Python爬虫反反爬虫策略详解
发表时间: 2020-06-26 17:08
过程如下,仅供参考。
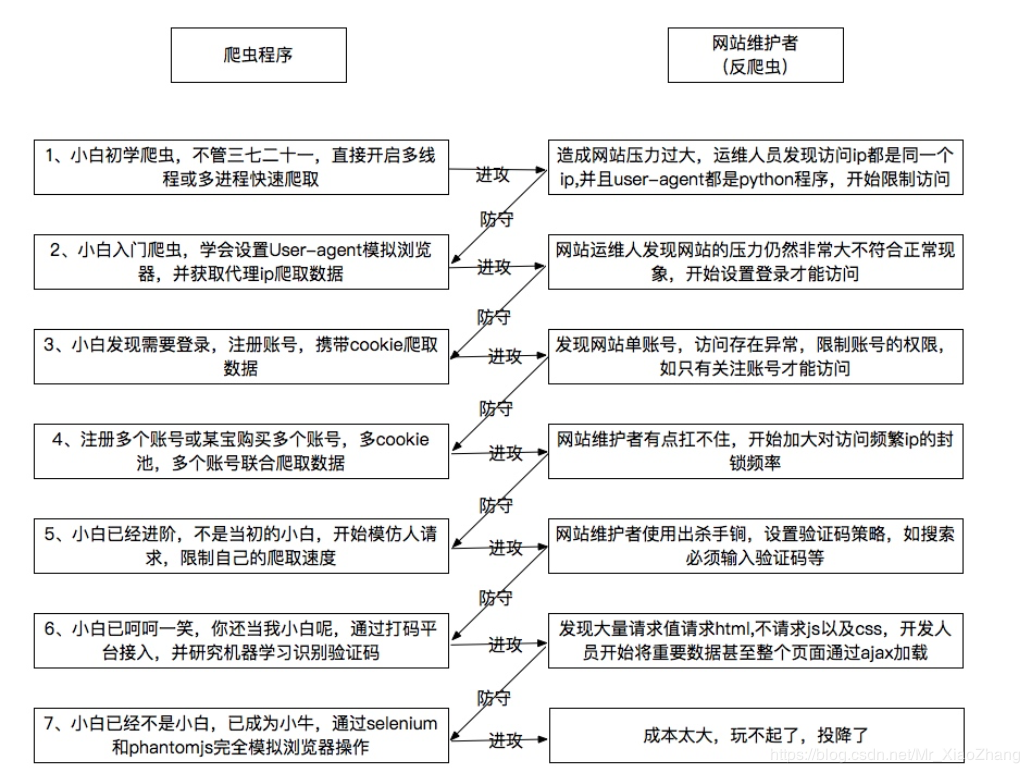
网站反爬虫方式
无论是浏览器还是爬虫程序,在向服务器发起网络请求的时候,都会发过去一个头文件:headers, 表明身份
对于爬虫程序来说,最需要注意的字段就是:User-Agent
很多网站都会建立 user-agent白名单,只有属于正常范围的user-agent才能够正常访问。
解决方法:
可以自己设置一下user-agent,或者更好的是,可以从一系列的user-agent里随机挑出一个符合标准的使用
举个例子:如果想爬取某个网站,在请求之前,它会有一个验证页面来验证你是否机器。
它是怎么实现的呢:
* 他会通过js代码生成一大段随机的数字,然后要求浏览器通过js的运算得出这一串数字的和,再返回给服务器.
解决方法: 使用PhantomJS
* PhantomJS是一个Python包,它可以在没有图形界面的情况下,完全模拟一个”浏览器“,js脚本验证什么的再也不是问题了。
如果一个固定的ip在短暂的时间内,快速大量的访问一个网站,那自然会引起注意,管理员可以通过一些手段把这个ip给封了,爬虫程序自然也就做不了什么了。
解决方法:
比较成熟的方式是:IP代理池
简单的说,就是通过ip代理,从不同的ip进行访问,这样就不会被封掉ip了。
可是ip代理的获取本身就是一个很麻烦的事情,网上有免费和付费的,但是质量都层次不齐。如果是企业里需要的话,可以通过自己购买集群云服务来自建代理池。
def get_ip_poll():
'''
模拟代理池
返回一个字典类型的键值对,
'''
ip_poll = ["http://xx.xxx.xxx.xxx:8000",
"http://xx.xxx.xxx.xxx:8111",
"http://xx.xxx.xxx.xxx:802",
"http://xx.xxx.xxx.xxx:9922",
"http://xx.xxx.xxx.xxx:801"]
addresses = {}
addresses['http'] = ip_poll[random.randint(0, len(ip_poll))]
return addresses
世界上做爬虫最大最好的就是Google了,搜索引擎本身就是一个超级大的爬虫,Google开发出来爬虫24h不间断的在网上爬取着新的信息,并返回给数据库,但是这些搜索引擎的爬虫都遵守着一个协议:robots.txt
robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。因为一些系统中的URL是大小写敏感的,所以robots.txt的文件名应统一为小写。robots.txt应放置于网站的根目录下。
如果想单独定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的robots.txt,或者使用robots元数据(Metadata,又称元数据)。robots.txt协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。注意robots.txt是用字符串比较来确定是否获取URL,所以目录末尾有与没有斜杠“/”表示的是不同的URL。robots.txt允许使用类似"Disallow: *.gif"这样的通配符[1][2]。
当然在特定情况下,比如说我们爬虫的获取网页的速度,和人类浏览网页是差不多的,这并不会给服务器造成太大的性能损失,在这种情况下,是可以不用恪守 robots协议的。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号