字节开源的 sonic-cpp:C++ JSON 库性能提升 2.5 倍!
发表时间: 2022-12-09 14:09
sonic-cpp 是由字节跳动 STE 团队和服务框架团队共同研发的一款面向 C++ 语言的高效 JSON 库,极致地利用当前 CPU 硬件特性与向量化编程,大幅提高了序列化反序列化性能,解析性能为 rapidjson 的 2.5 倍。sonic-cpp 在字节内部上线以来, 已为抖音、今日头条等核心业务,累计节省了数十万 CPU 核心。近日,我们正式对外开源 sonic-cpp,希望能够帮助更多开发者。
Github 地址:
https://github.com/bytedance/sonic-cpp
在字节跳动,有大量的业务需要用到 JSON 解析和增删查改,占用的 CPU 核心数非常大,所对应的物理机器成本较高,在某些单体服务上JSON CPU 占比甚至超过 40%。因此,提升 JSON 库的性能对于字节跳动业务的成本优化至关重要。同时,JSON 解析库几经更新,目前业界广泛使用的 rapidjson 虽然在性能上有了很大的改进,但相较于近期一些新的库(如 yyjson 和 simdjson),在解析性能方面仍有一定的劣势。
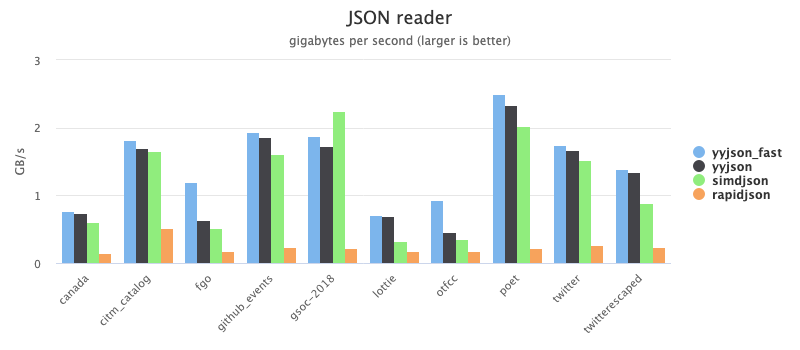
图 1.1 yyjson、simdjson 和 rapidjson 解析性能对比https://github.com/ibireme/yyjson
yyjson 和 simdjson 虽然有更快的 JSON 解析速度,但是都有各自的缺点。simdjson 不支持修改解析后的 JSON 结构,在实际业务中无法落地。yyjson 为了追求解析性能,使用链表结构,导致查找数据时性能非常差。
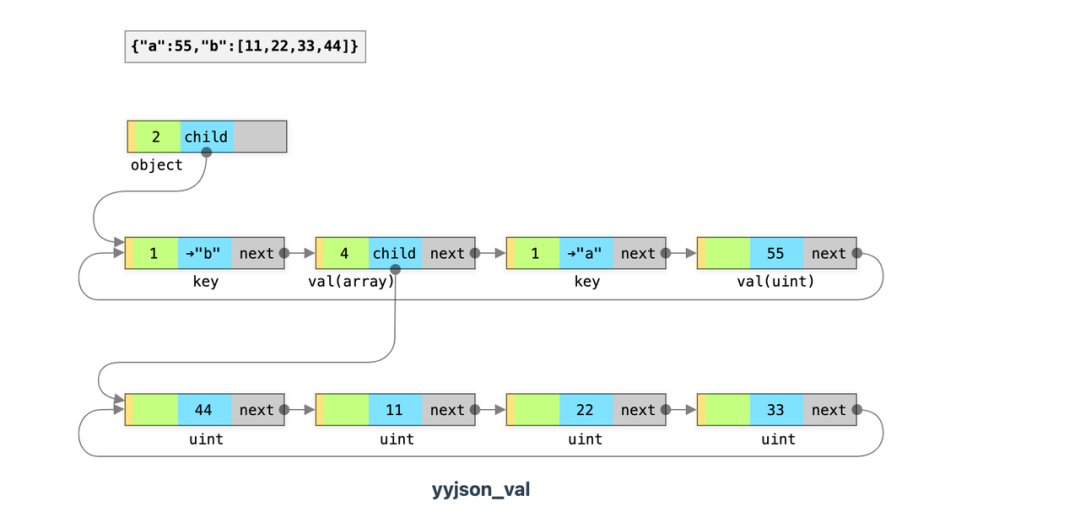
图1.2 yyjson 数据结构;图片来源自:https://github.com/ibireme/yyjson
基于上述原因,为了降低物理成本、优化性能,同时利用字节跳动已开源 GoJSON 解析库 sonic-go 的经验和部分思路,STE 团队和服务框架团队合作自研了一个适用于 C/C++ 服务的 JSON 解析库 sonic-cpp。
sonic-cpp 主要具备以下特性:
sonic-cpp 在设计上整合了 rapidjson ,yyjson 和 simdjson 三者的优点,并在此基础上做进一步的优化。在实现的过程中,我们主要通过充分利用向量化(SIMD)指令、优化内存布局和按需解析等关键技术,使得序列化、反序列化和增删改查能达到极致的性能。
2.1 向量化优化(SIMD)
单指令流多数据流(Single Instruction Multiple Data,缩写:SIMD)是一种采用一个控制器来控制多个处理器,同时对一组数据中的每一个数据分别执行相同的操作,从而实现空间上的并行性技术。例如 X86 的 SSE 或者 AVX2 指令集,以及 ARM 的 NEON 指令集等。sonic-cpp 的核心优化之一,正是通过利用 SIMD 指令集来实现的。
2.1.1序列化优化
从DOM内存表示序列化到文件的过程中,一个非常重要的过程是做字符串的转义,比如在引号前面添加转义符\。比如,把This is "a" string 序列化成 "This is \"a\" string" ,存放在文件。常见的实现是逐个字符扫描,添加转义。
比如 cJson 的实现:https://github.com/DaveGamble/cJSON/blob/master/cJSON.c#L902

sonic-cpp 则通过五条向量化指令,一次处理 32 个字符,极大地提高了性能。

序列化过程如下:
但如果没有 AVX512 的 load mask 指令集,在尾部最后一次读取 32 字节时,有可能发生内存越界,进而引起诸如 coredump 等问题。sonic-cpp 的处理方式是利用 Linux 的内存分配以页为单位的机制,通过检查所要读取的内存是否跨页来解决。只要不跨页,我们认为就算越界也是安全的。如果跨页了,则按保守的方式处理,保证正确性,极大地提高了序列化的效率。
具体实现见 sonic-cpp 实现:https://github.com/bytedance/sonic-cpp/blob/master/include/sonic/internal/quote.h#L256
2.1.2反序列化优化
在 JSON 的反序列化过程中,同样有个非常重要的步骤是解析数值,它对解析的性能至关重要。比如把字符串"12.456789012345" 解析成浮点数 12.456789012345。常见的实现基本上是逐个字符解析。见 Rapidjson 的实现 :
https://github.com/Tencent/rapidjson/blob/v1.1.0/include/rapidjson/reader.h#L1133
sonic-cpp 同样采用 SIMD 指令做浮点数的解析,实现方式如下图所示。
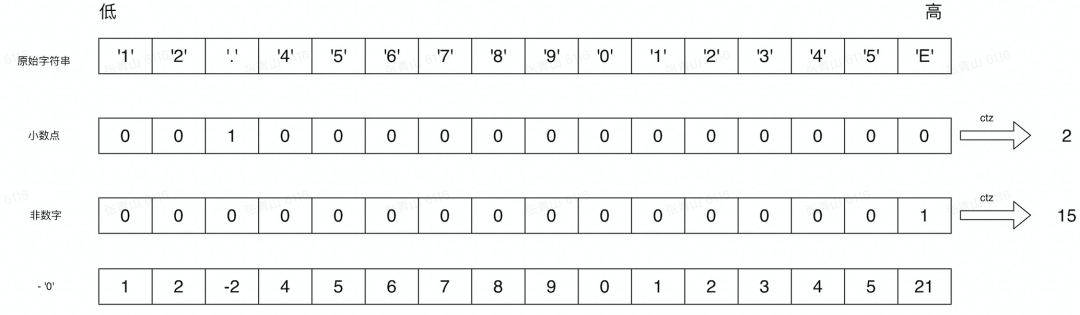

和序列化向量化类似,通过同样的向量指令得到小数点和结束符的位置,再把原始字符串通过向量减法指令,减去'0', 就得到真实数值。
当我们确定了小数点和结束符的位置,以及向量寄存器中存放的 16 个原始数值,通过乘加指令把他们拼成最终的 12456789012345和指数 12。
针对不同长度的浮点数做 benchmark 测试,可以看到解析性能提升明显。
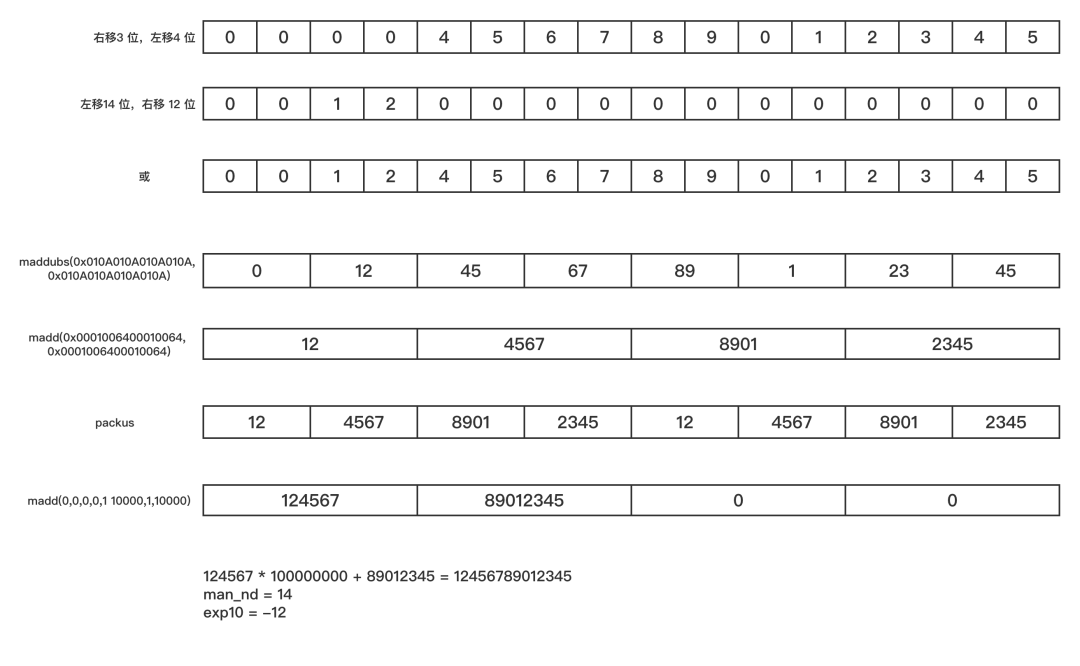
但我们发现,在字符串长度相对比较小(少于 4 个)的情况下,向量化性能反而是劣化的,因为此时数据短,标量计算并不会有多大劣势,而向量化反而需要乘加这类的重计算指令。
通过分析字节跳动内部使用 JSON 的特征,我们发现有大量少于 4 位数的短整数,同时我们认为,浮点数位数比较长的一般是小数部分,所以我们对该方法做进一步改进,整数部分通过标量方法循环读取解析,而小数部分通过上述向量化方法加速处理,取得了非常好的效果。流程如下,具体实现见sonic-cpp ParseNumber 实现
:https://github.com/bytedance/sonic-cpp/blob/master/include/sonic/dom/parser.h#L382
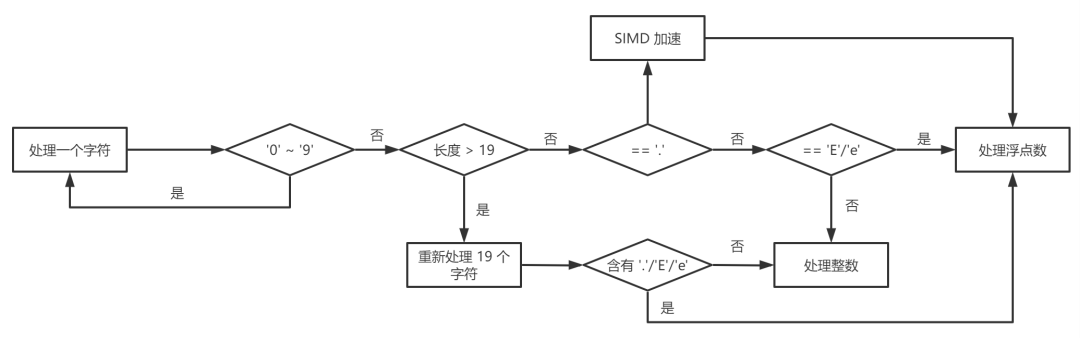
2.2 按需解析
在部分业务场景中,用户往往只需要 JSON 中的少数目标字段,此时,全量解析整个 JSON 是不必要的。为此,sonic-cpp 中实现了高性能的按需解析接口,能根据给定的 JsonPointer(目标字段的在 JSON 中的路径表示) 解析 JSON 中的目标字段。在按需解析时,由于JSON 较大,核心操作往往是如何跳过不必要的字段。如下:

2.2.1 传统实现
JSON 是一种半结构化数据,往往有嵌套 object 和 array。目前,实现按需解析主要有两种方法:递归下降法和两阶段处理。递归下降法,需要递归下降地“解析”整个 JSON,跳过所有不需要的 JSON 字段,该方法整体实现分支过多,性能较差;两阶段处理需要在阶段一标记整个 JSON token 结构的位置,例如,}]等,在阶段二再根据 token 位置信息,线性地跳过不需要的 JSON 字段,如按需查找的字段在 JSON 中的位置靠前时,该方法性能较差。
2.2.2 sonic-cpp 实现
sonic-cpp 基于 SIMD 实现了高性能的单阶段的按需解析。在按需解析过程中,核心操作在于如何跳过不需要的 JSON object 或 array。sonic-cpp 充分利用了完整的 JSON object 中 左括号数量必定等于右括号数量这一特性,利用 SIMD 读取 64 字节的 JSON 字段,得到左右括号的 bitmap。进一步,计算 object 中左括号和右括号的数量,最后通过比较左右括号数量来确定 object 结束位置。具体操作如下:
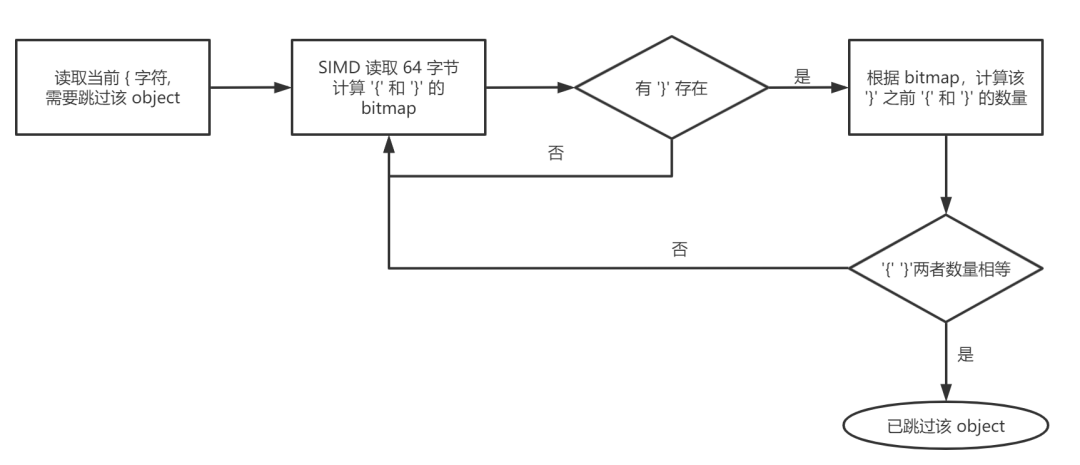
经过全场景测试,sonic-cpp 的按需解析明显好于已有的实现。性能测试结果如下图。其中,rapidjson-sax 是基于 rapidjson 的 SAX 接口实现的,使用递归下降法实现的按需解析。simdjson 的按需解析则是基于两阶段处理的方式实现。Normal,Fronter,NotFoud 则分别表示,按需解析时,目标字段 在 JSON 中的位置居中,靠前或不存在。不过,使用 sonic-cpp 和 simdjson 的按需解析时,都需要保证输入的 JSON 是正确合法的。
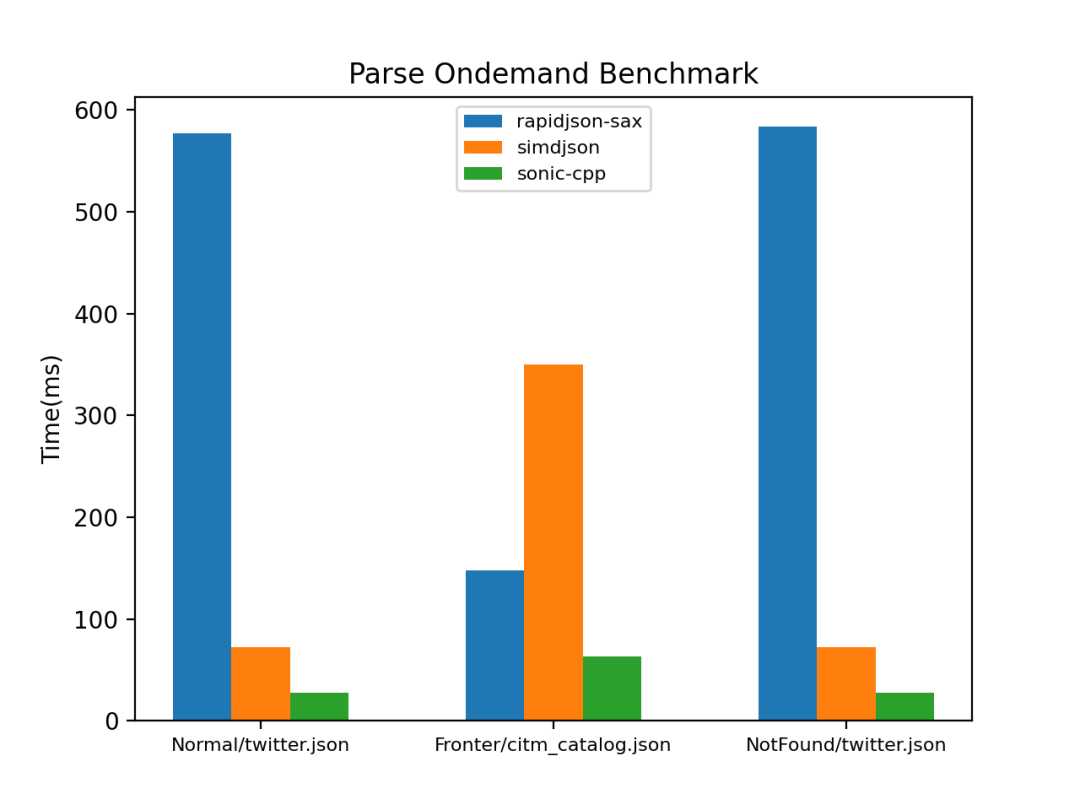
2.2.3 按需解析扩展
sonic-cpp 利用 SIMD 前向扫描,实现了高效的按需解析。在字节跳动内部,这一技术还可以应用于两个 JSON 的合并操作。在合并 JSON 时,通常需要先解析两个 JSON,合并之后,再反序列化。但是,如果两个 JSON 中需要合并的字段较少,就可以使用按需解析思想,先将各个字段的值解析为 raw JSON 格式,然后再进行合并操作。这样,能极大地减少 JSON 合并过程中的解析和序列化开销。
2.3 DOM 设计优化
2.3.1节点设计
在 sonic-cpp 中,表示一个 JSON value 的类被称作 node。node 采用常见的方法,将类型和 size 的信息合为一个,只使用 8 字节,减少内存的使用。对于每个 node,内存上只需要 16 字节,布局更紧凑,具体结构如下:

2.3.2DOM树设计
sonic-cpp 的 DOM 数据结构采用类似于 rapidjson 的实现,可以对包括 array 或 object 在内的所有节点进行增删查改。
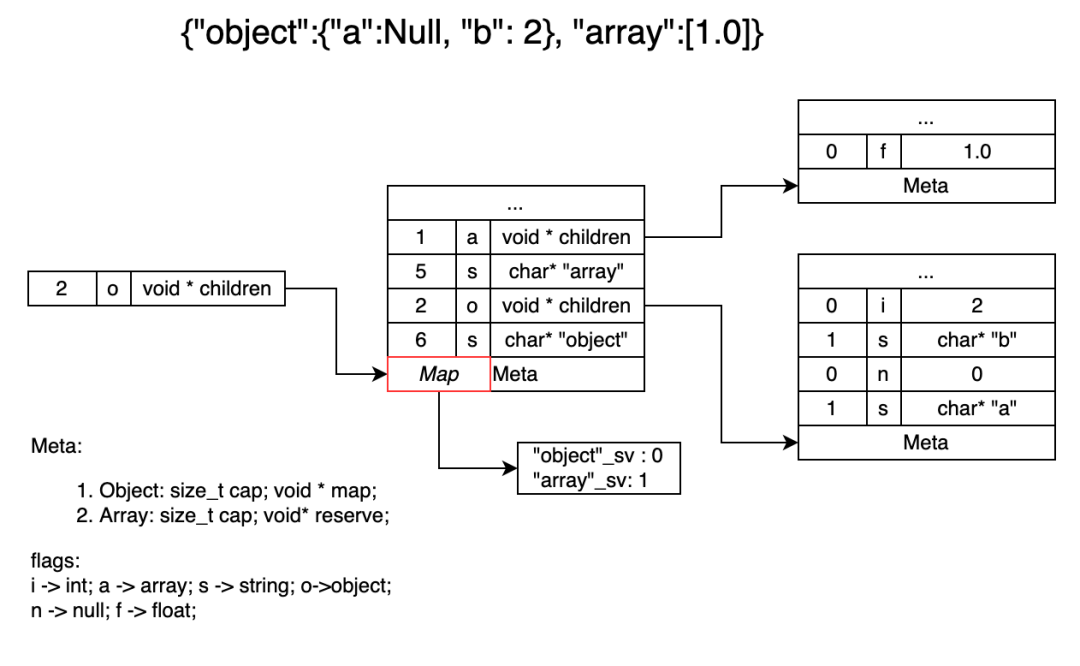
在 DOM 的设计上,sonic-cpp 把 object 和 array 的成员以数组方式组织,保证其在内存上的连续。数组方式让 sonic-cpp 随机访问 array 成员的效率更高。而对于 object,sonic-cpp 为其在 meta 数据中保存一个 map。map 里保存了 key 和 value 对应的 index。通过这个 map,查找的复杂度由 O(N) 降到 O(logN)。sonic-cpp 为这个 map 做了一定的优化处理:
2.3.3内存池
sonic-cpp 提供的内存分配器默认使用内存池进行内存分配。该分配器来自 rapidjson。使用内存池有以下几个好处:
Object 内建的 map 也使用了内存池分配内存,使得内存可以统一分配和释放。
在支持高效的增删改查的基础上,性能和 simdjson、yyjson 可比。
3.1 不同 JSON 库性能对比
基准测试是在
https://github.com/miloyip/nativejson-benchmark 的基础上支持 sonic-cpp 和 yyjson,测试得到。
反序列化(Parse)性能基准测试结果:
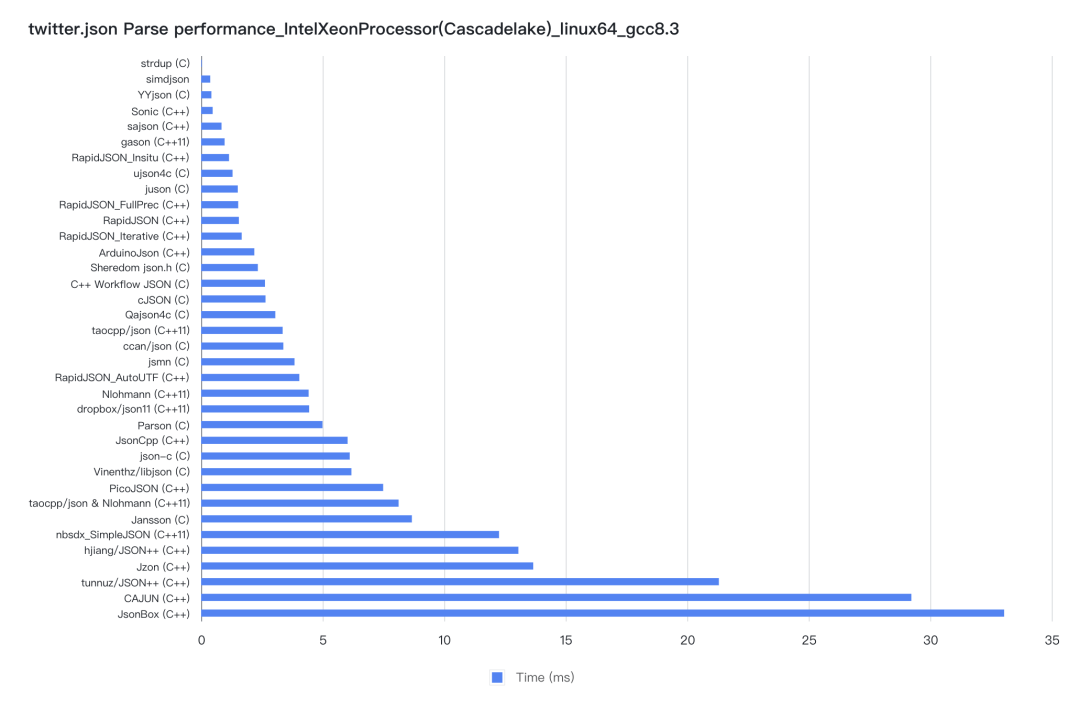
序列化(Stringify)性能基准测试结果:
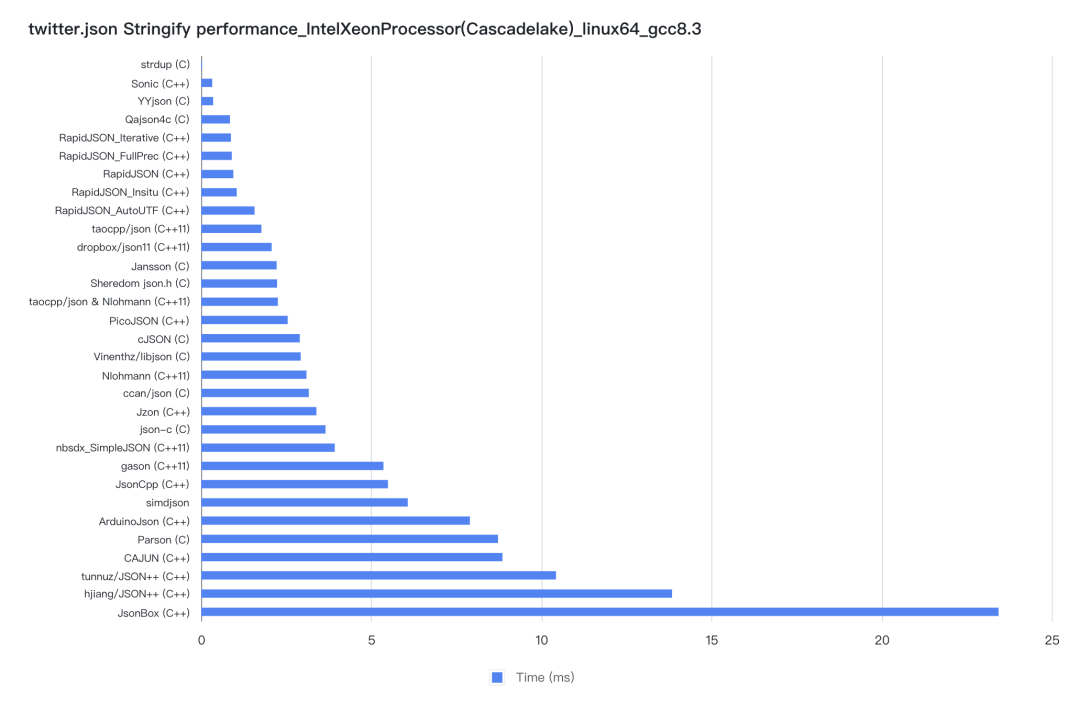
3.2 不同场景性能对比
sonic-cpp 与 rapidjson,simdjson 和 yyjson 之间在不同场景的性能对比(HIB: Higher is better)。
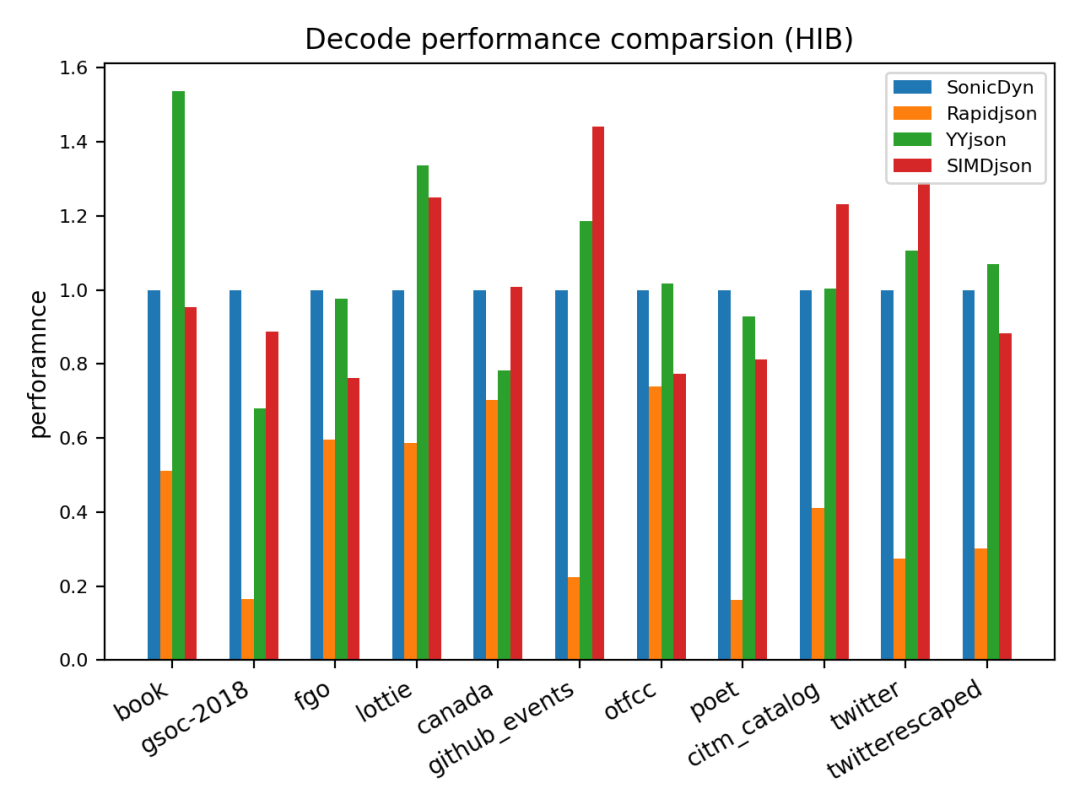
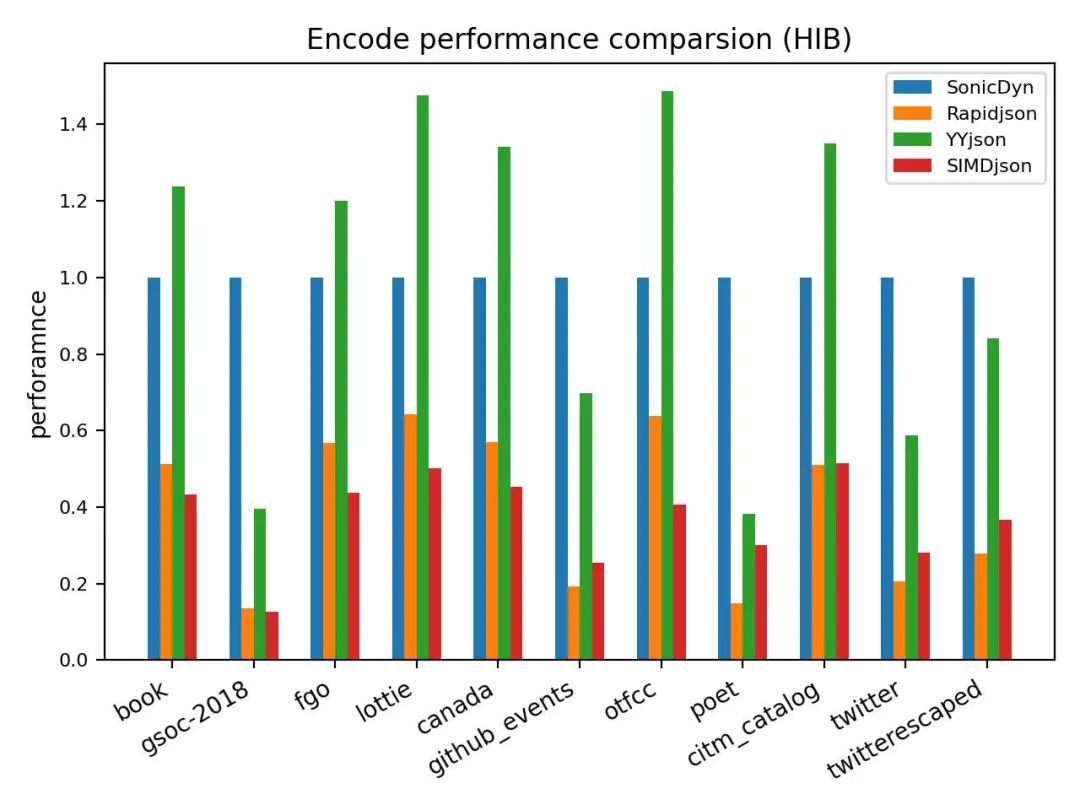
3.3 生产环境中性能对比
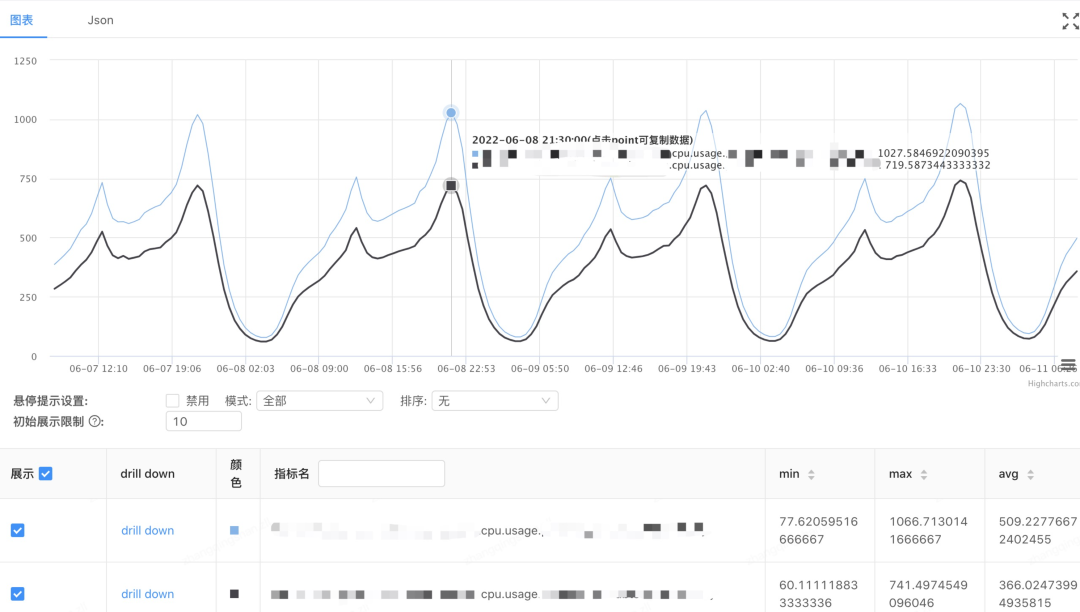
在实际生产环境中,sonic-cpp 的性能优势也得到了非常好的验证,下面是字节跳动抖音某个服务使用 sonic-cpp 在高峰段 CPU 前后的对比。
sonic-cpp 当前仅支持 amd64 架构,后续会逐步扩展到 ARM 等其它架构。同时,我们将积极地支持 JSON 相关 RFC 的特性,比如,支持社区的 JSON 合并相关的 RFC 7386,依据 RFC 8259 设计 JSON Path 来实现更便捷的 JSON 访问操作等。
欢迎开发者们加入进来贡献 PR,一起打造业界更好的 C/C++ JSON 库!
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号