深度解析 Node.js 中的流(Streams)
发表时间: 2023-08-19 15:40
转载说明:原创不易,未经授权,谢绝任何形式的转载

Node.js是一个强大的JavaScript运行时,允许开发人员构建可扩展和高效的应用程序。Node.js的一个关键特性是其内置对流的支持。流是Node.js中的一个基本概念,它能够实现高效的数据处理,特别是在处理大量信息或实时处理数据时。
在本文中,我们将探讨Node.js中的流概念,了解可用的不同类型的流(可读流、可写流、双工流和转换流),并讨论有效处理流的最佳实践。
流是Node.js应用程序中的一个基本概念,通过按顺序读取或写入输入和输出,实现高效的数据处理。它们非常适用于文件操作、网络通信和其他形式的端到端数据交换。
流的独特之处在于它以小的、连续的块来处理数据,而不是一次性将整个数据集加载到内存中。这种方法在处理大量数据时非常有益,因为文件大小可能超过可用内存。流使得以较小的片段处理数据成为可能,从而可以处理更大的文件。
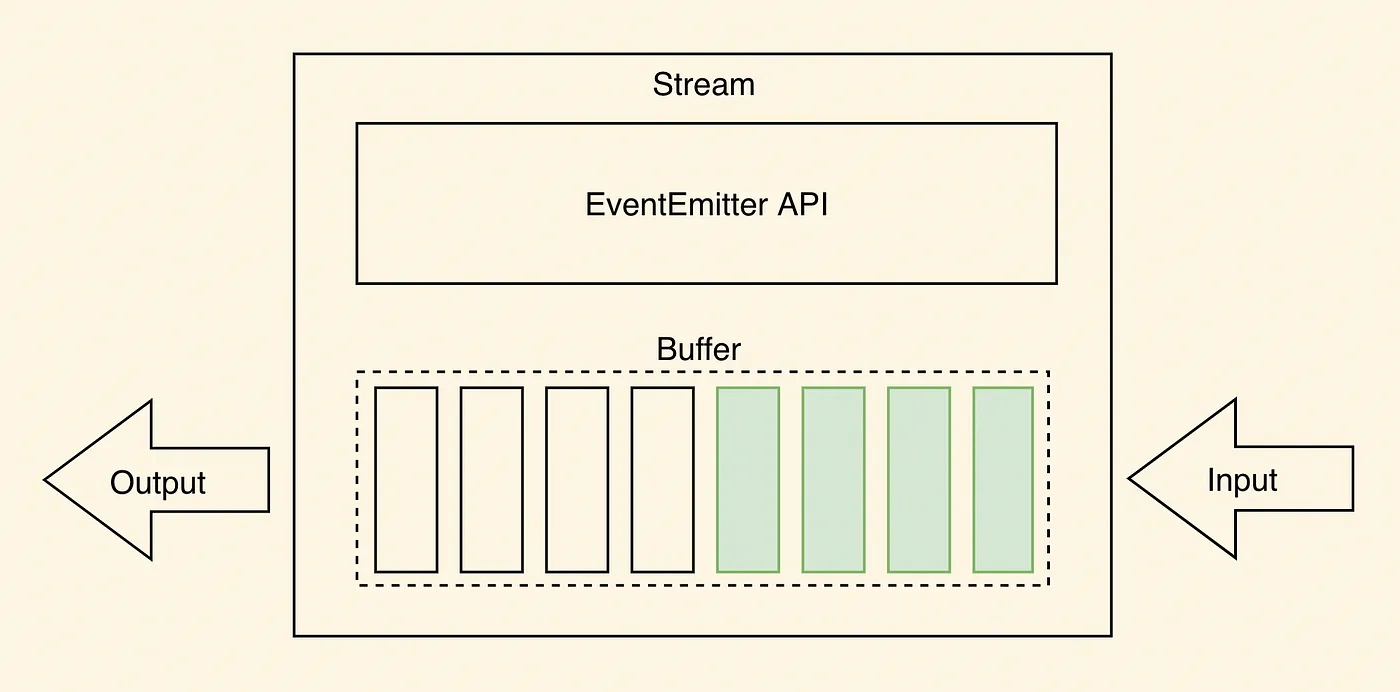
如上图所示,数据通常以块或连续流的形式从流中读取。从流中读取的数据块可以存储在缓冲区中。缓冲区提供临时存储空间,用于保存数据块,直到进一步处理。
为了进一步说明这个概念,考虑一个实时股票市场数据源的情景。在金融应用中,实时更新股票价格和市场数据对于做出明智的决策至关重要。流式处理使应用程序能够以较小的连续块处理数据,而不是获取和存储整个数据源,这可能是相当庞大和不切实际的。数据通过流动,允许应用程序在更新到达时执行实时分析、计算和通知。这种流式处理方法节省了内存资源,并确保应用程序能够迅速响应市场波动,并向交易员和投资者提供最新信息。它消除了在采取行动之前等待整个数据源可用的需要。
流提供了与其他数据处理方法相比的两个关键优势。
内存效率
使用流,处理前不需要将大量数据加载到内存中。相反,数据以较小的可管理块进行处理,减少了内存需求并有效利用了系统资源。
时间效率
流使得数据一旦可用就能立即进行处理,而不需要等待整个有效负载的传输。这样可以实现更快的响应时间和改善整体性能。
理解并有效地利用流能够帮助开发人员实现最佳的内存使用、更快的数据处理和增强的代码模块化,使其成为Node.js应用程序中强大的功能。然而,不同类型的Node.js流可以用于特定的目的,并在数据处理方面提供灵活性。为了在您的Node.js应用程序中有效地使用流,有必要清楚地了解每种流类型。因此,让我们深入研究一下Node.js中可用的不同流类型。
Node.js 提供了四种主要类型的流,每种流都有特定的用途:
Readable Streams 可读流
可读流允许从源(如文件或网络套接字)读取数据。它们按顺序发出数据块,并可以通过附加监听器到“data”事件来消费。可读流可以处于流动或暂停状态,取决于数据的消费方式。
const fs = require('fs');// Create a Readable stream from a fileconst readStream = fs.createReadStream('the_princess_bride_input.txt', 'utf8');// Readable stream 'data' event handlerreadStream.on('data', (chunk) => { console.log(`Received chunk: ${chunk}`);});// Readable stream 'end' event handlerreadStream.on('end', () => { console.log('Data reading complete.');});// Readable stream 'error' event handlerreadStream.on('error', (err) => { console.error(`Error occurred: ${err}`);});如上所示的代码片段中,我们使用fs模块使用createReadStream()方法创建一个可读流。我们将文件路径
the_princess_bride_input.txt 和编码 utf8 作为参数传递。可读流以小块方式从文件中读取数据。
我们将事件处理程序附加到可读流上以处理不同的事件。当数据块可供读取时,会触发 data 事件。当可读流完成从文件中读取所有数据时,会触发 end 事件。如果在读取过程中发生错误,则会触发 error 事件。
通过使用可读流并监听相应的事件,您可以高效地从源(例如文件)中读取数据,并对接收到的数据块执行进一步操作。
Writable Streams 可写流
可写流处理将数据写入目标位置,例如文件或网络套接字。它们提供了像 write() 和 end() 这样的方法来向流发送数据。可写流可用于以分块方式写入大量数据,防止内存溢出。
const fs = require('fs');// Create a Writable stream to a fileconst writeStream = fs.createWriteStream('the_princess_bride_output.txt');// Writable stream 'finish' event handlerwriteStream.on('finish', () => { console.log('Data writing complete.');});// Writable stream 'error' event handlerwriteStream.on('error', (err) => { console.error(`Error occurred: ${err}`);});// Write a quote from "The to the Writable streamwriteStream.write('As ');writeStream.write('You ');writeStream.write('Wish');writeStream.end();在上面的代码示例中,我们使用fs模块使用 createWriteStream() 方法创建一个可写流。我们指定数据将被写入的文件路径(
the_princess_bride_output.txt )。
我们将事件处理程序附加到可写流上,以处理不同的事件。当可写流完成写入所有数据时,会触发 finish 事件。如果在写入过程中发生错误,则会触发 error 事件。使用 write() 方法将单个数据块写入可写流。在这个例子中,我们将字符串'As'、'You'和'Wish'写入流中。最后,我们调用 end() 来表示数据写入结束。
通过使用可写流并监听相应的事件,您可以高效地将数据写入目标位置,并在写入过程完成后执行任何必要的清理或后续操作。
Duplex Streams 双工流
双工流代表了可读和可写流的组合。它们允许同时从源读取和写入数据。双工流是双向的,并在同时进行读取和写入的情况下提供了灵活性。
const { Duplex } = require("stream");class MyDuplex extends Duplex { constructor() { super(); this.data = ""; this.index = 0; this.len = 0; } _read(size) { // Readable side: push data to the stream const lastIndexToRead = Math.min(this.index + size, this.len); this.push(this.data.slice(this.index, lastIndexToRead)); this.index = lastIndexToRead; if (size === 0) { // Signal the end of reading this.push(null); } } _write(chunk, encoding, next) { const stringVal = chunk.toString(); console.log(`Writing chunk: ${stringVal}`); this.data += stringVal; this.len += stringVal.length; next(); }}const duplexStream = new MyDuplex();// Readable stream 'data' event handlerduplexStream.on("data", (chunk) => { console.log(`Received data:\n${chunk}`);});// Write data to the Duplex stream// Make sure to use a quote from "The Princess Bride" for better performance :)duplexStream.write("Hello.\n");duplexStream.write("My name is Inigo Montoya.\n");duplexStream.write("You killed my father.\n");duplexStream.write("Prepare to die.\n");// Signal writing endedduplexStream.end();在上面的例子中,我们从流模块扩展了Duplex类来创建一个双工流。双工流代表了既可读又可写的流(它们可以相互独立)。
我们定义了Duplex流的 _read() 和 _write() 方法来处理各自的操作。在这种情况下,我们将写入流和读取流绑定在一起,但这只是为了举例说明 - Duplex流支持独立的读取和写入流。
在 _read() 方法中,我们实现了双工流的可读端。我们使用 this.push() 将数据推送到流中,当大小变为0时,通过将null推送到流中来表示读取结束。
在 _write() 方法中,我们实现了Duplex流的可写端。我们处理接收到的数据块并将其添加到内部缓冲区。调用 next() 方法来指示写操作的完成。
事件处理程序附加到双工流的 data 事件,用于处理流的可读一侧。要向双工流写入数据,我们可以使用 write() 方法。最后,我们调用 end() 来表示写入结束。
双工流允许您创建一个双向流,既可以进行读取操作,也可以进行写入操作,从而实现灵活的数据处理场景。
Transform Streams 转换流
转换流是一种特殊类型的双工流,它在数据通过流时修改或转换数据。它们通常用于数据操作任务,如压缩、加密或解析。转换流接收输入数据,进行处理,并发出修改后的输出数据。
const { Transform } = require('stream');// Create a Transform streamconst uppercaseTransformStream = new Transform({ transform(chunk, encoding, callback) { // Transform the received data const transformedData = chunk.toString().toUpperCase(); // Push the transformed data to the stream this.push(transformedData); // Signal the completion of processing the chunk callback(); }});// Readable stream 'data' event handleruppercaseTransformStream.on('data', (chunk) => { console.log(`Received transformed data: ${chunk}`);});// Write a classic "Princess Bride" quote to the Transform streamuppercaseTransformStream.write('Have fun storming the castle!');uppercaseTransformStream.end();如上代码片段所示,我们使用流模块中的 Transform 类创建一个Transform流。我们在Transform流选项对象中定义 transform() 方法来处理转换操作。在 transform() 方法中,我们实现转换逻辑。在本例中,我们使用 chunk.toString().toUpperCase() 将接收到的数据块转换为大写。我们使用 this.push() 将转换后的数据推送到流中。最后,我们调用 callback() 来指示处理数据块的完成。
我们将事件处理程序附加到Transform流的 data 事件上,以处理流的可读端。要向Transform流写入数据,我们使用 write() 方法。并且我们调用 end() 来表示写入结束。
一个转换流允许您在数据通过流时即时进行数据转换,从而实现对数据的灵活和可定制的处理。
了解这些不同类型的流,让开发人员能够根据自己的特定需求选择适当的流类型。
为了更好地掌握Node.js Streams的实际应用,让我们考虑一个例子,使用流来读取数据并在转换和压缩后将其写入另一个文件。
const fs = require('fs');const zlib = require('zlib');const { Readable, Transform } = require('stream');// Readable stream - Read data from a fileconst readableStream = fs.createReadStream('classic_tale_of_true_love_and_high_adventure.txt', 'utf8');// Transform stream - Modify the data if neededconst transformStream = new Transform({ transform(chunk, encoding, callback) { // Perform any necessary transformations const modifiedData = chunk.toString().toUpperCase(); // Placeholder for transformation logic this.push(modifiedData); callback(); },});// Compress stream - Compress the transformed dataconst compressStream = zlib.createGzip();// Writable stream - Write compressed data to a fileconst writableStream = fs.createWriteStream('compressed-tale.gz');// Pipe streams togetherreadableStream.pipe(transformStream).pipe(compressStream).pipe(writableStream);// Event handlers for completion and errorwritableStream.on('finish', () => { console.log('Compression complete.');});writableStream.on('error', (err) => { console.error('An error occurred during compression:', err);});在这段代码片段中,我们使用可读流读取文件,将数据转换为大写,并使用两个转换流(一个是我们自己的,一个是内置的zlib转换流)进行压缩,最后使用可写流将数据写入文件。
我们使用 fs.createReadStream() 创建一个可读流,从输入文件中读取数据。使用 Transform 类创建一个转换流。在这里,您可以对数据进行任何必要的转换(对于这个例子,我们再次使用 toUpperCase() )。然后,我们使用 zlib.createGzip() 创建另一个转换流,使用Gzip压缩算法压缩转换后的数据。最后,我们使用 fs.createWriteStream() 创建一个可写流,将压缩后的数据写入 compressed-tale.gz 文件。
.pipe() 方法用于按顺序将流连接在一起。我们从可读流开始,将其导入转换流,然后将转换流导入压缩流,最后将压缩流导入可写流。它允许您建立从可读流通过转换和压缩流到可写流的流畅数据流。最后,事件处理程序被附加到可写流以处理 finish 和 error 事件。
使用 pipe() 简化了连接流的过程,自动处理数据流,并确保从可读流到可写流的高效和无误传输。它负责管理底层流事件和错误传播。
另一方面,直接使用事件可以让开发人员对数据流具有更精细的控制。通过将事件监听器附加到可读流上,您可以在将数据写入目标之前对接收到的数据执行自定义操作或转换。
在决定是使用 pipe() 还是events时,以下是一些你应该考虑的因素。
选择最适合您特定用例的方法非常重要。对于简单的数据传输,由于其简单性和自动错误处理, pipe() 通常是首选。然而,如果您需要更多的控制或在数据流中进行额外处理,直接使用事件提供了必要的灵活性。
在使用Node.js Streams时,遵循最佳实践以确保最佳性能和可维护的代码非常重要。
通过遵循这些最佳实践,开发人员可以确保高效的流处理,最小化资源使用,并构建强大且可扩展的应用程序。
Node.js流是一种强大的功能,可以以非阻塞的方式高效处理数据流。通过利用流,开发人员可以处理大型数据集,处理实时数据,并以内存高效的方式执行操作。了解不同类型的流,如可读流、可写流、双工流和转换流,并遵循最佳实践,可以确保最佳的流处理、错误管理和资源利用。通过利用流的能力,开发人员可以使用Node.js构建高性能和可扩展的应用程序。
由于文章内容篇幅有限,今天的内容就分享到这里,文章结尾,我想提醒您,文章的创作不易,如果您喜欢我的分享,请别忘了点赞和转发,让更多有需要的人看到。同时,如果您想获取更多前端技术的知识,欢迎关注我,您的支持将是我分享最大的动力。我会持续输出更多内容,敬请期待。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号