掌握 Node.js 流(Stream)的全面指南
发表时间: 2020-08-17 09:56
stream(流)是一种抽象的数据结构。就像数组或字符串一样,流是数据的集合。
不同的是,流可以每次输出少量数据,而且它不用存在内存中。
比如,对服务器发起 http 请求的 request/response 对象就是 Stream。
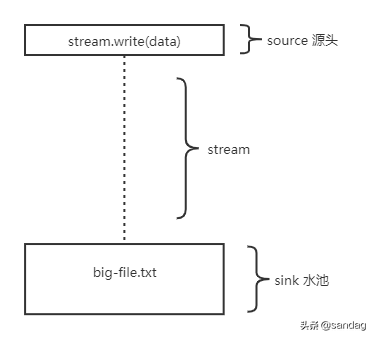
stream 就像是水流,但默认是没有水的。 stream.write 可以让水流中有水,也就是写入数据。
左上角是产生数据的一段,称为 source(源头)。 最下面是得到数据的一段 sink(水池)。 从上向下流动的小圆点是每次写的小数据,称为 chunk(块)。
同学们可能有这样的疑问,流的作用不就是传递数据吗,不用流 node 也可以实现读写操作啊。
是的,但是读写方式是把文件内容全部读入内存,然后再写入文件,小型文件这么处理问题不大。
但是遇到较大的文件,实在承受不住。
而流可以把文件资源拆分成小块,一块一块的运输,资源就像水流一样进行传输,减轻服务器压力。
可能这么描述并不能让大家信服, 我们来做一个试验,看看在读写大文件时有没有必要使用流。
首先创建一个大文件:
我们首先创建一个可写流,向文件里多次写入内容。 最后记得关闭流,得到一个大文件。
// 引入文件模块const fs = require('fs');const stream = fs.createWriteStream('./../big_file.txt');for (let i = 0; i < 1000000; i++) { stream.write(`这是第${i}行内容\n`);}stream.end()console.log('done')我们先使用 fs.readFile 来读取文件内容,看看会发生什么。
const fs = require('fs')const http = require('http')const server = http.createServer()server.on('request', (request, response) => { fs.readFile('./../big_file.txt', (error, data) => { if (error) throw error response.end(data) console.log('done') })})server.listen(8889)console.log(8889)当我们访问 http://localhost:8889 的时候,服务器会异步读取这个大文件。
看起来一切正常,没什么毛病。
但是,我们用任务管理器查看 Node.js 的内存,大概占用 130Mb。
服务器接收 1 次请求,占用 130 Mb;那如果接受 10 次请求,就是占用 1G。 对服务器的内存消耗是很大的。
怎么解决这个问题呢?使用 Stream。
我们来试试用 Stream 改写上面的例子。
创建一个可读流 createReadStream , 再把文件 stream 和 response stream 通过管道 pipe 相连。
const fs = require('fs')const http = require('http')const server = http.createServer()server.on('request', (request, response) => { const stream = fs.createReadStream('./big_file.txt') stream.pipe(response)})server.listen(8888)我们再次查看 node.js 内存占用,基本不会高于 30Mb。
因为每次只传递一小段数据,不会占用很大内存。
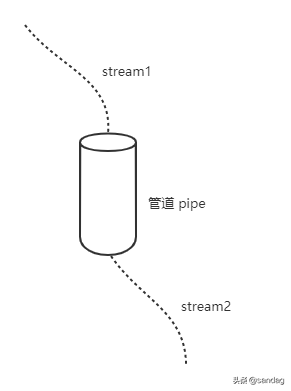
两个流可以用一个管道相连,stream1 的末尾连接上 stream2 的开端。
只要 stream1 有数据,就会流到 stream2。
比如上面的代码:
const stream = fs.createReadStream('./big_file.txt')stream.pipe(response)stream 就是一个文件流,下面的 stream 就是我们的 http 流 response。 本来这两个流是没有关系的,现在我们想把文件流的数据传递给 http 流。 很简单,用 pipe 连接就行啦。
stream1.pipe(stream2)
一个水流可以经过无限个管道,数据流也一样。
有两种写法:
a.pipe(b).pipe(c)// 等价于a.pipe(b)b.pipe(c)管道也可以认为是两个事件的封装
stream1.on('data', (chunk) => { stream2.write(chunk)})stream1.on('end', () => { stream2.end()})了解 Stream 的原型链,可以更容易地记忆 Stream 的 API。
如果 s = fs.createReadStream(path) ,那么 s 的对象层级为:
fs.ReadStreamstream.Readable.prototypestream.Stream.prototypeevents.EventEmitter.prototypeObject.prototype了解了原型链之,我们来看看 Stream 支持的事件和方法。
大概有个印象就好,用到的时候再去查。

一共分为四类
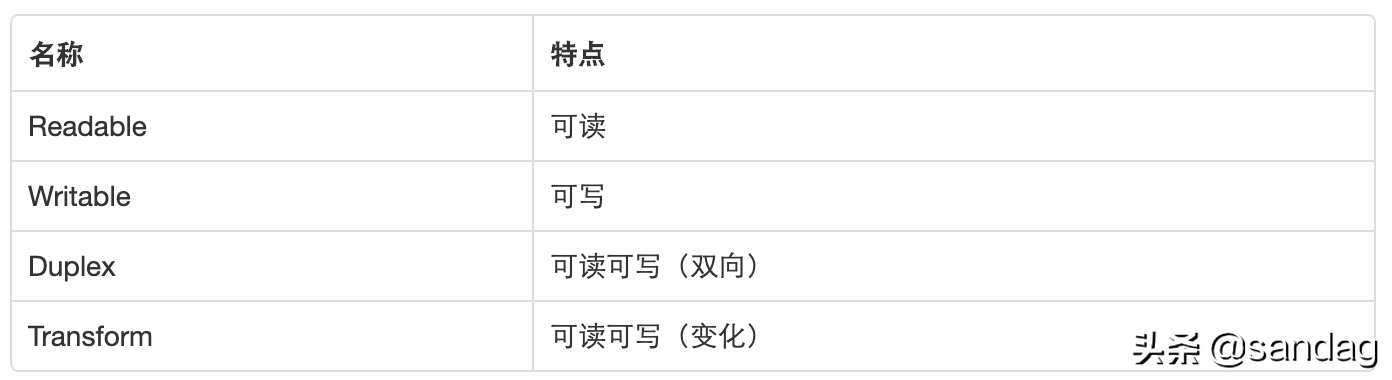
Readable、Writable 都是单向的,其他两个是双向的。
可读、可写好理解,剩下两个有什么区别呢?
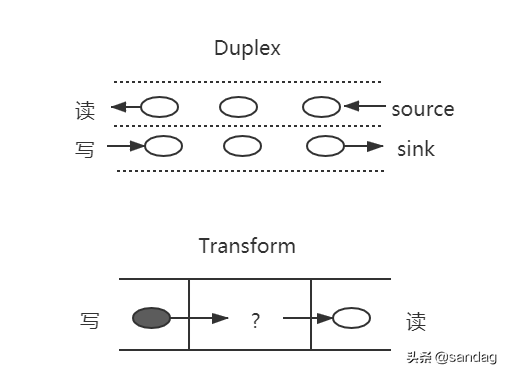
Duplex 可以读写,但是读的内容和写的内容是相互独立的,没有交叉。
而 Transform 是自己写自己读。
比如一个 babel,把es6转换为,我们在左边写入 es6,从右边读取 es5。 就像洗车一样,黑车进去,白车出来。
可读流有两个状态 paused 和 flowing。
可以把可读流看成内容生产者,不发内容时就是静止态,内容恢复发送时就是流动态。
const http = require('http')const fs = require('fs')const server = http.createServer()server,on('request', (request, response) => { // 默认处于 paused 态 const stream = fs.createReadStream('./big_file.txt') stream.pipe(response) stream.pause(); // 暂停 setTimeout(() => { // 恢复 stream.resume() }, 3000)})server.listen(8888);表示可以加点水了,也就是可以继续写入数据了。 我们调用 stream.write(chunk) 的时候,可能会得到 false。
false 的意思是你写太快了,积压数据。
这个时候我们就不能再 write 了,要监听 drain。
等 drain 事件触发了,我们才能继续 write。
光看这些有点难以理解,可以看看 官网上的例子 :
const fs = require('fs');// 将 data 写入文件 1000000 次function writeOneMillionTimes(writer, data) { let i = 1000000; write(); function write() { let ok = true; do { i--; if (i === 0) { // 最后一次写入 writer.write(data); } else { // 在这里判断是不是可以继续写 // ok 为 false 的意思是你写太快了,数据积压 ok = writer.write(data); if (ok === false) { console.log('不能再写了') } } } while (i > 0 && ok); if (i > 0) { // 干涸了,可以继续写入 writer.once('drain', () => { console.log('干涸了') write() }); } }}const write = fs.createWriteStream('./../big_file.txt')writeOneMillionTimes(write, 'hello world')在调用 stream.end() 之后,而且缓冲区数据都已经传给底层系统之后,触发 finish 事件。
我们往文件中写入数据时,不是直接存入硬盘中,而是先放入缓冲区。 当数据到达一定大小后,才会写入硬盘。
下面我们来看看,如何创建自己的流。
按照流的四个类型依次讲解。
const {Writable} = require('stream')const outStream = new Writable({ // 如果别人调用,我们做什么 write(chunk, encoding, callback) { console.log(chunk.toString()) // 进入下一个流程 callback() }})process.stdin.pipe(outStream);保存文件为 writable.js 然后用 node 运行。 不管你输入什么,都会得到相同的结果。
const {Readable} = require('stream')const inStream = new Readable()inStream.push('hello world') // 写入数据inStream.push('hello node')inStream.push(null) // 没有数据了// 将这个可读流,导入到可写流 process.stdout。inStream.pipe(process.stdout)先把所有数据都 push 进 inStream,再使用管道导入到可写流 process.stdout 中。
这样,当我们用 node 运行文件时,我们可以从 inStream 中读取所有数据,并且打印出来。
这种方式非常简单,但是并不高效。
更好的方式是按需 push,当用户需要的时候,我们才读取数据。
这种写法数据是按需供给的,对方调用 read ,我们才会给一次数据。
例如下面这个例子,我们一次 push 一个字符,从字符码 65(代表 A) 开始。
当用户读取时,会持续触发 read ,我们会 push 更多地字符。
当字符全部 push 完毕,我们 push null ,停止 Stream。
const {Readable} = require('stream')const inStream = new Readable({ read(size) { const char = String.fromCharCode(this.currentCharCode++) this.push(char); console.log(`推了${char}`) // 这个时候停止 if (this.currentCharCode > 90) { // Z this.push(null) } }})inStream.currentCharCode = 65 // AinStream.pipe(process.stdout)看完了可读流、可写流, Duplex Stream 就简单多了。
同时实现 write 和 read 方法就好啦。
const {Duplex} = require('stream')const inoutStream = new Duplex({ write(chunk, encoding, callback) { console.log(chunk.toString()) callback() }, read(size) { this.push(String.fromCharCode(this.currentCharCode++)) if (this.currentCharCode > 90) { this.pull(null) } }})inoutStream.currentCharCode = 65;process.stdin.pipe(inoutStream).pipe(process.stdout);对于 Transform Stream,我们实现 transform 方法就好了,它结合了可读、可写两个方法。
这里有一个简单的 transform 例子,会以大写的格式打印任何你键入的字符:
const {Transform} = require('stream')const upperCaseTr = new Transform({ transform(chunk, encoding, callback) { // 1. 读数据 chunk.toString() // 2. 写数据 this.push(xxx) this.push(chunk.toString().toUpperCase()) callback(); }})// 监听用户输入,调用 upperCaseTr// 转化完成后,输出process.stdin.pipe(upperCaseTr) .pipe(process.stdout)比如面试中经常说的优化方案:gzip 压缩。
在 Node.js 中用 4 行代码就可以实现
const fs = require('fs')const zlib = require('zlib')const file = process.argv[2]fs.createReadStream(file) .pipe(zlib.createGzip()) .on('data', () => process.stdout.write(".")) // 打出进度条 .pipe(fs.createWriteStream(file + ".gz"))声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号