利用Python,你也能成为AI绘画大师!(附代码)
发表时间: 2020-09-22 16:51

作者 | 李秋键
责编 | 李雪敬
头图 | CSDN下载自视觉中国
引言:基于前段时间我在CSDN上创作的文章“CylcleGAN人脸转卡通图”的不足,今天给大家分享一个更加完美的绘制卡通的项目“Learning to Cartoonize Using White-box Cartoon Representations”。
首先阐述下这个项目相对之前分享的卡通化的优势:
1、普遍适用性,相对于原来人脸转卡通而言,这个项目可以针对任意的图片进行卡通化转换,不再局限于必须是人脸图片或一定尺寸;
2、卡通化效果更好。
具体效果如下图可见:

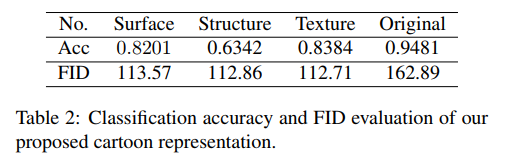
其主要原理仍然是基于GAN网络,但主要三个白盒分别对图像的结构、表面和纹理进行处理,最后得到了优于其他方法的图像转化方法 CartoonGAN。
而今天我们就将借助论文所分享的源代码,构建模型创建自己需要的人物运动。具体流程如下。

实验前的准备
首先我们使用的python版本是3.6.5所用到的模块如下:
argparse 模块用来定义命令行输入参数指令。
Utils 是将其中常用功能封装成为接口。
numpy 模块用来处理矩阵运算。
Tensorflow 模块创建模型网络,训练测试等。
tqdm 是显示循环的进度条的库。

因为不同的卡通风格需要特定任务的假设或先验知识来开发对应的算法去分别处理。例如,一些卡通工作更关注全局色调,线条轮廓是次要问题。或是稀疏干净的颜色块在艺术表达中占据主导地位。但是针对不同的需求,常见模型无法有效的实现卡通化效果。
故在文章中主要通过分别处理表面、结构和纹理表示来解决这个问题:
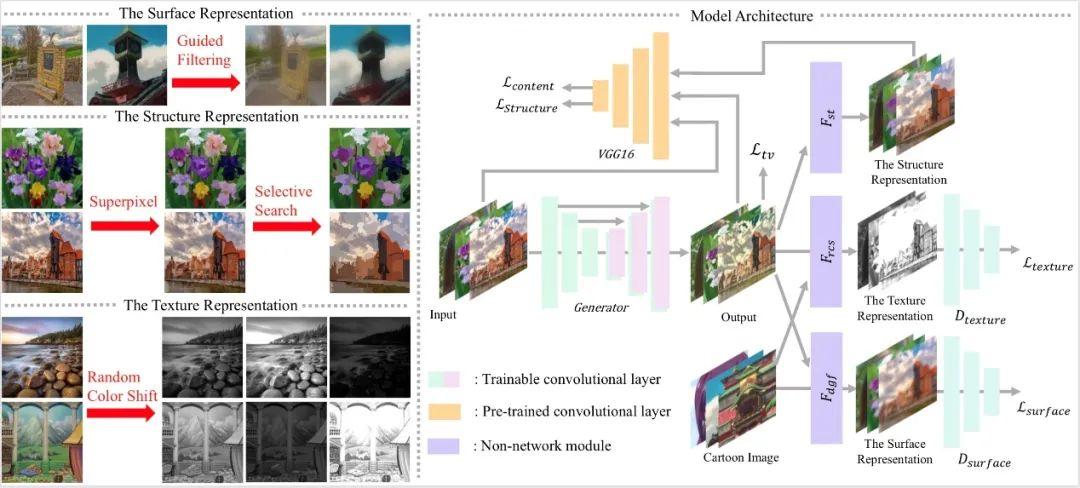
(1)首先是网络层的定义:
1.1 定义resblock保证在res block的输入前后通道数发生变化时,可以保证shortcut和普通的output的channel一致,这样就能直接相加了。
def resblock(inputs, out_channel=32, name='resblock'):
with tf.variable_scope(name):
x = slim.convolution2d(inputs, out_channel, [3, 3],
activation_fn=None, scope='conv1')
x = tf.nn.leaky_relu(x)
x = slim.convolution2d(x, out_channel, [3, 3],
activation_fn=None, scope='conv2')
return x + inputs
1.2 定义生成器函数:
def generator(inputs, channel=32, num_blocks=4, name='generator', reuse=False):
with tf.variable_scope(name, reuse=reuse):
x = slim.convolution2d(inputs, channel, [7, 7], activation_fn=None)
x = tf.nn.leaky_relu(x)
x = slim.convolution2d(x, channel*2, [3, 3], stride=2, activation_fn=None)
x = slim.convolution2d(x, channel*2, [3, 3], activation_fn=None)
x = tf.nn.leaky_relu(x)
x = slim.convolution2d(x, channel*4, [3, 3], stride=2, activation_fn=None)
x = slim.convolution2d(x, channel*4, [3, 3], activation_fn=None)
x = tf.nn.leaky_relu(x)
for idx in range(num_blocks):
x = resblock(x, out_channel=channel*4, name='block_{}'.format(idx))
x = slim.conv2d_transpose(x, channel*2, [3, 3], stride=2, activation_fn=None)
x = slim.convolution2d(x, channel*2, [3, 3], activation_fn=None)
x = tf.nn.leaky_relu(x)
x = slim.conv2d_transpose(x, channel, [3, 3], stride=2, activation_fn=None)
x = slim.convolution2d(x, channel, [3, 3], activation_fn=None)
x = tf.nn.leaky_relu(x)
x = slim.convolution2d(x, 3, [7, 7], activation_fn=None)
#x = tf.clip_by_value(x, -0.999999, 0.999999)
return x
def unet_generator(inputs, channel=32, num_blocks=4, name='generator', reuse=False):
with tf.variable_scope(name, reuse=reuse):
x0 = slim.convolution2d(inputs, channel, [7, 7], activation_fn=None)
x0 = tf.nn.leaky_relu(x0)
x1 = slim.convolution2d(x0, channel, [3, 3], stride=2, activation_fn=None)
x1 = tf.nn.leaky_relu(x1)
x1 = slim.convolution2d(x1, channel*2, [3, 3], activation_fn=None)
x1 = tf.nn.leaky_relu(x1)
x2 = slim.convolution2d(x1, channel*2, [3, 3], stride=2, activation_fn=None)
x2 = tf.nn.leaky_relu(x2)
x2 = slim.convolution2d(x2, channel*4, [3, 3], activation_fn=None)
x2 = tf.nn.leaky_relu(x2)
for idx in range(num_blocks):
x2 = resblock(x2, out_channel=channel*4, name='block_{}'.format(idx))
x2 = slim.convolution2d(x2, channel*2, [3, 3], activation_fn=None)
x2 = tf.nn.leaky_relu(x2)
h1, w1 = tf.shape(x2)[1], tf.shape(x2)[2]
x3 = tf.image.resize_bilinear(x2, (h1*2, w1*2))
x3 = slim.convolution2d(x3+x1, channel*2, [3, 3], activation_fn=None)
x3 = tf.nn.leaky_relu(x3)
x3 = slim.convolution2d(x3, channel, [3, 3], activation_fn=None)
x3 = tf.nn.leaky_relu(x3)
h2, w2 = tf.shape(x3)[1], tf.shape(x3)[2]
x4 = tf.image.resize_bilinear(x3, (h2*2, w2*2))
x4 = slim.convolution2d(x4+x0, channel, [3, 3], activation_fn=None)
x4 = tf.nn.leaky_relu(x4)
x4 = slim.convolution2d(x4, 3, [7, 7], activation_fn=None)
#x4 = tf.clip_by_value(x4, -1, 1)
return x4
1.3 表面结构等定义:
def disc_bn(x, scale=1, channel=32, is_training=True,
name='discriminator', patch=True, reuse=False):
with tf.variable_scope(name, reuse=reuse):
for idx in range(3):
x = slim.convolution2d(x, channel*2**idx, [3, 3], stride=2, activation_fn=None)
x = slim.batch_norm(x, is_training=is_training, center=True, scale=True)
x = tf.nn.leaky_relu(x)
x = slim.convolution2d(x, channel*2**idx, [3, 3], activation_fn=None)
x = slim.batch_norm(x, is_training=is_training, center=True, scale=True)
x = tf.nn.leaky_relu(x)
if patch == True:
x = slim.convolution2d(x, 1, [1, 1], activation_fn=None)
else:
x = tf.reduce_mean(x, axis=[1, 2])
x = slim.fully_connected(x, 1, activation_fn=None)
return x
def disc_sn(x, scale=1, channel=32, patch=True, name='discriminator', reuse=False):
with tf.variable_scope(name, reuse=reuse):
for idx in range(3):
x = layers.conv_spectral_norm(x, channel*2**idx, [3, 3],
stride=2, name='conv{}_1'.format(idx))
x = tf.nn.leaky_relu(x)
x = layers.conv_spectral_norm(x, channel*2**idx, [3, 3],
name='conv{}_2'.format(idx))
x = tf.nn.leaky_relu(x)
if patch == True:
x = layers.conv_spectral_norm(x, 1, [1, 1], name='conv_out'.format(idx))
else:
x = tf.reduce_mean(x, axis=[1, 2])
x = slim.fully_connected(x, 1, activation_fn=None)
return x
def disc_ln(x, channel=32, is_training=True, name='discriminator', patch=True, reuse=False):
with tf.variable_scope(name, reuse=reuse):
for idx in range(3):
x = slim.convolution2d(x, channel*2**idx, [3, 3], stride=2, activation_fn=None)
x = tf.contrib.layers.layer_norm(x)
x = tf.nn.leaky_relu(x)
x = slim.convolution2d(x, channel*2**idx, [3, 3], activation_fn=None)
x = tf.contrib.layers.layer_norm(x)
x = tf.nn.leaky_relu(x)
if patch == True:
x = slim.convolution2d(x, 1, [1, 1], activation_fn=None)
else:
x = tf.reduce_mean(x, axis=[1, 2])
x = slim.fully_connected(x, 1, activation_fn=None)
return x
(2)模型的训练:
使用clip_by_value应用自适应着色在最后一层的网络中,因为它不是很稳定。为了稳定再现我们的结果,请使用power=1.0然后首先在network.py中注释clip_by_value函数。
def train(args):
input_photo = tf.placeholder(tf.float32, [args.batch_size,
args.patch_size, args.patch_size, 3])
input_superpixel = tf.placeholder(tf.float32, [args.batch_size,
args.patch_size, args.patch_size, 3])
input_cartoon = tf.placeholder(tf.float32, [args.batch_size,
args.patch_size, args.patch_size, 3])
output = network.unet_generator(input_photo)
output = guided_filter(input_photo, output, r=1)
blur_fake = guided_filter(output, output, r=5, eps=2e-1)
blur_cartoon = guided_filter(input_cartoon, input_cartoon, r=5, eps=2e-1)
gray_fake, gray_cartoon = utils.color_shift(output, input_cartoon)
d_loss_gray, g_loss_gray = loss.lsgan_loss(network.disc_sn, gray_cartoon, gray_fake,
scale=1, patch=True, name='disc_gray')
d_loss_blur, g_loss_blur = loss.lsgan_loss(network.disc_sn, blur_cartoon, blur_fake,
scale=1, patch=True, name='disc_blur')
vgg_model = loss.Vgg19('vgg19_no_fc.npy')
vgg_photo = vgg_model.build_conv4_4(input_photo)
vgg_output = vgg_model.build_conv4_4(output)
vgg_superpixel = vgg_model.build_conv4_4(input_superpixel)
h, w, c = vgg_photo.get_shape.as_list[1:]
photo_loss = tf.reduce_mean(tf.losses.absolute_difference(vgg_photo, vgg_output))/(h*w*c)
superpixel_loss = tf.reduce_mean(tf.losses.absolute_difference\
(vgg_superpixel, vgg_output))/(h*w*c)
recon_loss = photo_loss + superpixel_loss
tv_loss = loss.total_variation_loss(output)
g_loss_total = 1e4*tv_loss + 1e-1*g_loss_blur + g_loss_gray + 2e2*recon_loss
d_loss_total = d_loss_blur + d_loss_gray
all_vars = tf.trainable_variables
gene_vars = [var for var in all_vars if 'gene' in var.name]
disc_vars = [var for var in all_vars if 'disc' in var.name]
tf.summary.scalar('tv_loss', tv_loss)
tf.summary.scalar('photo_loss', photo_loss)
tf.summary.scalar('superpixel_loss', superpixel_loss)
tf.summary.scalar('recon_loss', recon_loss)
tf.summary.scalar('d_loss_gray', d_loss_gray)
tf.summary.scalar('g_loss_gray', g_loss_gray)
tf.summary.scalar('d_loss_blur', d_loss_blur)
tf.summary.scalar('g_loss_blur', g_loss_blur)
tf.summary.scalar('d_loss_total', d_loss_total)
tf.summary.scalar('g_loss_total', g_loss_total)
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
g_optim = tf.train.AdamOptimizer(args.adv_train_lr, beta1=0.5, beta2=0.99)\
.minimize(g_loss_total, var_list=gene_vars)
d_optim = tf.train.AdamOptimizer(args.adv_train_lr, beta1=0.5, beta2=0.99)\
.minimize(d_loss_total, var_list=disc_vars)
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=args.gpu_fraction)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
train_writer = tf.summary.FileWriter(args.save_dir+'/train_log')
summary_op = tf.summary.merge_all
saver = tf.train.Saver(var_list=gene_vars, max_to_keep=20)
with tf.device('/device:GPU:0'):
sess.run(tf.global_variables_initializer)
saver.restore(sess, tf.train.latest_checkpoint('pretrain/saved_models'))
face_photo_dir = 'dataset/photo_face'
face_photo_list = utils.load_image_list(face_photo_dir)
scenery_photo_dir = 'dataset/photo_scenery'
scenery_photo_list = utils.load_image_list(scenery_photo_dir)
face_cartoon_dir = 'dataset/cartoon_face'
face_cartoon_list = utils.load_image_list(face_cartoon_dir)
scenery_cartoon_dir = 'dataset/cartoon_scenery'
scenery_cartoon_list = utils.load_image_list(scenery_cartoon_dir)
for total_iter in tqdm(range(args.total_iter)):
if np.mod(total_iter, 5) == 0:
photo_batch = utils.next_batch(face_photo_list, args.batch_size)
cartoon_batch = utils.next_batch(face_cartoon_list, args.batch_size)
else:
photo_batch = utils.next_batch(scenery_photo_list, args.batch_size)
cartoon_batch = utils.next_batch(scenery_cartoon_list, args.batch_size)
inter_out = sess.run(output, feed_dict={input_photo: photo_batch,
input_superpixel: photo_batch,
input_cartoon: cartoon_batch})
if args.use_enhance:
superpixel_batch = utils.selective_adacolor(inter_out, power=1.2)
else:
superpixel_batch = utils.simple_superpixel(inter_out, seg_num=200)
_, g_loss, r_loss = sess.run([g_optim, g_loss_total, recon_loss],
feed_dict={input_photo: photo_batch,
input_superpixel: superpixel_batch,
input_cartoon: cartoon_batch})
_, d_loss, train_info = sess.run([d_optim, d_loss_total, summary_op],
feed_dict={input_photo: photo_batch,
input_superpixel: superpixel_batch,
input_cartoon: cartoon_batch})
train_writer.add_summary(train_info, total_iter)
if np.mod(total_iter+1, 50) == 0:
print('Iter: {}, d_loss: {}, g_loss: {}, recon_loss: {}'.\
format(total_iter, d_loss, g_loss, r_loss))
if np.mod(total_iter+1, 500 ) == 0:
saver.save(sess, args.save_dir+'/saved_models/model',
write_meta_graph=False, global_step=total_iter)
photo_face = utils.next_batch(face_photo_list, args.batch_size)
cartoon_face = utils.next_batch(face_cartoon_list, args.batch_size)
photo_scenery = utils.next_batch(scenery_photo_list, args.batch_size)
cartoon_scenery = utils.next_batch(scenery_cartoon_list, args.batch_size)
result_face = sess.run(output, feed_dict={input_photo: photo_face,
input_superpixel: photo_face,
input_cartoon: cartoon_face})
result_scenery = sess.run(output, feed_dict={input_photo: photo_scenery,
input_superpixel: photo_scenery,
input_cartoon: cartoon_scenery})
utils.write_batch_image(result_face, args.save_dir+'/images',
str(total_iter)+'_face_result.jpg', 4)
utils.write_batch_image(photo_face, args.save_dir+'/images',
str(total_iter)+'_face_photo.jpg', 4)
utils.write_batch_image(result_scenery, args.save_dir+'/images',
str(total_iter)+'_scenery_result.jpg', 4)
utils.write_batch_image(photo_scenery, args.save_dir+'/images',
str(total_iter)+'_scenery_photo.jpg', 4)


(1)加载图片的尺寸自动处理和导向滤波定义:
def resize_crop(image):
h, w, c = np.shape(image)
if min(h, w) > 720:
if h > w:
h, w = int(720*h/w), 720
else:
h, w = 720, int(720*w/h)
image = cv2.resize(image, (w, h),
interpolation=cv2.INTER_AREA)
h, w = (h//8)*8, (w//8)*8
image = image[:h, :w, :]
return image
def tf_box_filter(x, r):
k_size = int(2*r+1)
ch = x.get_shape.as_list[-1]
weight = 1/(k_size**2)
box_kernel = weight*np.ones((k_size, k_size, ch, 1))
box_kernel = np.array(box_kernel).astype(np.float32)
output = tf.nn.depthwise_conv2d(x, box_kernel, [1, 1, 1, 1], 'SAME')
return output
def guided_filter(x, y, r, eps=1e-2):
x_shape = tf.shape(x)
#y_shape = tf.shape(y)
N = tf_box_filter(tf.ones((1, x_shape[1], x_shape[2], 1), dtype=x.dtype), r)
mean_x = tf_box_filter(x, r) / N
mean_y = tf_box_filter(y, r) / N
cov_xy = tf_box_filter(x * y, r) / N - mean_x * mean_y
var_x = tf_box_filter(x * x, r) / N - mean_x * mean_x
A = cov_xy / (var_x + eps)
b = mean_y - A * mean_x
mean_A = tf_box_filter(A, r) / N
mean_b = tf_box_filter(b, r) / N
output = mean_A * x + mean_b
return output
def fast_guided_filter(lr_x, lr_y, hr_x, r=1, eps=1e-8):
#assert lr_x.shape.ndims == 4 and lr_y.shape.ndims == 4 and hr_x.shape.ndims == 4
lr_x_shape = tf.shape(lr_x)
#lr_y_shape = tf.shape(lr_y)
hr_x_shape = tf.shape(hr_x)
N = tf_box_filter(tf.ones((1, lr_x_shape[1], lr_x_shape[2], 1), dtype=lr_x.dtype), r)
mean_x = tf_box_filter(lr_x, r) / N
mean_y = tf_box_filter(lr_y, r) / N
cov_xy = tf_box_filter(lr_x * lr_y, r) / N - mean_x * mean_y
var_x = tf_box_filter(lr_x * lr_x, r) / N - mean_x * mean_x
A = cov_xy / (var_x + eps)
b = mean_y - A * mean_x
mean_A = tf.image.resize_images(A, hr_x_shape[1: 3])
mean_b = tf.image.resize_images(b, hr_x_shape[1: 3])
output = mean_A * hr_x + mean_b
return output
(2)卡通化函数定义:
def cartoonize(load_folder, save_folder, model_path):
input_photo = tf.placeholder(tf.float32, [1, None, None, 3])
network_out = network.unet_generator(input_photo)
final_out = guided_filter.guided_filter(input_photo, network_out, r=1, eps=5e-3)
all_vars = tf.trainable_variables
gene_vars = [var for var in all_vars if 'generator' in var.name]
saver = tf.train.Saver(var_list=gene_vars)
config = tf.ConfigProto
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
sess.run(tf.global_variables_initializer)
saver.restore(sess, tf.train.latest_checkpoint(model_path))
name_list = os.listdir(load_folder)
for name in tqdm(name_list):
try:
load_path = os.path.join(load_folder, name)
save_path = os.path.join(save_folder, name)
image = cv2.imread(load_path)
image = resize_crop(image)
batch_image = image.astype(np.float32)/127.5 - 1
batch_image = np.expand_dims(batch_image, axis=0)
output = sess.run(final_out, feed_dict={input_photo: batch_image})
output = (np.squeeze(output)+1)*127.5
output = np.clip(output, 0, 255).astype(np.uint8)
cv2.imwrite(save_path, output)
except:
print('cartoonize {} failed'.format(load_path))
(3)模型调用
model_path = 'saved_models'
load_folder = 'test_images'
save_folder = 'cartoonized_images'
if not os.path.exists(save_folder):
os.mkdir(save_folder)
cartoonize(load_folder, save_folder, model_path)
(4)训练代码的使用:
test_code文件夹中运行python cartoonize.py。生成图片在cartoonized_images文件夹里,效果如下:



将输入图像通过导向滤波器处理,得到表面表示的结果,然后通过超像素处理,得到结构表示的结果,通过随机色彩变幻得到纹理表示的结果,卡通图像也就是做这样的处理。随后将GAN生成器产生的fake_image分别于上述表示结果做损失。其中纹理表示与表面表示通过判别器得到损失,fake_image的结构表示与fake_image,输入图像与fake_image分别通过vgg19网络抽取特征,进行损失的计算。
完整代码链接:
https://pan.baidu.com/s/10YklnSRIw_mc6W4ovlP3uw
提取码:pluq
作者简介:
李秋键,CSDN博客专家,CSDN达人课作者。硕士在读于中国矿业大学,开发有taptap竞赛获奖等。


点分享
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12


 鲁公网安备37020202000738号
鲁公网安备37020202000738号