MySQL数据库迁移策略详解
发表时间: 2020-12-31 23:23
大家在日常开发工作中一定遇到过以下场景:
1: 整体架构大升级,底层数据表需要进行一次脱胎换骨的改变;
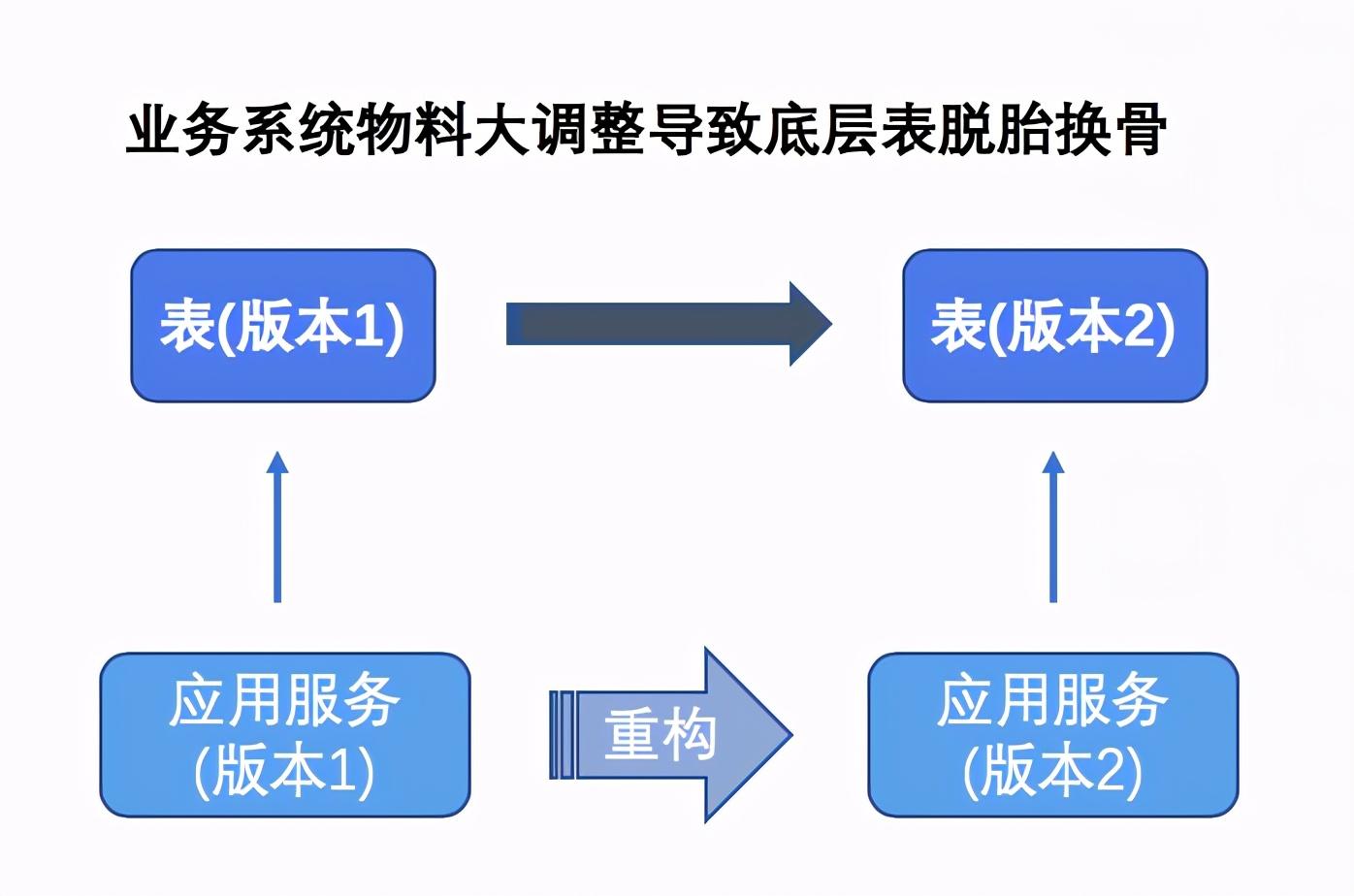
2:已有Mysql分表不足以支撑如此庞大的数据量,需要再次扩容;

3: 底层存储介质改造,例如从Mysql转存至其他存储系统;
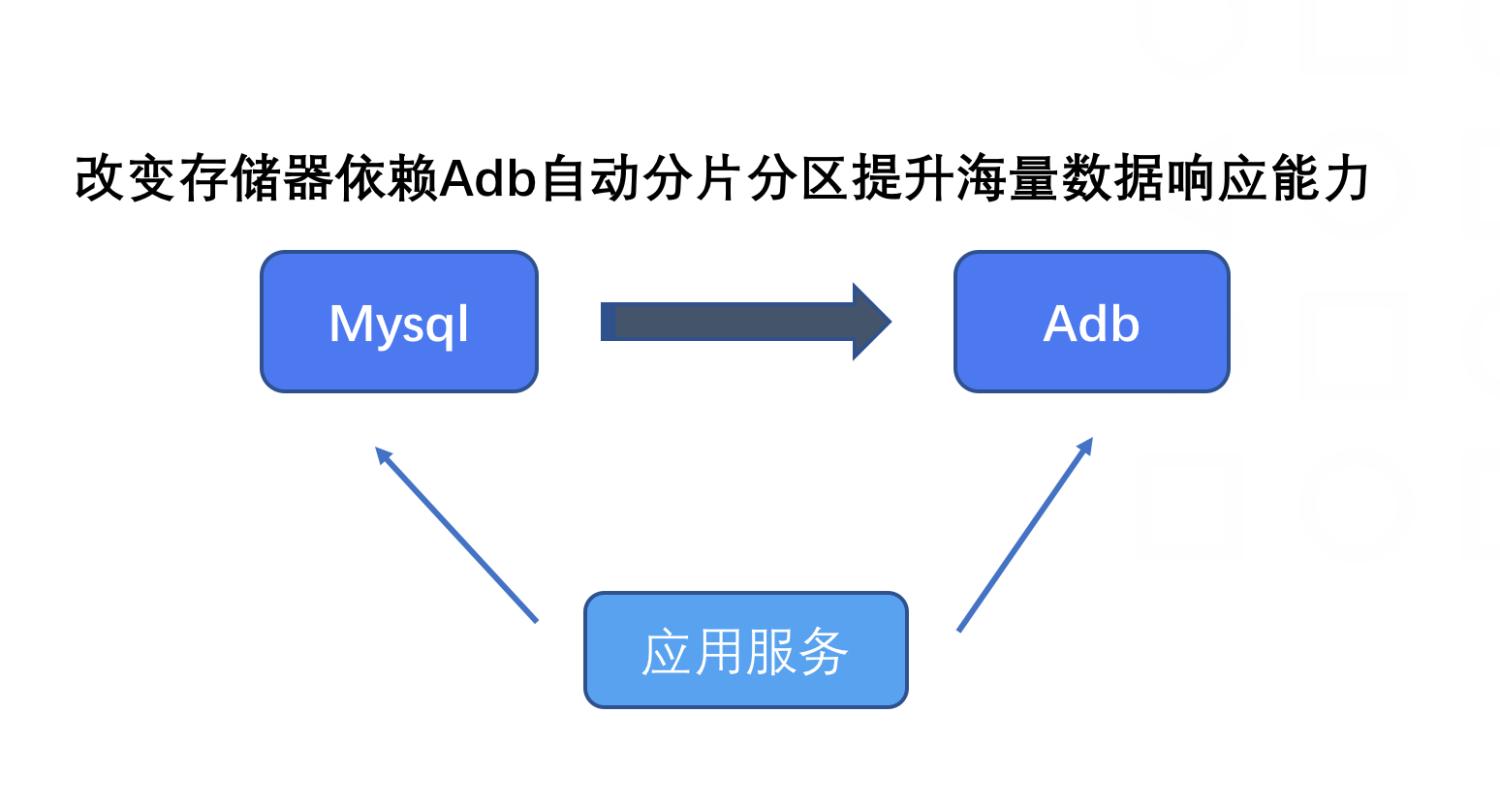
上述情况的发生一定不可避免,而作为一名合格的技术负责人,知晓掌握一套数据迁移成熟解决方案是必须的
本人基于从业以来线上真实迁移方案给大家做一个总结,期望能够帮助到大家伙。
在数据迁移过程中,我们最关心的问题是如何保证服务和数据的高可用,即数据迁移过程要平滑,既让用户无感知-系统不停机,也要保证底层数据的最终一致性、正确性;
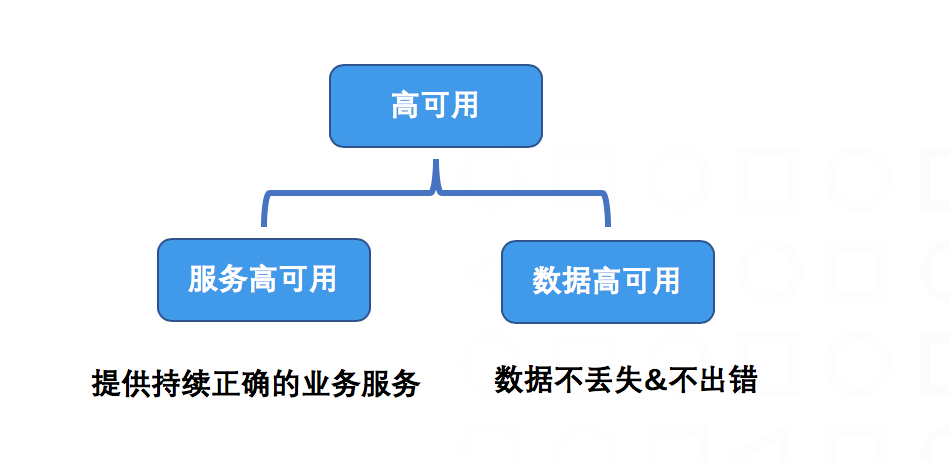
这里的高可用后续会单独开一篇文章为大家详细阐述。
整个方案包含两套服务配合完成
通过Canal(或其他类似服务)监听Binlog二进制日志,对线上实时产生的增量(Insert、Update、Delete)变化做一个同步转换,最后将结果存储至新的库表。
将历史存量数据按自增主键正序排序并每次Limit获取一批数据,对每条记录进行转换并存入新的库表,循环往复直到处理完所有记录。
那具体如何配合物完成整套迁移呢,且听我满满道来:
1 增量转换基于binlog,在历史转换启动之前,记录此刻线上binlog的gtid,而后启动历史数据转换服务,
待全部历史转储完毕后,让实时增量服务从之前记录的gtid开始追溯全量的增量事件,完成数据迁移。
注意:binlog监听处理要保证一个表对应一个线程,防止并发情况下乱序导致的不一致。
2 大家会想,为什么增量转换服务不能和历史转换服务一起启动呢?
其实并不不是不可以,而是这种做法一定会存在数据不一致问题,怎么发生的呢?
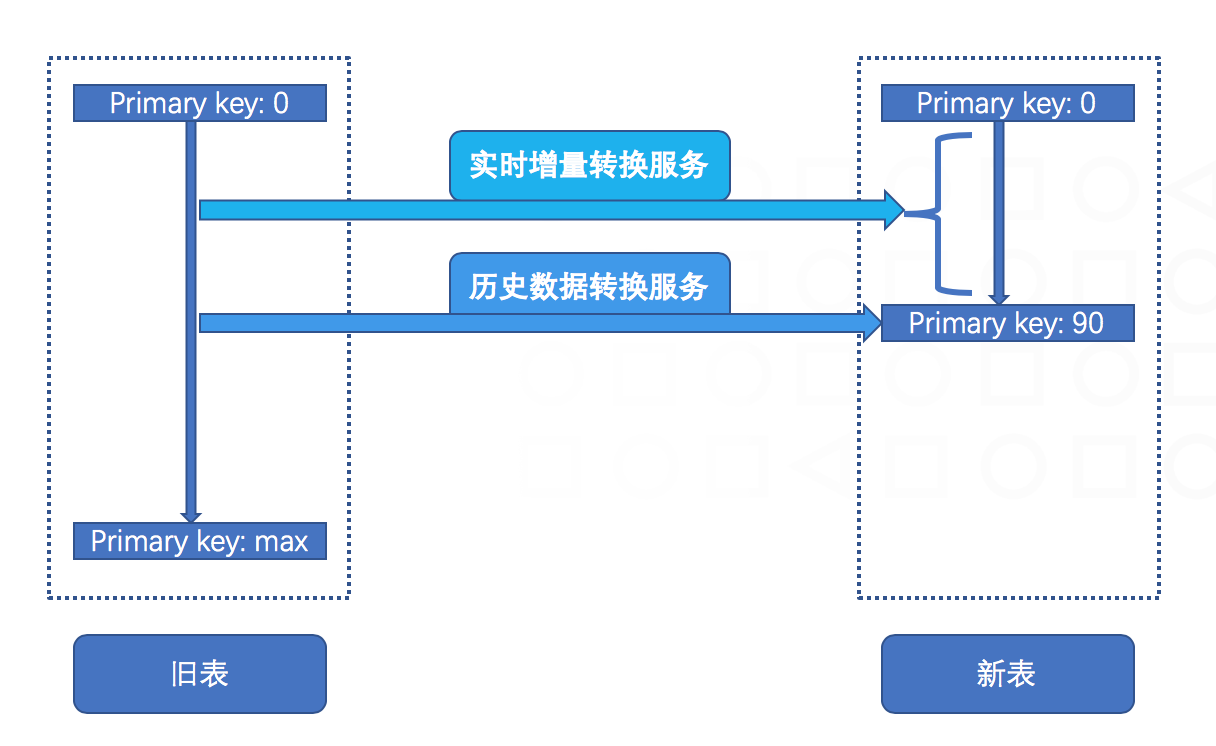
上面形象展示了双服务并行执行的过程
大家想一下,此时历史数据转换服务从旧表抽取一批数据置入内存正在进行逻辑转换,此时旧表来了一个修改操作,之前旧表为1的数据变为2,而此时新表没有这条数据,所以实时增量服务对新表没有数据操作,之后历史转换服务完成处理将数据为1的记录放入新表,此时不一致就发生了。
还有一种情况,数据抽取到内存还未置入新表,旧表数据被删除了,会发生什么呢?
相信大家举一反三已经猜到了-----新表多了一条不应该存在的记录。
所以并行情况下结果理论上一定是不一致的,如果大家执意如此,后续还需要加一个校验服务,待历史存量洗完后,跑几遍校验直到全部一致在进行全部切换(这个校验工具逻辑就是发现数据不一致按照旧表修补)
3 以上最基本的套路已经讲解完了,上述两种方案都要求一件事情,即两条数据流对于某个记录来说必须是单线程的,这句话怎么理解呢?假设binlog监控,我们拿到一条数据假如将其置入MQ进行解耦消费,或者多线程获取,某一条记录的Insert和Update会不会因为各种情况延迟出现乱序呢?
那么有没有一种机制能够完全Cover住上游的乱序消息呢?
精彩的地方来了,第一种方法是用具有原子语义的INSERT ON DUPLICATE UPDATE
这条语句在数据不存在时转成insert,存在时又会变成update
另一种方法是在逻辑层做此处理,因为INSERT ON DUPLICATE UPDATE在Mysql5.7会加Gap锁,会导致高并发下死锁发生,即逻辑判断数据是否存在,若存在转成update,不存在则insert。
总结到这里整体数据迁移方案就讲解完毕了,有什么不对的地方欢迎大家在下方评论,喜欢的朋友麻烦加个关注,哈哈~
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号