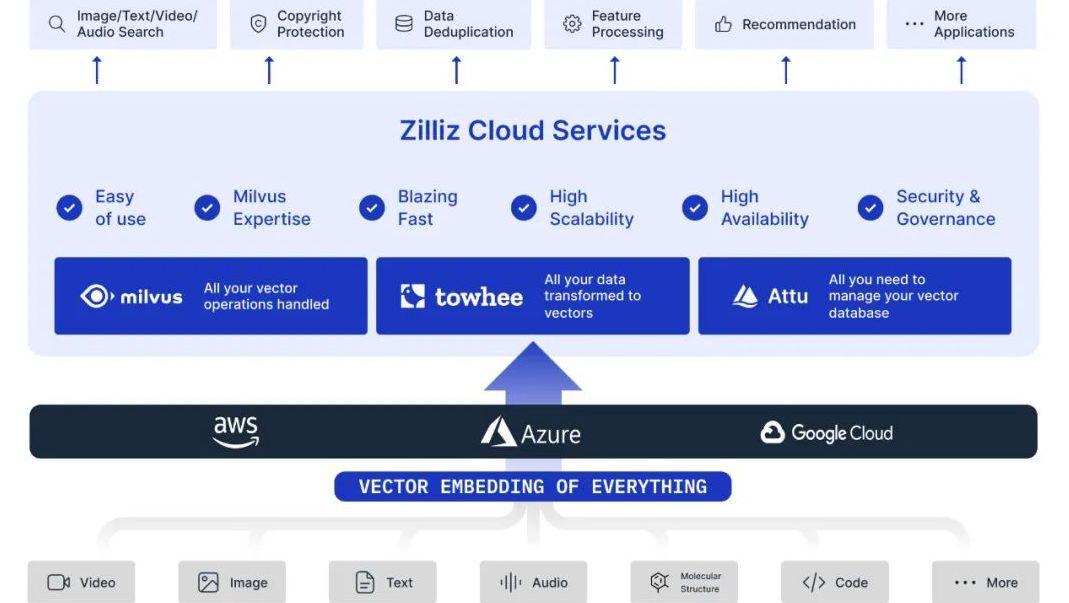
Zilliz cloud架构图
Zilliz的思路是,先找到PMF,与潜在的客户市场建立联系,然后基于云建立起全托管的数据库服务,为客户提供一整套的服务体系,从而获得相应的商业收益。不过,由于Milvus开源项目带来了很多海外目标用户,这也让Zilliz结合环境和市场需求后决定将商业化路径面向出海。2022年8月,Zilliz 首先面向海外市场推出了云端全托管向量数据库服务 Zilliz Cloud。
开源、做云、出海……这不仅是Zilliz的选择,也是目前国内数据库领域创业团队面临中国本土环境下的相似路径。从最终结果来讲,无论是哪种选择,都会为企业在技术社区的凝聚力和市场价值层面带来一些回馈。
(本文首发钛媒体APP 作者 | 杨丽)
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号