揭秘AI换脸新挑战:普通人如何应对?
发表时间: 2024-09-09 12:04

最近在韩国发生的「N 号房 2.0」事件,再次把 Deepfake(深度伪造)这个老生常谈的话题带到了台前。
加害人们聚集在 Telegram,用 AI 将女性照片合成为裸照,昭示着,Deepfake 的包围圈,早已从娱乐明星、政治人物,扩张到你我这样的普通人。

在这个 AI 成为显学的时代,我们想要了解,看似并不新鲜的、但近年越发普及的技术,如何影响了日常生活。
Deepfake 进化到什么程度了,会造成什么危害?如何用技术反 Deepfake?普通人怎么防范 Deepfake?
我们和瑞莱智慧算法科学家陈鹏博士聊了聊这些问题。瑞莱智慧成立于 2018 年,由清华大学人工智能研究院孵化,深耕 AI 鉴伪多年。
陈鹏告诉我们,普通人在鉴别 Deepfake 上已经一败涂地,反 Deepfake 还得看 AI。
Deepfake 最早兴起于 2017 年的「美版贴吧」Reddit,主要形式是将明星的脸替换到色情视频的主角身上,或者恶搞政界人物。
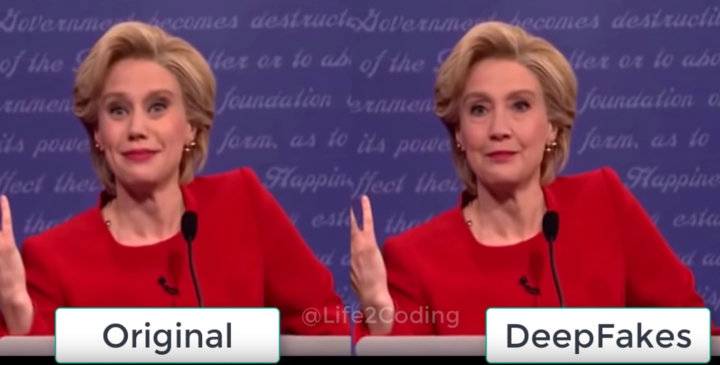
如今,造谣、搞黄色,仍然是 Deepfake 的主流用途,只是变得更加容易。
陈鹏解释,采集一张照片也足够换脸,当然,采集的数据越多,痣、五官等人脸的细节也会被更好地建模,换脸的效果就越逼真。
今年 4 月,两位德国艺术家的行为艺术项目,就是一个活生生的例子。

他们设计了一个 AI 相机 NUCA,相机本体 3D 打印,内置 37 毫米广角镜头,拍下的照片会被传输到云端,由 AI「脱去衣服」,10 秒钟不到即可「出片」。
NUCA 其实不知道你的裸体是什么样,只是通过分析你的性别、面部、年龄、体型等,呈现 AI 眼里你的裸体。
粗劣吗?或许不重要,几秒之间,你已经在 AI 面前暴露无遗,别人说不定也会相信这是你。

韩国「N 号房 2.0」也被曝光出类似的细节:一个 22.7 万人的 Telegram 聊天室,内置一个将女性照片合成为裸照、并能调整胸部的机器人,5 到 7 秒生成 Deepfake 内容。
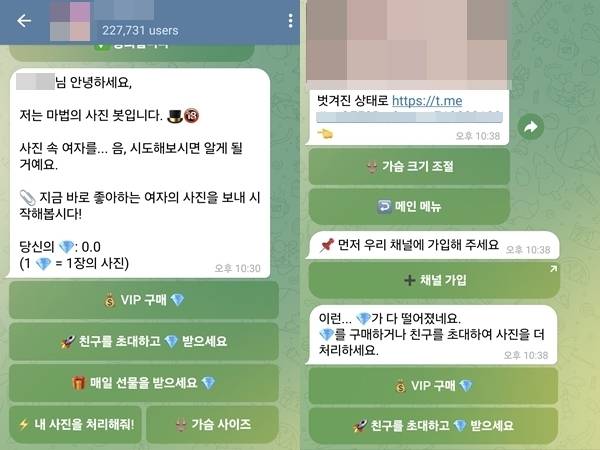
聊天室截图,说明 Deepfake 的使用方法
换脸、脱衣,只是 Deepfake 的一种应用。
通过生成式 AI 模型(GAN、VAE、扩散模型等),合成或伪造逼真的内容,包括文字、图像、音频、视频,都可以称为 Deepfake。
其中,音频的 Deepfake 也相当常见。
2023 年初,科技记者 Joseph Cox 拨打银行的自动服务热线,播放自己用 ElevenLabs 克隆的 AI 语音「我的声音就是我的密码」,要求检查余额,没想到语音验证成功了。

陈鹏表示这不奇怪,之前捕捉我们的声纹信息,需要几分钟、几十分钟的语音,但现在可能半分钟、几十秒,就能捕捉个大概。多接几个骚扰电话,我们的声音或许就泄漏了。
当然,想要更精准地克隆,复制音调等说话风格,比如让郭德纲说英文相声、让霉霉讲中文,仍然需要更多的语料。

甚至,文本也是一个被 Deepfake 的领域。AI 生成的文本早已到处可见,被学生拿来作弊和应付作业让老师头疼,但我们或许还没有意识到这背后的风险。
虚假消息和谣言,是文字 Deepfake 的重灾区,陈鹏说,以前还需要人类自己写文案,但现在针对某个事件,AI 可以生成各种言论,然后自动化地投放到社交媒体。

Deepfake 更快速、更简单,在陈鹏看来,主要有三个原因。
一是,文生图、文生视频等生成式 AI 技术有了突破,二是,算力越发普及,消费级的显卡已经能够运行生成式 AI 模型。
还有很重要的一点,Deepfake 这项技术,被优化成了各种门槛更低的工具。
拿换脸举例,Deepfake 的开源项目不少,比如 Github 的 DeepFaceLive 和 Deep-Live-Cam,用户可以从网站下载代码,在本地配置运行环境。
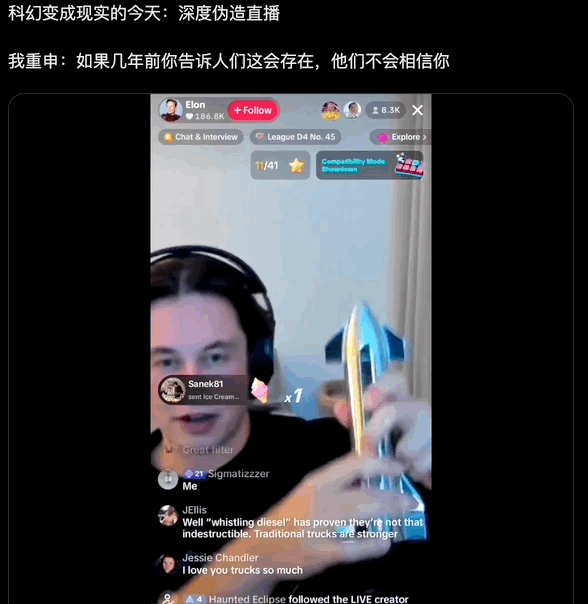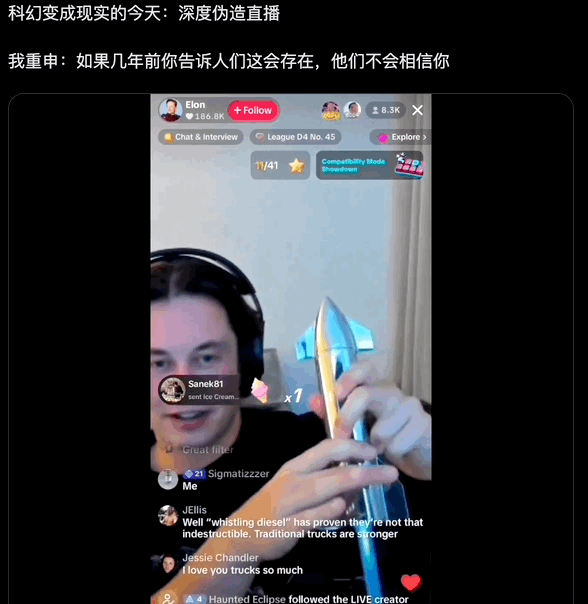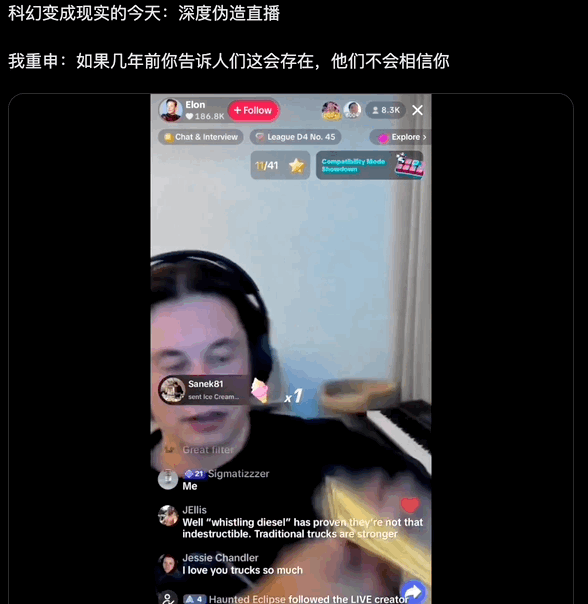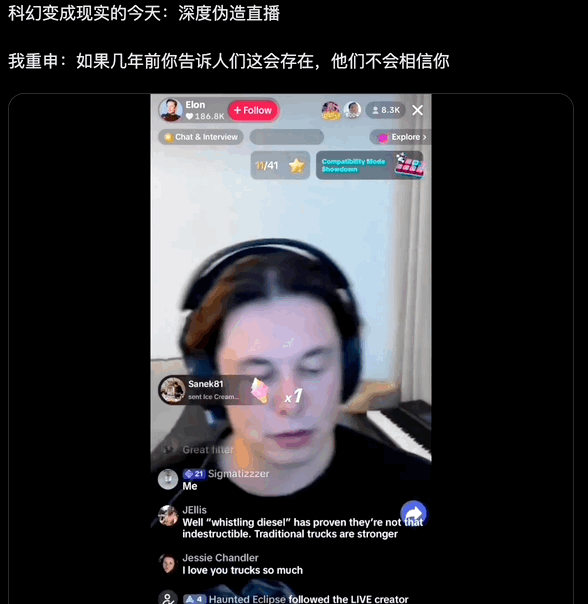
AI 马斯克直播,用的是 Deep-Live-Cam
如果不懂技术的小白还是觉得有难度,也有专业人士直接把饭喂到嘴边,对模型进行封装,编写成简单好用的软件供玩家免费下载,自己赚点广告费,包括很多一键脱衣的 app。
至于音频的 Deepfake,也已经有成熟的商业公司,以 SDK(开发工具包)或者 API(应用编程接口)的方式,让用户轻松使用服务。
用户甚至不需要一台带有显卡的设备部署程序,而是将音频等内容上传到网站,等待生成结果,然后下载。
所以,复杂的技术原理隐藏幕后,在用户面前的是一个个「开箱即用」的界面,连青少年们也能随手制造虚假信息。
一言以蔽之,陈鹏的结论是:
Deepfake 已经到了普通人唾手可得的地步了。
当一项技术「飞入寻常百姓家」,最可能被波及的,恰恰也是普通人。
诈骗是 Deepfake 最常见的作恶方式之一。
今年年初,一家跨国公司香港分公司因为 AI 被骗走了 2500 万美元。受害人参加了一次视频会议,其他人都是经过「AI 换脸」和「AI 换声」的诈骗分子。
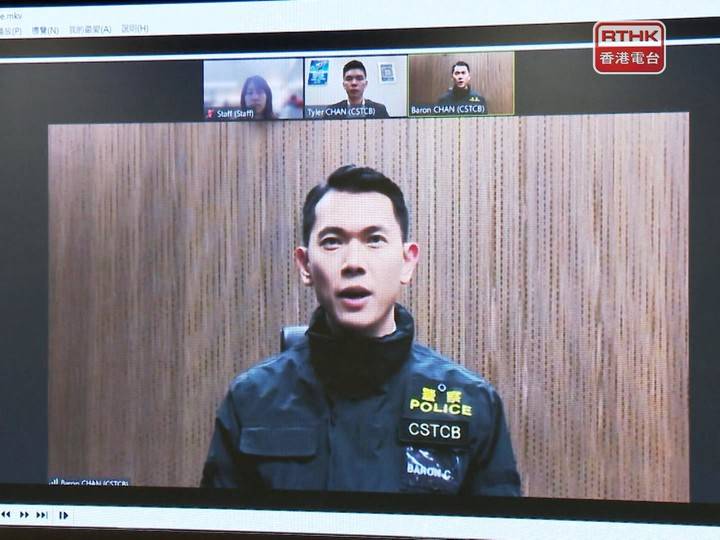
警方示范怎么用 Deepfake 伪造多人视频会议
事已至此,我们可以做些什么保护自己?
如果别人拿 Deepfake 来骗你,钻 AI 的空子,是其中一种办法,但有保质期。
举个例子,我们在视频通话时,如果怀疑对方是 AI 换脸,可以引导对方做些特定的动作,比如把手放在面前快速划动几下、大幅度地转动头部。
如果 AI 换脸背后的模型没有对手部遮挡做专门的优化,那么就会露馅,脸可能会出现在手的背部,或者突然发生扭曲。
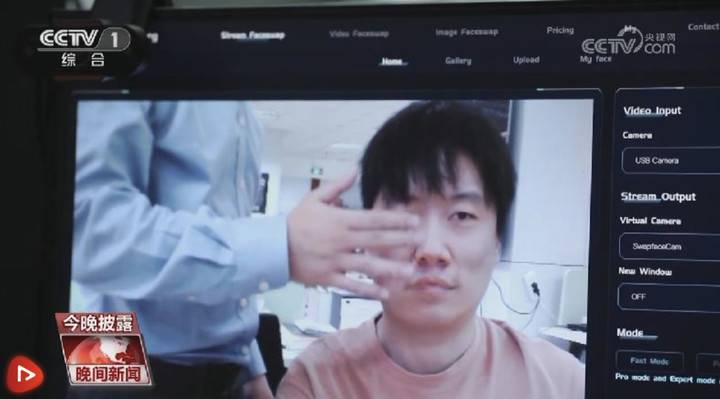
转动头部的原理也是一样,如果在收集数据的阶段,对方没有特意采集大于 45 度的转头素材,那么脸部贴合的形迹就会不自然。
但未来,这种肉眼可见的瑕疵,肯定会慢慢减少。

美国西北大学的「找茬」测试:AI-generated or Real?
陈鹏开玩笑说,如果诈骗分子觉得你是只待宰的肥羊,存了心要骗你,扒光你的社交媒体信息,花好几天优化你的模型,那么这些方法也不保证有用。
一个视频如果没有出现这些瑕疵的话,那就说明它是真视频?这不是的。 至于说有效没效,那肯定不能完全有效、百分百有效,就是一定程度上有效。
换成专业一些的说法,人类的视觉感知,在语义层次上表现得很好,比如能够轻松分辨出物体或场景的含义,但在处理像素级别的、低层次的细微差别时,感知能力不如 AI 模型。
从这个角度看,陈鹏认为,普通人在分辨 Deepfake 上已经一败涂地,专家或许还有一战之力,因为看得太多,分析能力比较全面,可以看出某个地方不符合规律。

我们都不是列文虎克,也没有火眼金睛,但人性亘古不变。所以,我们也可以拉起传统的、和技术无关的心理防线——小心驶得万年船。
诈骗往往万变不离其宗:窃取隐私,利用恐惧、贪欲、情绪价值编故事,冒充熟人或包装自己获取信任,图穷匕见以钱为最终目的。

瑞莱智慧旗下产品 RealBelieve,会在视频通话时发出预警
牢记这点,然后提高戒心,不点陌生链接,不随便给验证码,尽量不在互联网过度暴露人脸、声音、指纹等个人生物信息,接到可疑电话,谈到钱就多个心眼,多种方式验证对方身份,比如询问只有彼此知道的事情。
古语有云,攻心为上,我们一旦意识到自己有可能被骗,那么就有可能不被骗。
提高防诈意识还不够,韩国「N 号房 2.0」事件,展现了 Deepfake 的另一种作恶形式。人在家中坐,锅从天上来。
虚假裸照的受害者,可能遇上「复仇色情」——加害者以传播 Deepfake 材料为威胁,勒索和骚扰受害人,造成更严重的二次伤害。
但这把镰刀也可能举到我们头上:想象一下,诈骗团伙不知道从哪里拿到你的照片,合成到低俗视频,发短信威胁你,不转账,就全网曝光,你该如何自证?
陈鹏所在的瑞莱智慧,确实遇到过这类个人业务,对方说被视频换脸,能不能还他个清白。
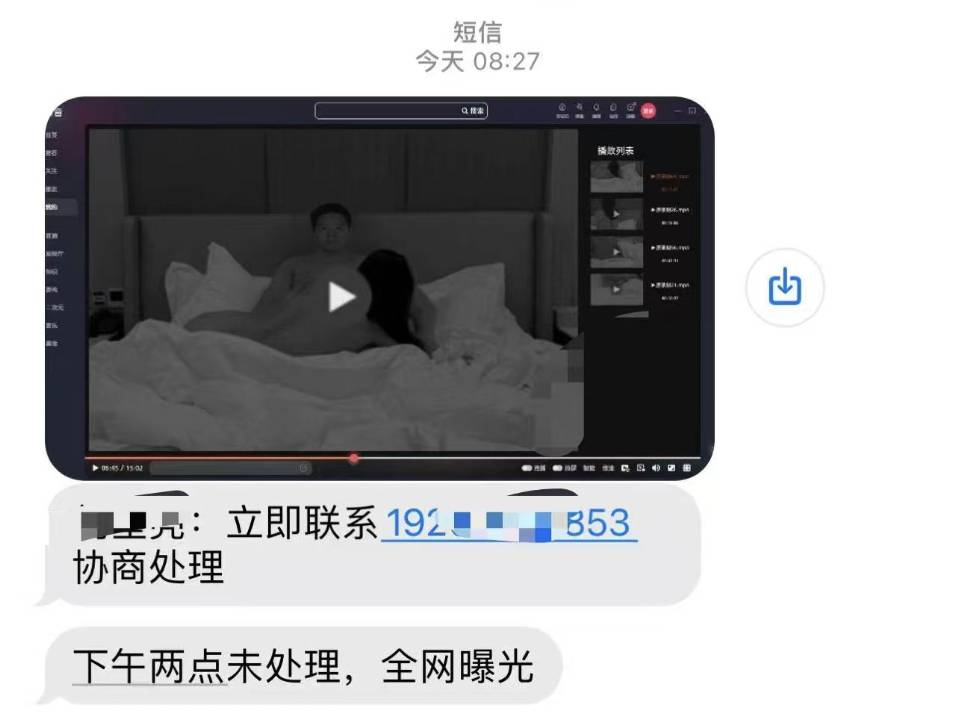
方法当然是有的:魔法对轰魔法,AI 打败 AI。
陈鹏介绍,AI 鉴伪主要有两条技术路线:主动式防御,被动式检测。
先说主动式防御,当我们在社交媒体发了照片,不希望照片被别人利用,那么可以在其中嵌入一些视觉上不可感知的噪声。
如果别人拿我们的照片训练模型,因为这种隐形的干扰,AI 没法很好地提取其中的视觉表征,最终出来的结果可能扭曲或者变糊,这叫作「对抗样本攻击」。
「半脆弱性水印」,是另一种主动式防御的方式。添加水印之后,如果别人编辑了我们的照片,这个水印会被破坏,我们就可以知道,这个图片被处理过了,不太可信。
水印不能直接阻止图片被 Deepfake,但可以检测和认证图片的真实性。
海外也有类似探索,Adobe 发起 C2PA 标准,利用元数据参数,作为图片出处的判定方式
当然,主动式防御的门槛较高,我们需要防患于未然,提前对图片进行一些处理。
更常见的情况是,我们没法未卜先知,收到自己的「裸照」,却也是第一次和自己这样「坦诚相见」。这时候,就要用上被动式检测。
瑞莱智慧旗下有一系列负责鉴伪的 AI 产品,包括生成式 AI 内容检测平台 DeepReal、人脸 AI 安全防火墙 RealGuard 等等。
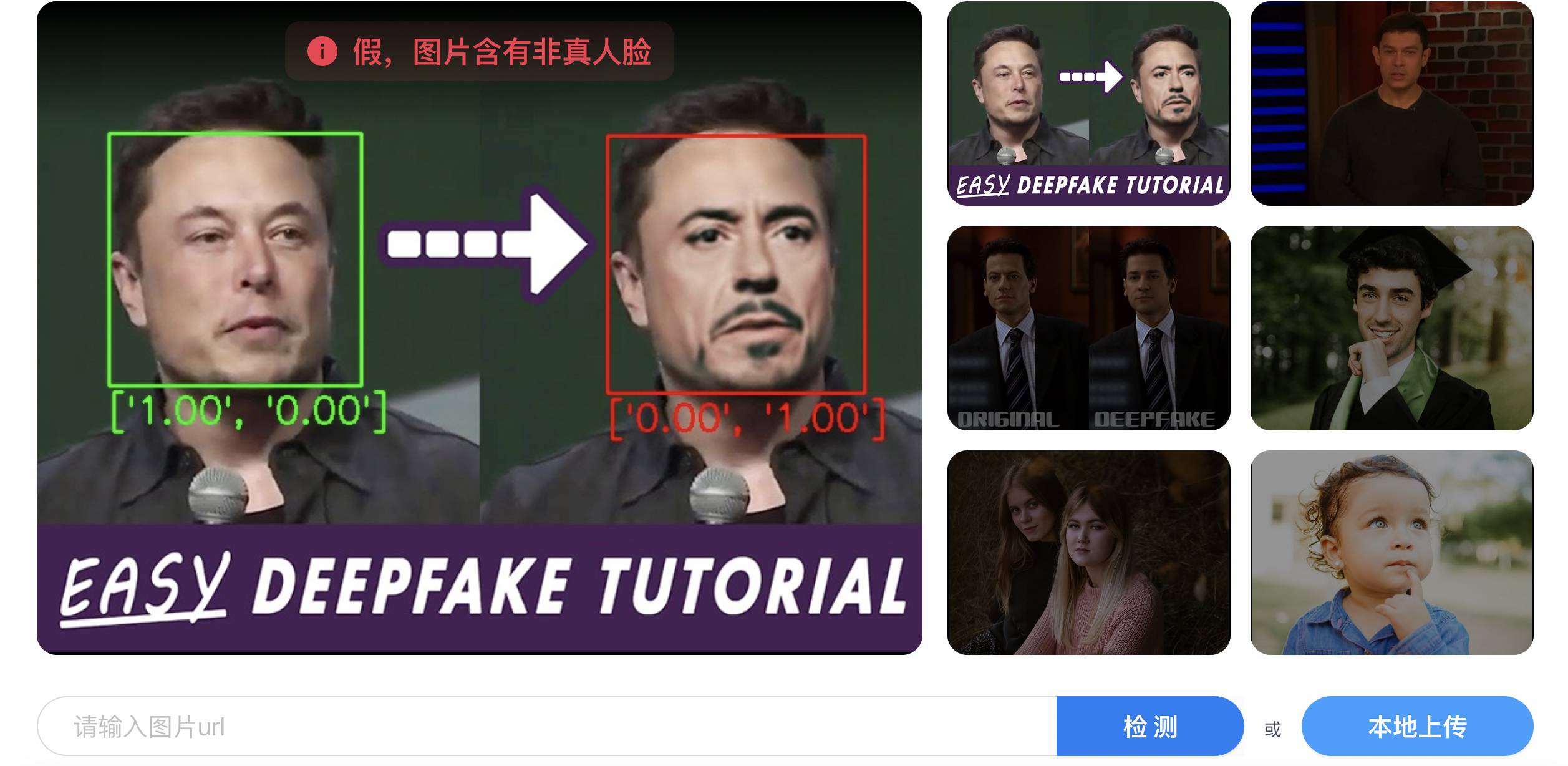
DeapReal
简单来说,用 AI 鉴别 AI,分为两个环节,先提取大量的伪造特征,再基于这些样本建模,让 AI 学习鉴伪的规律。
颜色的扭曲、纹理的不合理、表情的不自然、音画的不同步、虹膜形状的不规则、两个瞳孔高光的不一致,都是 AI 的学习素材。
其中,视频的鉴伪,可能比图像的准确率更高,因为视频由一系列连续的图像组成,相比单独的图像,提供了更多可以用于鉴伪的信息,比如人物在不同帧之间的动作连续性。
本质上,AI 鉴伪有些像人类用肉眼找茬,也是在利用 AI 模型本身的瑕疵。

中科院研究人员向全球开源了检测 Deepfake 的 AI 模型
但瑕疵肯定会逐渐改善,所以产生了一个很关键的问题:是先有伪造,后有鉴伪吗?如果如此,鉴伪不是永远落后伪造半拍吗?
陈鹏回答,生成的技术,可能略微领先鉴伪的技术,但他们内部有红蓝对抗的攻防实验室,一边模拟 Deepfake,一边防御 Deepfake,不断提高 Deepfake 的检测能力。
如果有什么新的 Deepfake 技术面世,他们可以很快复现,然后在检测产品上进行验证,「新的技术出来,即使我没有见过,我还是能够一定程度上检测出来」。
而且,模型本身也有一定的泛化能力,见过的 Deepfake 内容多了,碰上没见过的,一定程度上也可以准确识别和检测。
B 站等平台会对 AI 换脸娱乐内容进行标注
总之,AI 伪造和鉴伪,是一个长期对抗、互相博弈的「猫鼠游戏」。
这也是为什么,陈鹏一直在研究 AI 鉴伪算法:
反 Deepfake 对抗性太强了,需要长期投入,不像很多 AI 产品,做完就不用管了。
尽管如此,他仍然比较乐观:「用法律法规监管,平台进行内容治理,产业界提供技术和工具,媒体让更多人意识到风险,多方面治理到一定程度,肯定会有缓和。」
以后上网,我们可能会陷入这样一个有些荒谬的场景:验证码让你证明「我是人」,Deepfake 又让你证明「我不是我」。
技术没法完全检测出所有的恶意,但人类也不必过于焦虑,Deepfake 的得逞只是最后的结果,防范 Deepfake 却可以随时开始。
就像陈鹏所说,即使一个非常简单的 AI 产品,也是一个很系统性的工程。
我们是更大的系统里的部分,让受伤的人发声,让加害的人被罚,让阻止恶行的技术介入,让社会的观念抬高一寸,我们才能共同走向一个技术不被恐惧而是被合理使用的未来。
张成晨
利若秋霜,辟除凶殃。 工作邮箱:zhangchengchen@ifanr.com
邮箱8
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
爱范儿|原文链接· ·新浪微博
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号