微软专利揭秘:引领AR/VR身体姿态捕捉新突破
发表时间: 2023-09-18 09:12
(映维网Nweon 2023年09月18日)使用虚拟表示准确地表示人类用户的真实世界姿态通常需要关于用户身体部位的位置/方向的相对详细的信息,而这种信息并不总是可用。例如,当头戴式设备用于提供虚拟现实体验时,系统可能仅接收与用户头部和可选手有关的空间信息。在大多数情况下,这不足以准确地重现人类用户的真实姿态。
所以在名为“Pose prediction for articulated object”的专利申请中,微软提出了一种预测铰接对象的姿态的技术。特别地,机器学习模型接收到铰接对象的n个不同关节的空间信息,其中n个关节小于铰接对象的所有关节。
例如在人类用户的情况下,n个关节可以包括人类用户的头部关节和/或一个或两个手腕关节,它们与详细说明用户头部和/或手的参数的空间信息相关联。
机器学习模型已训练为接收铰接对象的n+m个关节的输入空间信息,其中m大于等于1。例如,在初始训练期间,机器学习模型会接收到与铰接对象的几乎所有关节相对应的输入数据。所述n+m个关节可包括所铰接对象的每一个关节。
但在其他示例中,n+m个关节可包括少于铰接对象的所有关节。在训练过程中,提供给机器学习模型的输入数据可能会逐渐被屏蔽。 m个节点中的特定节点对应的输入数据可以用表示掩码节点的预定义值替换,或者干脆省略。
换句话说,机器学习模型训练成基于关于铰接对象的各种可移动部分的位置/方向的逐渐减少的信息来准确预测铰接对象的姿态。
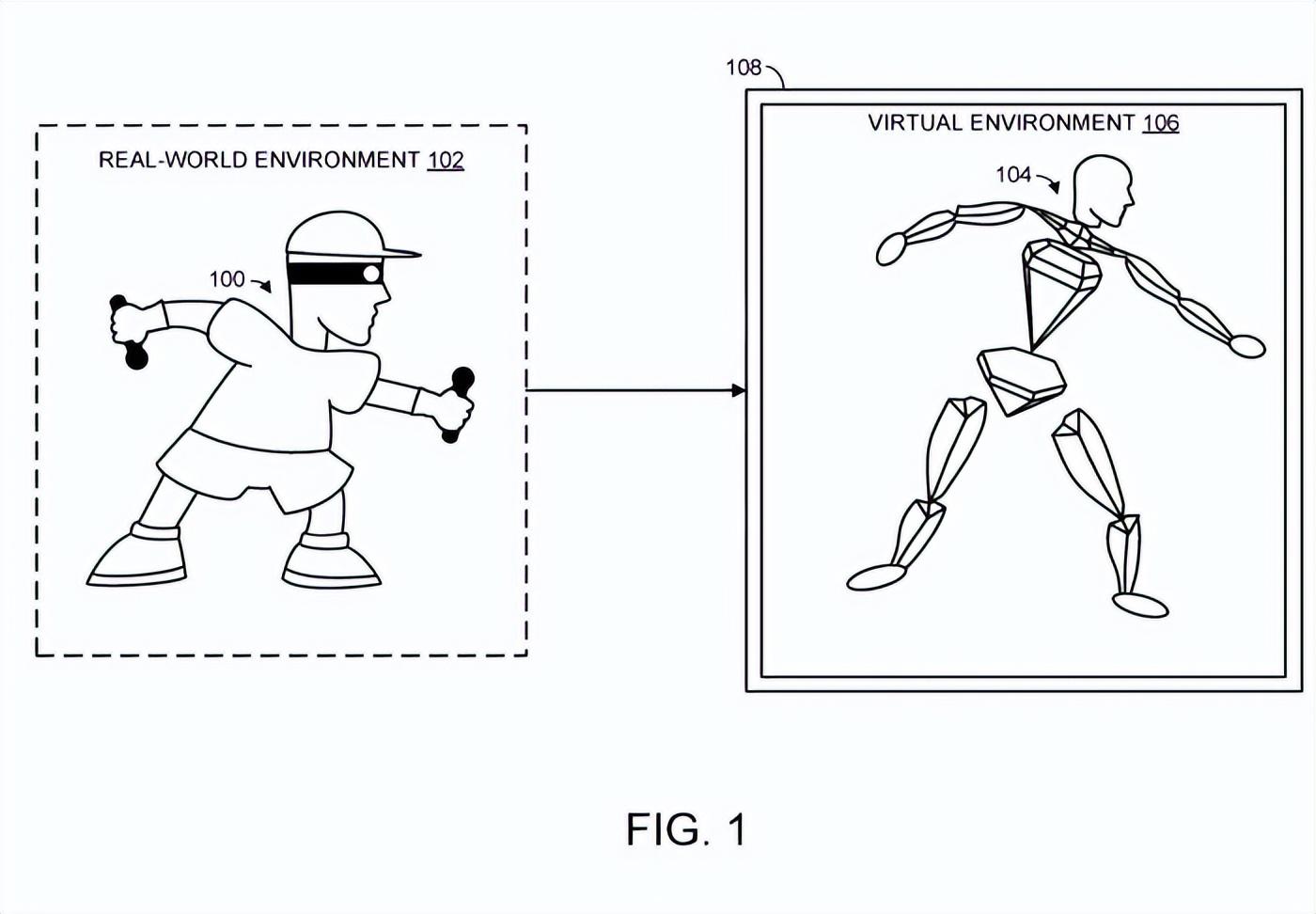
通过这种方式,机器学习模型可以基于稀疏输入在运行时准确地预测铰接对象的姿态。微软指出,这种技术可以有益地允许对诸如人类用户的铰接对象的真实世界姿态的精确再现,而不需要关于铰接对象的每个关节的方向的广泛信息。
换句话说,发明可以通过更准确地再现人类用户的真实世界姿势来提供改进人机交互的技术优势,例如提高虚拟现实体验的沉浸感,和/或提高手势识别系统的准确性。
另外,所述技术可以通过减少必须作为姿态预测过程的输入而收集的数据量,从而在准确地重现人类用户的真实姿态的同时减少计算资源的消耗。
图2示出用于预测铰接对象的姿态的示例方法200。
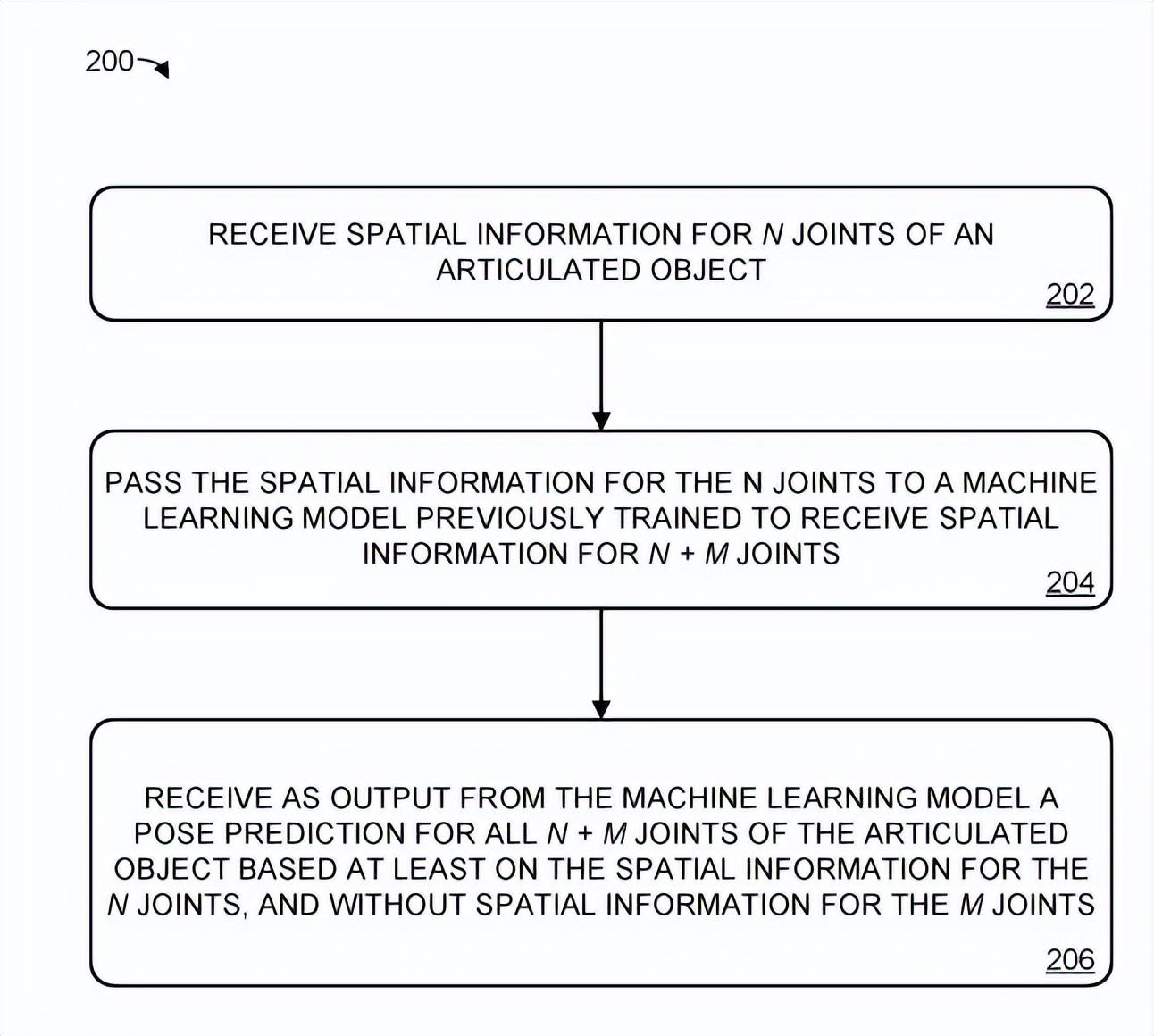
在202处,接收铰接对象的n个关节的空间信息。系统接收到铰接对象的n个关节的空间信息,其中包含的关节少于铰接对象的所有关节。将关节的空间信息表示为所连接的身体部分的六自由度位置和方向,这可用于推断关节的状态。
作为一个示例,所述n个关节可包括人体的头部关节,所述头部关节的空间信息可详细描述人体头部的参数。另外,所述n个关节可包括人体的一个或多个腕关节,所述一个或多个腕关节的空间信息可详细描述人体的一只或多只手的参数。
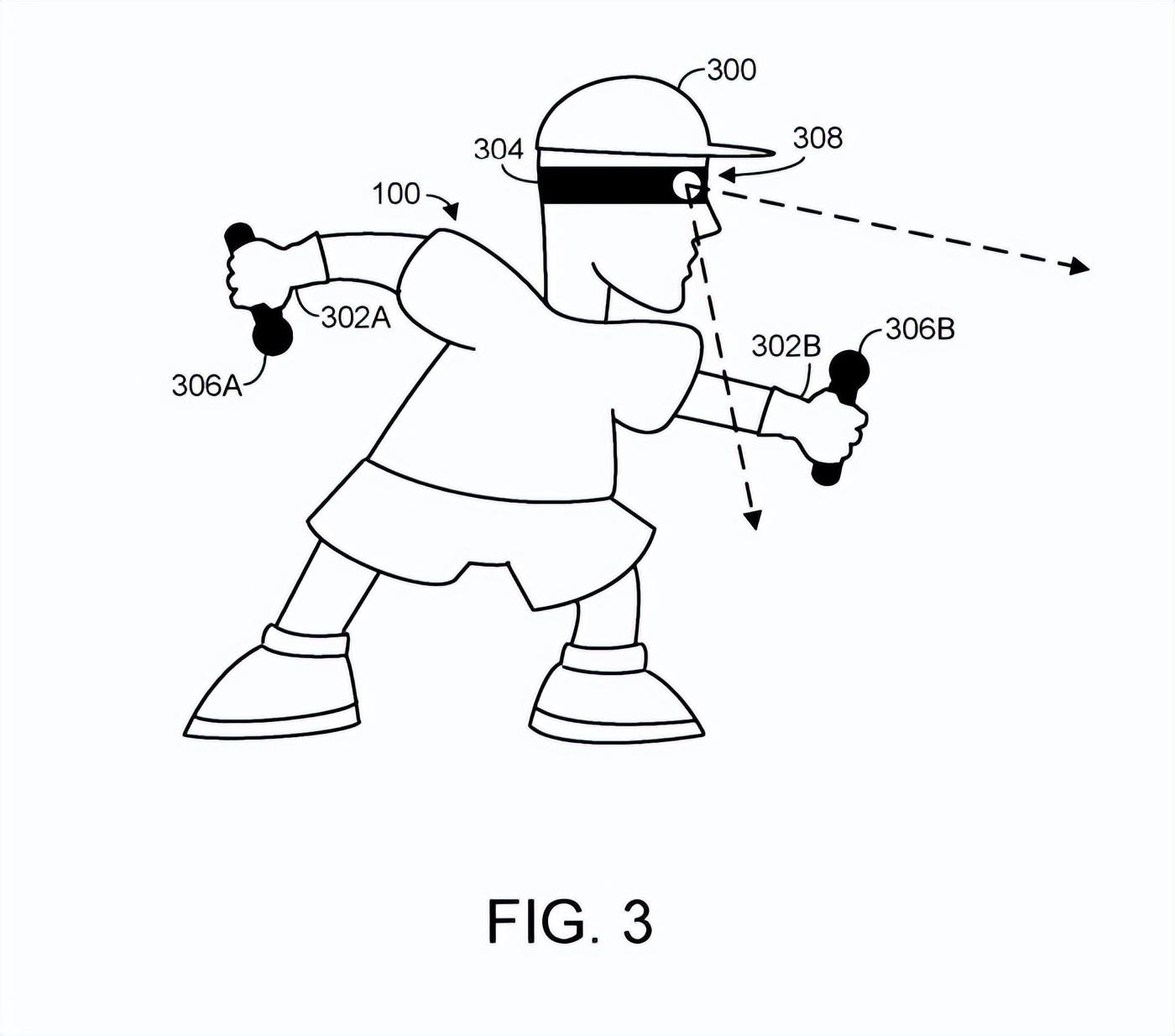
图3显示了人类用户。人类用户有一个头300和两只手302A和302B。计算系统可以接收人类用户的一个或多个关节的空间信息,其可以包括头部和/或手腕关节。
所述铰接对象的n个关节的空间信息可由一个或多个传感器输出的定位数据导出。传感器可以集成到一个或多个由人类用户的相应身体部位持有或佩戴的设备之中。
例如,传感器可以包括一个或多个集成到头戴式显示设备和/或手持控制器中的惯性测量单元。作为另一个例子,传感器可以包括一个或多个摄像头。
图3示意性地说明了不同类型的传感器,其中来自传感器的输出可以包括或可用于导出空间信息。具体地,人类用户在其头部300佩戴头戴式显示设备304。
另外,人类用户手持位置传感器306A和306B,所述位置传感器可配置为检测并向头显 304和/或配置为接收空间信息的另一计算系统报告用户手部的运动。
回到图2,在204中,将n个关节的空间信息传递给先前训练过的机器学习模型,模型接收n+m个关节的空间信息作为输入,其中m>=1。换句话说,机器学习模型接收的关节的空间信息比之前训练的机器学习模型接收的关节要少。
在206中,从机器学习模型接收作为输出的关节对象的姿态预测,所述预测至少基于n个关节的空间信息,并且不包含它们的关节的空间信息。换句话说,即便没有提供m个关节的空间信息,机器学习模型都可以预测关节对象的完整姿态。
这个过程如图4所示,图4显示了一个示例机器学习模型400。
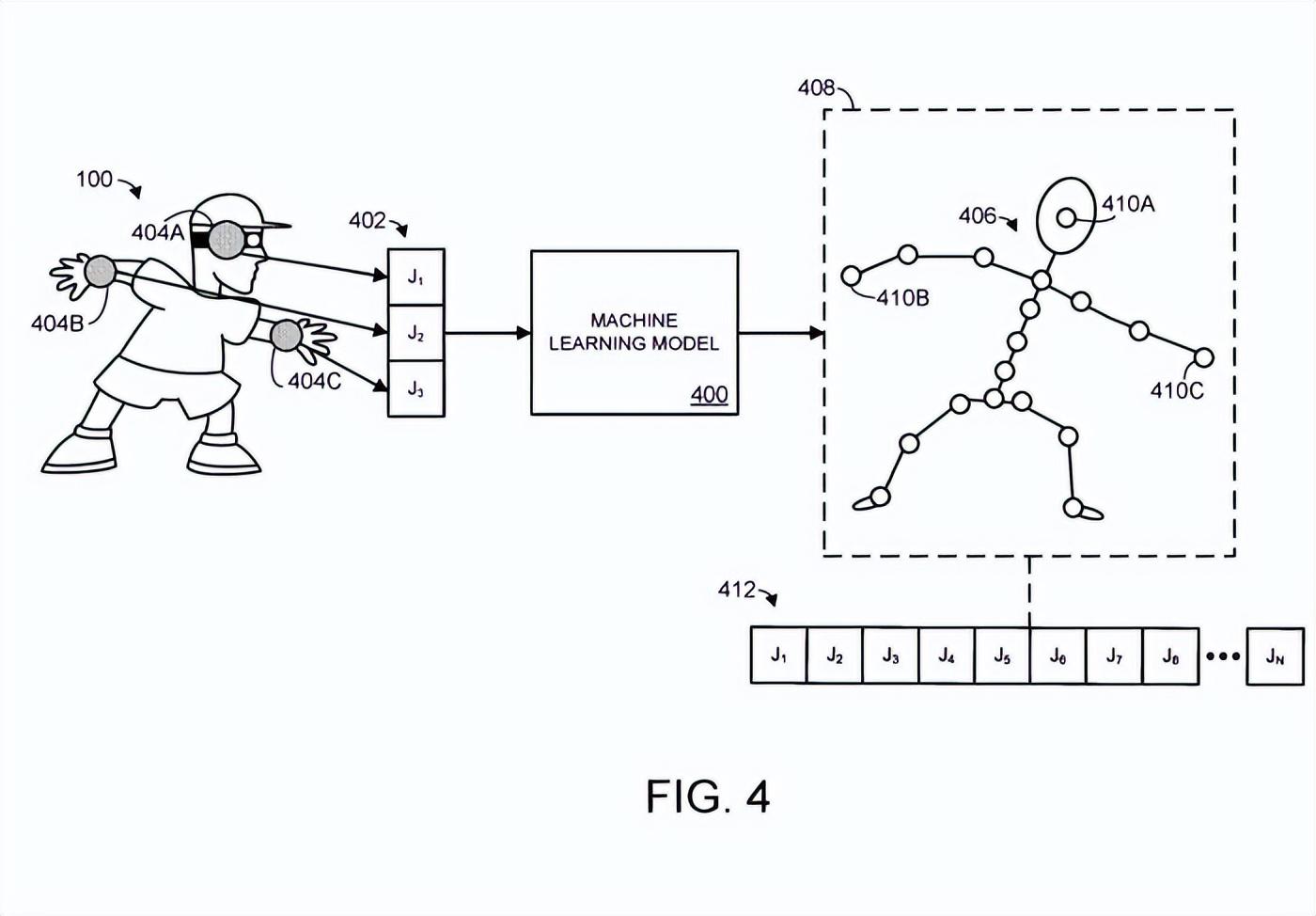
在图4中,机器学习模型接收到空间信息402,对应三个不同的关节J1、J2、J3。关节的空间信息可以采用任何合适的计算机数据的形式,而所述数据指定或可用于导出与关节相连的身体部位的位置和/或方向。
例如,空间信息可以直接指定身体部位的位置和方向,和/或空间信息可以指定关节相对于一个或多个旋转轴的一个或多个旋转。在图4中,关节J1、J2、J3对应于人类用户的头部关节404A和两个手腕关节404B/404C,如图用户身体上叠加的阴影圆圈所示。
在本例中,n个关节包括三个关节,分别对应人体的头部和手腕关节。基于所述输入空间信息402,所述机器学习模型输出所述铰接对象的预测位姿406。
另外,机器学习模型可以输出与虚拟铰接表示的关节相对应的预测空间信息。人类用户可以由具有卡通或非人类比例的虚拟化身Avatar表示。例如,预测的空间信息可能对应于SMPL表示的关节。
换句话说,铰接表示的虚拟表示的关节不必与铰接对象的关节具有1:1的对应关系。因此,机器学习模型预测的空间信息输出可以是针对与铰接对象的n+m个关节不直接对应的关节。例如,虚拟表示可能比铰接对象具有更少的脊柱关节。
机器学习模型可以用任何合适的方式进行训练。在一个实施例中,机器学习模型可能先前使用具有铰接对象的ground truth标签的训练输入数据进行训练。
换句话说,可以为机器学习模型提供铰接对象关节的训练空间信息,并标记为指定空间信息所对应的铰接对象的实际姿态的ground truth标签。
如上所述,可以训练机器学习模型以接收n+m个关节的空间信息作为输入。这包括,在第一次训练迭代中,为机器学习模型提供所有n+m个关节的训练输入数据。在随后的一系列训练迭代中,m个关节的训练输入数据可以逐渐被屏蔽。
例如,在第二次训练迭代中,m个关节中的第一个关节可以被屏蔽,其中训练数据集中关节的空间信息替换为表示被屏蔽关节的预定义值,或者干脆省略。
作为示例。在第三次训练迭代中,m个关节中的第二个关节可以被屏蔽,以此类推,直到m个关节都被屏蔽,并且只向机器学习模型提供了n个关节的空间信息。
这一过程用图5a-5d说明。具体而言,在图5A中,为机器学习模型400提供了一个训练输入数据集。在本实施例中,训练输入数据包括与所述铰接对象的多个不同姿态相对应的空间信息,包括第一姿态502A和第二姿态502B。
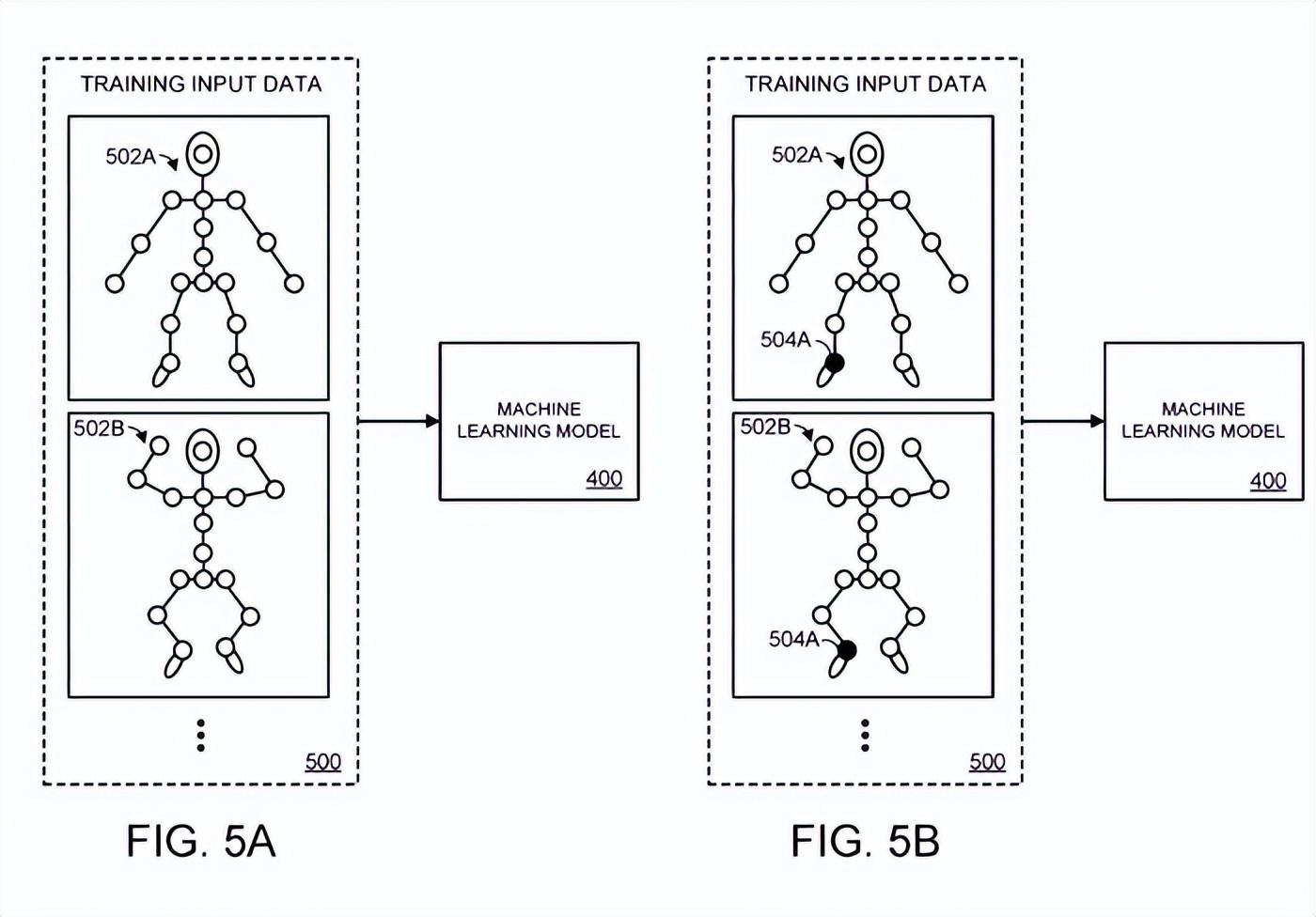
在图5A中,为机器学习模型提供了铰接对象的n+m个关节的空间信息。在人体的简化表示中,每个代表关节的圆圈都使用了白色填充模式来表示这一点。但在图5B中,504A被屏蔽,如图所示,黑色填充图案用于表示接头504A的圆圈。
换句话说,图5A可以表示训练过程的第一次训练迭代,其中向机器学习模型提供了所有n+m个关节的空间信息。图5B可以表示训练过程的第二次训练迭代,其中m个关节中的第一个关节504A被屏蔽。
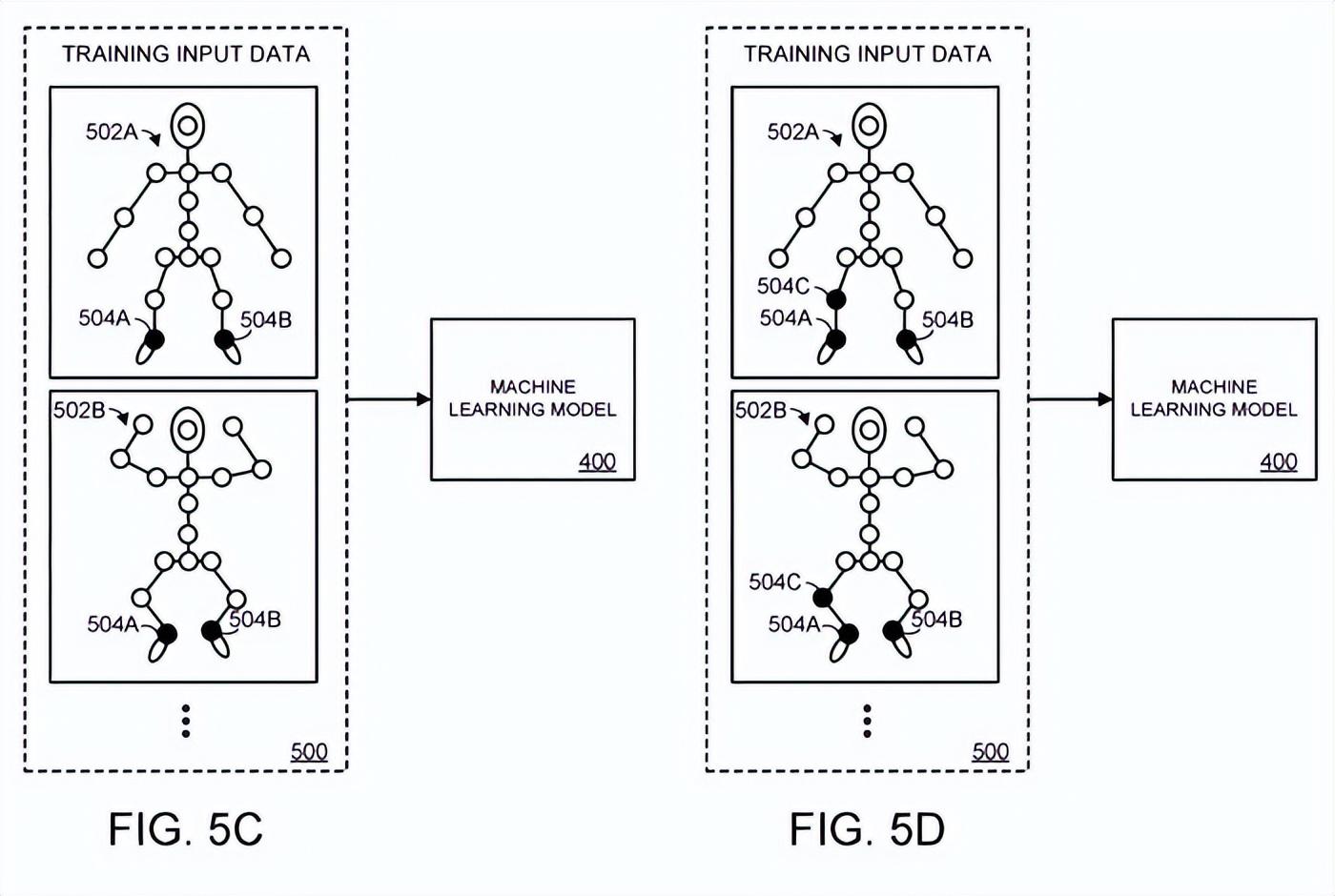
在图5C中,所述铰接表示的m个关节中的第二关节504B被遮挡。同样,在图5D中,m个关节中的第三个关节被遮挡。可以持续进行多次训练迭代,直到m个关节中的每个关节的空间信息被屏蔽,并且只向机器学习模型提供n个关节的空间信息。
以上描述了铰接对象为人体全身的场景。但铰接对象可以采取其他形式。
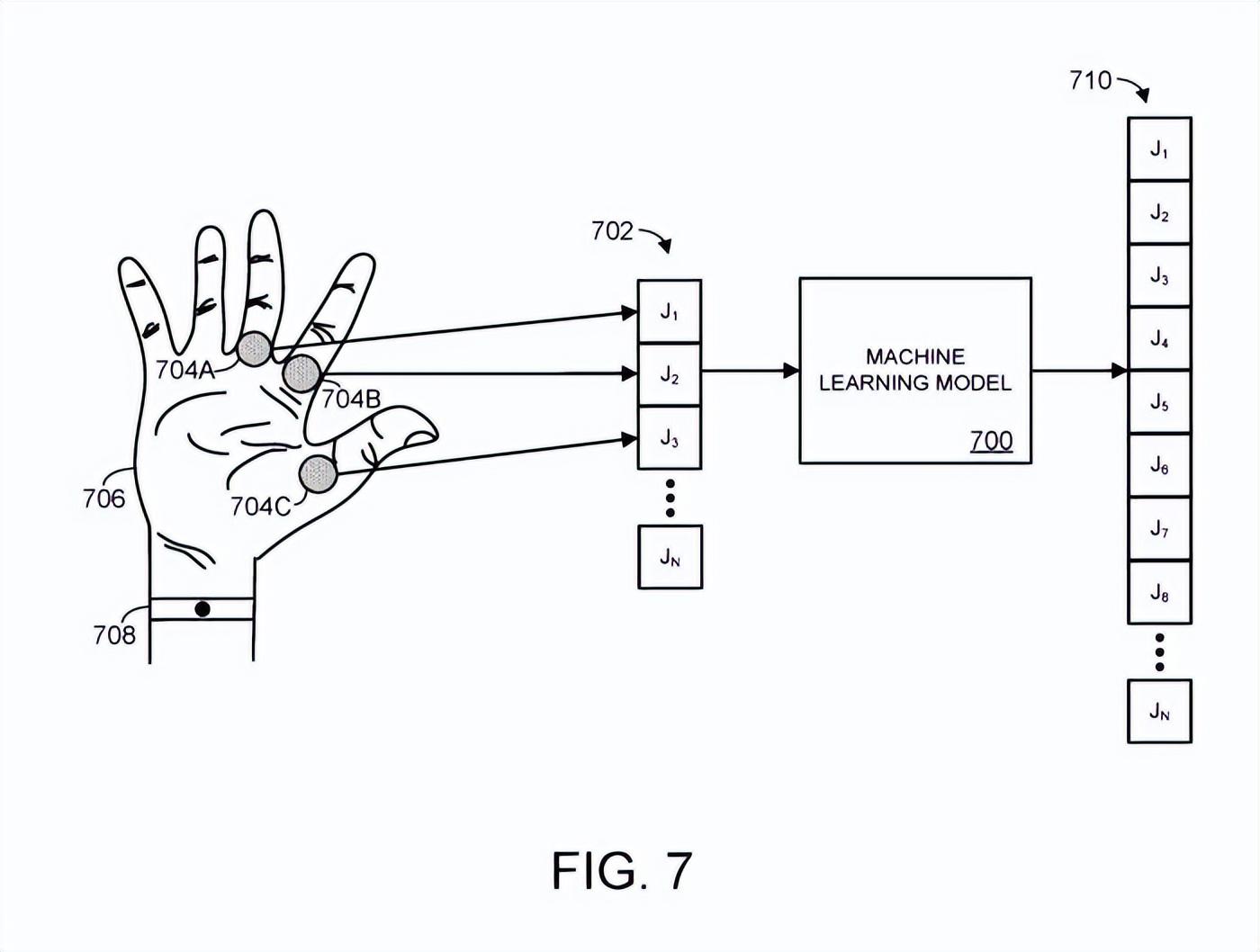
如图7所示,铰接对象是人手,而不是整个人体。具体而言,图7显示了一个示例机器学习模型700。
机器学习模型700接收关节J1、J2和J3的空间信息,它们对应于一个铰接物体的三个关节704A-C,在本例中采用人手706的形式。
具体来说,在这种情况下,n个关节包括人手的一个或多个手指关节。一个或多个手指关节的空间信息详细描述了人手的一个或多个手指或手指段的参数。例如,空间信息可以指定手的手指的位置/方向,和/或应用于手关节的旋转。
可以用任何合适的方法收集关节的空间信息,例如通过位置传感器708。作为一个示例,位置传感器可以采用配置为对人手成像的摄像头形式。作为另一个示例,位置传感器可以包括合适的射频天线,其配置为将人手表面暴露于电磁场,并评估天线处的电磁场阻抗如何受到导电人体皮肤的运动和接近的影响。
基于输入的空间信息702,机器学习模型输出一组预测的空间信息710。空间信息710可构成所述铰接对象的预测位姿。如上所述,这样的空间信息可以表示为铰接对象的身体部位的位置/方向。
相关专利:Microsoft Patent | Pose prediction for articulated object
名为“Pose prediction for articulated object”的微软专利申请最初在2022年6月提交,并在日前由美国专利商标局公布。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号