零基础掌握MySQL:实用指南
发表时间: 2020-03-13 21:11
关注我们吧,查看更多干货文章,视频。回复“数据”还有数据分析相关资料领取,每周更有免费直播课,有问题也可私信咨询小编哦!
一、为什么要用全文索引
我们在用一个东西前,得知道为什么要用它,使用全文索引无非有以下原因
二、什么是全文索引
简单的说,全文索引就相当于大词典中的目录,通过查询目录可以快速定位到想看的内容。全文索引通过建立倒排索引来快速匹配文档(仅在mysql5.6版本以上支持)全文索引将连续的字母、数字和下划线当做一个单词,分割单词一般用空格/逗号/句号MySQL的全文索引支持以下3种查询模式:
更多请看:官方文档
下面教大家如何创建全文索引,并创建测试数据演示三种查询模式的使用
三、如何创建全文索引
CREATE TABLE light_weight_baby ( id INT AUTO_INCREMENT NOT NULL PRIMARY KEY, title VARCHAR(200), content TEXT, FULLTEXT(title, content) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ; ALTER TABLE table_name ADD FULLTEXT INDEX index_name (column1,column2,...);CREATE FULLTEXT INDEX index_name ON table_name (column1,column2,...);四、创建测试数据
创建一个数据库用来演示这三种模式下的检索
CREATE DATABASE chenqionghe DEFAULT CHARSET utf8;创建一个文章表并插入测试数据
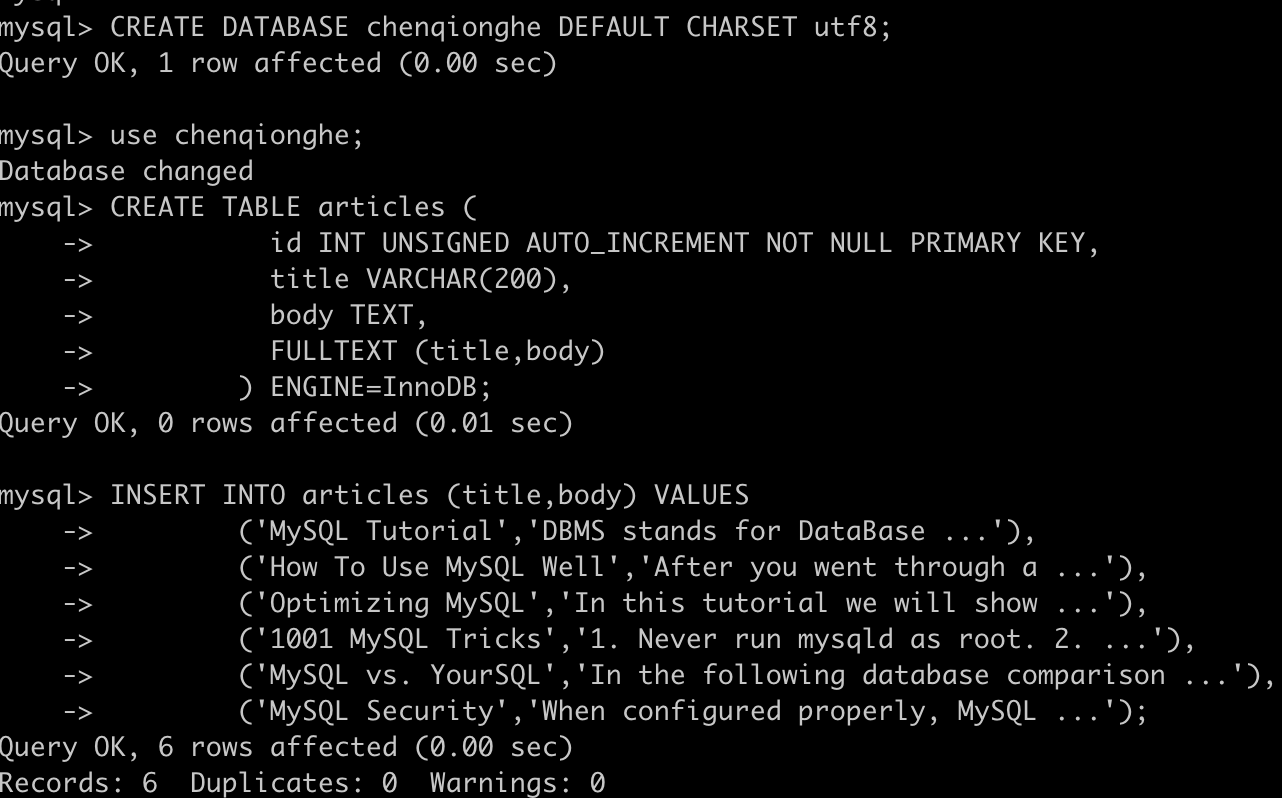
CREATE TABLE articles ( id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY, title VARCHAR(200), body TEXT, FULLTEXT (title,body)) ENGINE=InnoDB;插入测试数据
INSERT INTO articles (title,body) VALUES ('MySQL Tutorial','DBMS stands for DataBase ...'), ('How To Use MySQL Well','After you went through a ...'), ('Optimizing MySQL','In this tutorial we will show ...'), ('1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'), ('MySQL vs. YourSQL','In the following database comparison ...'), ('MySQL Security','When configured properly, MySQL ...');执行结果如下
五、查询-使用自然语言模式
这是MySQL的默认查询模式,简单示例如下
SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('database' IN NATURAL LANGUAGE MODE);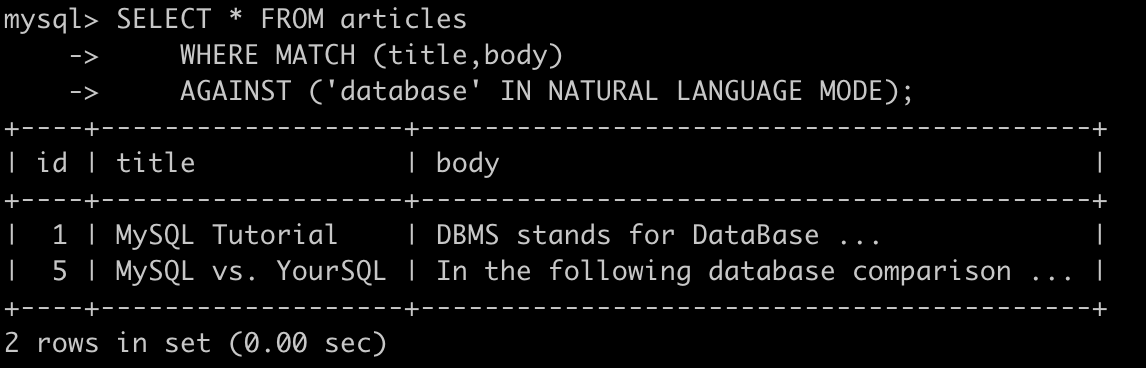
可以看到,不区分大小写,title或body包含database的都返回了,另外,返回的结果将以相关性进行排序。
相关性:根据行中的字段、唯一单词的数量、集合中单词总数和包含特定单词的行数计算。
下面通过两种方式统计数量
# 第一种方式 SELECT COUNT(*) FROM articles WHERE MATCH (title,body) AGAINST ('database' IN NATURAL LANGUAGE MODE);# 第二种方式SELECT COUNT(IF(MATCH (title,body) AGAINST ('database' IN NATURAL LANGUAGE MODE), 1, NULL)) AS count FROM articles;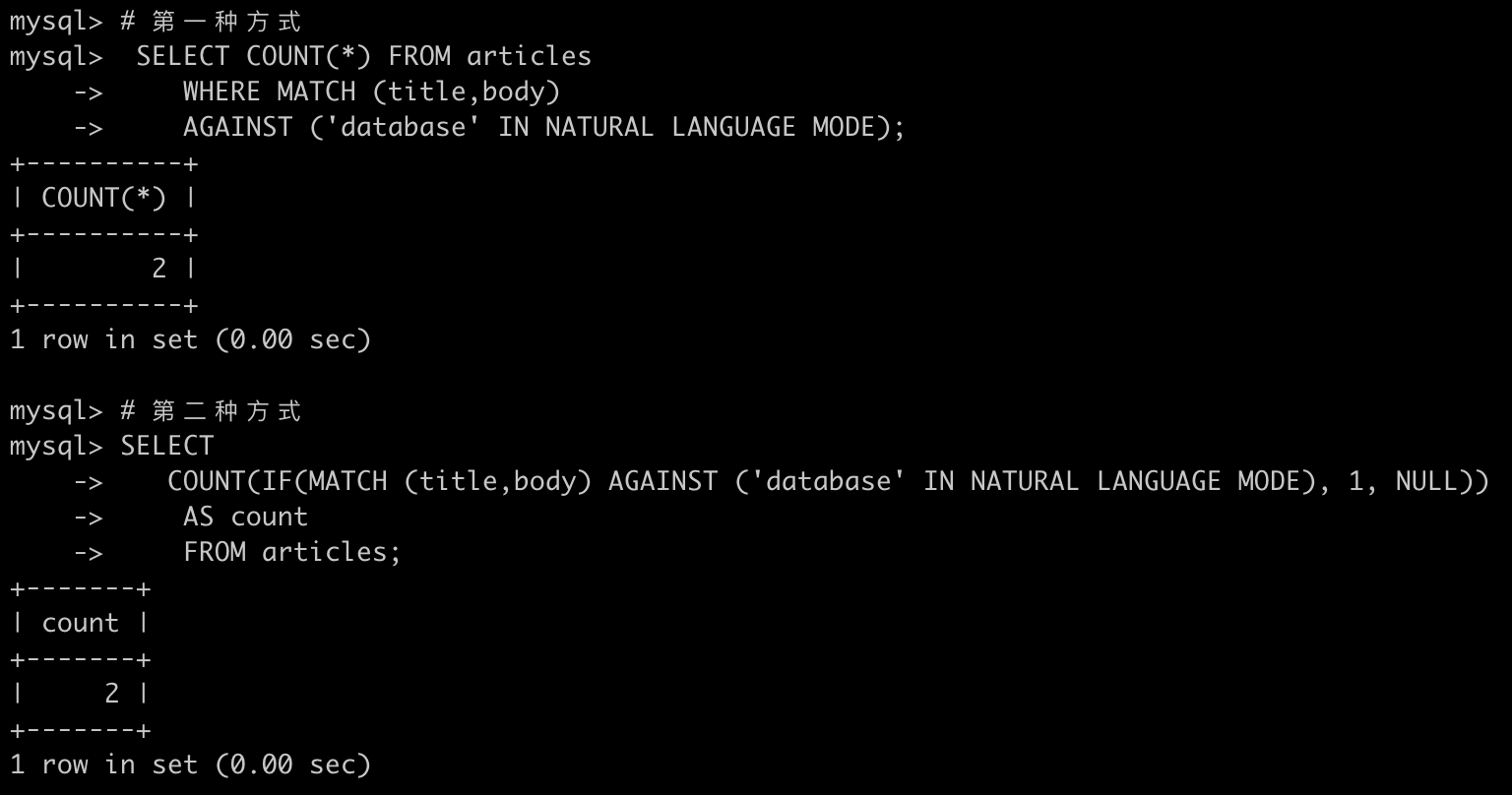
第一种做了一些额外的工作(按相关性对结果进行排序),但也能使用索引进行查询。第二种执行了全表扫描,如果搜索项出现在大多数行中,可能比索引查询更快匹配少数行,第一种快,匹配大多数行,第二种快
下面演示如何检索相关性,但不会进行排序(因为不包含WHERE和ORDER BY)
SELECT id, MATCH (title,body) AGAINST ('Tutorial' IN NATURAL LANGUAGE MODE) AS score FROM articles;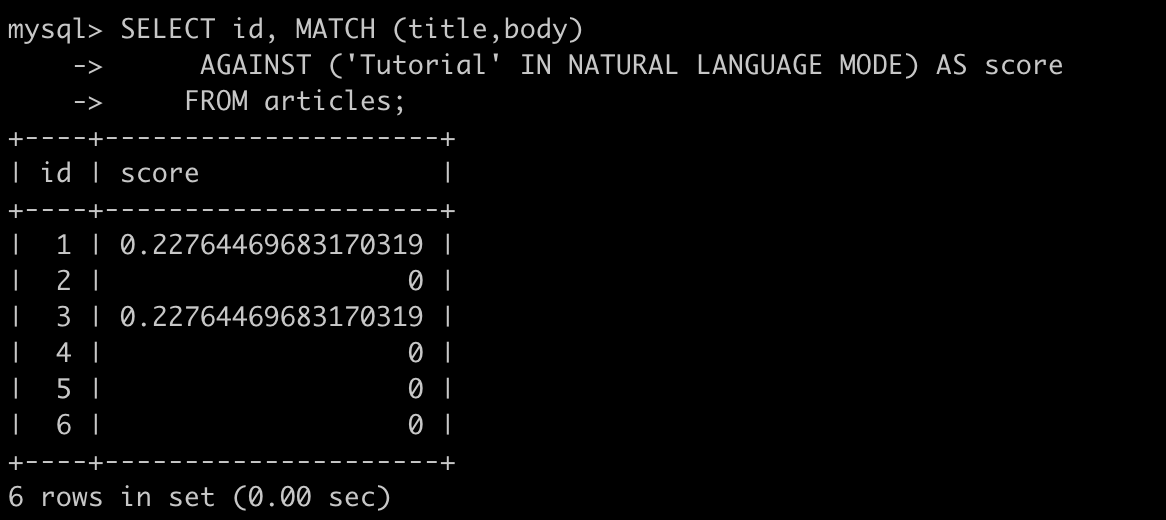
下面的示例更复杂,返回倒序后的相关性值,分别在SELECT和WHERE语句中使用了MATCH,但是不会导致额外的开销,因为mysql优化器注意到两次MATCH是相同的,只会使用一次全文搜索
SELECT id, body, MATCH (title,body) AGAINST ('Security implications of running MySQL as root' IN NATURAL LANGUAGE MODE) AS score FROM articles WHERE MATCH (title,body) AGAINST ('Security implications of running MySQL as root' IN NATURAL LANGUAGE MODE);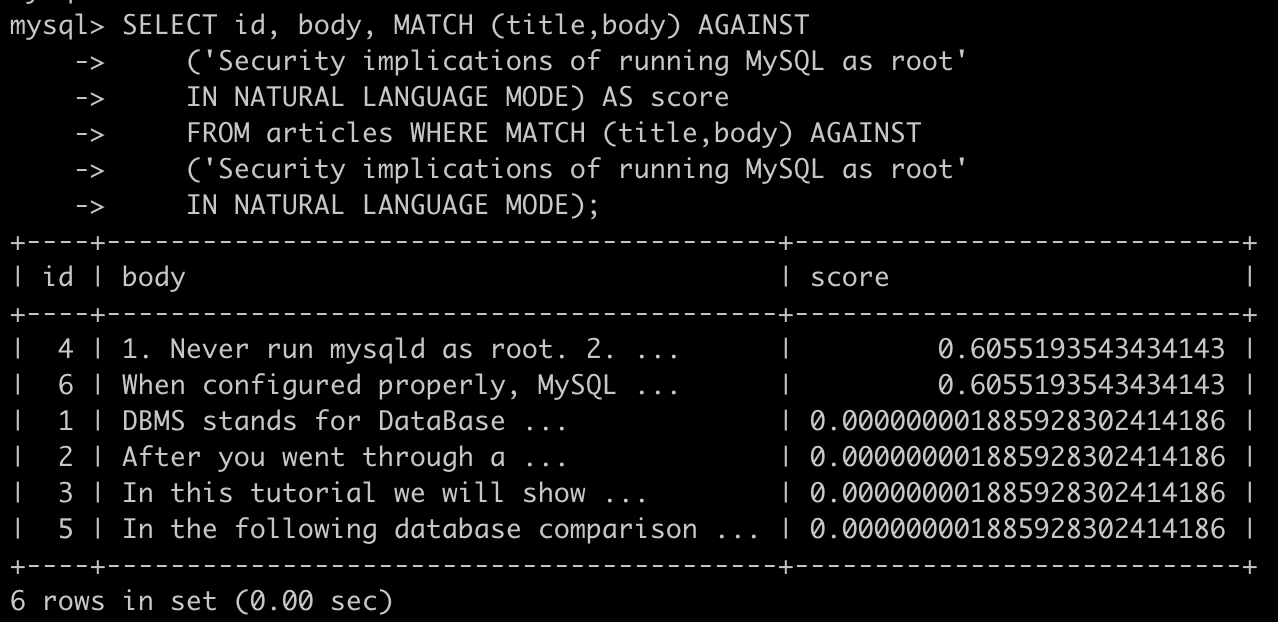
包含在("")中字符中的会被分解为单词,然后在全文索引中进行搜索,简单的说,就是进行OR查询。
六、查询-使用布尔模式(强大的语法)
使用布尔模式需要指定IN BOOLEAN MODE,不会自动根据相关性排序,一些字符具有特殊的含义,例如可以通过+或-表示一个单词必须存在或不存在。下面的sql语句代表查询必须 包含MySQL但不包含YourSQL
SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('+MySQL -YourSQL' IN BOOLEAN MODE);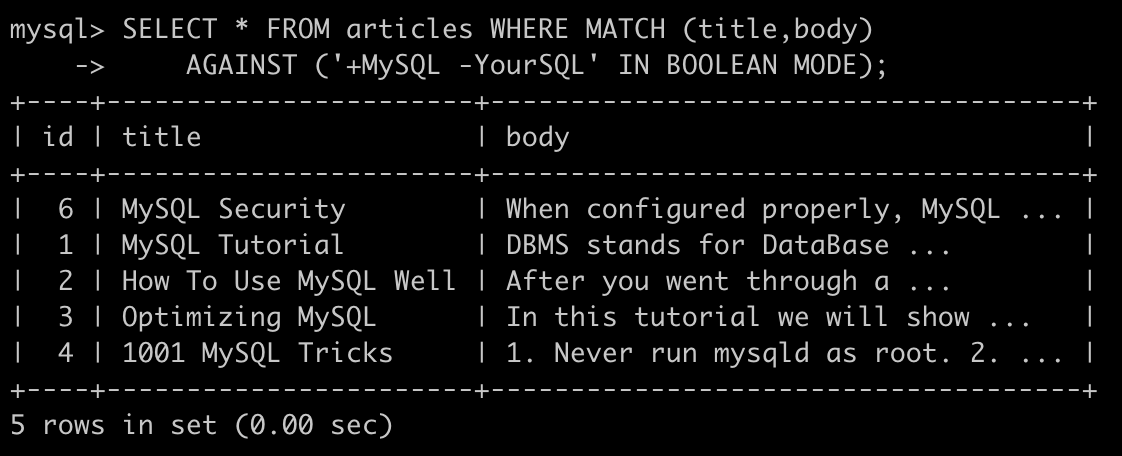
七、查询-使用扩展模式
当搜索短语很短时非常有用,例如搜索database可能意味着MySQL、Oracle、DB2、RDBMS都要被匹配到,这就是这个模式能做的。添加WITH QUERY EXPANSION或 IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION启用,它会执行两次检索,第一次使用给定短语检索,第二次是结合第一次相关性比较高的行进行检索。例如下面的例子
# 自然语言模式SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('database' IN NATURAL LANGUAGE MODE);# 扩展模式SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('database' WITH QUERY EXPANSION);可以看到第二条语句找到了包含MySQL的行,即使该行不包含database,但是因为在第一次的搜索中搜索引擎判断MySQL和database的相关性比较高,所以在执第二次搜索的时候返回了。
八、注意事项
end.
来源:博客园.
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号