Python编程:打造你的“谷歌搜索”系统
发表时间: 2020-02-17 12:04

来源 | hackernoon
编译 | 武明利,责编 | Carol
出品 | AI科技大本营(ID:rgznai100)
在这篇文章中,我将向您展示如何使用Python构建自己的答案查找系统。基本上,这种自动化可以从图片中找到多项选择题的答案。
有一件事我们要清楚,在考试期间不可能在互联网上搜索问题,但是当考官转过身去的时候,我可以很快地拍一张照片。这是算法的第一部分。我得想办法把这个问题从图中提取出来。
似乎有很多服务可以提供文本提取工具,但是我需要某种API来解决此问题。最后,Google的VisionAPI正是我正在寻找的工具。很棒的事情是,每月前1000个API调用是免费的,这足以让我测试和使用该API。

Vision AI
首先,创建Google云帐户,然后在服务中搜索Vision AI。使用VisionAI,您可以执行诸如为图像分配标签来组织图像,获取推荐的裁切顶点,检测著名的风景或地方,提取文本等工作。
检查文档以启用和设置API。配置后,您必须创建JSON文件,包含您下载到计算机的密钥。
运行以下命令安装客户端库:
pip install google-cloud-vision然后通过设置环境变量
GOOGLE_APPLICATION_CREDENTIALS,为应用程序代码提供身份验证凭据。
import os, iofrom google.cloud import visionfrom google.cloud.vision import types# JSON file that contains your keyos.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'your_private_key.json'# Instantiates a clientclient = vision.ImageAnnotatorClientFILE_NAME = 'your_image_file.jpg'# Loads the image into memorywith io.open(os.path.join(FILE_NAME), 'rb') as image_file:content = image_file.readimage = vision.types.Image(content=content)# Performs text detection on the image fileresponse = client.text_detection(image=image)print(response)# Extract descriptiontexts = response.text_annotations[0]print(texts.description)
在运行代码时,您将看到JSON格式的响应,其中包括检测到的文本的规范。但我们只需要纯描述,所以我从响应中提取了这部分。

在Google上搜索问题
下一步是在Google上搜索问题部分来获得一些信息。我使用正则表达式(regex)库从描述(响应)中提取问题部分。然后我们必须将提取出的问题部分进行模糊化,以便能够对其进行搜索。
import reimport urllib# If ending with question markif '?' in texts.description:question = re.search('([^?]+)', texts.description).group(1)# If ending with colonelif ':' in texts.description:question = re.search('([^:]+)', texts.description).group(1)# If ending with newlineelif '\n' in texts.description:question = re.search('([^\n]+)', texts.description).group(1)# Slugify the matchslugify_keyword = urllib.parse.quote_plus(question)print(slugify_keyword)

抓取的信息
我们将使用 BeautifulSoup 抓取前3个结果,以获得关于问题的一些信息,因为答案可能位于其中之一。
另外,如果您想从Google的搜索列表中抓取特定的数据,不要使用inspect元素来查找元素的属性,而是打印整个页面来查看属性,因为它与实际的属性有所不同。
我们需要对搜索结果中的前3个链接进行抓取,但是这些链接确实被弄乱了,因此获取用于抓取的干净链接很重要。
/url?q=https://en.wikipedia.org/wiki/IAU_definition_of_planet&sa=U&ved=2ahUKEwiSmtrEsaTnAhXtwsQBHduCCO4QFjAAegQIBBAB&usg=AOvVaw0HzMKrBxdHZj5u1Yq1t0en正如您所看到的,实际的链接位于q=和&sa之间。通过使用正则表达式Regex,我们可以获得这个特定的字段或有效的URL。
result_urls =def crawl_result_urls:req = Request('https://google.com/search?q=' + slugify_keyword, headers={'User-Agent': 'Mozilla/5.0'})html = urlopen(req).readbs = BeautifulSoup(html, 'html.parser')results = bs.find_all('div', class_='ZINbbc')try:for result in results:link = result.find('a')['href']# Checking if it is url (in case)if 'url' in link:result_urls.append(re.search('q=(.*)&sa', link).group(1))except (AttributeError, IndexError) as e:pass
在我们抓取这些URLs的内容之前,让我向您展示使用Python的问答系统。

问答系统
这是算法的主要部分。从前3个结果中抓取信息后,程序应该通过迭代文档来检测答案。首先,我认为最好使用相似度算法来检测与问题最相似的文档,但是我不知道如何实现它。
经过几个小时的研究,我在Medium上找到了一篇文章,用Python解释了问答系统。它有易于使用的python软件包能够对您自己的私有数据实现一个QA系统。
让我们先安装这个包:
pip install cdqa我正在使用下面的示例代码块中包含的下载功能来手动下载经过预训练的模型和数据:
import pandas as pdfrom ast import literal_evalfrom cdqa.utils.filters import filter_paragraphsfrom cdqa.utils.download import download_model, download_bnpp_datafrom cdqa.pipeline.cdqa_sklearn import QAPipeline# Download data and modelsdownload_bnpp_data(dir='./data/bnpp_newsroom_v1.1/')download_model(model='bert-squad_1.1', dir='./models')# Loading data and filtering / preprocessing the documentsdf = pd.read_csv('data/bnpp_newsroom_v1.1/bnpp_newsroom-v1.1.csv', converters={'paragraphs': literal_eval})df = filter_paragraphs(df)# Loading QAPipeline with CPU version of BERT Reader pretrained on SQuAD 1.1cdqa_pipeline = QAPipeline(reader='models/bert_qa.joblib')# Fitting the retriever to the list of documents in the dataframecdqa_pipeline.fit_retriever(df)# Sending a question to the pipeline and getting predictionquery = 'Since when does the Excellence Program of BNP Paribas exist?'prediction = cdqa_pipeline.predict(query)print('query: {}\n'.format(query))print('answer: {}\n'.format(prediction[0]))print('title: {}\n'.format(prediction[1]))print('paragraph: {}\n'.format(prediction[2]))
它的输出应该是这样的:

它打印出确切的答案和包含答案的段落。
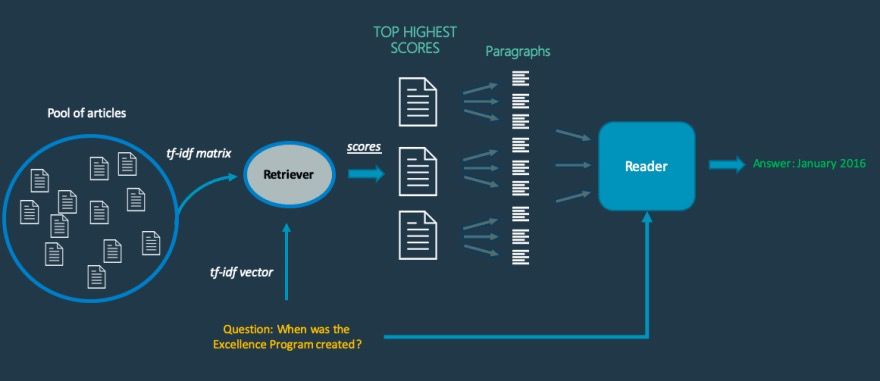
基本上,当从图片中提取问题并将其发送到系统时,检索器将从已抓取数据中选择最有可能包含答案的文档列表。如前所述,它计算问题与抓取数据中每个文档之间的余弦相似度。
在选择了最可能的文档后,系统将每个文档分成几个段落,并将问题一起发送给读者,这基本上是一个预先训练好的深度学习模型。所使用的模型是著名的NLP模型BERT的Pytorch 版本。
然后,读者输出在每个段落中找到的最可能的答案。在阅读者之后,系统中的最后一层通过使用内部评分函数对答案进行比较,并根据分数输出最有可能的答案,这将得到我们问题的答案。
下面是系统机制的模式。
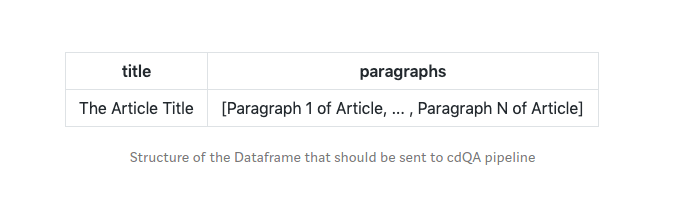
你必须在特定的结构中设置数据帧(CSV),以便将其发送到 cdQA 管道。
但是实际上我使用PDF转换器从PDF文件目录创建了一个输入数据框。因此,我要在pdf文件中保存每个结果的所有抓取数据。我们希望总共有3个pdf文件(也可以是1个或2个)。另外,我们需要命名这些pdf文件,这就是为什么我抓取每个页面的标题的原因。
def get_result_details(url):try:req = Request(url, headers={'User-Agent': 'Mozilla/5.0'})html = urlopen(req).readbs = BeautifulSoup(html, 'html.parser')try:# Crawl any heading in result to name pdf filetitle = bs.find(re.compile('^h[1-6]$')).get_text.strip.replace('?', '').lower# Naming the pdf filefilename = "/home/coderasha/autoans/pdfs/" + title + ".pdf"if not os.path.exists(os.path.dirname(filename)):try:os.makedirs(os.path.dirname(filename))except OSError as exc: # Guard against race conditionif exc.errno != errno.EEXIST:raisewith open(filename, 'w') as f:# Crawl first 5 paragraphsfor line in bs.find_all('p')[:5]:f.write(line.text + '\n')except AttributeError:passexcept urllib.error.HTTPError:passdef find_answer:df = pdf_converter(directory_path='/home/coderasha/autoans/pdfs')cdqa_pipeline = QAPipeline(reader='models/bert_qa.joblib')cdqa_pipeline.fit_retriever(df)query = question + '?'prediction = cdqa_pipeline.predict(query)print('query: {}\n'.format(query))print('answer: {}\n'.format(prediction[0]))print('title: {}\n'.format(prediction[1]))print('paragraph: {}\n'.format(prediction[2]))return prediction[0]
我总结一下算法:它将从图片中提取问题,在Google上搜索它,抓取前3个结果,从抓取的数据中创建3个pdf文件,最后使用问答系统找到答案。
如果你想看看它是如何工作的,请检查我做的一个可以从图片中解决考试问题的机器人。
以下是完整的代码:
import os, ioimport errnoimport urllibimport urllib.requestimport hashlibimport reimport requestsfrom time import sleepfrom google.cloud import visionfrom google.cloud.vision import typesfrom urllib.request import urlopen, Requestfrom bs4 import BeautifulSoupimport pandas as pdfrom ast import literal_evalfrom cdqa.utils.filters import filter_paragraphsfrom cdqa.utils.download import download_model, download_bnpp_datafrom cdqa.pipeline.cdqa_sklearn import QAPipelinefrom cdqa.utils.converters import pdf_converterresult_urls =os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'your_private_key.json'client = vision.ImageAnnotatorClientFILE_NAME = 'your_image_file.jpg'with io.open(os.path.join(FILE_NAME), 'rb') as image_file:content = image_file.readimage = vision.types.Image(content=content)response = client.text_detection(image=image)texts = response.text_annotations[0]# print(texts.description)if '?' in texts.description:question = re.search('([^?]+)', texts.description).group(1)elif ':' in texts.description:question = re.search('([^:]+)', texts.description).group(1)elif '\n' in texts.description:question = re.search('([^\n]+)', texts.description).group(1)slugify_keyword = urllib.parse.quote_plus(question)# print(slugify_keyword)def crawl_result_urls:req = Request('https://google.com/search?q=' + slugify_keyword, headers={'User-Agent': 'Mozilla/5.0'})html = urlopen(req).readbs = BeautifulSoup(html, 'html.parser')results = bs.find_all('div', class_='ZINbbc')try:for result in results:link = result.find('a')['href']print(link)if 'url' in link:result_urls.append(re.search('q=(.*)&sa', link).group(1))except (AttributeError, IndexError) as e:passdef get_result_details(url):try:req = Request(url, headers={'User-Agent': 'Mozilla/5.0'})html = urlopen(req).readbs = BeautifulSoup(html, 'html.parser')try:title = bs.find(re.compile('^h[1-6]$')).get_text.strip.replace('?', '').lower# Set your path to pdf directoryfilename = "/path/to/pdf_folder/" + title + ".pdf"if not os.path.exists(os.path.dirname(filename)):try:os.makedirs(os.path.dirname(filename))except OSError as exc:if exc.errno != errno.EEXIST:raisewith open(filename, 'w') as f:for line in bs.find_all('p')[:5]:f.write(line.text + '\n')except AttributeError:passexcept urllib.error.HTTPError:passdef find_answer:# Set your path to pdf directorydf = pdf_converter(directory_path='/path/to/pdf_folder/')cdqa_pipeline = QAPipeline(reader='models/bert_qa.joblib')cdqa_pipeline.fit_retriever(df)query = question + '?'prediction = cdqa_pipeline.predict(query)# print('query: {}\n'.format(query))# print('answer: {}\n'.format(prediction[0]))# print('title: {}\n'.format(prediction[1]))# print('paragraph: {}\n'.format(prediction[2]))return prediction[0]crawl_result_urlsfor url in result_urls[:3]:get_result_details(url)sleep(5)answer = find_answerprint('Answer: ' + answer)
有时它可能会混淆,但我认为总体来说是可以的。至少我可以用60%的正确答案通过考试。
欢迎开发者们在评论中告诉我你的看法!实际上,最好是一次遍历所有问题,但我没有足够的时间来做这件事,所以只好下次继续再做。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号