AIGC在视频创作领域的潜力有多大?
发表时间: 2023-11-29 09:59
AI技术正在视频内容生成领域发挥着越来越大的作用,那么当下,各家产品们的AI视频生成能力表现得如何?AIGC在视频生成领域的发展,未来又有着怎样的想象空间?一起来看本文的分享。

“AIGC在视频内容生成的赛道上才刚刚起步。”
上周二Stable Video Diffusion(SVD)模型的发布在行业内引起热议,SVD模型主要提供图片生成视频能力。在短视频的时代,谁能不对智能视频内容生成能力感到兴奋呢?那AI视频生成能力现在如何能为我们所用,未来会有多大的想象空间呢?

从产品类型区分,AIGC视频生成产品可以分为:
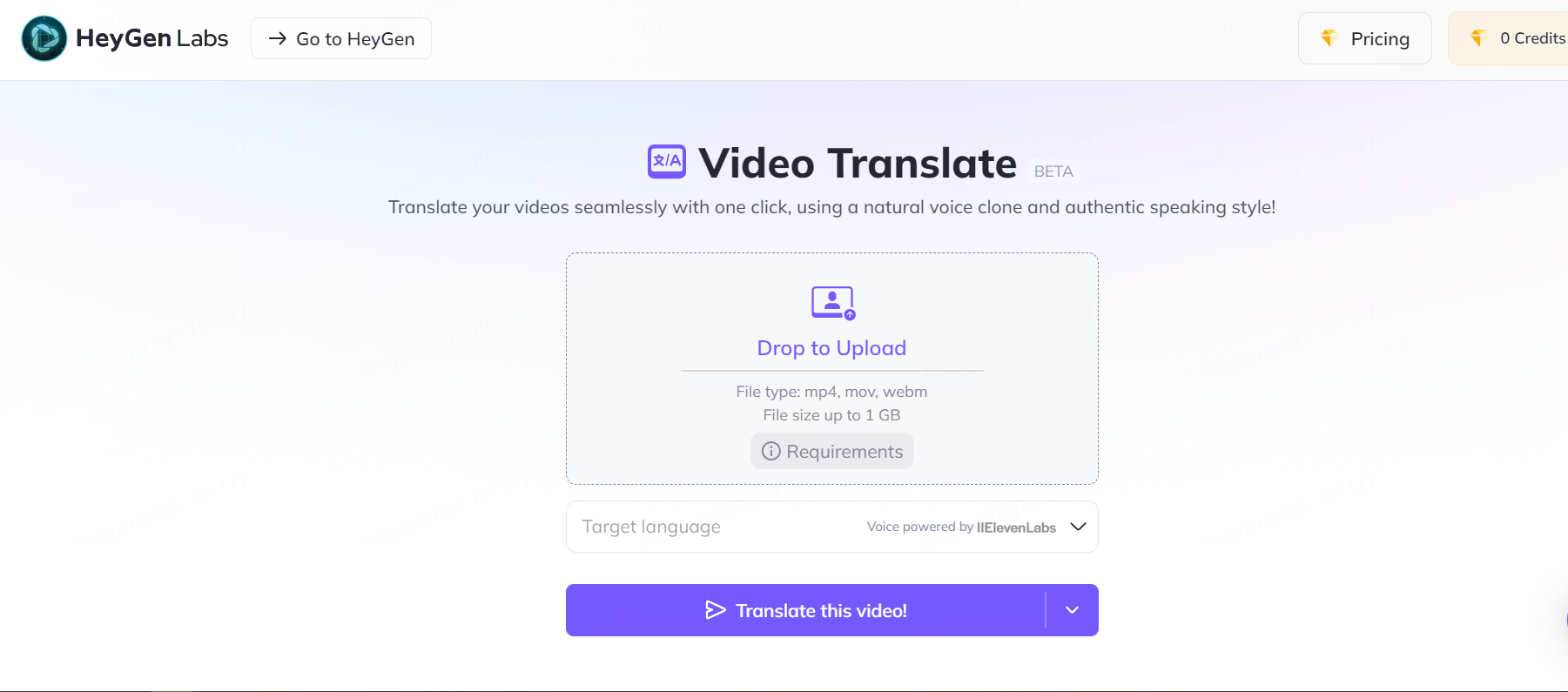
通过个人形象+动作+声音合成视频,视频内的相关元素均可通过视频录制上传后制作成为模板。适用于视频内容相对固定,视频形式以真人+讲解的场景,例如广告宣传、知识讲解等。
以下是通过HeyGen生成的视频片段,两个形象均为数字虚拟人,从产品效果看,数字人的形象、动作、音色的还原度均非常高。

前阵子非常火热的外语对嘴型视频也可以通过HeyGen进行制作,只要上传视频并选择需要翻译的语言,就可以将原视频音频的语言翻译为指定的另一门语言,并将视频中人物发音的嘴型对应上。
通过图片+文字描述生成视频。由于文字控制的自由度过高,随着视频时间的增加,视频内容的质量目前很难保证(且随着AI模型对视频内容记忆的增加,视频生成将消耗大量的硬件资源),目前适用于制作5秒以内的短视频(动态图),作为静态图片的延展。

但人类对于AI的幻想从来都不会局限在仅仅几秒的时间内。Runway在8月推出了Watch功能,展示了分钟级别的作品,目前已有60多个作品。虽然中长视频制作的功能暂未开放,但已有的作品为我们展示了AI在未来的可想象性。
以下视频是Runway的Watch功能里片段,除了人物镜头拉远后身体细节会出现一些扭曲外,视频整体的质量已经相当不错。

通过文字描述在已有的素材库中选择合适的视频及图片素材进行匹配,文字描述将作为字幕展示,再选择音色对字幕进行配音。这种应用方式从视频的角度是生成,而从素材的角度更多是进行合成。由于素材是从已有素材库提取,故视频质量相对可控。适用于素材较多的视频制作场景。
以下是通过剪映文字成片功能制作的视频片段,视频内容整体的流畅度与文字描述关联较大,但有部分素材与文字描述不符,受限于素材库的素材量。

从目前的产品形态以及生成质量上看,AIGC在视频生成领域的发展,还远未达到批量消费级内容生产的阶段。受限于机器资源、内容丰富度、使用场景等因素,视频生成能力还需要经过很长时间的打磨。
在未来,集成了三类视频生成能力的工具可能会推动AI生成视频走向消费级别。我们可以先定义好人物形象、声音、动作,再从素材库检索并添加已有的素材,最后根据文字描述决定故事情节的走向。或许有一天,所有人都可以成为一名AI电影导演。
本文由 @只A不I 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号