快速定位Node.js内存泄露的秘诀
发表时间: 2016-08-02 17:38
在7月7日的云栖TechDay活动上,来自阿里云的穆客给大家分享了《如何快速定位Node.js内存泄露》话题。此次分享主要包括Node.js和APM的简单介绍、Node.js内存管理、Node.js内存泄露及其排查过程四个方面。
下面是现场分享观点整理。
Node.js和APM
很多人应该都知道Node.js,它是一个运行于服务端的基于Chrome V8引擎的 JavaScript 运行环境,Node.js 使用了一个事件驱动、非阻塞式 I/O 的模型,使其轻量又高效。Node.js特别适合于web应用或API服务器,例如手机上的APP,如果它的服务器端采用Node.js来搭建,整体的开发效率会提高很多倍,而且也非常适合IoT服务端应用。
图一 Node.js和APM
同样的任务,用C或C++开发可能需要一个月的时间;采用Node.js开发的话,一两天就可以搭建出原型。因此,对于一些初创型、中小型企业在需要业务快速上线的时候,或者公司里需要快速做原型验证,如果系统不是特别复杂的时候,Node.js是非常适合的。即使业务量上来后,Node.js也是非常容易扩展的,现在像Uber/沃尔玛/阿里等规模的企业里面,Node.js也获得了很好的应用就能说明一些问题。
应用性能管理(APM),是对企业系统即时监控以实现对应用程序性能管理和故障管理的系统化的解决方案。APM的覆盖范围包括五个层次的实现:终端用户体验,应用架构映射,应用事务分析,深度应用诊断,和数据分析。总结成一句话概括:用一切手段把应用的整个链路监测起来,将中间的慢路径或热点找出来,进行优化后提高用户的体验。
现在,Node.js使用已经非常普遍了。在Github上搜索的热度,Node.js处于领先地位。同时,Node.js相比于其他语言的发展速度是最快的,据2016年1月份Node.js社区调查显示:Node.js目前在全球大约有350万用户,年增长率为100%。
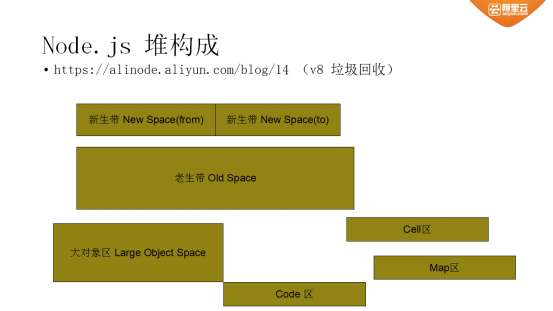
Node.js堆构成
Node.js的内存管理是不需要用户关心的,js代码也看不到内存管理的一些细节的,使用者无法像c语言里那样深入分配、管理内存,只能去创建一些对象,当这些对象不再使用时,v8引擎后期进行垃圾回收,进行内存管理。
图二 Node.js堆组成
这些对象是分配在堆上面的,对于用户代码而言,Node.js堆可以分为以下几个区域:
新生区:大多数对象开始时被分配在这里,新生区是一个很小的区域,垃圾回收在这个区域非常频繁,与其他区域相独立;
老生指针区:包含大多数可能存在指向其他对象的指针的对象,大多数在新生区存活一段时间之后的对象都会被挪到这里;
老生数据区:这里存放只包含原始数据的对象(这些对象没有指向其他对象的指针),字符串、封箱的数字以及未封箱的双精度数字数组,在新生区经历一次 Scavenge 后会被移动到这里;
大对象区:这里存放体积超过1MB大小的对象,每个对象有自己mmap产生的内存。垃圾回收器从不移动大对象;
Code区:代码对象,也就是包含JIT之后指令的对象,会被分配到这里;
Cell区、属性Cell区、Map区:这些区域存放Cell、属性Cell和Map,每个区域因为都是存放相同大小的元素,因此内存结构很简单。
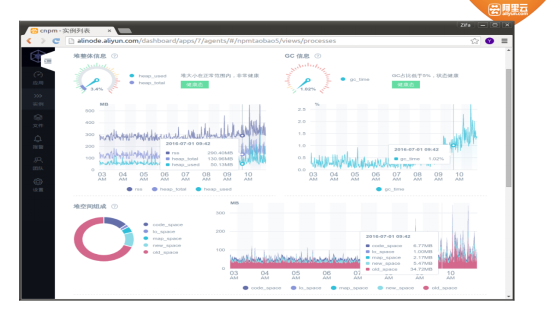
图三 内存使用情况
Alinode平台可以将Node.js代码运行时的状态显示出来。上图显示的是内存使用情况,可以显示整个RSS、堆中的数据以及堆里面的空间使用大小。其中RSS包括堆内堆外所有的;heap_total 表示的是V8从操作系统分配出来的空间;heap_use表示已经在用空间。Rss和heap_total中间这一块是堆外内存,对外内存从用户的角度考虑主要包括buffer和C++等模块分配出的内存。
GC信息是指运行时GC时间占整个程序运行时间的占比,由于进行GC时,用户代码是停掉的,所以这个数据是越小越好。该平台可以将堆上空间内每个Space占用大小显示出来,上图显示的数据是实时数据(来自CNPM),可以看到堆空间主要组成是Old_space。
垃圾回收机制
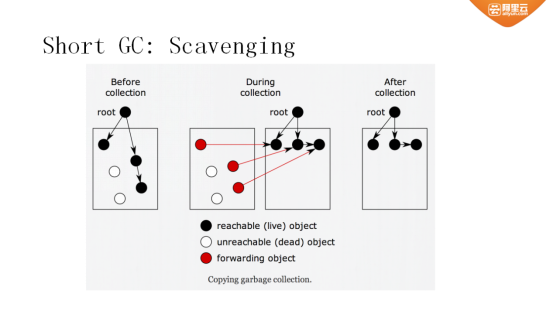
下面简要介绍下垃圾回收(GC)过程。在前面有提到,当堆分为几代之后,重新分配的对象大部分是放到New_space之中(如果这个对象非常大,超过1M,则会放到大对象区内)。新生带分为两类:New Space(from)和New Space(to)。对象在最初生成时,存放在New Space(from)内;当New Space(from)占满之后,进行一次GC操作。
图四 Short GC机制
在V8内有一个根对象(最简单的例子就是全局变量),GC时从根对象内进行遍历:如果另外一个对象被根对象引用了,则表示它是一个活的对象;接着,逐层进行查找,如果发现一个对象已经没有被任何一个对象指向,则认为该对象已死亡;需要将活对象先标记,再把它复制到New Space(to)中,当全部复制完成后;将Space(from)和New Space(to)的指针互换,全部复制后只保留活对象,那么死对象的空间就被空出来了;当有新对象生成时,就可以在这里面生存。
如果经过两次GC操作之后,一个对象仍然存活,则将其移动到老生带内。老生带空间很大,默认为1.4G,堆内几乎所有数据都存在老生带中。
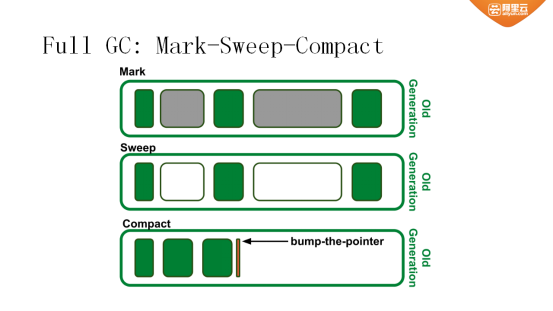
图五 Full GC机制
Scavenging是专门针对新生代的内存处理的,另外一种针对老生代的内存处理策略是标记清理(Mark-Sweep-Compact)。标记清理开始时需要遍历整个老生代,将活的对象标记出来(在图中用绿色颜色标记活对象);将死的对象放到一个列表内,如果两个相邻的对象都已经死掉,则二者连在一起形成列表,最后形成mark sweep。简单地说,就是将死亡的对象标记后放到free list内,当有新对象从新生代移过来时,只要空间足够就可以继续使用。
这里内存是按页进行管理的,每一页大小为1M。如果发现mark sweep多次复制之后,内存呈现碎片化;则需要进行mark compact,将活的对象靠在一起,释放出大量空间供新对象使用。
由于老生代自身很大,每次进行全量操作时,会导致代码停掉1秒甚至更多时间,这个是无法接受的。因此,V8对其进行了优化,采用增量式标记,保证用户代码停顿不会很久。
内存泄露
图六 内存泄露的因素
V8已经帮助用户实现了内存管理,用户无需再关心内存的释放和分配,那么为什么还存在内存泄露呢?
除了V8本身的Bug之外,主要的原因是变量释放问题。如果有变量忘记释放,V8则认为总是存在从根对象到该对象的路径,因此那部分内存不会被释放。堆上泄露主要包括全局变量、闭包和定时器等。前两者好理解,定时器主要分为两种:一种是常用的接口setTimeout,超时之后就释放了;另一种是setInterval(间隔性定时器),设置时如果没有用变量把它记下来,则setInterval就会永远存在那里,不被clear掉,进而导致各类问题发生。
堆外的内存泄露主要发生在Buffer和C++扩展模块。如果是C++模块内存泄露了,则比较麻烦,目前尚不存在gdb外好用的排查手段。
如何解决内存泄露问题?
图七 如何解决问题?
碰到内存泄露的问题该怎么办呢?
目前的整体思路主要有两种:一种是重启,将整个服务进行重启,这种方式虽然暴力,但是可以解决问题。当业务量较少或者代码与状态无关时,重启带来的影响不大;但如果业务比较复杂的话,重启过程较长则对用户的影响就非常大了。
另一种方法是一个优秀程序员应该采用的方法,找到内存泄露的那个Bug,将其解决掉。
内存泄露定位方法
对堆上的内存泄漏的定位,目前存在这几种方法:memwatch、v8 profiler + node inspector(Debug模式)、node-heapdump和Alinode。前三种都是社区内常用的方法,最后一种使阿里云自行开发的工具。
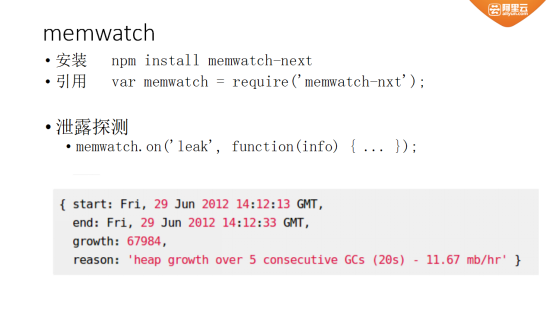
Memwatch
图八 Memwatch方法
Memwatch是在Node.js刚推出不久之后,由个人所开发的。它的基本思路是通过添加C++模块提取V8中的数据;之后通过TXT进行显示的提取的数据信息。
使用Memwatch需要安装一个NPM模块,在用户代码要引用该模块,此外,还要加一些事件,然后可以将所需信息打印出来。
如果需要判断是否存在内存泄露,需要做两次heap_dump,第一次记录每个对象的数量、大小;过一段时间再做第二次,生成报告里面的String会记录这段时间内对象的变化情况。
v8 profiler + node inspector
图九 v8 profiler + node inspector方法
v8-profiler + node-inspector,它是一种调试模式。首先需要用安装v8-profiler(实时做Heap dump的工具),还需要安装node-inspector(图形化展示和操作界面);然后采用Debug模式启动应用;之后再进入node-inspector查看内存泄露情况。
node-heapdump
图十 node-heapdump方法
node-heapdump使用前需要通过NPM安装一个heapdump的模块,在应用内部同样需要引用该模块。在外部通过发送一个USR2的信号给PID,node-heapdump是通过外部来触发的。如果不知道什么时间出现问题,可以通过在内部添加逻辑来判断堆的大小。当认为出现问题时,可以发信号给自己或调用heapdump接口,把堆全部dump出来。
Alinode
图十一 Alinode方法
最后一种方法Alinode,首先需要安装Alinode的运行时;同时Alinode支持在生产环境内部署,此外无需修改用户代码;发现问题时,直接进行heapdump;最后生成详细的分析报告。
相比于前三种方式,Alinode可以较为方便、快递地查找到泄漏点,便于后续的修改。
cpu-profiling 以及其它
图十二 CPU-profiling以及其他
Alinode除了支持在线的heapdump之外,还支持在线的CpuProfiling等操作。用户程序写好之后,除非用户逻辑写错,否则最后的问题都可以归结为CPU或内存的瓶颈。
在进程中,如果感觉CPU利用率很高,可以创建一个CPU profile,在线进行三分钟的CPU profiling,三分钟过后将其关闭。Node.js如果不用这种方法,还有两种方法,但都需要在node启动时就设置参数:一个是Debug参数,加个node-profiler可以实现该功能;另一种方法是prof参数,可以生成一个prof的文件显示CPU的使用情况。
更多技术细节,请查看该文章:
https://alinode.aliyun.com/blog/18。
总结
图十三 总结
前面介绍的Memwatc、v8-profiler+node-inspector、heapdump三种社区方法,使用起来相对比较复杂,不太适合放到生产环境中;同时需要其他的工具进行监控;最后,堆分析依赖DevTools,不容易定位问题。
针对上述问题,阿里云自行开发的alinode则做了很多改进:
部署简单:安装alinode后,配置一个ID和加密的密钥即可;
无需用户代码变更/监控不影响性能:Node.js自带的用于导出堆信息的process.memoryUsage()等函数运行在用户层面,同用户逻辑共用一个空间,对性能理论上是有那么一点点影响的,另外,也只是给出了三个统计数据,alinode则通过修改V8代码,将足够多的运行时状态写入到一个buffer中,另外开启一个线程(C++线程)写日志,对用户JS代码执行的性能是没用影响的;
生产环境调查问题的必要性:首先一些用户的行为习惯可能在测试环境中难以重现,其次搭建全功能的测试环境成本很高,因此在生产环境中使用Alinode是非常有必要的;
专家支持:对于堆的分析,Alinode提供的工具要比devTools提供的要好。此外,阿里内部有很多JS方面的专家可以提供方案咨询。
专业的人做专业的事情,总结各个用户遇到的问题:通过总结不同客户碰到的问题,将很多诊断方法提前做好,当其他用户碰到类似问题时,就可以大大提高解决效率。
更多详细资料及Alinode试用:
https://alinode.aliyun.com。
精彩问答
提问: 你好,我是上海秦唐信息技术公司,我们两年前开发了一款产品Node.js+mongo DB的APM产品,我们当时在使用的时候很长时间都没有问题,但是后来出现一个内存的问题,积累了大量数据之后,当查询的时候内存急剧上升,在查看路程监控的时候它会上到1.5G,所有的人都访问不了,只能重启释放了。我们把old space扩大到5个G暂时性解决问题,但是大数据的查询Node.js有什么好的办法?另外GC的回收机制是自动的还是由手动来处理合适呢?
穆客:
手动目前没有接口,在很早之前的Node.js版本有个接口是在空闲的时候做一次full GC,但现在已经没有了。V8里有接口强制做full GC,做一个mark compact,有类似的接口,但JS目前没有释放出来;大数据的查询的问题,瓶颈可能是数据库返回太慢了。
提问:
如果不用Node.js查询,单纯的用Mongo DB的客户端去查询,它的EXE的内存也会很大。
穆客:
可以用多个实例的方式来处理。如果优化已经做过了,没有明显的问题,就只能用多实例了。热点找出来看一下是否有逻辑问题?
提问:
CPU的占用比较低,只是内存会上去,Gzip也启动起来了。分析数据量也并不是很大,大概3万条数据,Json因为有很多冗余的数据在里面。
穆客:
Json数据冗余是行业中一致的问题,也有很多人在研究,目前没有好的解决方法。
提问:
有人建议是用Jsonline来解决问题。
穆客:
Json有些应用有几百M确实是个问题。如果100M的Json在Node.js要用好几百M的内存去做处理。
更多深度技术内容,请关注云栖社区微信公众号:yunqiinsight。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12








 鲁公网安备37020202000738号
鲁公网安备37020202000738号