Redis全解析:一篇文章带你掌握
发表时间: 2023-02-07 10:21
作者: 京东物流 刘丽侠 姚再毅 康睿 刘斌 李振
Redis的数据类型有String、Hash、Set、List、Zset、bitMap(基于String类型)、 Hyperloglog(基于String类型)、Geo(地理位置)、Streams流。
// 批量设置> mset key1 value1 key2 value2// 批量获取> mget key1 key2// 获取长度> strlen key // 字符串追加内容> append key xxx// 获取指定区间的字符> getrange key 0 5// 整数值递增 (递增指定的值)> incr intkey (incrby intkey 10)// 当key 存在时将覆盖> SETEX key seconds value// 将 key 的值设为 value ,当且仅当 key 不存在。> SETNX key value// 将哈希表 key 中的域 field 的值设为 value 。> HSET key field value// 返回哈希表 key 中给定域 field 的值。> HGET key field// 返回哈希表 key 中的所有域。> HKEYS key// 返回哈希表 key 中所有域的值。> HVALS key// 为哈希表 key 中的域 field 的值加上增量 increment 。> HINCRBY key field increment// 查看哈希表 key 中,给定域 field 是否存在。> HEXISTS key field存储有序的字符串列表,元素可以重复。列表的最大长度为 2^32 - 1 个元素(4294967295,每个列表超过 40 亿个元素)。
// 将一个或多个值 value 插入到列表 key 的表头> LPUSH key value [value ...]// 将一个或多个值 value 插入到列表 key 的表尾(最右边)。> RPUSH key value [value ...]// 移除并返回列表 key 的头元素。> LPOP key// 移除并返回列表 key 的尾元素。> RPOP key// BLPOP 是列表的阻塞式(blocking)弹出原语。> BLPOP key [key ...] timeout// BRPOP 是列表的阻塞式(blocking)弹出原语。> BRPOP key [key ...] timeout// 获取指点位置元素> LINDEX key index因为list是有序的,所以我们可以先进先出,先进后出的列表都可以做
// 将一个或多个 member 元素加入到集合 key 当中,已经存在于集合的 member 元素将被忽略。> SADD key member [member ...]// 返回集合 key 中的所有成员。> SMEMBERS key// 返回集合 key 的基数(集合中元素的数量)。> SCARD key// 如果命令执行时,只提供了 key 参数,那么返回集合中的一个随机元素。> SRANDMEMBER key [count]// 移除并返回集合中的一个随机元素。> SPOP key// 移除集合 key 中的一个或多个 member 元素,不存在的 member 元素会被忽略。> SREM key member [member ...]// 判断 member 元素是否集合 key 的成员。> SISMEMBER key member// 获取前一个集合有而后面1个集合没有的> sdiff huihuiset huihuiset1// 获取交集> sinter huihuiset huihuiset1// 获取并集> sunion huihuiset huihuiset1sorted set,有序的set,每个元素有个score。
score相同时,按照key的ASCII码排序。
//将一个或多个 member 元素及其 score 值加入到有序集 key 当中。> ZADD key score member [[score member] [score member] ...]// 返回有序集 key 中,指定区间内的成员。其中成员的位置按 score 值递增(从小到大)来排序> ZRANGE key start stop [WITHSCORES]// 返回有序集 key 中,指定区间内的成员。其中成员的位置按 score 值递减(从大到小)来排列。> ZREVRANGE key start stop [WITHSCORES]// 返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。> ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]// 移除有序集 key 中的一个或多个成员,不存在的成员将被忽略。> ZREM key member [member ...]// 返回有序集 key 的基数。> ZCARD key// 为有序集 key 的成员 member 的 score 值加上增量 increment 。> ZINCRBY key increment member// 返回有序集 key 中, score 值在 min 和 max 之间(默认包括 score 值等于 min 或 max )的成员的数量。> ZCOUNT key min max// 返回有序集 key 中成员 member 的排名。其中有序集成员按 score 值递增(从小到大)顺序排列。> ZRANK key member// 1. multi命令开启事务,exec命令提交事务127.0.0.1:6379> multiOK127.0.0.1:6379(TX)> set k1 v1QUEUED127.0.0.1:6379(TX)> set k2 v2QUEUED127.0.0.1:6379(TX)> exec1) OK2) OK// 2. 组队的过程中可以通过discard来放弃组队。 127.0.0.1:6379> multiOK 127.0.0.1:6379(TX)> set k3 v3QUEUED 127.0.0.1:6379(TX)> set k4 v4QUEUED 127.0.0.1:6379(TX)> discardOK事务中的所有命令都会序列化、按顺序地执行。
事务在执行过程中,不会被其他客户端发送来的命令请求所打断。
队列中的命令没有提交之前,都不会被实际地执行,因为事务提交之前任何指令都不会被实际执行,也就不存在“事务内的查询要看到事务里的更新,在事务外查询不能看到”这个让人万分头疼的问题。
Redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚。
local lockSet = redis.call('exists', KEYS[1])if lockSet == 0 then redis.call('set', KEYS[1], ARG[1]) redis.call('expire', KEYS[1], ARG[2]) endreturn lockSet数据最外层的结构为RedisDb
typedef struct redisDb { dict *dict; /* The keyspace for this DB */ //数据库的键 dict *expires; /* Timeout of keys with a timeout set */ //设置了超时时间的键 dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/ //客户端等待的keys dict *ready_keys; /* Blocked keys that received a PUSH */ dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */ int id; /* Database ID */ //所在数 据库ID long long avg_ttl; /* Average TTL, just for tats */ //平均TTL,仅用于统计 unsigned long expires_cursor; /* Cursor of the active expire cycle. */ list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */} redisDb;我们发现数据存储在dict中
typedef struct dict { dictType *type; //理解为面向对象思想,为支持不同的数据类型对应dictType抽象方法,不同的数据类型可以不同实现 void *privdata; //也可不同的数据类型相关,不同类型特定函数的可选参数。 dictht ht[2]; //2个hash表,用来数据存储 2个dictht long rehashidx; /* rehashing not in progress if rehashidx == -1 */ // rehash标记 -1代表不再rehash unsigned long iterators; /* number of iterators currently running */} dict;typedef struct dictht { dictEntry **table; //dictEntry 数组 unsigned long size; //数组大小 默认为4 #define DICT_HT_INITIAL_SIZE 4 unsigned long sizemask; //size-1 用来取模得到数据的下标值 unsigned long used; //改hash表中已有的节点数据} dictht;typedef struct dictEntry { void *key; //key union { void *val; uint64_t u64; int64_t s64; double d; } v; //value struct dictEntry *next; //指向下一个节点} dictEntry;/* Objects encoding. Some kind of objects like Strings andHashes can be* internally represented in multiple ways. The 'encoding'field of the object* is set to one of this fields for this object. */#define OBJ_ENCODING_RAW 0 /* Raw representation */#define OBJ_ENCODING_INT 1 /* Encoded as integer */#define OBJ_ENCODING_HT 2 /* Encoded as hash table */#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: oldlist encoding. */#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds stringencoding */#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked listof ziplists */#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix treeof listpacks */#define LRU_BITS 24#define LRU_CLOCK_MAX ((1<<LRU_BITS)-1) /* Max value ofobj->lru */#define LRU_CLOCK_RESOLUTION 1000 /* LRU clock resolutionin ms */#define OBJ_SHARED_REFCOUNT INT_MAX /* Global objectnever destroyed. */#define OBJ_STATIC_REFCOUNT (INT_MAX-1) /* Objectallocated in the stack. */#define OBJ_FIRST_SPECIAL_REFCOUNT OBJ_STATIC_REFCOUNTtypedef struct redisObject {unsigned type:4; //数据类型 string hash listunsigned encoding:4; //底层的数据结构 跳表unsigned lru:LRU_BITS; /* LRU time (relative to globallru_clock) or* LFU data (least significant8 bits frequency* and most significant 16 bitsaccess time). */int refcount; //用于回收,引用计数法void *ptr; //指向具体的数据结构的内存地址 比如 跳表、压缩列表} robj;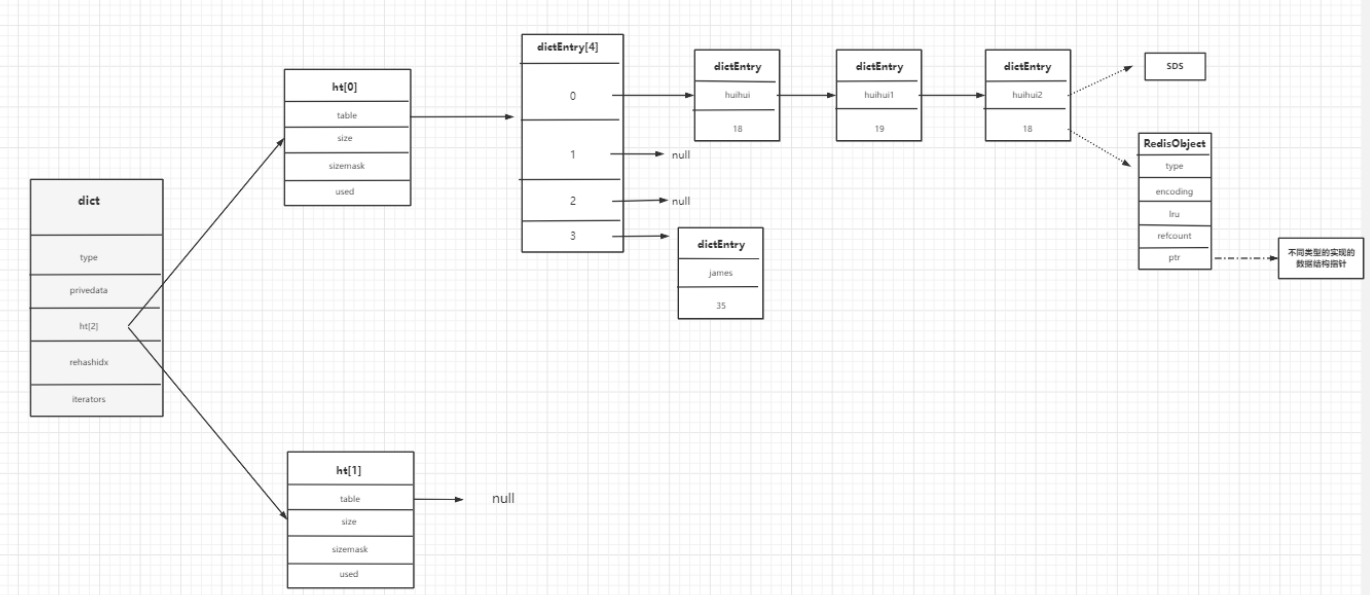
因为我们的dictEntry数组默认大小是4,如果不进行扩容,那么我们所有的数据都会以链表的形式添加至数组下标 随着数据量越来越大,之前只需要hash取模就能得到下标位置,现在得去循环我下标的链表,所以性能会越来越慢,当我们的数据量达到一定程度后,我们就得去触发扩容操作。
扩容,肯定是在添加数据的时候才会扩容,所以我们找一个添加数据的入口。
int dictReplace(dict *d, void *key, void *val) { dictEntry *entry, *existing, auxentry; /* Try to add the element. If the key * does not exists dictAdd will succeed. */ entry = dictAddRaw(d,key,&existing); if (entry) { dictSetVal(d, entry, val); return 1; } /* Set the new value and free the old one. Note that it is important * to do that in this order, as the value may just be exactly the same * as the previous one. In this context, think to reference counting, * you want to increment (set), and then decrement (free), and not the * reverse. */ auxentry = *existing; dictSetVal(d, existing, val); dictFreeVal(d, &auxentry); return 0;}dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing){ long index; dictEntry *entry; dictht *ht; if (dictIsRehashing(d)) _dictRehashStep(d); //如果正在Rehash 进行渐进式hash 按步rehash /* Get the index of the new element, or -1 if * the element already exists. */ if ((index = _dictKeyIndex(d, key, dictHashKey(d,key),existing)) == -1) return NULL; /* Allocate the memory and store the new entry. * Insert the element in top, with the assumption that in a database * system it is more likely that recently added entries are accessed * more frequently. */ //如果在hash 放在ht[1] 否则放在ht[0] ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0]; entry = zmalloc(sizeof(*entry)); //采用头插法插入hash桶 entry->next = ht->table[index]; ht->table[index] = entry; //已使用++ ht->used++; /* Set the hash entry fields. */ dictSetKey(d, entry, key); return entry;}static long _dictKeyIndex(dict *d, const void *key,uint64_t hash, dictEntry **existing){ unsigned long idx, table; dictEntry *he; if (existing) *existing = NULL; /* Expand the hash table if needed */ //扩容如果需要 if (_dictExpandIfNeeded(d) == DICT_ERR) return -1; //比较是否存在这个值 for (table = 0; table <= 1; table++) { idx = hash & d->ht[table].sizemask; /* Search if this slot does not already contain the given key */ he = d->ht[table].table[idx]; while(he) { if (key==he->key || dictCompareKeys(d, key,he->key)) { if (existing) *existing = he; return -1; } he = he->next; } if (!dictIsRehashing(d)) break; } return idx;}/* Expand the hash table if needed */static int _dictExpandIfNeeded(dict *d){ /* Incremental rehashing already in progress. Return.*/ if (dictIsRehashing(d)) return DICT_OK; //正在rehash,返回 /* If the hash table is empty expand it to the initialsize. */ //如果ht[0]的长度为0,设置默认长度4 dictExpand为扩容的关键方法 if (d->ht[0].size == 0) return dictExpand(d,DICT_HT_INITIAL_SIZE); //扩容条件 hash表中已使用的数量大于等于 hash表的大小 //并且dict_can_resize为1 或者 已使用的大小大于hash表大小的 5倍,大于等于1倍的时候,下面2个满足一个条件即可 if (d->ht[0].used >= d->ht[0].size && (dict_can_resize || d->ht[0].used/d->ht[0].size >dict_force_resize_ratio)){ //扩容成原来的2倍 return dictExpand(d, d->ht[0].used*2); } return DICT_OK;}int dictExpand(dict *d, unsigned long size){ /* the size is invalid if it is smaller than the number of * elements already inside the hash table */ //正在扩容,不允许第二次扩容,或者ht[0]的数据量大于扩容后的数量,没有意义,这次不扩容 if (dictIsRehashing(d) || d->ht[0].used > size) return DICT_ERR; dictht n; /* the new hash table */ //得到最接近2的幂 跟hashMap思想一样 unsigned long realsize = _dictNextPower(size); /* Rehashing to the same table size is not useful. */ //如果跟ht[0]的大小一致 直接返回错误 if (realsize == d->ht[0].size) return DICT_ERR; /* Allocate the new hash table and initialize all pointers to NULL */ //为新的dictht赋值 n.size = realsize; n.sizemask = realsize-1; n.table = zcalloc(realsize*sizeof(dictEntry*)); n.used = 0; /* Is this the first initialization? If so it's not really a rehashing * we just set the first hash table so that it can accept keys. */ //ht[0].table为空,代表是初始化 if (d->ht[0].table == NULL) { d->ht[0] = n; return DICT_OK; } /* Prepare a second hash table for incremental rehashing */ //将扩容后的dictht赋值给ht[1] d->ht[1] = n; //标记为0,代表可以开始rehash d->rehashidx = 0; return DICT_OK;}假如一次性把数据全部迁移会很耗时间,会让单条指令等待很久,会形成阻塞。
所以,redis采用渐进式Rehash,所谓渐进式,就是慢慢的,不会一次性把所有数据迁移。
那什么时候会进行渐进式数据迁移?
if (dictIsRehashing(d)) _dictRehashStep(d); //这个代码在增删改查的方法中都会调用static void _dictRehashStep(dict *d) { if (d->iterators == 0) dictRehash(d,1);}int dictRehash(dict *d, int n) { int empty_visits = n*10; /* Max number of empty buckets to visit. */ //要访问的最大的空桶数 防止此次耗时过长 if (!dictIsRehashing(d)) return 0; //如果没有在rehash返回0 //循环,最多1次,并且ht[0]的数据没有迁移完 进入循环 while(n-- && d->ht[0].used != 0) { dictEntry *de, *nextde; /* Note that rehashidx can't overflow as we are sure there are more * elements because ht[0].used != 0 */ assert(d->ht[0].size > (unsigned long)d->rehashidx); //rehashidx rehash的索引,默认0 如果hash桶为空 进入自旋 并且判断是否到了最大的访问空桶数 while(d->ht[0].table[d->rehashidx] == NULL) { d->rehashidx++; if (--empty_visits == 0) return 1; } de = d->ht[0].table[d->rehashidx]; //得到ht[0]的下标为rehashidx桶 /* Move all the keys in this bucket from the old to the new hash HT */ while(de) { //循环hash桶的链表 并且转移到ht[1] uint64_t h; nextde = de->next; /* Get the index in the new hash table */ h = dictHashKey(d, de->key) & d- >ht[1].sizemask; de->next = d->ht[1].table[h]; //头插 d->ht[1].table[h] = de; d->ht[0].used--; d->ht[1].used++; de = nextde; } //转移完后 将ht[0]相对的hash桶设置为null d->ht[0].table[d->rehashidx] = NULL; d->rehashidx++; } /* Check if we already rehashed the whole table... */ //ht[0].used=0 代表rehash全部完成 if (d->ht[0].used == 0) { //清空ht[0]table zfree(d->ht[0].table); //将ht[0] 重新指向已经完成rehash的ht[1] d->ht[0] = d->ht[1]; //将ht[1]所有数据重新设置 _dictReset(&d->ht[1]); //设置-1,代表rehash完成 d->rehashidx = -1; return 0; } /* More to rehash... */ return 1;}//将ht[1]的属性复位static void _dictReset(dictht *ht){ ht->table = NULL; ht->size = 0; ht->sizemask = 0; ht->used = 0;}再讲定时任务之前,我们要知道Redis中有个时间事件驱动,在 server.c文件下有个serverCron 方法。
serverCron 每隔多久会执行一次,执行频率根据redis.conf中的hz配置,serverCorn中有个方法databasesCron()
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) { //....... /* We need to do a few operations on clients asynchronously. */ clientsCron(); /* Handle background operations on Redis databases. */ databasesCron(); //处理Redis数据库上的后台操作。 //.......}void databasesCron(void) { /* Expire keys by random sampling. Not required for slaves * as master will synthesize DELs for us. */ if (server.active_expire_enabled) { if (iAmMaster()) { activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW); } else { expireSlaveKeys(); } } /* Defrag keys gradually. */ activeDefragCycle(); /* Perform hash tables rehashing if needed, but only if there are no * other processes saving the DB on disk. Otherwise rehashing is bad * as will cause a lot of copy-on-write of memory pages. */ if (!hasActiveChildProcess()) { /* We use global counters so if we stop the computation at a given * DB we'll be able to start from the successive in the next * cron loop iteration. */ static unsigned int resize_db = 0; static unsigned int rehash_db = 0; int dbs_per_call = CRON_DBS_PER_CALL; int j; /* Don't test more DBs than we have. */ if (dbs_per_call > server.dbnum) dbs_per_call = server.dbnum; /* Resize */ for (j = 0; j < dbs_per_call; j++) { tryResizeHashTables(resize_db % server.dbnum); resize_db++; } /* Rehash */ //Rehash逻辑 if (server.activerehashing) { for (j = 0; j < dbs_per_call; j++) { //进入incrementallyRehash int work_done = incrementallyRehash(rehash_db); if (work_done) { /* If the function did some work, stop here, we'll do * more at the next cron loop. */ break; } else { /* If this db didn't need rehash, we'll try the next one. */ rehash_db++; rehash_db %= server.dbnum; } } } }} int incrementallyRehash(int dbid) { /* Keys dictionary */ if (dictIsRehashing(server.db[dbid].dict)) { dictRehashMilliseconds(server.db[dbid].dict,1); return 1; /* already used our millisecond for this loop... */ } /* Expires */ if (dictIsRehashing(server.db[dbid].expires)) { dictRehashMilliseconds(server.db[dbid].expires,1); return 1; /* already used our millisecond for this loop... */ } return 0;}int dictRehashMilliseconds(dict *d, int ms) { long long start = timeInMilliseconds(); int rehashes = 0; //进入rehash方法 dictRehash 去完成渐进时HASH while(dictRehash(d,100)) { rehashes += 100; //判断是否超时 if (timeInMilliseconds()-start > ms) break; } return rehashes;}Redis中String的底层没有用c的char来实现,而是采用了SDS(simple Dynamic String)的数据结构来实现。并且提供了5种不同的类型
typedef char *sds;/* Note: sdshdr5 is never used, we just access the flags byte directly. * However is here to document the layout of type 5 SDSstrings. */struct __attribute__ ((__packed__)) sdshdr5 { unsigned char flags; /* 3 lsb of type, and 5 msb of string length */ char buf[];}struct __attribute__ ((__packed__)) sdshdr8 { uint8_t len; /* used */ //已使用的长度 uint8_t alloc; /* excluding the header and null terminator */ //分配的总容量 不包含头和空终止符 unsigned char flags; /* 3 lsb of type, 5 unused bits */ //低三位类型 高5bit未使用 char buf[]; //数据buf 存储字符串数组};struct __attribute__ ((__packed__)) sdshdr16 { uint16_t len; /* used */ uint16_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];};struct __attribute__ ((__packed__)) sdshdr32 { uint32_t len; /* used */ uint32_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];};struct __attribute__ ((__packed__)) sdshdr64 { uint64_t len; /* used */ uint64_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];};Redis的字典相当于Java语言中的HashMap,他是无序字典。内部结构上同样是数组 + 链表二维结构。第一维hash的数组位置碰撞时,就会将碰撞的元素使用链表串起来。
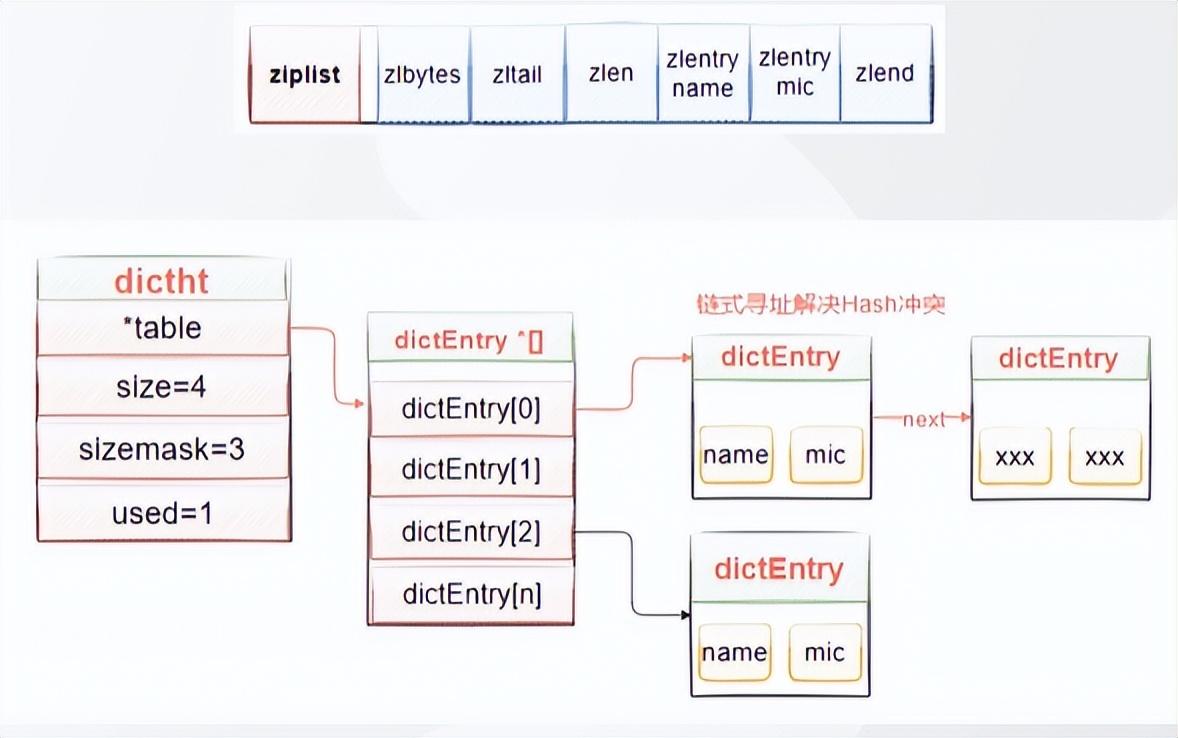
压缩列表会根据存入的数据的不同类型以及不同大小,分配不同大小的空间。所以是为了节省内存而采用的。
因为是一块完整的内存空间,当里面的元素发生变更时,会产生连锁更新,严重影响我们的访问性能。所以,只适用于数据量比较小的场景。
所以,Redis会有相关配置,Hashes只有小数据量的时候才会用到ziplist,当hash对象同时满足以下两个条件的时候,使用ziplist编码:
hash-max-ziplist-value 64 // ziplist中最大能存放的值长度hash-max-ziplist-entries 512 // ziplist中最多能存放的entry节点数量兼顾了ziplist的节省内存,并且一定程度上解决了连锁更新的问题,我们的 quicklistNode节点里面是个ziplist,每个节点是分开的。那么就算发生了连锁更新,也只会发生在一个quicklistNode节点。
quicklist.h文件
typedef struct{ struct quicklistNode *prev; //前指针 struct quicklistNode *next; //后指针 unsigned char *zl; //数据指针 指向ziplist结果 unsigned int sz; //ziplist大小 /* ziplist size in bytes */ unsigned int count : 16; /* count of items in ziplist */ //ziplist的元素 unsigned int encoding : 2; /* RAW==1 or LZF==2 */ // 是否压缩, 1没有压缩 2 lzf压缩 unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */ //预留容器字段 unsigned int recompress : 1; /* was this node previous compressed? */ unsigned int attempted_compress : 1; /* node can't compress; too small */ unsigned int extra : 10; /* more bits to steal for future usage */ //预留字段} quicklistNode;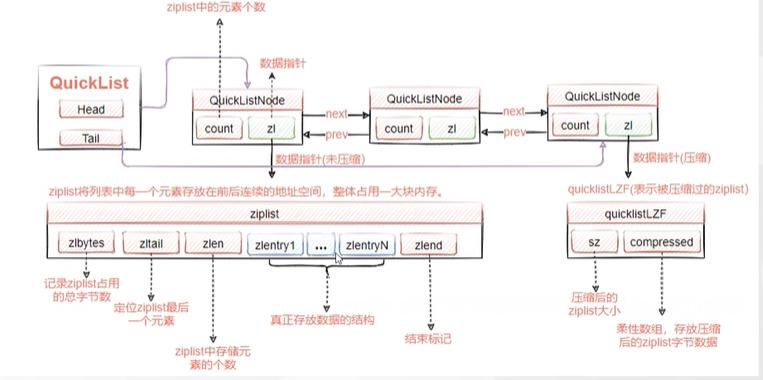
Redis用intset或hashtable存储set。满足下面条件,就用inset存储。
set-max-intset-entries 512不满足上述条件的,都使用hash表存储,value存null。
默认使用ziplist编码。
在ziplist的内部,按照score排序递增来存储。插入的时候要移动之后的数据。
如果元素数量大于等于128个,或者任一member长度大于等于64字节使用 skiplist+dict存储。
zset-max-ziplist-entries 128zset-max-ziplist-value 64如果不满足条件,采用跳表。
结构定义(servier.h)
/* ZSETs use a specialized version of Skiplists */typedef struct zskiplistNode { sds ele; //sds数据 double score; //score struct zskiplistNode *backward; //后退指针 //层级数组 struct zskiplistLevel { struct zskiplistNode *forward; //前进指针 unsigned long span; //跨度 } level[];} zskiplistNode;//跳表列表typedef struct zskiplist { struct zskiplistNode *header, *tail; //头尾节点 unsigned long length; //节点数量 int level; //最大的节点层级} zskiplist;zslInsert 添加节点方法 (t_zset.c)
zskiplistNode *zslInsert(zskiplist *zsl, double score, sdsele) { zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x; unsigned int rank[ZSKIPLIST_MAXLEVEL]; int i, level; serverAssert(!isnan(score)); x = zsl->header; for (i = zsl->level-1; i >= 0; i--) { /* store rank that is crossed to reach the insert position */ rank[i] = i == (zsl->level-1) ? 0 : rank[i+1]; while (x->level[i].forward && (x->level[i].forward->score < score || 咕泡出品 必属精品精品属精品 咕泡出品 必属精品 咕泡出品 必属精品 咕泡咕泡 (x->level[i].forward->score == score && sdscmp(x->level[i].forward->ele,ele) < 0))) { rank[i] += x->level[i].span; x = x->level[i].forward; } update[i] = x; } /* we assume the element is not already inside, since we allow duplicated * scores, reinserting the same element should never happen since the * caller of zslInsert() should test in the hash table if the element is * already inside or not. */ level = zslRandomLevel(); if (level > zsl->level) { for (i = zsl->level; i < level; i++) { rank[i] = 0; update[i] = zsl->header; update[i]->level[i].span = zsl->length; } zsl->level = level; } x = zslCreateNode(level,score,ele); //不同层级建立链表联系 for (i = 0; i < level; i++) { x->level[i].forward = update[i]->level[i].forward; update[i]->level[i].forward = x; /* update span covered by update[i] as x is inserted here */ x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]); update[i]->level[i].span = (rank[0] - rank[i]) + 1; } /* increment span for untouched levels */ for (i = level; i < zsl->level; i++) { update[i]->level[i].span++; } x->backward = (update[0] == zsl->header) ? NULL : update[0]; if (x->level[0].forward) x->level[0].forward->backward = x; else zsl->tail = x; zsl->length++; return x;}ZSKIPLIST_MAXLEVEL默认32 定义在server.h
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^64elements */所谓惰性过期,就是在每次访问操作key的时候,判断这个key是不是过期了,过期了就删除。
int expireIfNeeded(redisDb *db, robj *key) { if (!keyIsExpired(db,key)) return 0; /* If we are running in the context of a slave, instead of * evicting the expired key from the database, we return ASAP: * the slave key expiration is controlled by the master that will * send us synthesized DEL operations for expired keys. * * Still we try to return the right information to the caller, * that is, 0 if we think the key should be still valid, 1 if * we think the key is expired at this time. */ // 如果配置有masterhost,说明是从节点,那么不操作删除 if (server.masterhost != NULL) return 1; /* Delete the key */ server.stat_expiredkeys++; propagateExpire(db,key,server.lazyfree_lazy_expire); notifyKeyspaceEvent(NOTIFY_EXPIRED, "expired",key,db->id); //是否是异步删除 防止单个Key的数据量很大 阻塞主线程 是4.0之后添加的新功能,默认关闭 int retval = server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) : dbSyncDelete(db,key); if (retval) signalModifiedKey(NULL,db,key); return retval;}每次调用到相关指令时,才会执行expireIfNeeded判断是否过期,平时不会去判断是否过期。
该策略可以最大化的节省CPU资源。
但是却对内存非常不友好。因为如果没有再次访问,就可能一直堆积再内存中。占用内存
所以就需要另一种策略来配合使用,就是定期过期
那么多久去清除一次,我们在讲Rehash的时候,有个方法是serverCron,执行频率根据redis.conf中的hz配置。
这方法除了做Rehash以外,还会做很多其他的事情,比如:
// serverCron方法调用databasesCron方法(server.c)/* Handle background operations on Redis databases. */databasesCron();void databasesCron(void) { /* Expire keys by random sampling. Not required for slaves * as master will synthesize DELs for us. */ if (server.active_expire_enabled) { if (iAmMaster()) { activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW); //过期删除方法 } else { expireSlaveKeys(); } }}由于Redis内存是有大小的,并且我可能里面的数据都没有过期,当快满的时候,我又没有过期的数据进行淘汰,那么这个时候内存也会满。内存满了,Redis也会不能放入新的数据。所以,我们不得已需要一些策略来解决这个问题来保证可用性。
New values aren’t saved when memory limit is reached. When a database uses replication, this applies to the primary database.
默认,不淘汰 能读不能写
Keeps most recently used keys; removes least recently used (LRU) keys
基于伪LRU算法,在所有的key中去淘汰
Keeps frequently used keys; removes least frequently used (LFU) keys.
基于伪LFU算法,在所有的key中去淘汰
Removes least recently used keys with the expire field set to true.
基于伪LRU算法,在设置了过期时间的key中去淘汰
Removes least frequently used keys with the expire field set to true.
基于伪LFU算法 在设置了过期时间的key中去淘汰
Randomly removes keys to make space for the new data added.
基于随机算法,在所有的key中去淘汰
Randomly removes keys with expire field set to true.
基于随机算法 在设置了过期时间的key中去淘汰
Removes least frequently used keys with expire field set to true and the shortest remaining time-to-live (TTL) value.
根据过期时间来,淘汰即将过期的
Lru,Least Recently Used 翻译过来是最久未使用,根据时间轴来走,仍很久没用的数据。只要最近有用过,我就默认是有效的。
那么它的一个衡量标准是啥?时间!根据使用时间,从近到远,越远的越容易淘汰。
需求:得到对象隔多久没访问,隔的时间越久,越容易被淘汰
redis中,对象都会被redisObject对象包装,其中有个字段叫lru。
redisObject对象 (server.h文件)
typedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or * LFU data (least significant 8 bits frequency * and most significant 16 bits access time). */ int refcount; void *ptr;} robj;看LRU的字段的说明,那么我们大概能猜出来,redis去实现lru淘汰算法肯定跟我们这个对象的lru相关
并且这个字段的大小为24bit,那么这个字段记录的是对象操作访问时候的秒单位时间的后24bit
相当于:
long timeMillis=System.currentTimeMillis();System.out.println(timeMillis/1000); //获取当前秒System.out.println(timeMillis/1000 & ((1<<24)-1)); //获取秒的后24位我们知道了这个对象的最后操作访问的时间。如果我们要得到这个对象多久没访问了,我们是不是就很简单,用我当前的时间-这个对象的访问时间就可以了!但是这个访问时间是秒单位时间的后24bit 所以,也是用当前的时间的秒单位的后24bit去减。
estimateObjectIdleTime方法(evict.c)
unsigned long long estimateObjectIdleTime(robj *o) { //获取秒单位时间的最后24位 unsigned long long lruclock = LRU_CLOCK(); //因为只有24位,所有最大的值为2的24次方-1 //超过最大值从0开始,所以需要判断lruclock(当前系统时间)跟缓存对象的lru字段的大小 if (lruclock >= o->lru) { //如果lruclock>=robj.lru,返回lruclock-o->lru,再转换单位 return (lruclock - o->lru) * LRU_CLOCK_RESOLUTION; } else { //否则采用lruclock + (LRU_CLOCK_MAX - o->lru),得到对 象的值越小,返回的值越大,越大越容易被淘汰 return (lruclock + (LRU_CLOCK_MAX - o->lru)) * LRU_CLOCK_RESOLUTION; }}用lruclock与 redisObject.lru进行比较,因为lruclock只获取了当前秒单位时间的后24位,所以肯定有个轮询。
所以,我们会用lruclock跟 redisObject.lru进行比较,如果lruclock>redisObject.lru,那么我们用lruclock- redisObject.lru,否则lruclock+(24bit的最大值-redisObject.lru),得到lru越小,那么返回的数据越大,相差越大的越优先会被淘汰!
https://www.processon.com/view/link/5fbe0541e401fd2d6ed8fc38
LFU,英文 Least Frequently Used,翻译成中文就是最不常用的优先淘汰。
不常用,它的衡量标准就是次数,次数越少的越容易被淘汰。
这个实现起来应该也很简单,对象被操作访问的时候,去记录次数,每次操作访问一次,就+1;淘汰的时候,直接去比较这个次数,次数越少的越容易淘汰!
何为时效性问题?就是只会去考虑数量,但是不会去考虑时间。
ps:去年的某个新闻很火,点击量3000W,今年有个新闻刚出来点击量100次,本来我们是想保留今年的新的新闻的,但是如果根据LFU来做的话,我们发现淘汰的是今年的新闻,明显是不合理的
导致的问题:新的数据进不去,旧的数据出不来。
那么如何解决呢,且往下看
我们还是来看redisObject(server.h)
typedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or * LFU data (least significant 8 bits frequency * and most significant 16 bits access time). */ int refcount; void *ptr;} robj;我们看它的lru,它如果在LFU算法的时候!它前面16位代表的是时间,后8位代表的是一个数值,frequency是频率,应该就是代表这个对象的访问次数,我们先给它叫做counter。
前16bits时间有啥用?
跟时间相关,我猜想应该是跟解决时效性相关的,那么怎么解决的?从生活中找例子
大家应该充过一些会员,比如我这个年纪的,小时候喜欢充腾讯的黄钻、绿钻、蓝钻等等。但是有一个点,假如哪天我没充钱了的话,或者没有续VIP的时候,我这个钻石等级会随着时间的流失而降低。比如我本来是黄钻V6,但是一年不充钱的话,可能就变成了V4。
那么回到Redis,大胆的去猜测,那么这个时间是不是去记录这个对象有多久没访问了,如果多久没访问,我就去减少对应的次数。
LFUDecrAndReturn方法(evict.c)
unsigned long LFUDecrAndReturn(robj *o) { //lru字段右移8位,得到前面16位的时间 unsigned long ldt = o->lru >> 8; //lru字段与255进行&运算(255代表8位的最大值), //得到8位counter值 unsigned long counter = o->lru & 255; //如果配置了lfu_decay_time,用LFUTimeElapsed(ldt) 除以配置的值 //LFUTimeElapsed(ldt)源码见下 //总的没访问的分钟时间/配置值,得到每分钟没访问衰减多少 unsigned long num_periods = server.lfu_decay_time ?LFUTimeElapsed(ldt) / server.lfu_decay_time : 0; if (num_periods) //不能减少为负数,非负数用couter值减去衰减值 counter = (num_periods > counter) ? 0 : counter - num_periods; return counter;}衰减因子由配置
lfu-decay-time 1 //多少分钟没操作访问就去衰减一次后8bits的次数,最大值是255,够不够?
肯定不够,一个对象的访问操作次数肯定不止255次。
但是我们可以让数据达到255的很难。那么怎么做的?这个比较简单,我们先看源码,然后再总结
LFULogIncr方法 (evict.c 文件)
uint8_t LFULogIncr(uint8_t counter) { //如果已经到最大值255,返回255 ,8位的最大值 if (counter == 255) return 255; //得到随机数(0-1) double r = (double)rand()/RAND_MAX; //LFU_INIT_VAL表示基数值(在server.h配置) double baseval = counter - LFU_INIT_VAL; //如果达不到基数值,表示快不行了,baseval =0 if (baseval < 0) baseval = 0; //如果快不行了,肯定给他加counter //不然,按照几率是否加counter,同时跟baseval与lfu_log_factor相关 //都是在分子,所以2个值越大,加counter几率越小 double p = 1.0/(baseval*server.lfu_log_factor+1); if (r < p) counter++; return counter;}自动触发
save 900 1 900s检查一次,至少有1个key被修改就触发save 300 10 300s检查一次,至少有10个key被修改就触发save 60 10000 60s检查一次,至少有10000个key被修改任何组件在正常关闭的时候,都会去完成应该完成的事。比如Mysql 中的Redolog持久化,正常关闭的时候也会去持久化。
数据清空指令会触发RDB操作,并且是触发一个空的RDB文件,所以, 如果在没有开启其他的持久化的时候,flushall是可以删库跑路的,在生产环境慎用。
优势
不足
由于RDB的数据可靠性非常低,所以Redis又提供了另外一种持久化方案: Append Only File 简称:AOF
AOF默认是关闭的,你可以在配置文件中进行开启:
appendonly no //默认关闭,可以进行开启# The name of the append only file (default:"appendonly.aof")appendfilename "appendonly.aof" //AOF文件名追加文件,即每次更改的命令都会附加到我的AOF文件中。
AOF会记录每个写操作,那么问题来了。我难道每次操作命令都要和磁盘交互?
当然不行,所以redis支持几种策略,由用户来决定要不要每次都和磁盘交互
# appendfsync always 表示每次写入都执行fsync(刷新)函数 性能会非常非常慢 但是非常安全appendfsync everysec 每秒执行一次fsync函数 可能丢失1s的数据# appendfsync no 由操作系统保证数据同步到磁盘,速度最快 你的数据只需要交给操作系统就行默认1s一次,最多有1s丢失
由于AOF是追加的形式,所以文件会越来越大,越大的话,数据加载越慢。 所以我们需要对AOF文件进行重写。
何为重写
比如 我们的incr指令,假如我们incr了100次,现在数据是100,但是我们的aof文件中会有100条incr指令,但是我们发现这个100条指令用处不大, 假如我们能把最新的内存里的数据保存下来的话。所以,重写就是做了这么一件事情,把当前内存的数据重写下来,然后把之前的追加的文件删除。
重写流程
但是重写是把当前内存的数据,写入一个新的AOF文件,如果当前数据比较大,然后以指令的形式写入的话,会很慢很慢
所以在4.0之后,在重写的时候是采用RDB的方式去生成新的AOF文件,然 后后续追加的指令,还是以指令追加的形式追加的文件末尾
aof-use-rdb-preamble yes //是否开启RDB与AOF混合模式什么时候重写
配置文件redis.conf
# 重写触发机制auto-aof-rewrite-percentage 100auto-aof-rewrite-min-size 64mb 就算达到了第一个百分比的大小,也必须大于 64M在 aof 文件小于64mb的时候不进行重写,当到达64mb的时候,就重写一次。重写后的 aof 文件可能是40mb。上面配置了auto-aof-rewritepercentag为100,即 aof 文件到了80mb的时候,进行重写。优势
不足
采用RDB或者不持久化, 会有数据丢失,因为是手动或者配置以快照的形式来进行备份。
解决:启用AOF,以命令追加的形式进行备份,但是默认也会有1s丢失, 这是在性能与数据安全性中寻求的一个最适合的方案,如果为了保证数据 一致性,可以将配置更改为always,但是性能很慢,一般不用。
因为Redis的数据是主异步同步给从的,提升了性能,但是由于是异步同步到从。所以存在数据丢失的可能
缓存雪崩就是Redis的大量热点数据同时过期(失效),因为设置了相同的过期时间,刚好这个时候Redis请求的并发量又很大,就会导致所有的请求落到数据库。
缓存穿透是指缓存和数据库中都没有的数据,但是用户一直请求不存在的数据!这时的用户很可能就是攻击者,恶意搞你们公司的,攻击会导致数据库压力过大。
解决方案:布隆过滤器
布隆过滤器的思想:既然是因为你Redis跟DB都没有,然后用户恶意一直访问不存在的key,然后全部打到Redis跟DB。那么我们能不能单独把DB的数据单独存到另外一个地方,但是这个地方只存一个简单的标记,标记这个key存不存在,如果存在,就去访问Redis跟DB,否则直接返回。并且这个内存最好很小。
单个key过期的时候有大量并发,使用互斥锁,回写redis,并且采用双重检查锁来提升性能!减少对DB的访问。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号