【锐捷乐享】新手运维如何快速提升为专家,只需一个“它”!
发表时间: 2023-09-14 19:04
许多朋友都想知道,作为一名新入职的运维工程师,需要掌握哪些技能才能迅速上手工作?随着市场对运维工程师的要求不断提高,知识领域需要全面,包括网络、数据库、操作系统和编程语言等。为了应对突发情况,运维工程师需要24小时待命,没有时间休息,更不用说提升自己了。因此,我今天要向大家介绍一个非常实用的工具——锐捷乐享运维平台。即使你是一名新手,也能通过这个平台高效地进行运维工作。

首先,我们需要了解作为一名运维工程师需要做哪些工作。



第一,是预防,通过日常运维巡检来预防安全隐患。

第二,是响应,及时发现并响应服务故障。
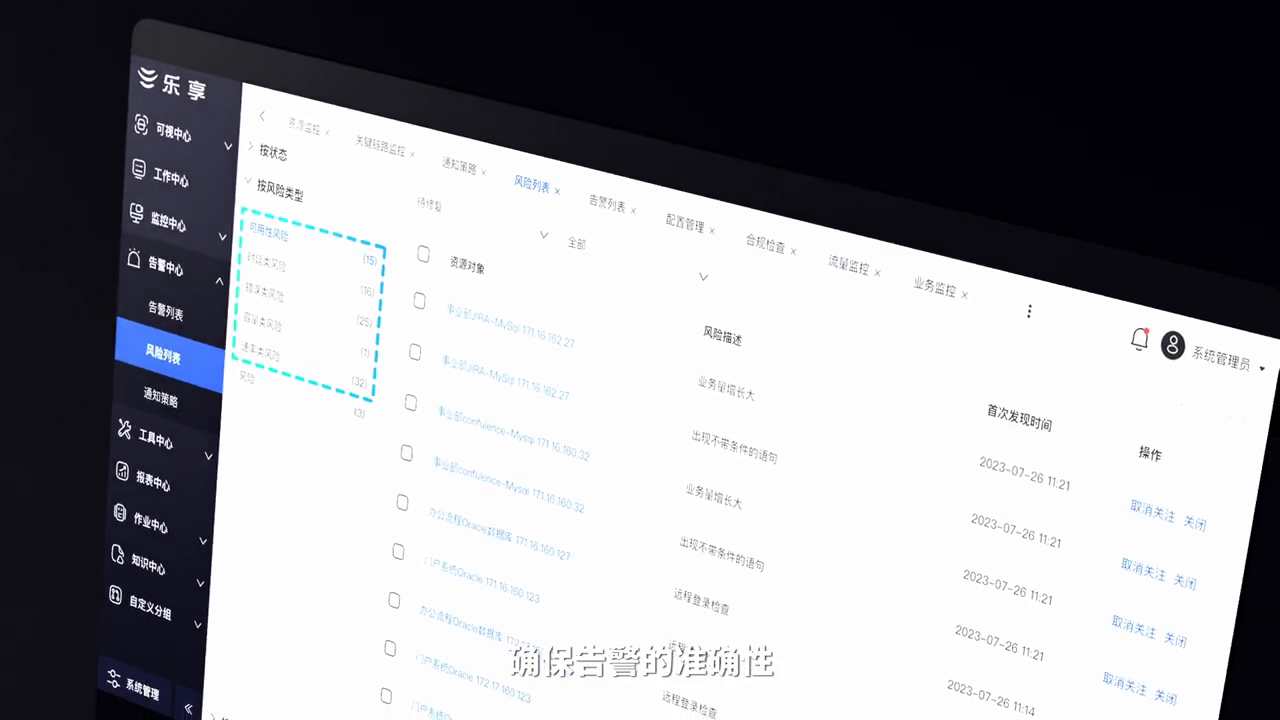
我们先从日常巡检入手。日常巡检耗时、耗力,主要问题是我们应用的一些平台虽然有监控功能,但里面只有自己的产品,甚至想要监控一些操作系统还需要自研一个平台,我们的巡检过程就需要在不同平台中来回穿梭检查。而使用“锐捷乐享运维平台”,只需点击按键,它就会直接输出健康检查报告。通过健康雷达图,我们可以直观地看到整体网络运行状态。

值得一提的是,这份报告中需要重点关注“未恢复的告警”和“重要风险隐患”。未恢复的告警是指已经发生的故障但还没有解决,重要风险隐患是可能会发生且需要关注的风险点。此外,它还会给出对应的处理建议。
那么,如何实现这些功能呢?
实际上,需要在监控层面足够全才可能达到快速检查的目的。
锐捷乐享平台监控有多全?它涵盖了网络设备、安全设备、负载、均衡、操作系统、中间件、数据库、虚拟化平台、物理服务器等企事业单位运营过程中设计到的IT资源类别。通过底层的模型工具,还可以快速构建新设备型号的监控模型。
拥有这些就相当于你拥有了全面监控的基础。下一个思考的问题就是,到底应该监控哪些指标才能快速响应并服务故障?在这种庞大的数据下,传统监控方案给出的指标太多太杂,哪些要做报警?哪些要做巡检往往分不清楚,而且很容易出现告警风暴。就像在常用的OA系统出现卡慢时,传统运维监控方案通常会建议系统工程师通过关注OA服务器的CPU内存,OA所在的数据库的DBtime表空间大小等基础指标来判断OA系统是否出现异常。这就像胃痛去医院检查。
医生给出了一个数据表,但我还是不知道胃为什么会痛。
在选取什么指标这件事上,其实Google已经针对大量的分布式监控经验做出总结。
本文介绍了4个黄金指标,可以帮助衡量终端用户体验、服务中断、业务影响等方面的问题,包括延迟、服务一个请求所需的时间。这些指标已成为中国头部互联网企业(如阿里、腾讯、美团)评估IT资源运行好坏的标准。乐享参考学习并基于最佳实践,建立了以5个黄金指标为基础的异常评估体系,确保告警的准确性。如何应用这些指标呢?以OA卡慢的问题为例,我们可以按照以下步骤进行排查:
1. 可用性检查:首先要确保OA系统是否可用,检查服务器网络和硬件是否正常工作。如果发现问题,就要进一步检查硬件。
2. 错误率分析:如果系统可用,可以通过检查错误日志来定位问题。检查服务器日志中是否有异常或错误,如果发现特定错误可以进一步跟踪解决。
3. 可视分析:如果系统响应缓慢,可以分析时延测量不同组件的响应时间,包括数据库查询API调用等,找出造成延迟的部分。例如数据库查询缓慢可以优化查询。
4. 速率测量:可以通过测量系统的处理能力,找出可能的瓶颈。如果处理请求的速度下降,可能是CPU内存或其他资源瓶颈,可以考虑增加资源或优化代码来提高吞吐量。
5. 容量评估:最后可以评估系统的容量,确保没有资源过载。检查CPU、内存、硬盘等资源的使用情况,如果发现某些资源使用过高,可以考虑扩展或优化资源。
这些信息对于经验丰富的老手来说当然很明确,但对于运维小白来说也不会慌。乐享特别建立了专家经验库,汇集了行业客户频发的各类it资源故障实例,还收集了各领域专家的处理建议。老师傅们可以在系统里面把处理的建议沉淀起来,避免小白发现问题只能靠问,实现了从风险识别到分析再到处置,建议完美闭环。
今天的干货就分享到这里了,如果觉得视频对运营工作有帮助,希望能够点击一键三连。如果大家有兴趣还可以点击下方的链接申请试用,我们下期见。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号