揭秘Java锁:一篇文章带你全面了解
发表时间: 2019-12-19 19:46

作者 | cxuan
责编 | Elle
Java 中的锁有很多,可以按照不同的功能、种类进行分类,下面是我对 Java 中一些常用锁的分类,包括一些基本的概述
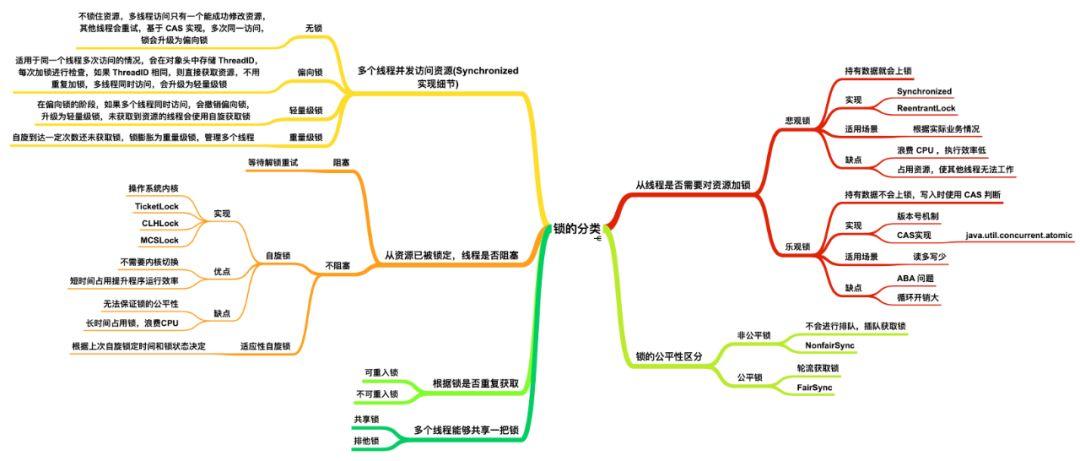
从线程是否需要对资源加锁可以分为 悲观锁 和 乐观锁
从资源已被锁定,线程是否阻塞可以分为 自旋锁
从多个线程并发访问资源,也就是 Synchronized 可以分为 无锁、偏向锁、 轻量级锁 和 重量级锁
从锁的公平性进行区分,可以分为公平锁 和 非公平锁
从根据锁是否重复获取可以分为 可重入锁 和 不可重入锁
从那个多个线程能否获取同一把锁分为 共享锁 和 排他锁
下面我们依次对各个锁的分类进行详细阐述。
Java 按照是否对资源加锁分为乐观锁和悲观锁,乐观锁和悲观锁并不是一种真实存在的锁,而是一种设计思想,乐观锁和悲观锁对于理解 Java 多线程和数据库来说至关重要,下面就来探讨一下这两种实现方式的区别和优缺点
悲观锁是一种悲观思想,它总认为最坏的情况可能会出现,它认为数据很可能会被其他人所修改,所以悲观锁在持有数据的时候总会把资源 或者 数据 锁住,这样其他线程想要请求这个资源的时候就会阻塞,直到等到悲观锁把资源释放为止。传统的关系型数据库里边就用到了很多这种锁机制,**比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。**悲观锁的实现往往依靠数据库本身的锁功能实现。
Java 中的 Synchronized 和 ReentrantLock 等独占锁(排他锁)也是一种悲观锁思想的实现,因为 Synchronzied 和 ReetrantLock 不管是否持有资源,它都会尝试去加锁,生怕自己心爱的宝贝被别人拿走。
乐观锁的思想与悲观锁的思想相反,它总认为资源和数据不会被别人所修改,所以读取不会上锁,但是乐观锁在进行写入操作的时候会判断当前数据是否被修改过(具体如何判断我们下面再说)。乐观锁的实现方案一般来说有两种:版本号机制 和 CAS实现 。乐观锁多适用于多读的应用类型,这样可以提高吞吐量。
在Java中
java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式 CAS 实现的。
上面介绍了两种锁的基本概念,并提到了两种锁的适用场景,一般来说,悲观锁不仅会对写操作加锁还会对读操作加锁,一个典型的悲观锁调用:
select * from student where name="cxuan" for update
这条 sql 语句从 Student 表中选取 name = "cxuan" 的记录并对其加锁,那么其他写操作再这个事务提交之前都不会对这条数据进行操作,起到了独占和排他的作用。
悲观锁因为对读写都加锁,所以它的性能比较低,对于现在互联网提倡的三高(高性能、高可用、高并发)来说,悲观锁的实现用的越来越少了,但是一般多读的情况下还是需要使用悲观锁的,因为虽然加锁的性能比较低,但是也阻止了像乐观锁一样,遇到写不一致的情况下一直重试的时间。
相对而言,乐观锁用于读多写少的情况,即很少发生冲突的场景,这样可以省去锁的开销,增加系统的吞吐量。
乐观锁的适用场景有很多,典型的比如说成本系统,柜员要对一笔金额做修改,为了保证数据的准确性和实效性,使用悲观锁锁住某个数据后,再遇到其他需要修改数据的操作,那么此操作就无法完成金额的修改,对产品来说是灾难性的一刻,使用乐观锁的版本号机制能够解决这个问题,我们下面说。
乐观锁一般有两种实现方式:采用版本号机制 和 CAS(Compare-and-Swap,即比较并替换)算法实现。
版本号机制是在数据表中加上一个 version 字段来实现的,表示数据被修改的次数,当执行写操作并且写入成功后,version = version + 1,当线程A要更新数据时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值为当前数据库中的version值相等时才更新,否则重试更新操作,直到更新成功。
我们以上面的金融系统为例,来简述一下这个过程。
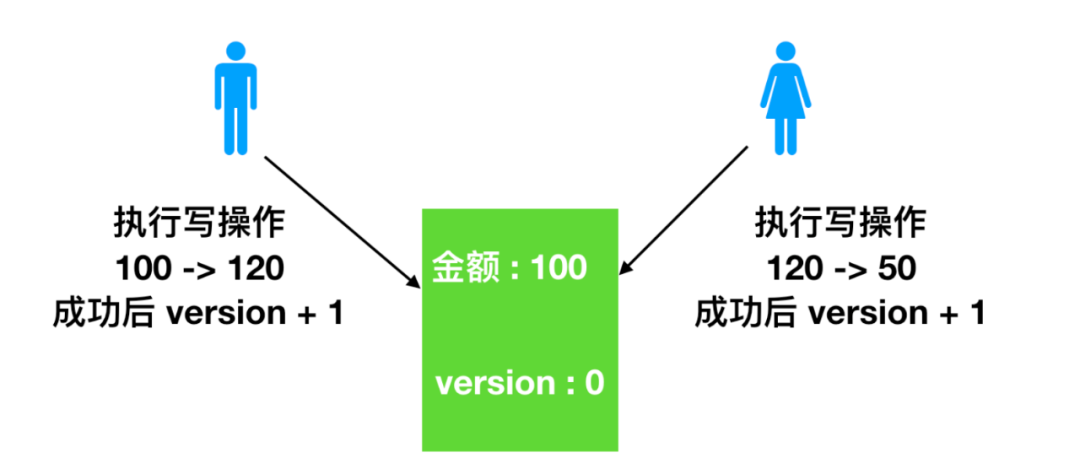
成本系统中有一个数据表,表中有两个字段分别是 金额 和 version,金额的属性是能够实时变化,而 version 表示的是金额每次发生变化的版本,一般的策略是,当金额发生改变时,version 采用递增的策略每次都在上一个版本号的基础上 + 1。
在了解了基本情况和基本信息之后,我们来看一下这个过程:公司收到回款后,需要把这笔钱放在金库中,假如金库中存有100 元钱
下面开启事务一:当男柜员执行回款写入操作前,他会先查看(读)一下金库中还有多少钱,此时读到金库中有 100 元,可以执行写操作,并把数据库中的钱更新为 120 元,提交事务,金库中的钱由 100 -> 120,version的版本号由 0 -> 1。
开启事务二:女柜员收到给员工发工资的请求后,需要先执行读请求,查看金库中的钱还有多少,此时的版本号是多少,然后从金库中取出员工的工资进行发放,提交事务,成功后版本 + 1,此时版本由 1 -> 2。
上面两种情况是最乐观的情况,上面的两个事务都是顺序执行的,也就是事务一和事务二互不干扰,那么事务要并行执行会如何呢?
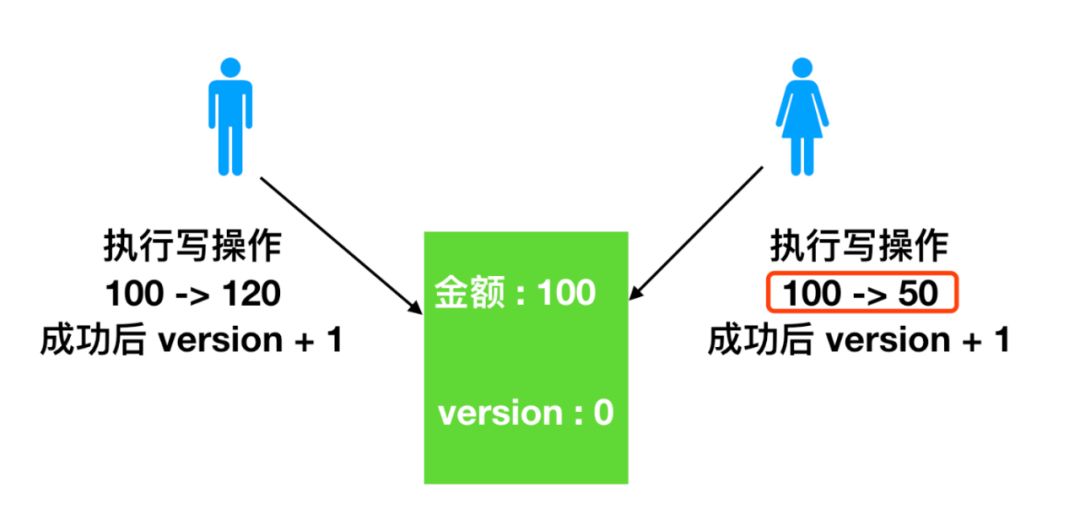
事务一开启,男柜员先执行读操作,取出金额和版本号,执行写操作
begin
update 表 set 金额 = 120,version = version + 1 where 金额 = 100 and version = 0
此时金额改为 120,版本号为1,事务还没有提交
事务二开启,女柜员先执行读操作,取出金额和版本号,执行写操作
begin
update 表 set 金额 = 50,version = version + 1 where 金额 = 100 and version = 0此时金额改为 50,版本号变为 1,事务未提交
现在提交事务一,金额改为 120,版本变为1,提交事务。理想情况下应该变为 金额 = 50,版本号 = 2,但是实际上事务二 的更新是建立在金额为 100 和 版本号为 0 的基础上的,所以事务二不会提交成功,应该重新读取金额和版本号,再次进行写操作。
这样,就避免了女柜员 用基于 version = 0 的旧数据修改的结果覆盖男操作员操作结果的可能。
begin
update 表 set 金额 = 120,version = version + 1 where 金额 = 100 and version = 0
begin
update 表 set 金额 = 120,version = version + 1 where 金额 = 100 and version = 0
begin
update 表 set 金额 = 120,version = version + 1 where 金额 = 100 and version = 0
省略代码,完整代码请参照 看完你就应该能明白的悲观锁和乐观锁
CAS 即 compare and swap(比较与交换),是一种有名的无锁算法。即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization
Java 从 JDK1.5 开始支持,java.util.concurrent 包里提供了很多面向并发编程的类,也提供了 CAS 算法的支持,一些以 Atomic 为开头的一些原子类都使用 CAS 作为其实现方式。使用这些类在多核 CPU 的机器上会有比较好的性能。
如果要保证它们的原子性,必须进行加锁,使用 Synchronzied 或者 ReentrantLock,我们前面介绍它们是悲观锁的实现,我们现在讨论的是乐观锁,那么用哪种方式保证它们的原子性呢?请继续往下看
CAS 中涉及三个要素:
需要读写的内存值 V
进行比较的值 A
拟写入的新值 B
当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
我们以 java.util.concurrent 中的AtomicInteger 为例,看一下在不用锁的情况下是如何保证线程安全的
public class AtomicCounter {
private AtomicInteger integer = new AtomicInteger;
public AtomicInteger getInteger {
return integer;
}
public voidsetInteger(AtomicInteger integer) {
this.integer = integer;
}
public voidincrement{
integer.incrementAndGet;
}
public voiddecrement{
integer.decrementAndGet;
}
}
public class AtomicProducer extendsThread{
private AtomicCounter atomicCounter;
publicAtomicProducer(AtomicCounter atomicCounter){
this.atomicCounter = atomicCounter;
}
@Override
public voidrun {
for(int j = 0; j < AtomicTest.LOOP; j++) {
System.out.println("producer : " + atomicCounter.getInteger);
atomicCounter.increment;
}
}
}
public class AtomicConsumer extendsThread{
private AtomicCounter atomicCounter;
publicAtomicConsumer(AtomicCounter atomicCounter){
this.atomicCounter = atomicCounter;
}
@Override
public voidrun {
for(int j = 0; j < AtomicTest.LOOP; j++) {
System.out.println("consumer : " + atomicCounter.getInteger);
atomicCounter.decrement;
}
}
}
public class AtomicTest {
final static int LOOP = 10000;
public static void main(String[] args) throws InterruptedException {
AtomicCounter counter = new AtomicCounter;
AtomicProducer producer = new AtomicProducer(counter);
AtomicConsumer consumer = new AtomicConsumer(counter);
producer.start;
consumer.start;
producer.join;
consumer.join;
System.out.println(counter.getInteger);
}
}
经测试可得,不管循环多少次最后的结果都是0,也就是多线程并行的情况下,使用 AtomicInteger 可以保证线程安全性。incrementAndGet 和 decrementAndGet 都是原子性操作。
任何事情都是有利也有弊,软件行业没有完美的解决方案只有最优的解决方案,所以乐观锁也有它的弱点和缺陷:
ABA 问题说的是,如果一个变量第一次读取的值是 A,准备好需要对 A 进行写操作的时候,发现值还是 A,那么这种情况下,能认为 A 的值没有被改变过吗?可以是由 A -> B -> A 的这种情况,但是 AtomicInteger 却不会这么认为,它只相信它看到的,它看到的是什么就是什么。
JDK 1.5 以后的 AtomicStampedReference类就提供了此种能力,其中的 compareAndSet 方法就是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
也可以采用CAS的一个变种DCAS来解决这个问题。DCAS,是对于每一个V增加一个引用的表示修改次数的标记符。对于每个V,如果引用修改了一次,这个计数器就加1。然后在这个变量需要update的时候,就同时检查变量的值和计数器的值。
我们知道乐观锁在进行写操作的时候会判断是否能够写入成功,如果写入不成功将触发等待 -> 重试机制,这种情况是一个自旋锁,简单来说就是适用于短期内获取不到,进行等待重试的锁,它不适用于长期获取不到锁的情况,另外,自旋循环对于性能开销比较大。
简单的来说 CAS 适用于写比较少的情况下(多读场景,冲突一般较少),synchronized 适用于写比较多的情况下(多写场景,冲突一般较多)
对于资源竞争较少(线程冲突较轻)的情况,使用 Synchronized 同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗 cpu 资源;而 CAS 基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
对于资源竞争严重(线程冲突严重)的情况,CAS 自旋的概率会比较大,从而浪费更多的 CPU 资源,效率低于 synchronized。
由于在多处理器环境中某些资源的有限性,有时需要互斥访问(mutual exclusion),这时候就需要引入锁的概念,只有获取了锁的线程才能够对资源进行访问,由于多线程的核心是CPU的时间分片,所以同一时刻只能有一个线程获取到锁。那么就面临一个问题,那么没有获取到锁的线程应该怎么办?
通常有两种处理方式:一种是没有获取到锁的线程就一直循环等待判断该资源是否已经释放锁,这种锁叫做自旋锁,它不用将线程阻塞起来(NON-BLOCKING);还有一种处理方式就是把自己阻塞起来,等待重新调度请求,这种叫做互斥锁。
自旋锁的定义:当一个线程尝试去获取某一把锁的时候,如果这个锁此时已经被别人获取(占用),那么此线程就无法获取到这把锁,该线程将会等待,间隔一段时间后会再次尝试获取。这种采用循环加锁 -> 等待的机制被称为自旋锁(spinlock)。
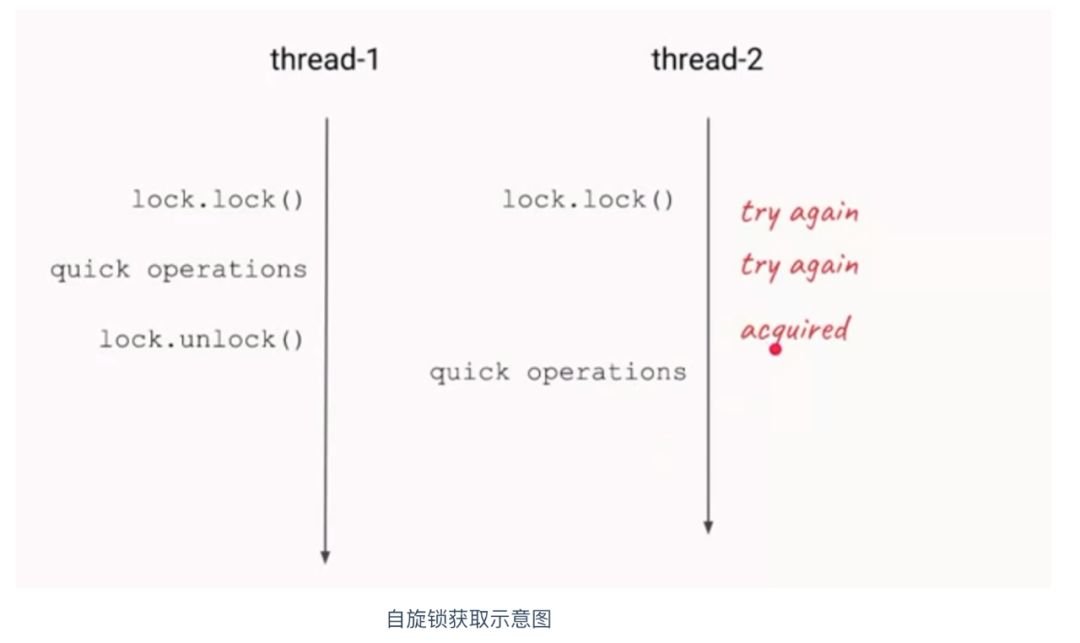
自旋锁的原理比较简单,如果持有锁的线程能在短时间内释放锁资源,那么那些等待竞争锁的线程就不需要做内核态和用户态之间的切换进入阻塞状态,它们只需要等一等(自旋),等到持有锁的线程释放锁之后即可获取,这样就避免了用户进程和内核切换的消耗。
因为自旋锁避免了操作系统进程调度和线程切换,所以自旋锁通常适用在时间比较短的情况下。由于这个原因,操作系统的内核经常使用自旋锁。但是,如果长时间上锁的话,自旋锁会非常耗费性能,它阻止了其他线程的运行和调度。线程持有锁的时间越长,则持有该锁的线程将被 OS(Operating System) 调度程序中断的风险越大。如果发生中断情况,那么其他线程将保持旋转状态(反复尝试获取锁),而持有该锁的线程并不打算释放锁,这样导致的是结果是无限期推迟,直到持有锁的线程可以完成并释放它为止。
解决上面这种情况一个很好的方式是给自旋锁设定一个自旋时间,等时间一到立即释放自旋锁。自旋锁的目的是占着CPU资源不进行释放,等到获取锁立即进行处理。但是如何去选择自旋时间呢?如果自旋执行时间太长,会有大量的线程处于自旋状态占用 CPU 资源,进而会影响整体系统的性能。因此自旋的周期选的额外重要!JDK在1.6 引入了适应性自旋锁,适应性自旋锁意味着自旋时间不是固定的了,而是由前一次在同一个锁上的自旋时间以及锁拥有的状态来决定,基本认为一个线程上下文切换的时间是最佳的一个时间。
自旋锁尽可能的减少线程的阻塞,这对于锁的竞争不激烈,且占用锁时间非常短的代码块来说性能能大幅度的提升,因为自旋的消耗会小于线程阻塞挂起再唤醒的操作的消耗,这些操作会导致线程发生两次上下文切换!
但是如果锁的竞争激烈,或者持有锁的线程需要长时间占用锁执行同步块,这时候就不适合使用自旋锁了,因为自旋锁在获取锁前一直都是占用 cpu 做无用功,占着 XX 不 XX,同时有大量线程在竞争一个锁,会导致获取锁的时间很长,线程自旋的消耗大于线程阻塞挂起操作的消耗,其它需要 cpu 的线程又不能获取到 cpu,造成 cpu 的浪费。所以这种情况下我们要关闭自旋锁。
下面我们用Java 代码来实现一个简单的自旋锁
public class SpinLockTest {
private AtomicBoolean available = new AtomicBoolean(false);
public voidlock{
// 循环检测尝试获取锁
while (!tryLock){
// doSomething...
}
}
public booleantryLock{
// 尝试获取锁,成功返回true,失败返回false
return available.compareAndSet(false,true);
}
public voidunLock{
if(!available.compareAndSet(true,false)){
throw new RuntimeException("释放锁失败");
}
}
}
这种简单的自旋锁有一个问题:无法保证多线程竞争的公平性。对于上面的 SpinlockTest,当多个线程想要获取锁时,谁最先将available设为false谁就能最先获得锁,这可能会造成某些线程一直都未获取到锁造成线程饥饿。就像我们下课后蜂拥的跑向食堂,下班后蜂拥地挤向地铁,通常我们会采取排队的方式解决这样的问题,类似地,我们把这种锁叫排队自旋锁(QueuedSpinlock)。计算机科学家们使用了各种方式来实现排队自旋锁,如TicketLock,MCSLock,CLHLock。接下来我们分别对这几种锁做个大致的介绍。
在计算机科学领域中,TicketLock 是一种同步机制或锁定算法,它是一种自旋锁,它使用ticket 来控制线程执行顺序。
就像票据队列管理系统一样。面包店或者服务机构(例如银行)都会使用这种方式来为每个先到达的顾客记录其到达的顺序,而不用每次都进行排队。通常,这种地点都会有一个分配器(叫号器,挂号器等等都行),先到的人需要在这个机器上取出自己现在排队的号码,这个号码是按照自增的顺序进行的,旁边还会有一个标牌显示的是正在服务的标志,这通常是代表目前正在服务的队列号,当前的号码完成服务后,标志牌会显示下一个号码可以去服务了。
像上面系统一样,TicketLock 是基于先进先出(FIFO) 队列的机制。它增加了锁的公平性,其设计原则如下:TicketLock 中有两个 int 类型的数值,开始都是0,第一个值是队列ticket(队列票据), 第二个值是 出队(票据)。队列票据是线程在队列中的位置,而出队票据是现在持有锁的票证的队列位置。可能有点模糊不清,简单来说,就是队列票据是你取票号的位置,出队票据是你距离叫号的位置。现在应该明白一些了吧。
当叫号叫到你的时候,不能有相同的号码同时办业务,必须只有一个人可以去办,办完后,叫号机叫到下一个人,这就叫做原子性。你在办业务的时候不能被其他人所干扰,而且不可能会有两个持有相同号码的人去同时办业务。然后,下一个人看自己的号是否和叫到的号码保持一致,如果一致的话,那么就轮到你去办业务,否则只能继续等待。上面这个流程的关键点在于,每个办业务的人在办完业务之后,他必须丢弃自己的号码,叫号机才能继续叫到下面的人,如果这个人没有丢弃这个号码,那么其他人只能继续等待。下面来实现一下这个票据排队方案
public class TicketLock {
// 队列票据(当前排队号码)
private AtomicInteger queueNum = new AtomicInteger;
// 出队票据(当前需等待号码)
private AtomicInteger dueueNum = new AtomicInteger;
// 获取锁:如果获取成功,返回当前线程的排队号
public int lock{
int currentTicketNum = dueueNum.incrementAndGet;
while (currentTicketNum != queueNum.get){
// doSomething...
}
return currentTicketNum;
}
// 释放锁:传入当前排队的号码
public void unLock(int ticketNum){
queueNum.compareAndSet(ticketNum,ticketNum + 1);
}
}
每次叫号机在叫号的时候,都会判断自己是不是被叫的号,并且每个人在办完业务的时候,叫号机根据在当前号码的基础上 + 1,让队列继续往前走。
但是上面这个设计是有问题的,因为获得自己的号码之后,是可以对号码进行更改的,这就造成系统紊乱,锁不能及时释放。这时候就需要有一个能确保每个人按会着自己号码排队办业务的角色,在得知这一点之后,我们重新设计一下这个逻辑
public class TicketLock2 {
// 队列票据(当前排队号码)
private AtomicInteger queueNum = new AtomicInteger;
// 出队票据(当前需等待号码)
private AtomicInteger dueueNum = new AtomicInteger;
private ThreadLocal<Integer> ticketLocal = new ThreadLocal<>;
public void lock{
int currentTicketNum = dueueNum.incrementAndGet;
// 获取锁的时候,将当前线程的排队号保存起来
ticketLocal.set(currentTicketNum);
while (currentTicketNum != queueNum.get){
// doSomething...
}
}
// 释放锁:从排队缓冲池中取
public void unLock{
Integer currentTicket = ticketLocal.get;
queueNum.compareAndSet(currentTicket,currentTicket + 1);
}
}
这次就不再需要返回值,办业务的时候,要将当前的这一个号码缓存起来,在办完业务后,需要释放缓存的这条票据。
缺点
TicketLock 虽然解决了公平性的问题,但是多处理器系统上,每个进程/线程占用的处理器都在读写同一个变量queueNum ,每次读写操作都必须在多个处理器缓存之间进行缓存同步,这会导致繁重的系统总线和内存的流量,大大降低系统整体的性能。
为了解决这个问题,MCSLock 和 CLHLock 应运而生。
上面说到TicketLock 是基于队列的,那么 CLHLock 就是基于链表设计的,CLH的发明人是:Craig,Landin and Hagersten,用它们各自的字母开头命名。CLH 是一种基于链表的可扩展,高性能,公平的自旋锁,申请线程只能在本地变量上自旋,它会不断轮询前驱的状态,如果发现前驱释放了锁就结束自旋。
public class CLHLock {
public static class CLHNode{
private volatile boolean isLocked = true;
}
// 尾部节点
private volatile CLHNode tail;
private static final ThreadLocal<CLHNode> LOCAL = new ThreadLocal<>;
private static final AtomicReferenceFieldUpdater<CLHLock,CLHNode> UPDATER =
AtomicReferenceFieldUpdater.newUpdater(CLHLock.class,CLHNode.class,"tail");
public void lock{
// 新建节点并将节点与当前线程保存起来
CLHNode node = new CLHNode;
LOCAL.set(node);
// 将新建的节点设置为尾部节点,并返回旧的节点(原子操作),这里旧的节点实际上就是当前节点的前驱节点
CLHNode preNode = UPDATER.getAndSet(this,node);
if(preNode != ){
// 前驱节点不为表示当锁被其他线程占用,通过不断轮询判断前驱节点的锁标志位等待前驱节点释放锁
while (preNode.isLocked){
}
preNode = ;
LOCAL.set(node);
}
// 如果不存在前驱节点,表示该锁没有被其他线程占用,则当前线程获得锁
}
public void unlock {
// 获取当前线程对应的节点
CLHNode node = LOCAL.get;
// 如果tail节点等于node,则将tail节点更新为,同时将node的lock状态职位false,表示当前线程释放了锁
if (!UPDATER.compareAndSet(this, node, )) {
node.isLocked = false;
}
node = ;
}
}
MCS Spinlock 是一种基于链表的可扩展、高性能、公平的自旋锁,申请线程只在本地变量上自旋,直接前驱负责通知其结束自旋,从而极大地减少了不必要的处理器缓存同步的次数,降低了总线和内存的开销。MCS 来自于其发明人名字的首字母:John Mellor-Crummey 和 Michael Scott。
public class MCSLock {
public static class MCSNode {
volatile MCSNode next;
volatile boolean isLocked = true;
}
private static final ThreadLocal<MCSNode> NODE = new ThreadLocal<>;
// 队列
@SuppressWarnings("unused")
private volatile MCSNode queue;
private static final AtomicReferenceFieldUpdater<MCSLock,MCSNode> UPDATE =
AtomicReferenceFieldUpdater.newUpdater(MCSLock.class,MCSNode.class,"queue");
public voidlock{
// 创建节点并保存到ThreadLocal中
MCSNode currentNode = new MCSNode;
NODE.set(currentNode);
// 将queue设置为当前节点,并且返回之前的节点
MCSNode preNode = UPDATE.getAndSet(this, currentNode);
if (preNode != ) {
// 如果之前节点不为,表示锁已经被其他线程持有
preNode.next = currentNode;
// 循环判断,直到当前节点的锁标志位为false
while (currentNode.isLocked) {
}
}
}
public voidunlock {
MCSNode currentNode = NODE.get;
// next为表示没有正在等待获取锁的线程
if (currentNode.next == ) {
// 更新状态并设置queue为
if (UPDATE.compareAndSet(this, currentNode, )) {
// 如果成功了,表示queue==currentNode,即当前节点后面没有节点了
return;
} else {
// 如果不成功,表示queue!=currentNode,即当前节点后面多了一个节点,表示有线程在等待
// 如果当前节点的后续节点为,则需要等待其不为(参考加锁方法)
while (currentNode.next == ) {
}
}
} else {
// 如果不为,表示有线程在等待获取锁,此时将等待线程对应的节点锁状态更新为false,同时将当前线程的后继节点设为
currentNode.next.isLocked = false;
currentNode.next = ;
}
}
}
都是基于链表,不同的是CLHLock是基于隐式链表,没有真正的后续节点属性,MCSLock是显示链表,有一个指向后续节点的属性。
将获取锁的线程状态借助节点(node)保存,每个线程都有一份独立的节点,这样就解决了TicketLock多处理器缓存同步的问题。

Java 语言专门针对 synchronized 关键字设置了四种状态,它们分别是:无锁、偏向锁、轻量级锁和重量级锁,但是在了解这些锁之前还需要先了解一下 Java 对象头和 Monitor。
我们知道 synchronized 是悲观锁,在操作同步之前需要给资源加锁,这把锁就是对象头里面的,而Java 对象头又是什么呢?我们以 Hotspot 虚拟机为例,Hopspot 对象头主要包括两部分数据:Mark Word(标记字段) 和 class Pointer(类型指针)。
Mark Word:默认存储对象的HashCode,分代年龄和锁标志位信息。这些信息都是与对象自身定义无关的数据,所以Mark Word被设计成一个非固定的数据结构以便在极小的空间内存存储尽量多的数据。它会根据对象的状态复用自己的存储空间,也就是说在运行期间Mark Word里存储的数据会随着锁标志位的变化而变化。
class Point:对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
在32位虚拟机和64位虚拟机的 Mark Word 所占用的字节大小不一样,32位虚拟机的 Mark Word 和 class Pointer 分别占用 32bits 的字节,而 64位虚拟机的 Mark Word 和 class Pointer 占用了64bits 的字节,下面我们以 32位虚拟机为例,来看一下其 Mark Word 的字节具体是如何分配的


用中文翻译过来就是
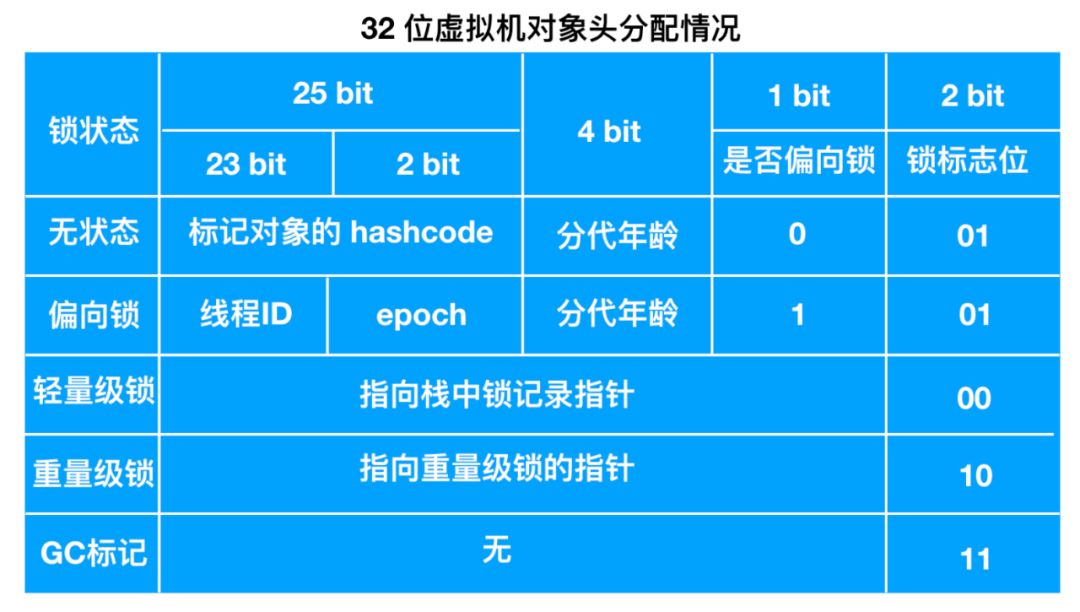
无状态也就是无锁的时候,对象头开辟 25bit 的空间用来存储对象的 hashcode ,4bit 用于存放分代年龄,1bit 用来存放是否偏向锁的标识位,2bit 用来存放锁标识位为01
偏向锁 中划分更细,还是开辟25bit 的空间,其中23bit 用来存放线程ID,2bit 用来存放 epoch,4bit 存放分代年龄,1bit 存放是否偏向锁标识, 0表示无锁,1表示偏向锁,锁的标识位还是01
轻量级锁中直接开辟 30bit 的空间存放指向栈中锁记录的指针,2bit 存放锁的标志位,其标志位为00
重量级锁中和轻量级锁一样,30bit 的空间用来存放指向重量级锁的指针,2bit 存放锁的标识位,为11
GC标记开辟30bit 的内存空间却没有占用,2bit 空间存放锁标志位为11。
其中无锁和偏向锁的锁标志位都是01,只是在前面的1bit区分了这是无锁状态还是偏向锁状态。
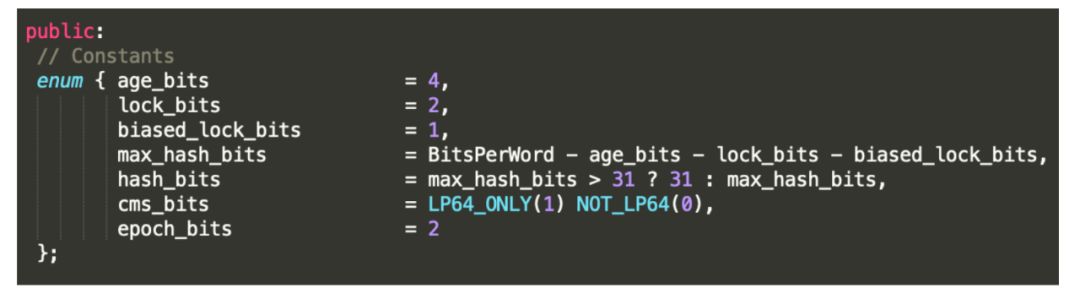
关于为什么这么分配的内存,我们可以从 OpenJDK 中的markOop.hpp类中的枚举窥出端倪
来解释一下
age_bits 就是我们说的分代回收的标识,占用4字节
lock_bits 是锁的标志位,占用2个字节
biased_lock_bits 是是否偏向锁的标识,占用1个字节
max_hash_bits 是针对无锁计算的hashcode 占用字节数量,如果是32位虚拟机,就是 32 - 4 - 2 -1 = 25 byte,如果是64 位虚拟机,64 - 4 - 2 - 1 = 57 byte,但是会有 25 字节未使用,所以64位的 hashcode 占用 31 byte
hash_bits 是针对 64 位虚拟机来说,如果最大字节数大于 31,则取31,否则取真实的字节数
cms_bits 我觉得应该是不是64位虚拟机就占用 0 byte,是64位就占用 1byte
epoch_bits 就是 epoch 所占用的字节大小,2字节。
synchronized用的锁是存在Java对象头里的。
JVM基于进入和退出 Monitor 对象来实现方法同步和代码块同步。代码块同步是使用 monitorenter 和 monitorexit 指令实现的,monitorenter 指令是在编译后插入到同步代码块的开始位置,而 monitorexit 是插入到方法结束处和异常处。任何对象都有一个 monitor 与之关联,当且一个 monitor 被持有后,它将处于锁定状态。
根据虚拟机规范的要求,在执行 monitorenter 指令时,首先要去尝试获取对象的锁,如果这个对象没被锁定,或者当前线程已经拥有了那个对象的锁,把锁的计数器加1,相应地,在执行 monitorexit 指令时会将锁计数器减1,当计数器被减到0时,锁就释放了。如果获取对象锁失败了,那当前线程就要阻塞等待,直到对象锁被另一个线程释放为止。
Synchronized是通过对象内部的一个叫做监视器锁(monitor)来实现的,监视器锁本质又是依赖于底层的操作系统的 Mutex Lock(互斥锁)来实现的。而操作系统实现线程之间的切换需要从用户态转换到核心态,这个成本非常高,状态之间的转换需要相对比较长的时间,这就是为什么 Synchronized 效率低的原因。因此,这种依赖于操作系统 Mutex Lock 所实现的锁我们称之为重量级锁。
Java SE 1.6为了减少获得锁和释放锁带来的性能消耗,引入了偏向锁和轻量级锁:锁一共有4种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态。锁可以升级但不能降级。
所以锁的状态总共有四种:无锁状态、偏向锁、轻量级锁和重量级锁。随着锁的竞争,锁可以从偏向锁升级到轻量级锁,再升级的重量级锁(但是锁的升级是单向的,也就是说只能从低到高升级,不会出现锁的降级)。JDK 1.6中默认是开启偏向锁和轻量级锁的,我们也可以通过-XX:-UseBiasedLocking=false来禁用偏向锁。
先来个大体的流程图来感受一下这个过程,然后下面我们再分开来说
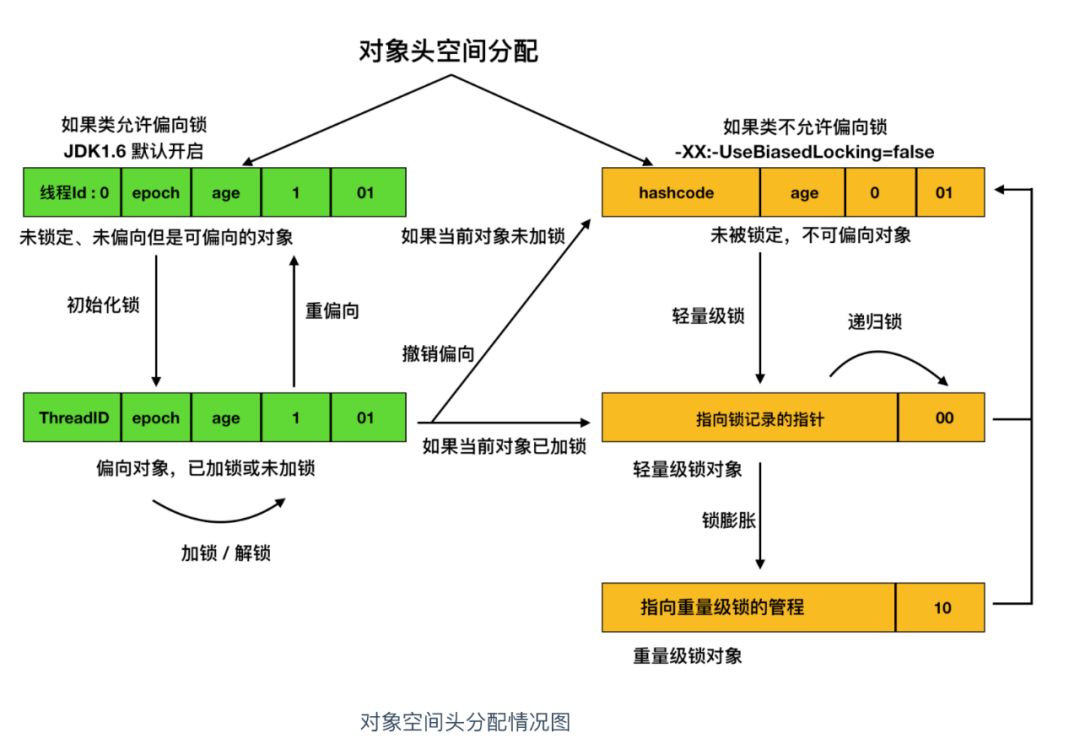
无锁状态,无锁即没有对资源进行锁定,所有的线程都可以对同一个资源进行访问,但是只有一个线程能够成功修改资源。

无锁的特点就是在循环内进行修改操作,线程会不断的尝试修改共享资源,直到能够成功修改资源并退出,在此过程中没有出现冲突的发生,这很像我们在之前文章中介绍的 CAS 实现,CAS 的原理和应用就是无锁的实现。无锁无法全面代替有锁,但无锁在某些场合下的性能是非常高的。
HotSpot 的作者经过研究发现,大多数情况下,锁不仅不存在多线程竞争,还存在锁由同一线程多次获得的情况,偏向锁就是在这种情况下出现的,它的出现是为了解决只有在一个线程执行同步时提高性能。

可以从对象头的分配中看到,偏向锁要比无锁多了线程ID 和 epoch,下面我们就来描述一下偏向锁的获取过程
偏向锁获取过程
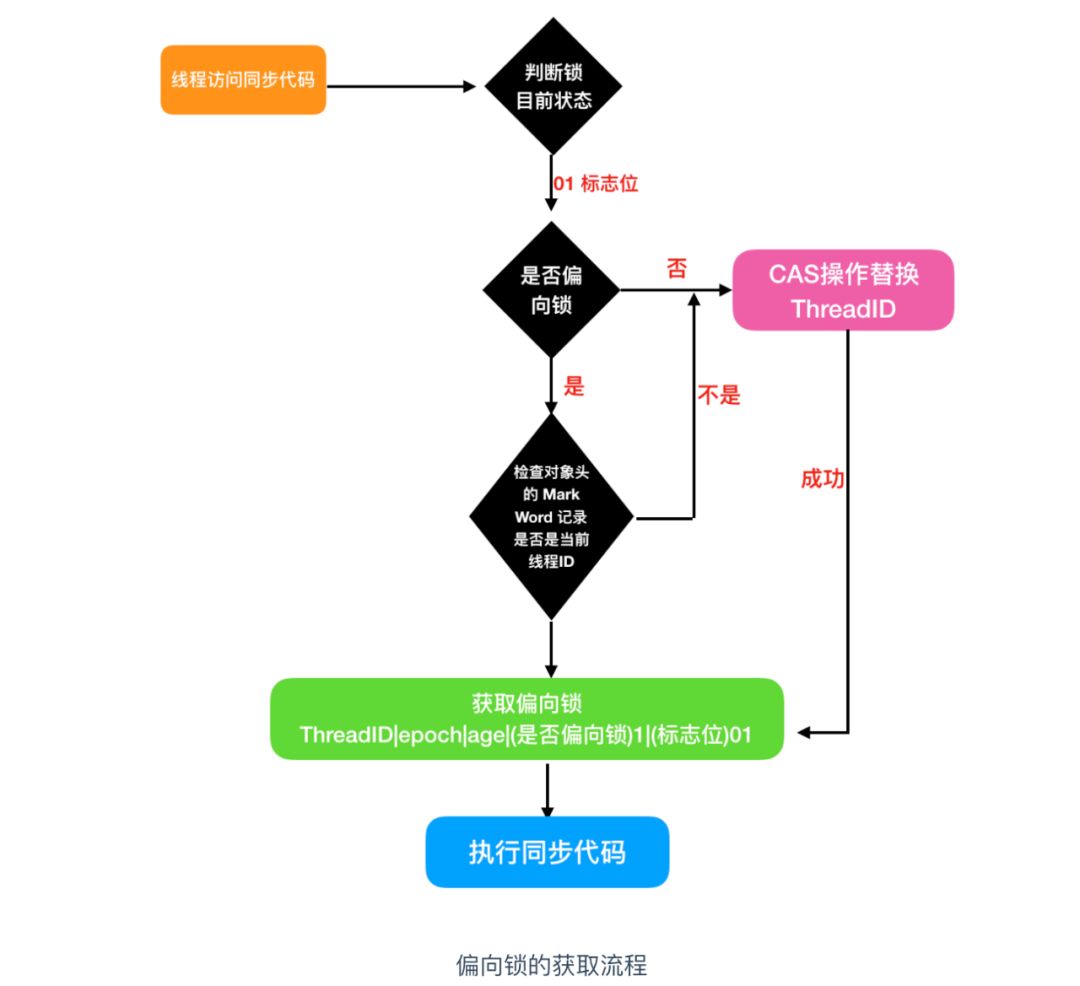
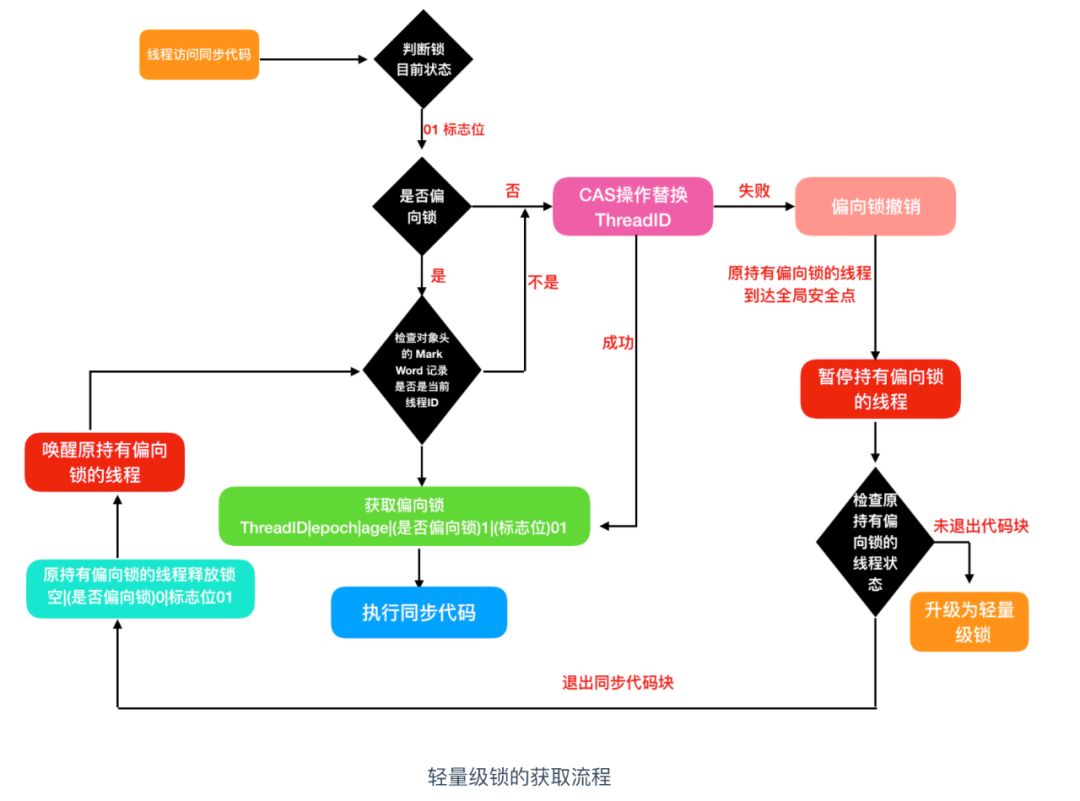
首先线程访问同步代码块,会通过检查对象头 Mark Word 的锁标志位判断目前锁的状态,如果是 01,说明就是无锁或者偏向锁,然后再根据是否偏向锁 的标示判断是无锁还是偏向锁,如果是无锁情况下,执行下一步
线程使用 CAS 操作来尝试对对象加锁,如果使用 CAS 替换 ThreadID 成功,就说明是第一次上锁,那么当前线程就会获得对象的偏向锁,此时会在对象头的 Mark Word 中记录当前线程 ID 和获取锁的时间 epoch 等信息,然后执行同步代码块。
全局安全点(Safe Point):全局安全点的理解会涉及到 C 语言底层的一些知识,这里简单理解 SafePoint 是 Java 代码中的一个线程可能暂停执行的位置。
等到下一次线程在进入和退出同步代码块时就不需要进行 CAS 操作进行加锁和解锁,只需要简单判断一下对象头的 Mark Word 中是否存储着指向当前线程的线程ID,判断的标志当然是根据锁的标志位来判断的。如果用流程图来表示的话就是下面这样
关闭偏向锁
偏向锁在Java 6 和Java 7 里是默认启用的。由于偏向锁是为了在只有一个线程执行同步块时提高性能,如果你确定应用程序里所有的锁通常情况下处于竞争状态,可以通过JVM参数关闭偏向锁:-XX:-UseBiasedLocking=false,那么程序默认会进入轻量级锁状态。
关于 epoch
偏向锁的对象头中有一个被称为 epoch 的值,它作为偏差有效性的时间戳。
轻量级锁是指当前锁是偏向锁的时候,资源被另外的线程所访问,那么偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,从而提高性能,下面是详细的获取过程。
轻量级锁加锁过程
紧接着上一步,如果 CAS 操作替换 ThreadID 没有获取成功,执行下一步;
如果使用 CAS 操作替换 ThreadID 失败(这时候就切换到另外一个线程的角度)说明该资源已被同步访问过,这时候就会执行锁的撤销操作,撤销偏向锁,然后等原持有偏向锁的线程到达全局安全点(SafePoint)时,会暂停原持有偏向锁的线程,然后会检查原持有偏向锁的状态,如果已经退出同步,就会唤醒持有偏向锁的线程,执行下一步;
检查对象头中的 Mark Word 记录的是否是当前线程 ID,如果是,执行同步代码,如果不是,执行偏向锁获取流程 的第2步。
如果用流程表示的话就是下面这样(已经包含偏向锁的获取)
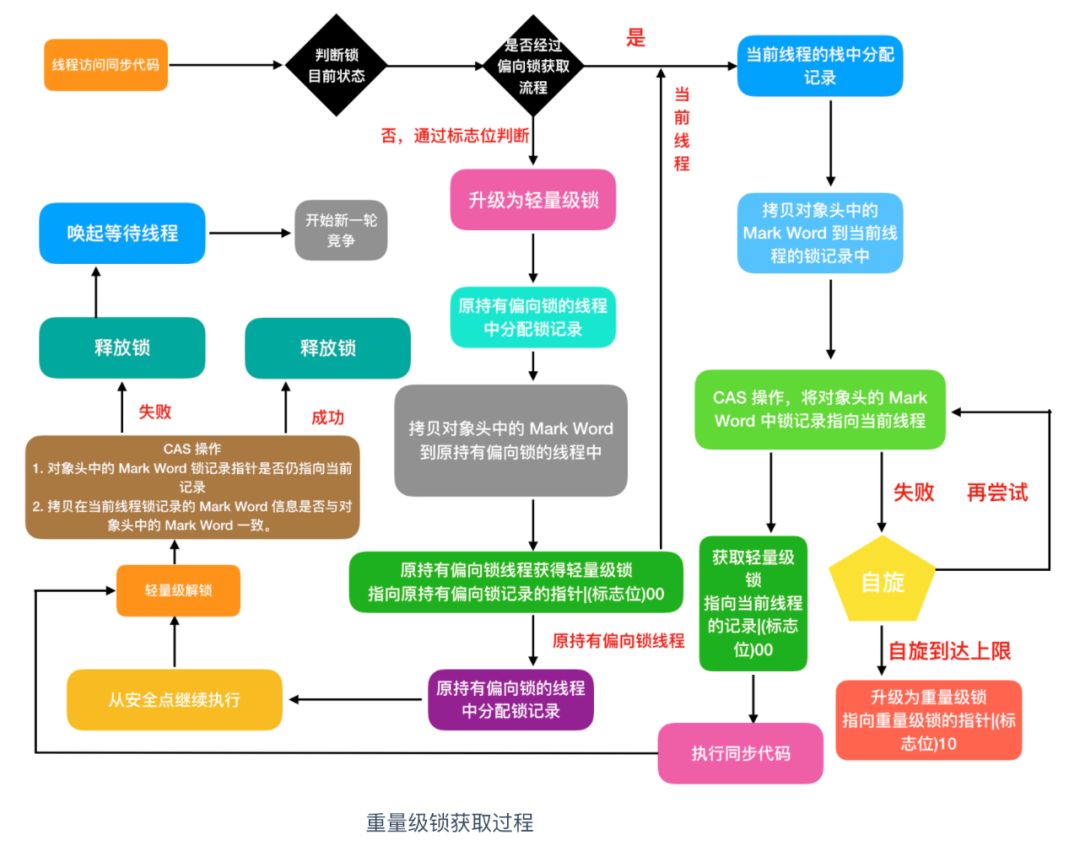
重量级锁的获取流程比较复杂,小伙伴们做好准备,其实多看几遍也没那么麻烦,呵呵。
重量级锁的获取流程
1. 接着上面偏向锁的获取过程,由偏向锁升级为轻量级锁,执行下一步
2 . 会在原持有偏向锁的线程的栈中分配锁记录,将对象头中的 Mark Word 拷贝到原持有偏向锁线程的记录中,然后原持有偏向锁的线程获得轻量级锁,然后唤醒原持有偏向锁的线程,从安全点处继续执行,执行完毕后,执行下一步,当前线程执行第4步
3. 执行完毕后,开始轻量级解锁操作,解锁需要判断两个条件
如果上面两个判断条件都符合的话,就进行锁释放,如果其中一个条件不 符合,就会释放锁,并唤起等待的线程,进行新一轮的锁竞争。

拷贝在当前线程锁记录的 Mark Word 信息是否与对象头中的 Mark Word 一致。
判断对象头中的 Mark Word 中锁记录指针是否指向当前栈中记录的指针
4. 在当前线程的栈中分配锁记录,拷贝对象头中的 MarkWord 到当前线程的锁记录中,执行 CAS 加锁操作,会把对象头 Mark Word 中锁记录指针指向当前线程锁记录,如果成功,获取轻量级锁,执行同步代码,然后执行第3步,如果不成功,执行下一步
5. 当前线程没有使用 CAS 成功获取锁,就会自旋一会儿,再次尝试获取,如果在多次自旋到达上限后还没有获取到锁,那么轻量级锁就会升级为 重量级锁

如果用流程图表示是这样的
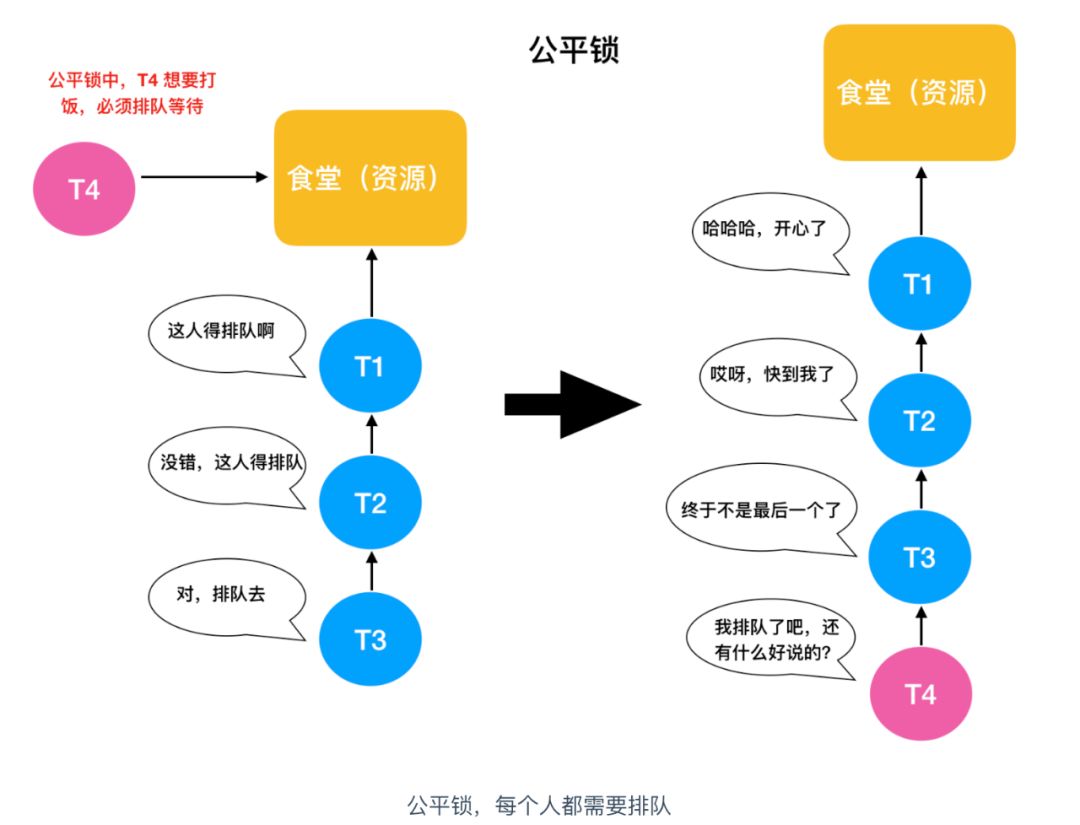
我们知道,在并发环境中,多个线程需要对同一资源进行访问,同一时刻只能有一个线程能够获取到锁并进行资源访问,那么剩下的这些线程怎么办呢?这就好比食堂排队打饭的模型,最先到达食堂的人拥有最先买饭的权利,那么剩下的人就需要在第一个人后面排队,这是理想的情况,即每个人都能够买上饭。那么现实情况是,在你排队的过程中,就有个别不老实的人想走捷径,插队打饭,如果插队的这个人后面没有人制止他这种行为,他就能够顺利买上饭,如果有人制止,他就也得去队伍后面排队。
对于正常排队的人来说,没有人插队,每个人都在等待排队打饭的机会,那么这种方式对每个人来说都是公平的,先来后到嘛。这种锁也叫做公平锁。
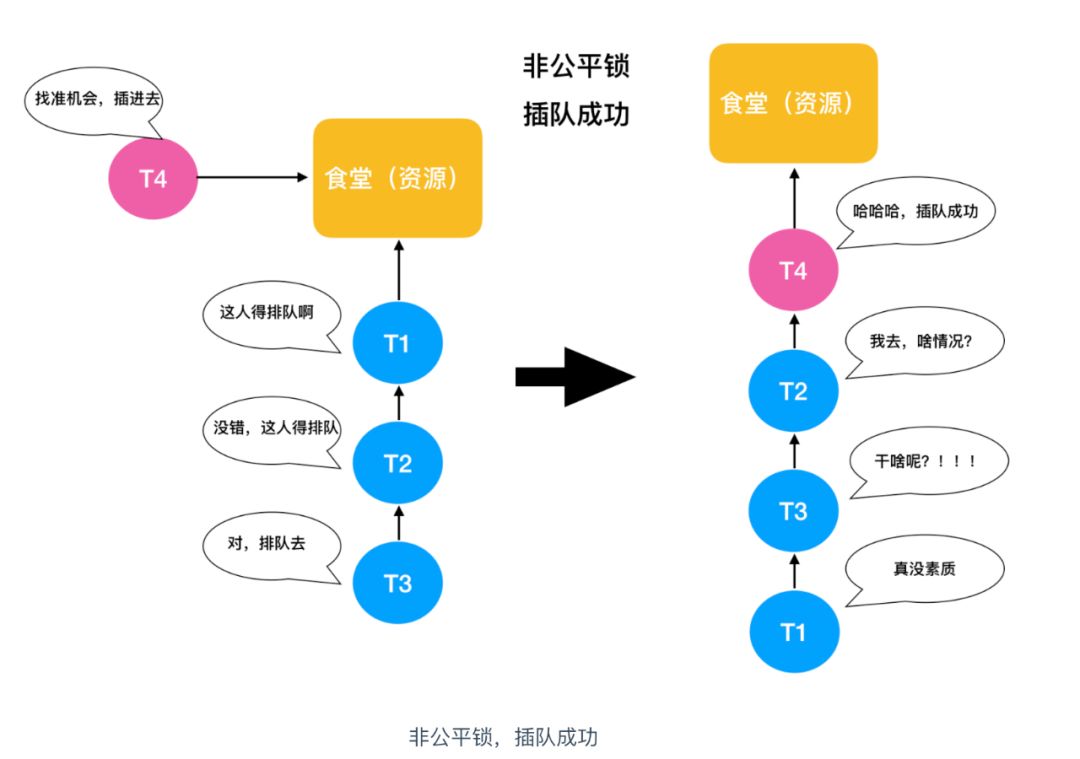
那么假如插队的这个人成功买上饭并且在买饭的过程不管有没有人制止他,他的这种行为对正常排队的人来说都是不公平的,这在锁的世界中也叫做非公平锁。
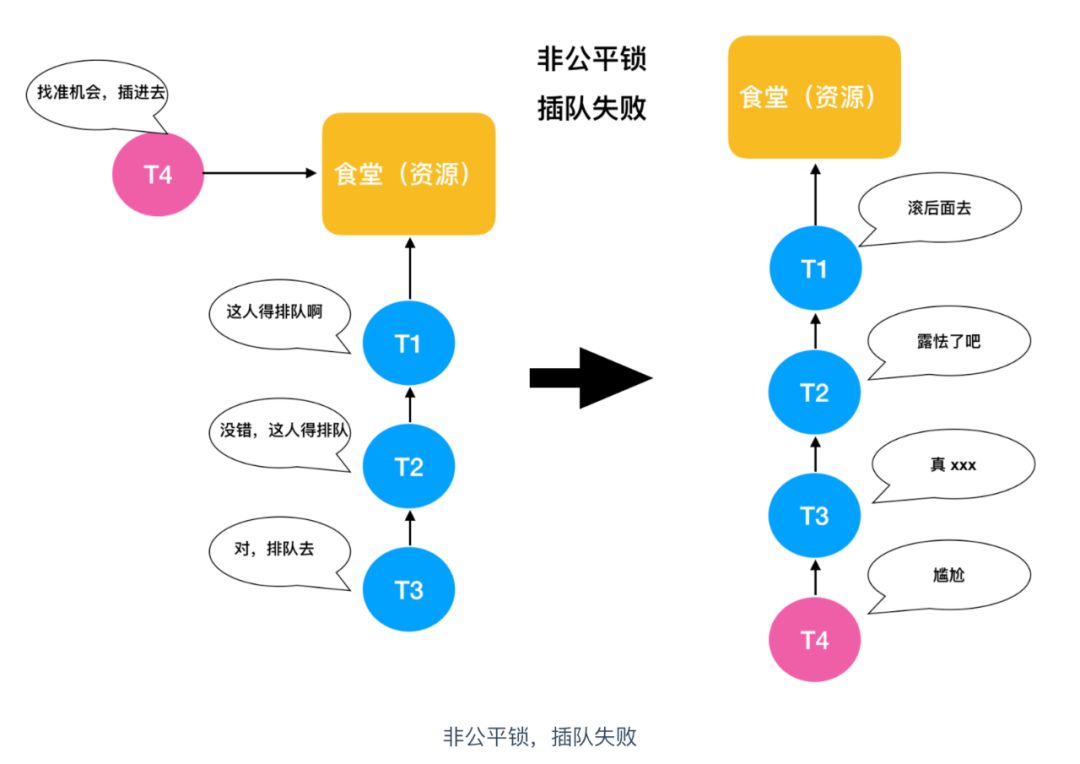
那么我们根据上面的描述可以得出下面的结论
公平锁表示线程获取锁的顺序是按照线程加锁的顺序来分配的,即先来先得的FIFO先进先出顺序。而非公平锁就是一种获取锁的抢占机制,是随机获得锁的,和公平锁不一样的就是先来的不一定先得到锁,这个方式可能造成某些线程一直拿不到锁,结果也就是不公平的了。
在 Java 中,我们一般通过 ReetrantLock 来实现锁的公平性
我们分别通过两个例子来讲解一下锁的公平性和非公平性
锁的公平性
public class MyFairLock extends Thread{
private ReentrantLock lock = new ReentrantLock(true);
public void fairLock{
try {
lock.lock;
System.out.println(Thread.currentThread.getName + "正在持有锁");
}finally {
System.out.println(Thread.currentThread.getName + "释放了锁");
lock.unlock;
}
}
public static void main(String[] args) {
MyFairLock myFairLock = new MyFairLock;
Runnable runnable = -> {
System.out.println(Thread.currentThread.getName + "启动");
myFairLock.fairLock;
};
Thread thread = new Thread[10];
for(int i = 0;i < 10;i++){
thread[i] = new Thread(runnable);
}
for(int i = 0;i < 10;i++){
thread[i].start;
}
}
}我们创建了一个 ReetrantLock,并给构造函数传了一个 true,我们可以查看 ReetrantLock 的构造函数
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync : new NonfairSync;
}
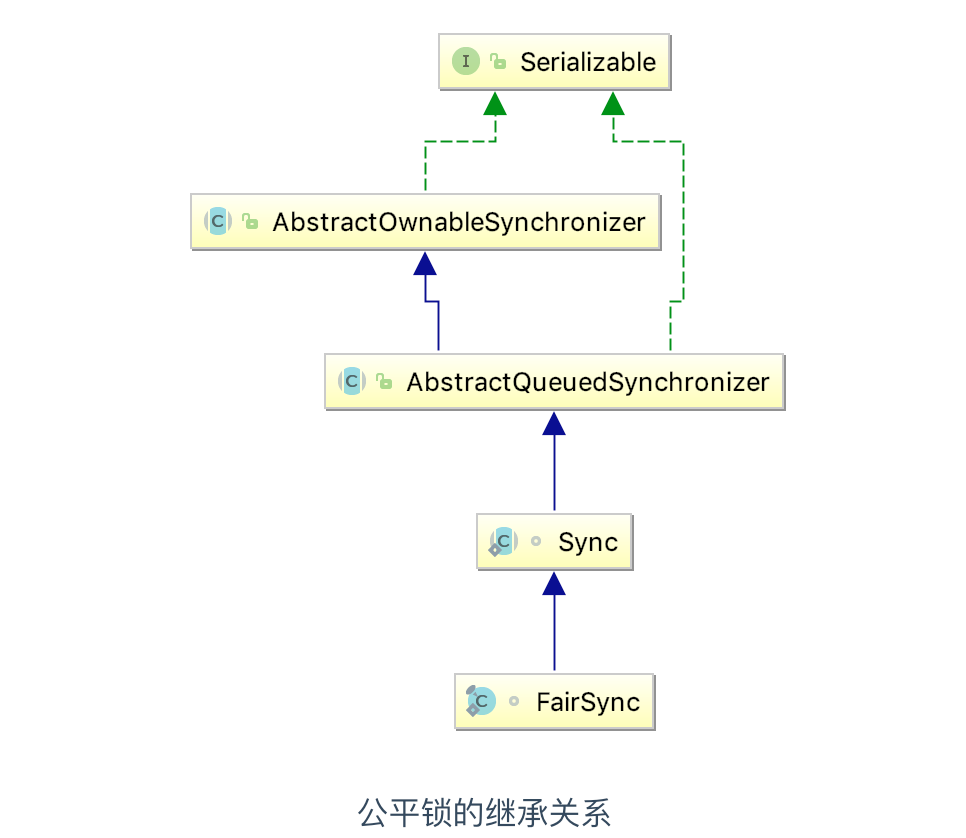
根据 JavaDoc 的注释可知,如果是 true 的话,那么就会创建一个 ReentrantLock 的公平锁,然后并创建一个 FairSync ,FairSync 其实是一个 Sync 的内部类,它的主要作用是同步对象以获取公平锁。

而 Sync 是 ReentrantLock 中的内部类,Sync 继承
AbstractQueuedSynchronizer 类,
AbstractQueuedSynchronizer 就是我们常说的 AQS ,它是 JUC(java.util.concurrent) 中最重要的一个类,通过它来实现独占锁和共享锁。
abstract static class Sync extends AbstractQueuedSynchronizer {...}也就是说,我们把 fair 参数设置为 true 之后,就可以实现一个公平锁了,是这样吗?我们回到示例代码,我们可以执行一下这段代码,它的输出是顺序获取的(碍于篇幅的原因,这里就暂不贴出了),也就是说我们创建了一个公平锁
锁的非公平性
与公平性相对的就是非公平性,我们通过设置 fair 参数为 true,便实现了一个公平锁,与之相对的,我们把 fair 参数设置为 false,是不是就是非公平锁了?用事实证明一下
private ReentrantLock lock = new ReentrantLock(false);其他代码不变,我们执行一下看看输出(部分输出)
Thread-1启动
Thread-4启动
Thread-1正在持有锁
Thread-1释放了锁
Thread-5启动
Thread-6启动
Thread-3启动
Thread-7启动
Thread-2启动可以看到,线程的启动并没有按顺序获取,可以看出非公平锁对锁的获取是乱序的,即有一个抢占锁的过程。也就是说,我们把 fair 参数设置为 false 便实现了一个非公平锁。
ReentrantLock 是一把可重入锁,也是一把互斥锁,它具有与 synchronized 相同的方法和监视器锁的语义,但是它比 synchronized 有更多可扩展的功能。
ReentrantLock 的可重入性是指它可以由上次成功锁定但还未解锁的线程拥有。当只有一个线程尝试加锁时,该线程调用 lock 方法会立刻返回成功并直接获取锁。如果当前线程已经拥有这把锁,这个方法会立刻返回。可以使用 isHeldByCurrentThread 和 getHoldCount 进行检查。
这个类的构造函数接受可选择的 fairness 参数,当 fairness 设置为 true 时,在多线程争夺尝试加锁时,锁倾向于对等待时间最长的线程访问,这也是公平性的一种体现。否则,锁不能保证每个线程的访问顺序,也就是非公平锁。与使用默认设置的程序相比,使用许多线程访问的公平锁的程序可能会显示较低的总体吞吐量(即较慢;通常要慢得多)。但是获取锁并保证线程不会饥饿的次数比较小。无论如何请注意:锁的公平性不能保证线程调度的公平性。因此,使用公平锁的多线程之一可能会连续多次获得它,而其他活动线程没有进行且当前未持有该锁。这也是互斥性 的一种体现。
也要注意的 tryLock 方法不支持公平性。如果锁是可以获取的,那么即使其他线程等待,它仍然能够返回成功。
推荐使用下面的代码来进行加锁和解锁
class MyFairLock {
private final ReentrantLock lock = new ReentrantLock;
public void m {
lock.lock;
try {
// ...
} finally {
lock.unlock
}
}
}ReentrantLock 锁通过同一线程最多支持2147483647个递归锁。尝试超过此限制会导致锁定方法引发错误。
我们在上面的简述中提到,ReentrantLock 是可以实现锁的公平性的,那么原理是什么呢?下面我们通过其源码来了解一下 ReentrantLock 是如何实现锁的公平性的
跟踪其源码发现,调用 Lock.lock 方法其实是调用了 sync 的内部的方法
abstract void lock;而 sync 是最基础的同步控制 Lock 的类,它有公平锁和非公平锁的实现。它继承
AbstractQueuedSynchronizer 即 使用 AQS 状态代表锁持有的数量。
lock 是抽象方法是需要被子类实现的,而继承了 AQS 的类主要有
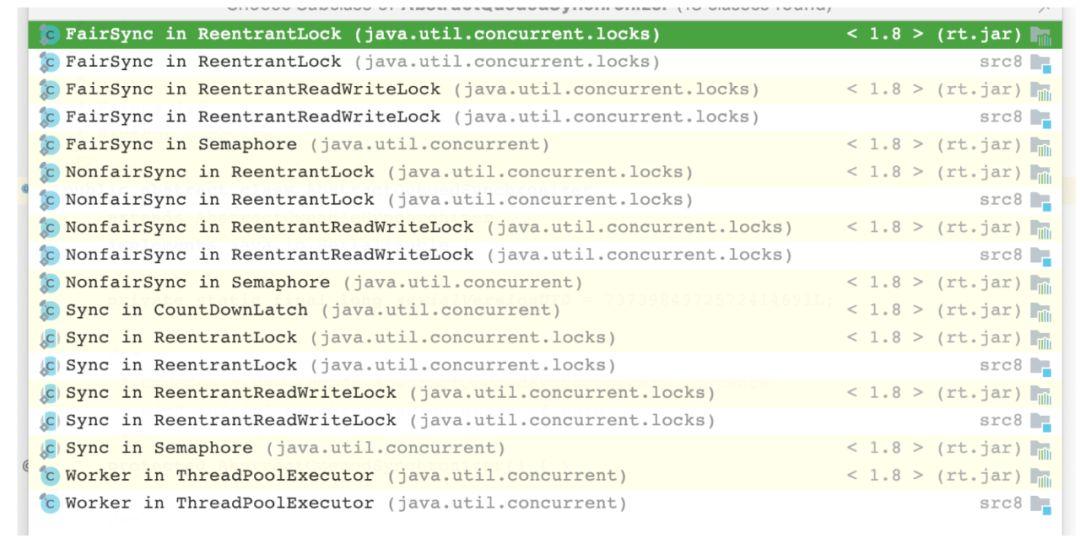
我们可以看到,所有实现了 AQS 的类都位于 JUC 包下,主要有五类:ReentrantLock、ReentrantReadWriteLock、Semaphore、CountDownLatch 和 ThreadPoolExecutor,其中 ReentrantLock、ReentrantReadWriteLock、Semaphore 都可以实现公平锁和非公平锁。
下面是公平锁 FairSync 的继承关系
非公平锁的NonFairSync 的继承关系
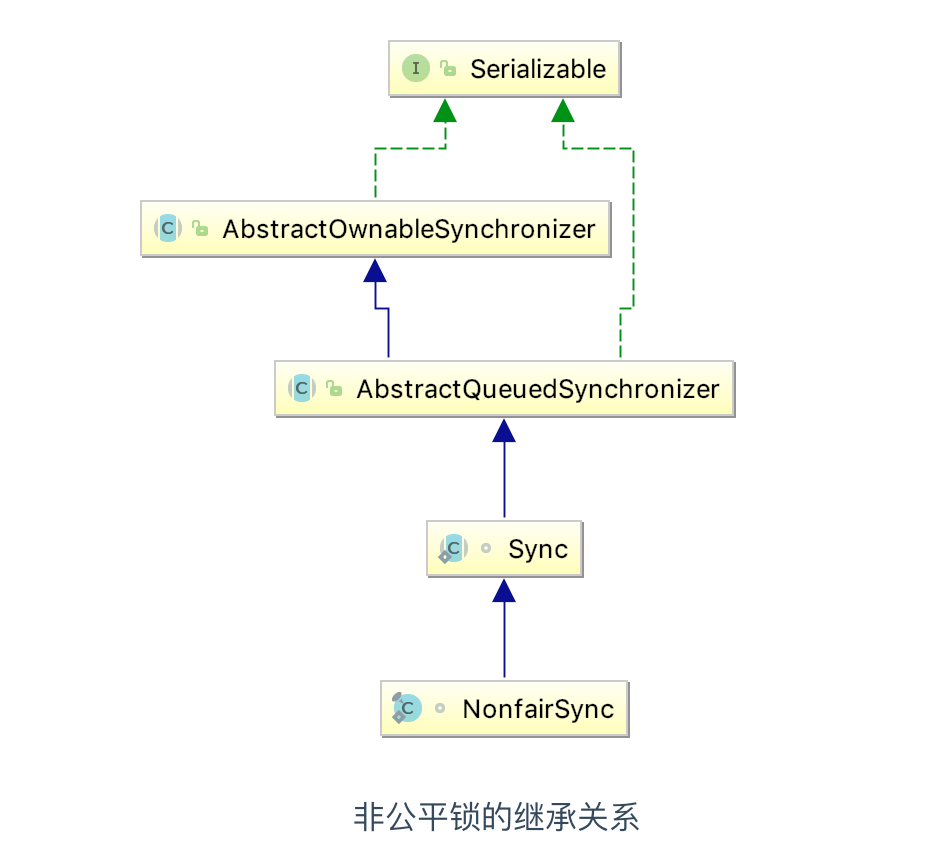
由继承图可以看到,两个类的继承关系都是相同的,我们从源码发现,公平锁和非公平锁的实现就是下面这段代码的区别(下一篇文章我们会从原理角度分析一下公平锁和非公平锁的实现)
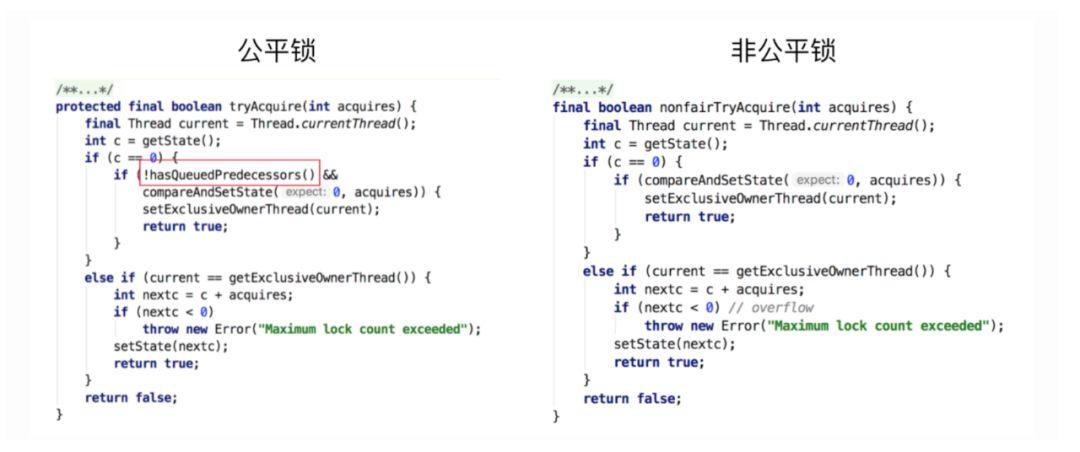
通过上图中的源代码对比,我们可以明显的看出公平锁与非公平锁的lock方法唯一的区别就在于公平锁在获取同步状态时多了一个限制条件:hasQueuedPredecessors。
hasQueuedPredecessors 也是 AQS 中的方法,它主要是用来 查询是否有任何线程在等待获取锁的时间比当前线程长,也就是说每个等待线程都是在一个队列中,此方法就是判断队列中在当前线程获取锁时,是否有等待锁时间比自己还长的队列,如果当前线程之前有排队的线程,返回 true,如果当前线程位于队列的开头或队列为空,返回 false。
综上,公平锁就是通过同步队列来实现多个线程按照申请锁的顺序来获取锁,从而实现公平的特性。非公平锁加锁时不考虑排队等待问题,直接尝试获取锁,所以存在后申请却先获得锁的情况。
可重入锁又称为递归锁,是指在同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁(前提锁对象得是同一个对象或者class),不会因为之前已经获取过还没释放而阻塞。Java 中 ReentrantLock 和synchronized 都是可重入锁,可重入锁的一个优点是在一定程度上可以避免死锁。
我们先来看一段代码来说明一下 synchronized 的可重入性
private synchronized void doSomething{
System.out.println("doSomething...");
doSomethingElse;
}
private synchronized void doSomethingElse{
System.out.println("doSomethingElse...");
}
在上面这段代码中,我们对 doSomething 和 doSomethingElse 分别使用了 synchronized 进行锁定,doSomething 方法中调用了 doSomethingElse 方法,因为 synchronized 是可重入锁,所以同一个线程在调用 doSomething 方法时,也能够进入 doSomethingElse 方法中。
如果 synchronized 是不可重入锁的话,那么在调用 doSomethingElse 方法的时候,必须把 doSomething 的锁丢掉,实际上该对象锁已被当前线程所持有,且无法释放。所以此时会出现死锁。
也就是说,不可重入锁会造成死锁
独占多和共享锁一般对应 JDK 源码的 ReentrantLock 和 ReentrantReadWriteLock 源码来介绍独占锁和共享锁。
独占锁又叫做排他锁,是指锁在同一时刻只能被一个线程拥有,其他线程想要访问资源,就会被阻塞。JDK 中 synchronized和 JUC 中 Lock 的实现类就是互斥锁。
共享锁指的是锁能够被多个线程所拥有,如果某个线程对资源加上共享锁后,则其他线程只能对资源再加共享锁,不能加排它锁。获得共享锁的线程只能读数据,不能修改数据。

我们看到 ReentrantReadWriteLock 有两把锁:ReadLock 和 WriteLock,也就是一个读锁一个写锁,合在一起叫做读写锁。再进一步观察可以发现 ReadLock 和 WriteLock 是靠内部类 Sync 实现的锁。Sync 是继承于 AQS 子类的,AQS 是并发的根本,这种结构在CountDownLatch、ReentrantLock、Semaphore里面也都存在。
在 ReentrantReadWriteLock 里面,读锁和写锁的锁主体都是 Sync,但读锁和写锁的加锁方式不一样。读锁是共享锁,写锁是独享锁。读锁的共享锁可保证并发读非常高效,而读写、写读、写写的过程互斥,因为读锁和写锁是分离的。所以ReentrantReadWriteLock的并发性相比一般的互斥锁有了很大提升。
声明:本文为作者投稿,版权归作者个人所有。
【End】
☞干货分享: 服务器处理器基础知识
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号