微软Excel与Python集成深度解析:新手指南及限制探讨
发表时间: 2024-07-09 17:43
在 Python 之父 Guido van Rossum 的支持下,2023 年 8 月,微软宣布推出集成到 Excel 中的 Python 公开预览版(Python in Excel),这将允许数据分析师、工程师、营销人员亦或是学习数据科学的学生都可以直接使用 Python 代码、库在 Excel 中执行复杂的统计分析、高级可视化、预测分析和机器学习等等。
如今时隔一年,这项功能仍处于预览阶段,但是对于开发者的实用性究竟如何,来自《Python for Excel》一书的作者、Xlwings 工具创建者 Felix Zumstein 在尝试后进行了解析。
原文链接:https://www.xlwings.org/blog/my-thoughts-on-python-in-excel
本文为 CSDN 翻译。
作者 | Felix Zumstein
译者 | 弯月 责编 | 苏宓
2023 年 8 月 22 日,微软发布了“Python in Excel”的预览版。作为《Python for Excel》一书的作者,我非常好奇,想要试一试。由于不能仅凭图书的封面来判断这项功能的优劣,所以我决定深入研究一番。
那么,我对Excel中的Python编程有什么看法?简单来说:
我们想要的是 VBA 的替代品,但实际上得到的是 Excel 公式语言的替代品。
将 Jupyter notebook 单元格集成到 Excel 网格中是一个错误。
Excel中的Python编程不适合Python初学者,也不适合交互式数据分析。
目前有太多限制(不能使用自己的包,不能连接到网络 API)。
目前,我看到的Excel中Python编程的用例如下:
计算密集型任务,比如蒙特卡洛模拟等。
通过已有软件包完成AI相关的任务(scikit-learn、nltk、statsmodels、imbalanced-learn、gensim)。
通过 Matplotlib/Seaborn 进行高级可视化。
时间序列分析(这是 Excel 的盲点之一)。
数据整理、数据分析的处理能力不确定:几乎可以肯定需要 Power Query,可能更简单且更快的方式是只使用 Power Query(而不是同时使用 Power Query 和 Excel中的Python)。
在深入探讨细节之前,我想澄清一下,文本阐述的只是我的个人意见,并不是为了发牢骚或批评。在这个过程中,我与 Excel 团队联系过几次,他们都非常友好,我很感谢他们重视我的意见。他们必须与拥有近 40 年历史且拥有大量企业用户的Excel打交道,考虑到这些限制,我认为他们在工作中的表现非常出色。
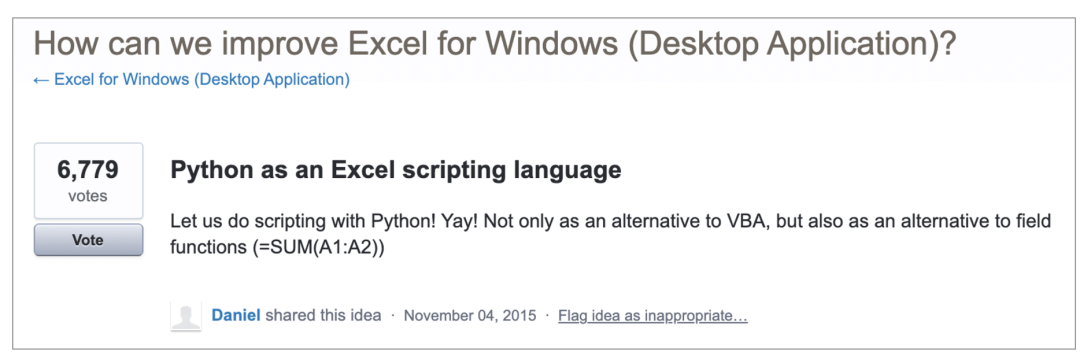
Excel中的Python的故事始于 2015 年,用户 “Daniel” 在微软的 UserVoice 页面上发布了以下想法(此页面现已迁移到他们的新反馈论坛):
这个想法很快就成为了最受欢迎的建议,大家想表达的需求也很明确:
一种脚本语言
用户自定义函数
不幸的是,Excel中的Python编程并不支持这两项功能。它并不是 VBA 的替代品,而是被设计成了 Excel 公式语言的替代品。我并不认为 Excel 的公式语言有什么问题,而Excel中的Python实际上只是 Excel 网格中的二维 Jupyter notebook。
顺便提一下,它使用的是运行在 Azure 云上的一个 Jupyter notebook内核。这意味着,你可以使用notebook的一些魔法,比如%%timeit,这倒是很酷。
该项目的首席架构师 John Lam 在播客中表示,最初大家都认为这种实现是一个“疯狂的想法”,但最终被微软的决策者采纳了。在我看来,这个想法本来就很“癫”。
Excel中的Python编程本可以集成Jupyter notebook,并将其作为Excel中的任务窗格。这样,Python 开发人员会感到很熟悉,他们可以直接读取和写入 Excel 单元格。而 Excel 用户则可以在一个“标准”环境中开始涉猎 Python,从Excel顺利过渡到Python,而不需要学习新的工具。
那么,将notebook单元格放入网格有什么问题呢?
所有人都很熟悉电子表格:你在单元格中输入数字和公式,然后由Excel计算每个单元格的依赖关系,并在特定输入变更时重新计算需要更新的单元格。而单元格在电子表格中的位置并不重要。
然而,Excel中的Python编程打破了这一核心电子表格规则:尽管行为与用户自定义函数非常相似,但Excel中Python代码的处理顺序为:从左到右、从上到下。这包括工作簿,因此工作簿的计算顺序为:第一个工作簿,第二个工作簿,依此类推。
当初Office引入脚本,代码存储在 SharePoint/OneDrive 上,因此用户可以在多个工作簿中使用相同的代码,而不需要任何复制/粘贴操作。这也意味着,在发现错误时,用户只需修改一处代码。多么美好。如果Office脚本文件可以是常规 TypeScript 文件,那就更好了,但这是另一个故事。
如今,Excel中的Python编程将代码存储在 Excel 文件中。对最终用户来说,代码存在于单元格中,但从技术的角度来看,这些代码的存储位置为 Excel 工作簿的 /xl/pythonScripts.xml 下(即 ZIP 文件中)。所以,我们又回到了复制/粘贴,“哦耶!”。
每当想将 pandas DataFrame(或任何其他 Python 对象)写入 Excel 单元格时,你首先需要从对象模式切换到值模式(公式栏左侧的按钮)。这就引出了两个问题:
将DataFrame转换为值时,如果使用了默认的整数索引,则索引是隐藏的。如果索引是文本或非默认索引,则会显示。魔法!
想象一下,你有 100 个单元格,在第 3 个单元格中将 id 列设置为 DataFrame 索引。这意味着,当你将 Python 对象转换为值时,第 100 个单元格中突然会多出一列。
从对象模式切换到值模式时,有些公式会发生变化,比如=PY("...", 1)会变成=PY("...", 0)。然而,这对用户是隐藏的,用户只能看到单元格中的 Python 代码(也就是公式中的“...”部分)。魔法!
我看到的问题主要有两个:
用户无法直接引用具有 Python 对象的单元格,因为存在一定的风险,如果某天有人将该单元格切换到值模式,就会破坏引用此单元格中对象模式的其他公式。
对象模式下的 Python 单元格行为不同于任何其他对象单元格(“Excel(富)数据类型”)。以股票数据类型为例:这种单元格始终是一个对象,你只需在另一个单元格中输入 =A1.Price就可以显示其价格。Python单元格的行为本应采用相同的方式,这样你只需输入=A1.Values就可以获取值。微不足道的一致性却能带来长期的好处。
我主要使用 Jupyter notebooks 完成一些交互式数据分析或尝试一些渐进的操作。你在一个单元格中输入几行代码,按 Shift+Enter 计算单元格,查看中间结果,然后继续下一个单元格。
然而,在Excel中使用Python时,我看不到单元格的输出,所以我必须:
将单元格类型从对象改为值。这个操作一般是不可能的,因为你需要确保单元格周围有足够的空间。
点击预览图标,打开一个弹出窗口。不仅操作步骤增加了,而且预览窗口通常都没什么用:窗口太小,而且 Excel 单元格中显示的值是Excel的表示法,而不是Jupyter notebook的表示法。这个问题应该能被修复,但目前距离初始版本已经快一年了,仍然在预览中显示 #N/A,所以我不知道究竟是 np.nan,pd.NA,还是 pd.NaT。
工作流程中的摩擦太多了,所以我不打算考虑使用Excel中的Python完成交互式数据分析。
我认为,诊断面板是Excel中的Python的最大问题。首先,名称过于技术化,为什么不能像VS Code那样简单地称其为“输出”呢?
所有单元格中的 print() 的结果和所有错误消息都会显示在诊断面板中。因此,Jupyter notebook中显示的一切都会直接出现在单元格下方。但Excel中的Python将输出抽离了单元格,因此你必须手动将输出关联到正确的单元格。以下是两个示例:
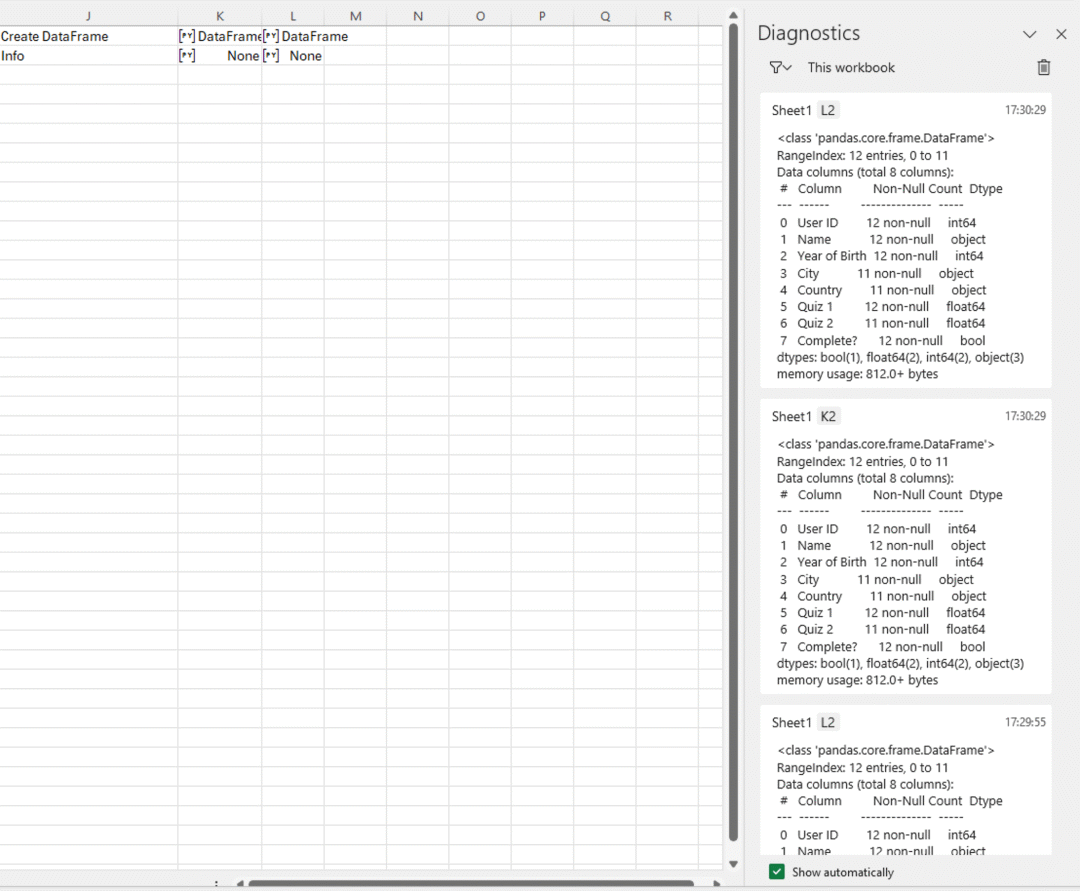
查看 DataFrame 时,一般你会首先运行 df.info()。而如今,由于输出会打印出来,每当 Excel 重新计算 Python 单元格时,诊断面板就会弹出。这令人恼火,而且你完全无法快速地将诊断面板上的输出与相应的单元格关联起来。此外,单元格还会保留前一次运行的输出,所以找到你想要的行会难上加难。哪个是df1的输出,哪个是df2?不知道,除非查看 L2 和 K2 单元格中的代码:
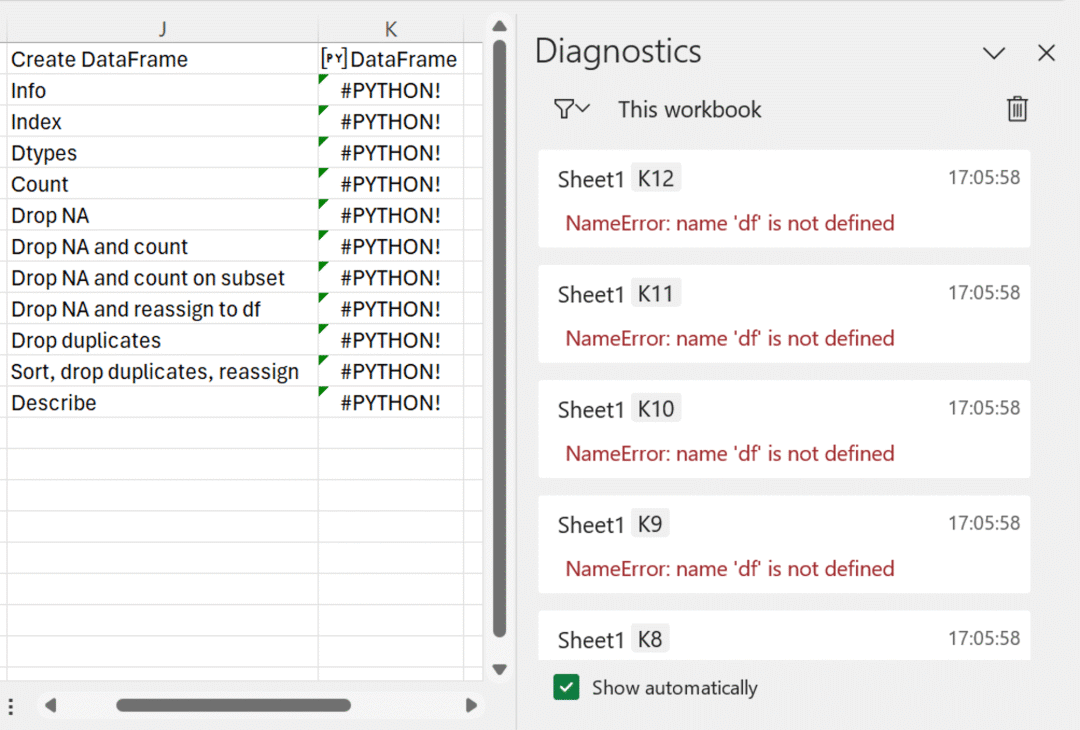
异常处理也面临相同的窘境。你看看能否找到以下截图中的错误(答案:错误发生在 K2 单元格中,但在诊断面板中该条错误已消失在底部)。
对于Python初学者来说,轻松获取错误反馈非常重要。然而,Excel却无法提供,这也是我认为Excel中的Python编程不适合初学者的原因。
我有一个建议:对于显示输出同时不丢失上下文,预览弹出窗口是一个更好的选择。此外,当出现错误时,将单元格或PY图标标记为红色可以提供进一步的帮助。
你可能已经听说过,Python在Azure容器实例上运行,而不是在Excel内部。社交媒体上有很多强烈的反对声音,但这些评论者忽略了大多数公司都会使用OneDrive/SharePoint来管理所有的数据。
事实上,我同意云是Excel引入Python的最佳方式。对于没有经验的人和大型团队来说,在本地维护和安装Python环境根本不可行。另一种选择是WebAssembly(WASM),但看似Excel团队打算将这个实现留给我。
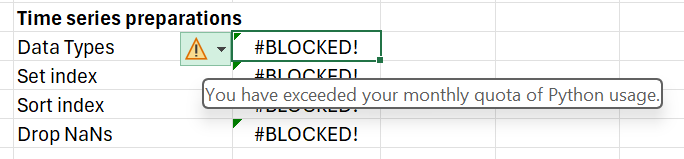
不过,请记住,Excel中的Python将在微软365订阅费用之上收取额外的费用(具体费用未知),而且使用配额还有一定的限制。我就曾收到以下消息:
出现这种情况很令人恼火,而通过Excel电子表格完成冲基金交易时遇到这种情况更是不可接受。即使没有配额限制,Azure云有时会崩溃,导致Python单元格无法工作,这一点需要特别注意。
说了这么多都是为了表明,如果无法在云服务宕机时切换到自托管或本地服务器,我就不会使用Excel中的Python完成关键任务。
人们喜爱Python的一个主要原因是这是一种“胶水语言”。在Python编程中,你可以连接所需连接的一切,还有适用于各种场景的包。常见的工作流程如下:通过Web API下载一些文件,从数据库获取数据,通过pandas或polars DataFrame处理所有数据,最后通过电子邮件发送结果。
然而,Excel中的Python无法实现这种基本的工作流。你无法安装任何额外的包,代码在一个封闭的环境中运行,这意味着你无法通过Web API或数据库连接到外部世界。官方的解决方案是使用Power Query获取外部数据,因为在Excel中的Python可以引用Power Query。但实际上,我希望在Excel中使用Python和pandas的原因之一正是为了避免使用Power Query(我不想学习M语言),所以我对这种解决方案并不是很满意。
以下是我不理解的地方:
Excel中的Python在Azure容器实例上运行。Azure容器实例可以使用你自己的容器,并且拥有所有需要的依赖项,因此我真的不明白为什么Excel团队在Reddit问答活动中表示,每次打开工作簿时都必须从头安装依赖项。这简直是胡说八道,因为容器镜像只需构建一次,下次打开工作簿所有依赖项都可以立即使用。
我可以通过Office脚本访问Web API,但为什么Excel中的Python不能?据我所知,Office管理员可以限制Office脚本可以访问的内容,因此我希望Excel中的Python也能提供类似的功能。
总结一下,由于缺少包且无法访问互联网,导致许多最初呼吁在Excel中引入Python的案例都无法在Excel中使用Python。
Excel中的Python提供了Matplotlib和Seaborn,这两个工具可用于创建图表,然而对于Excel来说,创建图表的功能是不是太过于基础了?虽然这个功能本身很好,也确实有必要,但输出静态图片是不是太无聊了?
人们经常使用Excel做报表。一个很常见的用法是合并包含多个工作表数据的一个或多个工作簿。例如,每个月、每个店铺或每个部门都有一个工作表。在Excel的Python编程中,你必须手动选择每个工作表上的数据才能获取所有数据。
jan = xl("Jan[#All]", headers=True)feb = xl("Feb[#All]", headers=True)mar = xl("Mar[#All]", headers=True)...df = pd.concat([jan, feb, mar, ...])
如果你只需要合并一周的数据,或者只有100个部门,那算你走运。如果Excel中的Python允许你访问Excel对象模型(就像VBA或Office脚本),那么代码就可以写成下面这样:
data = []for sheet in workbook.sheets:data.append(sheet.tables[0].range.options(pd.DataFrame).value)df = pd.concat(data)
至于报表,每个人对于颜色和单元格边框格式都有不同的需求,但无法访问Excel对象模型,这些也无法实现。
如果你选择了1个以上的单元格,xl()函数就会返回一个pandas数据框。我不介意这个默认功能,但在实际工作中,我们常常需要列表、NumPy数组(或polars数据框),而不是pandas数据框。实际上,这应该很容易实现。你甚至可以自己动手编写转换器来解决这个问题。下面是参考写法:
def myconverter(x, headers=False, convert=None, **kwargs):if convert is None or convert == pd.DataFrame:return excel.convert_to_dataframe(x, headers=headers, **kwargs)elif convert == np.array:return np.array(x)elif convert == list:return xelse:raise ValueError(f"{convert} is not supported.")excel.set_xl_array_conversion(myconverter)
在初始化窗格中运行上述代码,就可以像往常一样使用xl()函数来获取pandas数据框:
df = xl("A1:B2", headers=True)而且你还可以获取NumPy数组:
arr = xl("A1:B2", convert=np.array)或者是列表:
mylist = xl("A1:B2", convert=list)只需要几行代码,但目前Excel中的Python却没有提供,所以你需要重复编写相同的代码,并在工作簿之间复制/粘贴。
我问自己:“如今的Excel虽然添加了Python,却只能提升Excel公式语言的分析能力,难道我们就没有更好的替代方案了吗?”我认为,有。我们可以改进Excel的原生公式语言。近年来,微软正在朝着这个方向努力。一切始于 2018 年首次出现的动态数组,这打开了 =UNIQUE() 或 =SORT() 这类的强大公式的大门。最近,微软添加了以下新功能:
=PIVOT()
=GROUPBY()
这就是我在Excel中创建 pandas 数据框的一半原因,我无需编写df.pivot_table() 和df.groupby(),而是使用Excel的原生功能,编写正确的公式,这样就可以摆脱笨重的Python。
然而,我发现有趣的是 PY 单元格的多行编辑体验。为什么不升级一下Excel原生的公式语言呢?这样我就不必编写如下LET表达式了:
=LET(x, 1, y, 2, x + y)我可以直接写下面的代码:
let x = 1let y = 2x + y
另外,为什么不将 Excel 表格转换为 Excel 的原生数据框呢?给它们添加属性就可以了:
=MyTable[#All].GROUPBY(...)我们可以通过各种方法,以更原生的方法,将pandas的功能集成到Excel。

Excel引入Python肯定没问题,但我认为,相较于将单元格直接放置在 Excel 表格中,将经典的 Jupyter notebook 集成到 Excel 中会更好。
不要忘记,截至今天,Excel中的Python编程仍处于预览阶段,所以接下来我们还会看到更多改进,以及限制的减少。
大模型刷新一切,让我们有着诸多的迷茫,AI 这股热潮究竟会推着我们走向何方?面对时不时一夜变天,焦虑感油然而生,开发者怎么能够更快、更系统地拥抱大模型?《新程序员 007》以「大模型时代,开发者的成长指南」为核心,希望拨开层层迷雾,让开发者定下心地看到及拥抱未来。
读过本书的开发者这样感慨道:“让我惊喜的是,中国还有这种高质量、贴近开发者的杂志,我感到非常激动。最吸引我的是里面有很多人对 AI 的看法和经验和一些采访的内容,这些内容既真实又有价值。”
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12











 鲁公网安备37020202000738号
鲁公网安备37020202000738号