微软蓝屏技术故障背后的启示:如何提升系统架构的可用性?
发表时间: 2024-07-27 18:06
随着现代技术系统的日益复杂,像CrowdStrike事件这样的重大软件更新故障可能会带来广泛而深远的影响。根据微软企业和操作系统安全副总裁David Weston的声明,大约850万台Windows设备受到了CrowdStrike更新故障的影响,这一事件不仅揭示了技术系统之间的紧密联系,也强调了在关键时刻保持系统可用性的必要性。为了防止类似事件的再次发生,本文将探讨如何在系统架构中实现高可用性和容错能力,如何设计渐进式更新策略以减少更新故障的影响,以及如何在软件更新过程中引入更多的安全检查和验证机制。

一 系统架构的高可用性与容错能力
1高可用性的定义
高可用性(High Availability, HA)是指系统在任何时间都能正常运行并提供服务的能力。对于企业来说,高可用性是确保业务连续性和用户满意度的关键。实现高可用性通常涉及到冗余设计、负载均衡、自动故障切换和容灾备份等技术手段。
2实现高可用性的方法
冗余设计:
硬件冗余:通过多台服务器、多条网络路径和多台存储设备等硬件冗余来防止单点故障。这意味着在关键组件出现故障时,系统能够无缝切换到备用组件,确保服务不间断。例如,数据中心可以部署双机热备方案,一台服务器故障时,备用服务器可以立即接管任务。
软件冗余:在软件层面实现冗余,可以通过多实例和多副本来实现。例如,数据库可以通过主从复制的方式在多台服务器上运行,确保在主数据库故障时,从数据库可以接管。
负载均衡:
负载均衡器通过分配流量到不同的服务器实例上,提高系统的可靠性和性能。当一台服务器出现问题时,负载均衡器会自动将流量切换到其他健康的服务器上,避免单个服务器的故障影响整个系统的可用性。负载均衡可以是硬件级的(如F5、Cisco等)或软件级的(如Nginx、HAProxy等)。
自动故障切换:
自动故障切换机制能够迅速切换到备用组件,当系统检测到某个组件出现故障时,系统可以自动启动备用组件来保持服务的持续性。例如,许多云服务提供商提供自动故障转移的功能,当某个实例不可用时,系统会自动将流量导向其他可用的实例。
容灾备份:
容灾备份是指在不同的地理位置部署数据中心,以确保在某个数据中心发生故障时,系统能够切换到其他数据中心继续提供服务。容灾方案通常包括数据实时备份、定期备份和备份数据的异地存储,确保数据的完整性和可恢复性。
3容错能力的定义
容错能力是指系统在发生部分故障时,仍能继续正常运行并提供服务的能力。实现容错能力需要从以下几个方面入手:
错误检测与隔离:
系统需要具备实时监控和错误检测的能力,能够迅速识别故障并隔离问题组件,以防止故障蔓延。例如,许多现代系统使用健康检查机制,定期监测服务的状态,发现异常后及时通知运维人员。
自我修复机制:
通过自动化工具和脚本,系统可以在检测到故障后自动修复问题,减少人工干预,提高响应速度。例如,Kubernetes的自愈机制可以自动重启失败的容器,确保服务的可用性。
弹性扩展能力:
系统架构应具备弹性扩展能力,能够根据负载情况动态增加或减少资源,以应对突发流量和故障恢复。弹性扩展不仅能应对流量高峰,还能有效利用资源,降低成本。
多层次防护:
在系统的各个层次(如网络层、应用层、数据层)都设置容错机制,以确保单个层次的故障不会影响整个系统的正常运行。例如,使用微服务架构可以将不同的服务模块解耦,确保某个模块的故障不会影响其他模块的运行。
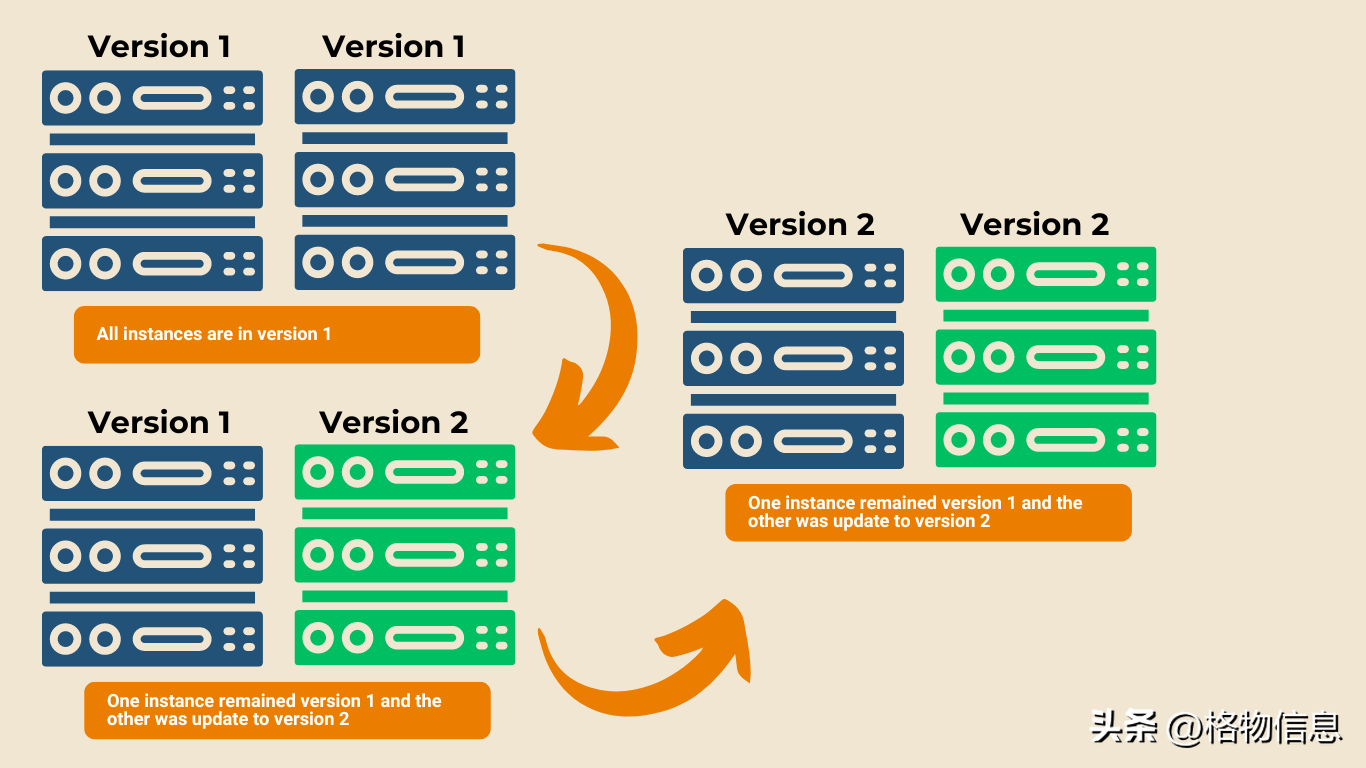
二 渐进式更新策略
渐进式更新策略(Rolling Update)是一种通过逐步推广更新来减少更新故障影响的方法。设计渐进式更新策略需要考虑以下几个方面:
1. 分批更新
将更新分成多个批次,先在小范围内进行测试和推广,确保更新稳定后再逐步扩大范围。这样可以在更新过程中及时发现和解决问题,减少对用户的影响。通过选择少量的用户或环境进行初始更新,可以更好地监测更新的效果并收集反馈。
2. 灰度发布
灰度发布是指在更新过程中,将新旧版本同时运行一段时间,并逐步增加新版本的流量占比,直到完全替换旧版本。通过灰度发布,可以在更新过程中进行充分验证,确保新版本的稳定性和兼容性。此外,灰度发布还可以帮助团队监测新版本对系统性能和用户体验的影响。
3. 自动化部署
使用自动化部署工具(如Jenkins、Ansible、Kubernetes等)来实现更新过程的自动化,减少人为操作带来的错误和风险。自动化部署工具可以帮助实现快速回滚、版本控制和多环境部署,提高更新效率和安全性。自动化流程还可以通过CI/CD管道进行集成,使得每次代码提交都经过一系列测试和验证后再部署到生产环境。
4. 监控与报警
在更新过程中,实时监控系统的运行状态和性能指标,及时发现异常情况并触发报警。通过监控和报警机制,可以在更新出现问题时迅速响应和处理,减少故障影响。现代监控工具(如Prometheus、Grafana等)能够提供实时数据监控,帮助运维人员更快地发现和定位问题。

三 安全检查与验证机制
在软件更新过程中引入更多的安全检查和验证机制,可以有效防止类似Bug再次出现。以下是一些关键措施:
1. 静态代码分析
通过静态代码分析工具(如SonarQube、Checkmarx等),在代码提交和合并前进行静态分析,发现潜在的安全漏洞和代码质量问题。静态代码分析可以在早期阶段捕获问题,从而降低后期修复的成本。
2. 单元测试与集成测试
编写充分的单元测试和集成测试用例,确保代码在提交前经过充分验证。自动化测试工具(如JUnit、TestNG、Selenium等)可以帮助提高测试覆盖率和效率。定期进行回归测试,确保新代码不会影响现有功能。
3. 安全扫描
在更新发布前,通过安全扫描工具(如Nessus、Qualys等)对系统进行全面的安全扫描,发现和修复潜在的安全漏洞。安全扫描可以帮助团队及时了解系统中的安全风险并进行处理。
4. 渗透测试
定期进行渗透测试,模拟攻击者行为,发现系统中的安全弱点和漏洞,并及时修复。渗透测试可以帮助企业识别潜在的安全威胁,提前采取防护措施。
5. 回归测试
在更新发布前,进行全面的回归测试,确保新版本不会引入新的问题或破坏已有功能。自动化测试工具可以帮助提高回归测试的效率和覆盖率。
6. 代码审查
在代码提交前,进行代码审查和同行评审,确保代码质量和安全性。代码审查工具(如Gerrit、Crucible等)可以帮助提高代码审查的效率和质量,确保每一行代码都经过充分验证。
7. 安全培训
对开发和运维团队进行安全培训,增强他们的安全意识和技能,确保在开发和部署过程中遵循安全最佳实践。定期的安全培训可以帮助团队及时了解最新的安全威胁和防护措施,提高整个团队的安全防范能力。
总结
通过全面优化系统架构、设计渐进式更新策略以及引入更多的安全检查和验证机制,企业能够有效提升系统的高可用性和容错能力,从而防范类似CrowdStrike事件引发的突发故障。实现高可用性和容错能力不仅需要从硬件、软件到管理层面进行全面考虑和部署,还需构建一个协同工作的生态系统,以应对各种可能出现的风险和问题。渐进式更新策略的设计使得系统在进行软件更新时,可以先在小范围内测试,确保功能的稳定性再逐步推广,降低了更新过程中可能带来的风险。同时,引入更严格的安全检查和验证机制,不仅能够及时识别和修复潜在的Bug,也能在更新前进行充分的评估,从而进一步提升系统的安全性和稳定性。通过综合运用这些措施,企业能够显著提高系统的可靠性,增强对突发故障的抵御能力,为业务持续运行提供有力保障。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号