Redis持久化策略的深度解析
发表时间: 2022-09-26 16:41
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的内存高速缓存数据存储服务。使用 ANSI C 语言编写,支持网络、可基于内存亦可持久化的日志型、Key-Value 数据存储,并提供多种语言的 API。
Redis 是内存数据库,数据都是存储在内存中,为了避免进程退出导致数据的永久丢失,需要定期将 Redis 中的数据以某种形式(数据或命令)从内存保存到硬盘。当下次 Redis 重启时,利用持久化文件实现数据恢复。除此之外,为了进行灾难备份,可以将持久化文件拷贝到一个远程位置。Redis 的持久化机制有两种:
RDB 将当前数据保存到硬盘,AOF 则是将每次执行的写命令保存到硬盘(类似于 MySQL 的 Binlog)。AOF 持久化的实时性更好,即当进程意外退出时丢失的数据更少。
简介
RDB ( Redis Data Base) 指的是在指定的时间间隔内将内存中的数据集快照写入磁盘,RDB 是内存快照(内存数据的二进制序列化形式)的方式持久化,每次都是从 Redis 中生成一个快照进行数据的全量备份。
优点:
缺点:
RDB 文件结构
在默认情况下,Redis 将数据库快照保存在名字为 dump.rdb 的二进制文件中。RDB 文件结构由五个部分组成:
(1)长度为5字节的 REDIS 常量字符串。
(2)4字节的 db_version,标识 RDB 文件版本。
(3)databases:不定长度,包含零个或多个数据库,以及各数据库中的键值对数据。
(4)1字节的 EOF 常量,表示文件正文内容结束。
(5)check_sum: 8字节长的无符号整数,保存校验和。

数据结构举例,以下是数据库[0]和数据库[3]有数据的情况:

RDB 文件的创建
手动指令触发
手动触发 RDB 持久化的方式可以使用 save 命令和 bgsave 命令,这两个命令的区别如下:
save:执行 save 指令,阻塞 Redis 的其他操作,会导致 Redis 无法响应客户端请求,不建议使用。
bgsave:执行 bgsave 指令,Redis 后台创建子进程,异步进行快照的保存操作,此时 Redis 仍然能响应客户端的请求。
自动间隔性保存
在默认情况下,Redis 将数据库快照保存在名字为 dump.rdb的二进制文件中。可以对 Redis 进行设置,让它在“ N 秒内数据集至少有 M 个改动”这一条件被满足时,自动保存一次数据集。
比如说, 以下设置会让 Redis 在满足“ 60 秒内有至少有 10 个键被改动”这一条件时,自动保存一次数据集:save 60 10。
Redis 的默认配置如下,三个设置满足其一即可触发自动保存:
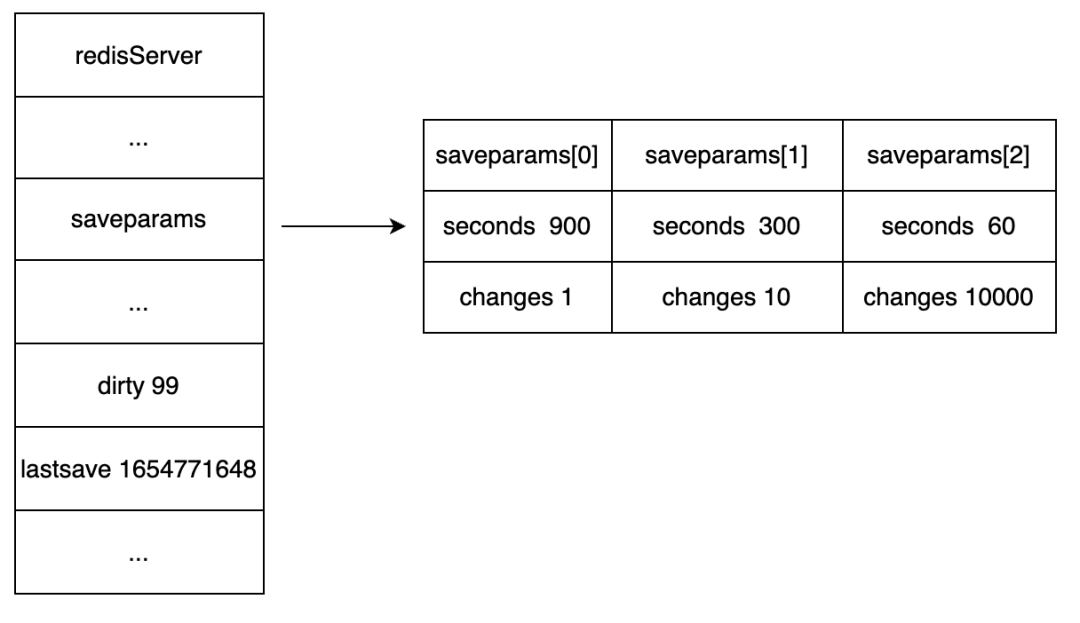
save 60 10000save 300 10save 900 1自动保存配置的数据结构
记录了服务器触发自动 BGSAVE 条件的saveparams属性。
lastsave 属性:记录服务器最后一次执行 SAVE 或者 BGSAVE 的时间。
dirty 属性:以及自最后一次保存 RDB 文件以来,服务器进行了多少次写入。
RDB 持久化方案进行备份时,Redis 会单独 fork 一个子进程来进行持久化,会将数据写入一个临时文件中,持久化完成后替换旧的 RDB 文件。在整个持久化过程中,主进程(为客户端提供服务的进程)不参与 IO 操作,这样能确保 Redis 服务的高性能,RDB 持久化机制适合对数据完整性要求不高但追求高效恢复的使用场景。下面展示 RDB 持久化流程:
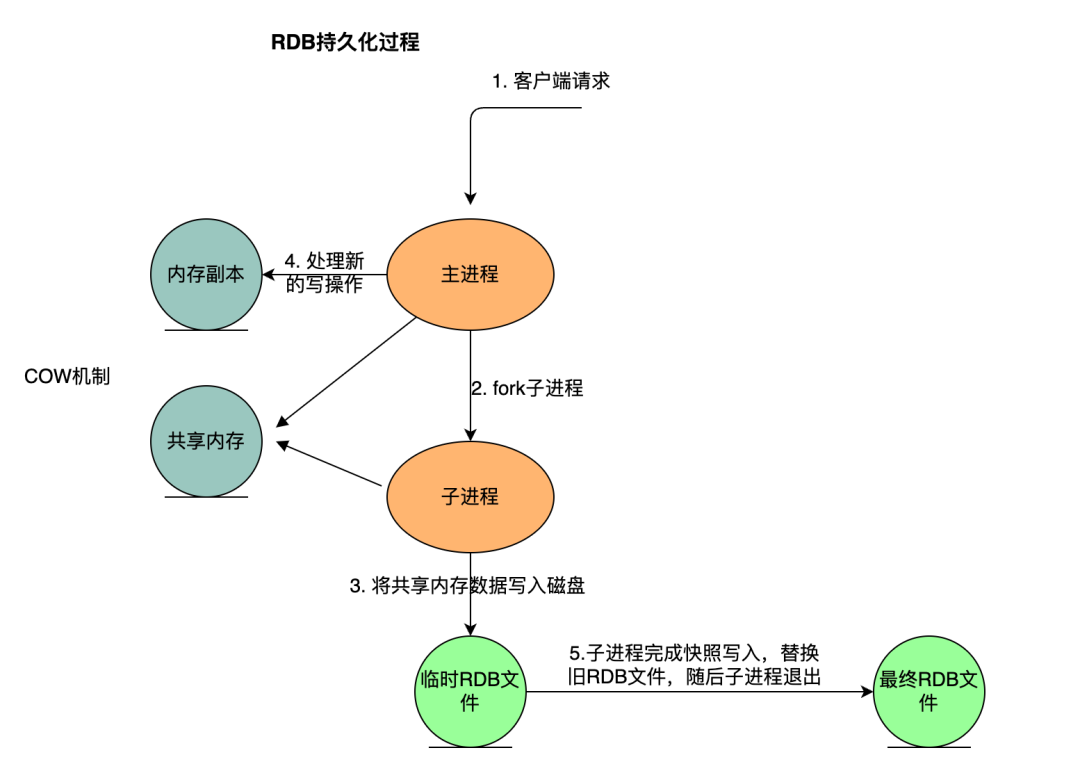
关键执行步骤如下
在生成 RDB 文件的步骤中,在同步到磁盘和持续写入这个过程是如何处理数据不一致的情况呢?生成快照 RDB 文件时是否会对业务产生影响?
Fork 子进程的作用
上面说到了 RDB 持久化过程中,主进程会 fork 一个子进程来负责 RDB 的备份,这里简单介绍一下 fork:
在 Redis 中,RDB 持久化就是充分的利用了这项技术,Redis 在持久化时调用 glibc 函数 fork 一个子进程,全权负责持久化工作,这样父进程仍然能继续给客户端提供服务。fork 的子进程初始时与父进程(Redis 的主进程)共享同一块内存;当持久化过程中,客户端的请求对内存中的数据进行修改,此时就会通过 COW (Copy On Write) 机制对数据段页面进行分离,也就是复制一块内存出来给主进程去修改。
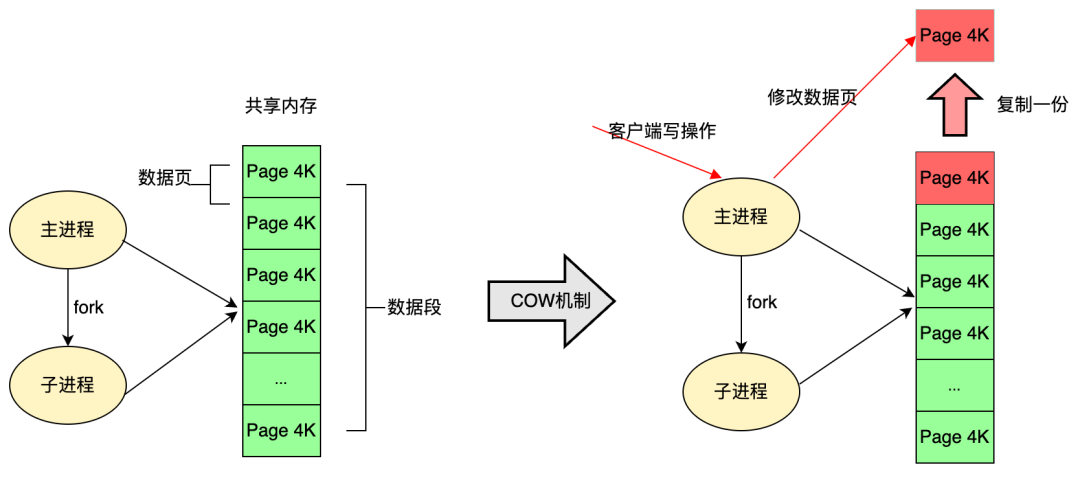
通过 fork 创建的子进程能够获得和父进程完全相同的内存空间,父进程对内存的修改对于子进程是不可见的,两者不会相互影响;
通过 fork 创建子进程时不会立刻触发大量内存的拷贝,采用的是写时拷贝 COW (Copy On Write)。内核只为新生成的子进程创建虚拟空间结构,它们来复制于父进程的虚拟究竟结构,但是不为这些段分配物理内存,它们共享父进程的物理空间,当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间;
简介
AOF (Append Only File) 是把所有对内存进行修改的指令(写操作)以独立日志文件的方式进行记录,重启时通过执行 AOF 文件中的 Redis 命令来恢复数据。类似MySql bin-log 原理。AOF 能够解决数据持久化实时性问题,是现在 Redis 持久化机制中主流的持久化方案。
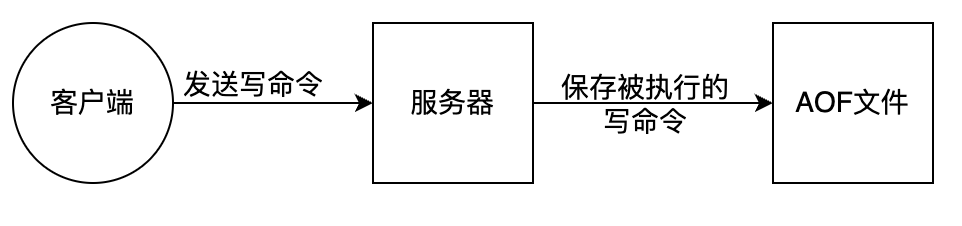
优点:
缺点:
AOF 文件内容
被写入 AOF 文件的所有命令都是以 RESP 格式保存的,是纯文本格式保存在 AOF 文件中。
Redis 客户端和服务端之间使用一种名为 RESP(REdis Serialization Protocol) 的二进制安全文本协议进行通信。
下面以一个简单的 SET 命令进行举例:
redis> SET mykey "hello" //客户端命令OK客户端封装为以下格式(每行用 \r\n分隔)
*3SETmykeyhelloAOF 文件中记录的文本内容如下
*2\r\n\r\nSELECT\r\n\r\n0\r\n //多出一个SELECT 0 命令,用于指定数据库,为系统自动添加*3\r\n\r\nSET\r\n\r\nmykey\r\n\r\nhello\r\nAOF 持久化实现
AOF 持久化方案进行备份时,客户端所有请求的写命令都会被追加到 AOF 缓冲区中,缓冲区中的数据会根据 Redis 配置文件中配置的同步策略来同步到磁盘上的 AOF 文件中,追加保存每次写的操作到文件末尾。同时当 AOF 的文件达到重写策略配置的阈值时,Redis 会对 AOF 日志文件进行重写,给 AOF 日志文件瘦身。Redis 服务重启的时候,通过加载 AOF 日志文件来恢复数据。
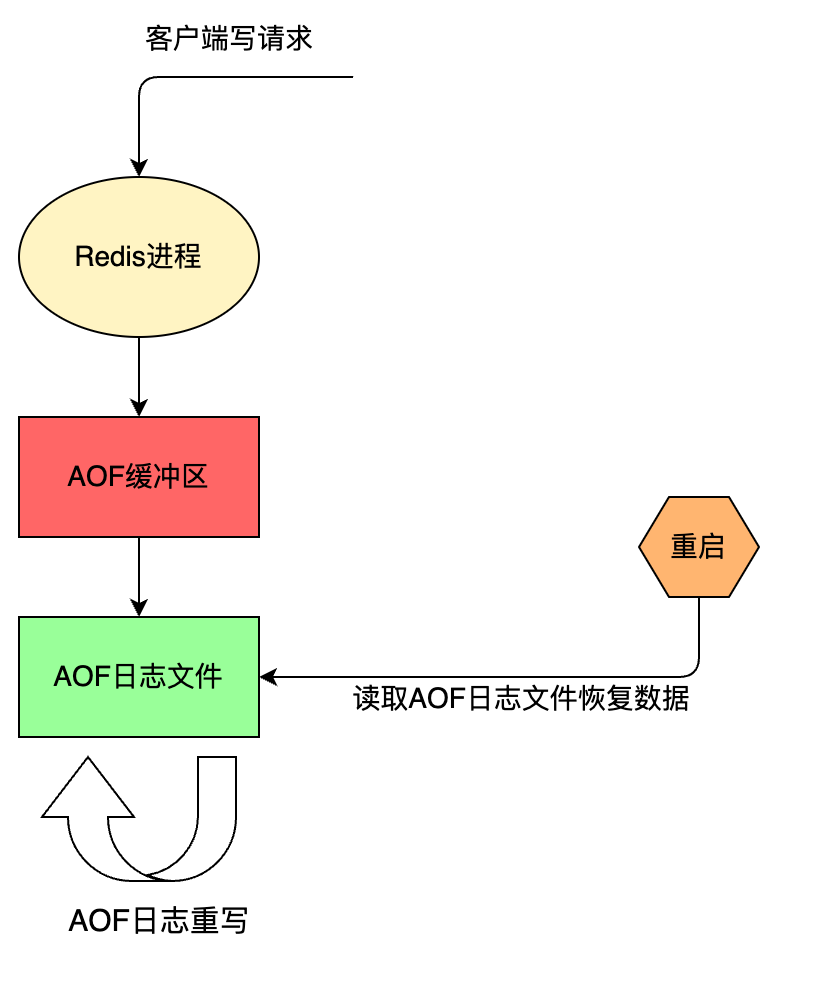
AOF 的执行流程包括:
命令追加(append)
Redis 先将写命令追加到缓冲区 aof_buf,而不是直接写入文件,主要是为了避免每次有写命令都直接写入硬盘,导致硬盘 IO 成为 Redis 负载的瓶颈。
struct redisServer { //其他域... sds aof_buf; // sds类似于Java中的String //其他域...}文件写入(write)和文件同步(sync)
根据不同的同步策略将 aof_buf 中的内容同步到硬盘;
Linux 操作系统中为了提升性能,使用了页缓存(page cache)。当我们将 aof_buf 的内容写到磁盘上时,此时数据并没有真正的落盘,而是在 page cache 中,为了将 page cache 中的数据真正落盘,需要执行 fsync / fdatasync 命令来强制刷盘。这边的文件同步做的就是刷盘操作,或者叫文件刷盘可能更容易理解一些。
AOF 缓存区的同步文件策略由参数 appendfsync 控制,有三种同步策略,各个值的含义如下:
文件重写(rewrite)
定期重写 AOF 文件,达到压缩的目的。
AOF 重写是 AOF 持久化的一个机制,用来压缩 AOF 文件,通过 fork 一个子进程,重新写一个新的 AOF 文件,该次重写不是读取旧的 AOF 文件进行复制,而是读取内存中的Redis数据库,重写一份 AOF 文件,有点类似于 RDB 的快照方式。
文件重写之所以能够压缩 AOF 文件,原因在于:
AOF重写
前面提到 AOF 的缺点时,说过 AOF 属于日志追加的形式来存储 Redis 的写指令,这会导致大量冗余的指令存储,从而使得 AOF 日志文件非常庞大,比如同一个 key 被写了 10000 次,最后却被删除了,这种情况不仅占内存,也会导致恢复的时候非常缓慢,因此 Redis 提供重写机制来解决这个问题。Redis 的 AOF 持久化机制执行重写后,保存的只是恢复数据的最小指令集,我们如果想手动触发可以使用如下指令:
bgrewriteaof文件重写时机
相关参数:
同时满足下面两个条件,则触发 AOF 重写机制:
AOF 重写流程如下:
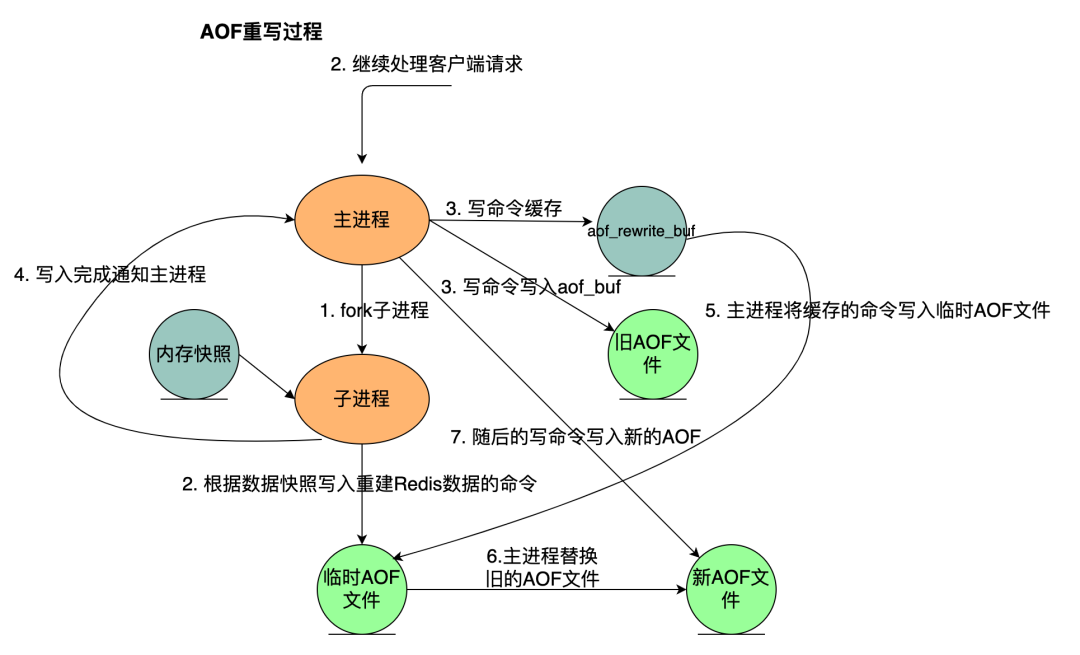
在实际中,为了避免在执行命令时造成客户端输入缓冲区溢出,重写程序会检查集合元素数量是否超过
REDIS_AOF_REWRITE_ITEMS_PER_CMD 常量的值,如果超过了,则会使用多个命令来记录,而不单单使用一条命令。
Redis 2.9版本中该常量为64,如果一个命令的集合键包含超过了64个元素,重写程序会拆成多个命令。
SADD <key> <elem1> <elem2>...<elem64>
SADD <key> <elem65> <elem66>...<elem128>
AOF重写是一个有歧义的名字,该功能是通过直接读取数据库的键值对实现的,程序无需对现有AOF文件进行任何读入、分析或者写入操作。
AOF 与 WAL
Redis 为什么考虑使用 AOF 而不是 WAL 呢?
很多数据库都是采用的 Write Ahead Log(WAL)写前日志,其特点就是先把修改的数据记录到日志中,再进行写数据的提交,可以方便通过日志进行数据恢复。
但是 Redis 采用的却是 AOF(Append Only File)写后日志,特点就是先执行写命令,把数据写入内存中,再记录日志。
如果先让系统执行命令,只有命令能执行成功,才会被记录到日志中。因此,Redis 使用写后日志这种形式,可以避免出现记录错误命令的情况。
另外还有一个原因就是:AOF 是在命令执行后才记录日志,所以不会阻塞当前的写操作。
AOF 和 RDB 之间的相互作用
在版本号大于等于2.4的 Redis 中,BGSAVE 执行的过程中,不可以执行 BGREWRITEAOF。反过来说,在 BGREWRITEAOF 执行的过程中,也不可以执行 BGSAVE。这可以防止两个 Redis 后台进程同时对磁盘进行大量的 I/O 操作。
如果 BGSAVE 正在执行,并且用户显示地调用 BGREWRITEAOF 命令,那么服务器将向用户回复一个 OK 状态,并告知用户,BGREWRITEAOF 已经被预定执行:一旦 BGSAVE 执行完毕 BGREWRITEAOF 就会正式开始。
当 Redis 启动时,如果 RDB 持久化和 AOF 持久化都被打开了,那么程序会优先使用 AOF 文件来恢复数据集,因为 AOF 文件所保存的数据通常是最完整的。
Redis4.0 后大部分的使用场景都不会单独使用 RDB 或者 AOF 来做持久化机制,而是兼顾二者的优势混合使用。其原因是 RDB 虽然快,但是会丢失比较多的数据,不能保证数据完整性;AOF 虽然能尽可能保证数据完整性,但是性能确实是一个诟病,比如重放恢复数据。
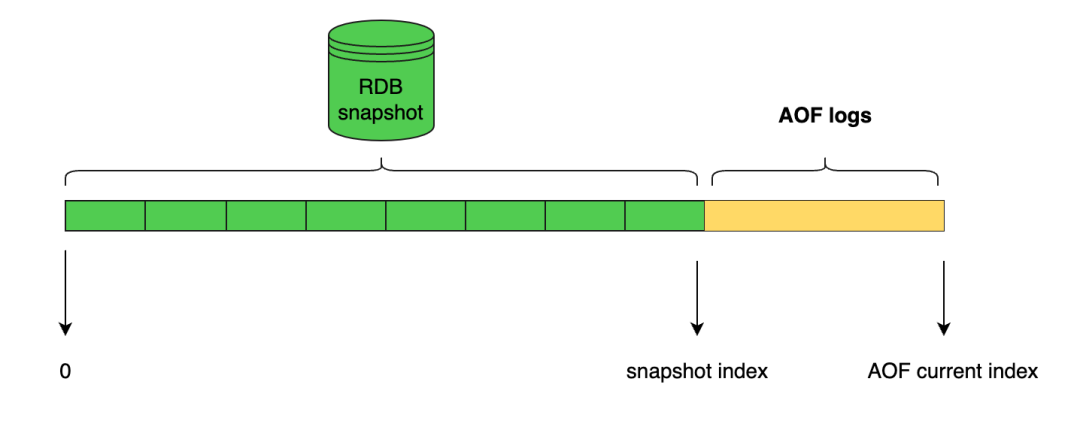
Redis从4.0版本开始引入 RDB-AOF 混合持久化模式,这种模式是基于 AOF 持久化模式构建而来的,混合持久化通过 aof-use-rdb-preamble yes 开启。
那么 Redis 服务器在执行 AOF 重写操作时,就会像执行 BGSAVE 命令那样,根据数据库当前的状态生成出相应的 RDB 数据,并将这些数据写入新建的 AOF 文件中,至于那些在 AOF 重写开始之后执行的 Redis 命令,则会继续以协议文本的方式追加到新 AOF 文件的末尾,即已有的 RDB 数据的后面。
换句话说,在开启了 RDB-AOF 混合持久化功能之后,服务器生成的 AOF 文件将由两个部分组成,其中位于 AOF 文件开头的是 RDB 格式的数据,而跟在 RDB 数据后面的则是 AOF 格式的数据。
当一个支持 RDB-AOF 混合持久化模式的 Redis 服务器启动并载入 AOF 文件时,它会检查 AOF 文件的开头是否包含了 RDB 格式的内容。
其日志文件结构如下:
最后来总结这两者,到底用哪个更好呢?
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号