深入解析DataX源码:探索其主干逻辑的秘密
发表时间: 2022-07-02 18:54
DataX 是阿里开源的一款异构数据源离线同步工具。将复杂的网状的同步链路变成了星型数据链路。接下来,我们将一起来看看 DataX 整体流程都干啥了,后面再逐步地拆开每个模块来细讲。
继上篇文章:DataX源码分析之二本地启动调试
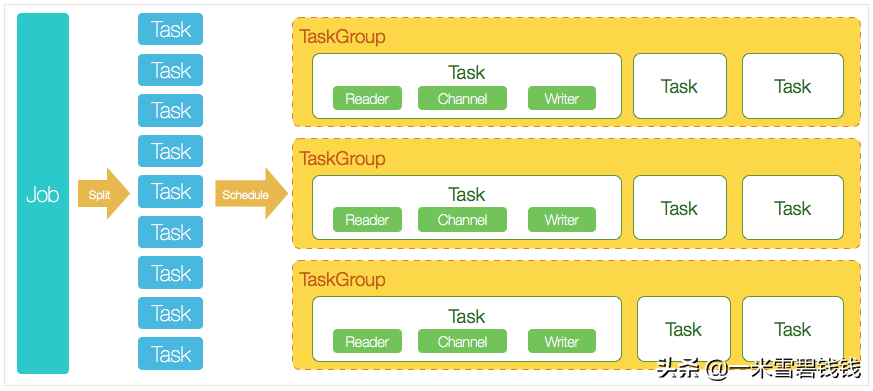
DataX 3.0 核心架构
DataX 里面涉及到一些概念,在阅读源码前,我们必须要整体了解这些概念,防止后续阅读源码搞混了。
启动源码过程,略有删减,对于源码的各种判断,先删除掉。假设我们是最初的开发者,我们需要把握整体流程,其他的各种判断都是开发过程中各种的优化流程。
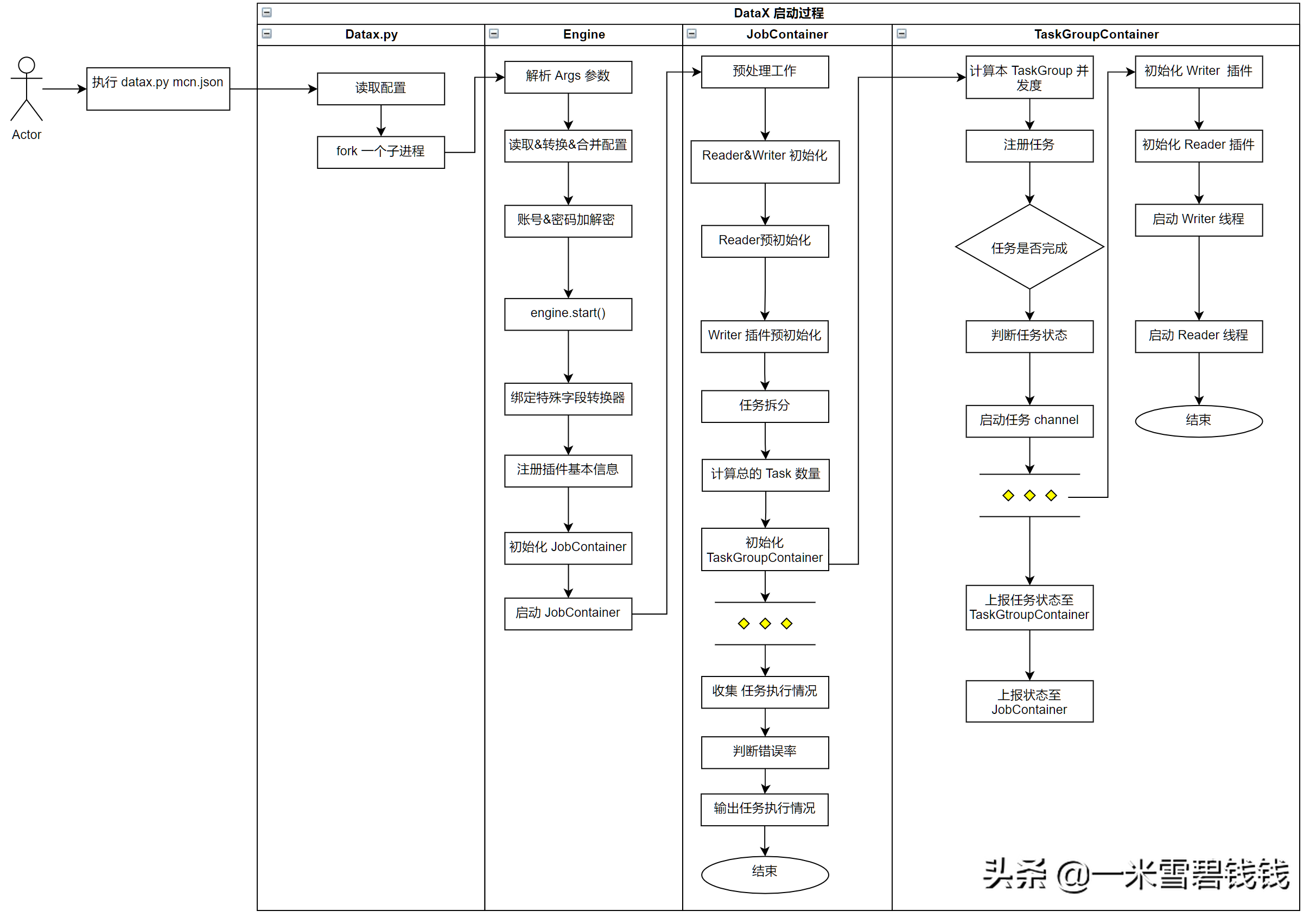
DataX 主干逻辑源码分析流程图
关于我
前去哪儿技术专家!混迹中间件职场8+年!分享各种Java中间件知识!
#中间件#
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2024 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号