图结构算法与实现:数据结构与算法的新篇章
发表时间: 2022-09-19 19:19
注意: 篇幅较长,建议收藏后再仔细阅读!!!!!!!!!!
一.图的定义
二.图的分类
2.1 无向图
2.2. 有向图
2.3.网
三. 图的存储结构
3.1. 图的存储结构讨论
3.2. 邻接矩阵
3.3. 邻接表
3.4. Java Mission Control(JMC):可持续在线的监控工具
四. 图的遍历
4.1. 深度优先遍历DFS
4.2. 广度优先遍历BFS
五. 图的应用
5.1. 拓扑排序
5.2. 最小生成树
5.3 最短路径
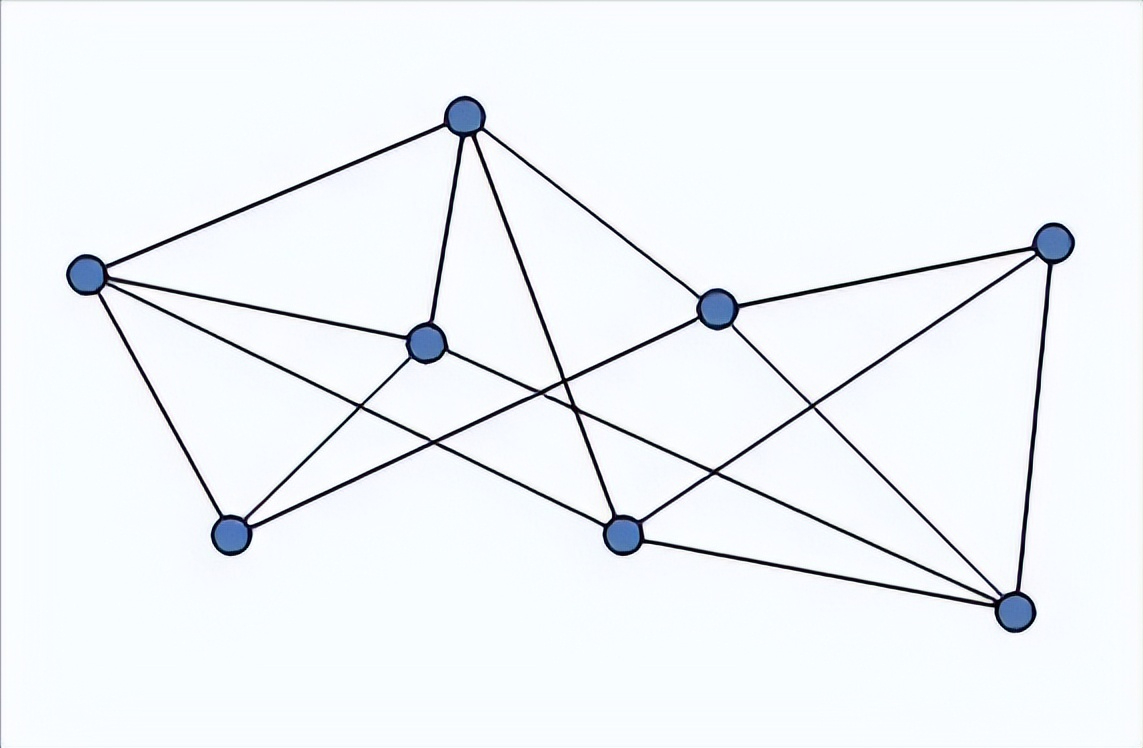
图论〔Graph Theory〕是数学的一个分支。它以图为研究对象。图论中的图是由若干给定的点及连接两点的线所构成的图形,这种图形通常用来描述某些事物之间的某种特定关系,用点代表事物,用连接两点的线表示相应两个事物间具有这种关系。
图论是一种表示 "多对多" 的关系
图是由顶点和边组成的:(可以无边,但至少包含一个顶点)
图可以分为有向图和无向图,在图中:
图可以分为有权图和无权图:
图又可以分为连通图和非连通图:
图中的顶点有度的概念:
术语 | 含义 |
顶点 | 图中的某个结点 |
边 | 顶点之间连线 |
相邻顶点 | 由同一条边连接在一起的顶点 |
度 | 一个顶点的相邻顶点个数 |
简单路径 | 由一个顶点到另一个顶点的路线,且没有重复经过顶点 |
回路 | 第一个顶点和最后一个顶点的相同的路径 |
无向图 | 图中所有的边都没有方向 |
有向图 | 图中所有的边都有方向 |
无权图 | 图中的边没有权重值 |
有权图 | 图中的边带有一定的权重值 |
我们再来看个图的例子,借此来更详细地介绍一下每个术语的含义,如图
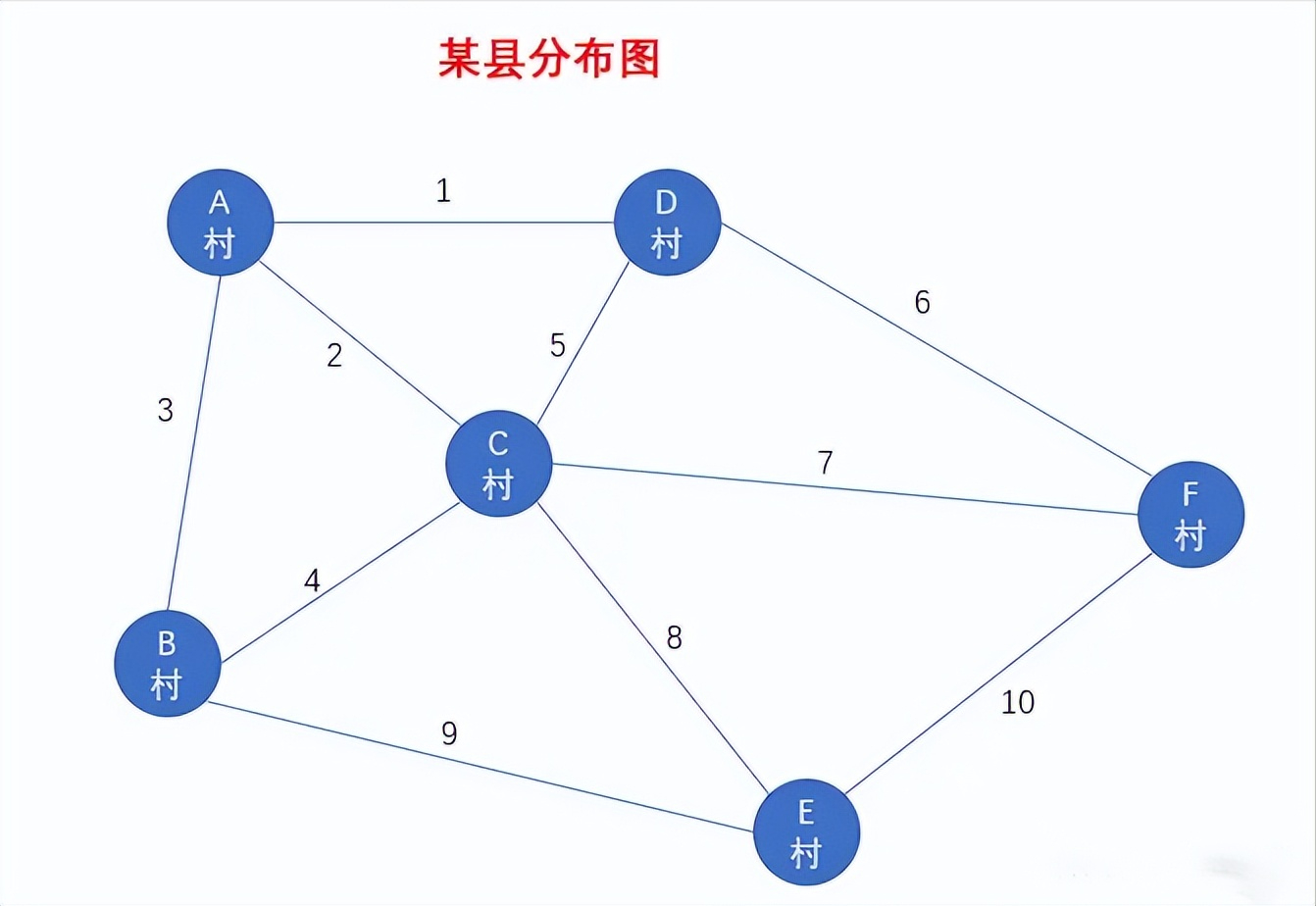
该图为某某县的村落分布图,我们可以把其看成是一个图结构,其中每个村看成是一个顶点,每两个村之间可能通了一条路方便来往,例如 A村和D村之间就有一条路线1,我们称之为边
邻村表示只需要经过一条边就可以到达另一个村,那么我们就说这两个村互为邻村,也可以称它们互为相邻顶点。每个村都会有一个甚至多个邻村,例如D村的邻村有 A村 、C村 、F村,此时我们就说顶点D(D村)的度为3
假设有一天,你要从A村前往E村,你选择的路线是这样的,如图所示
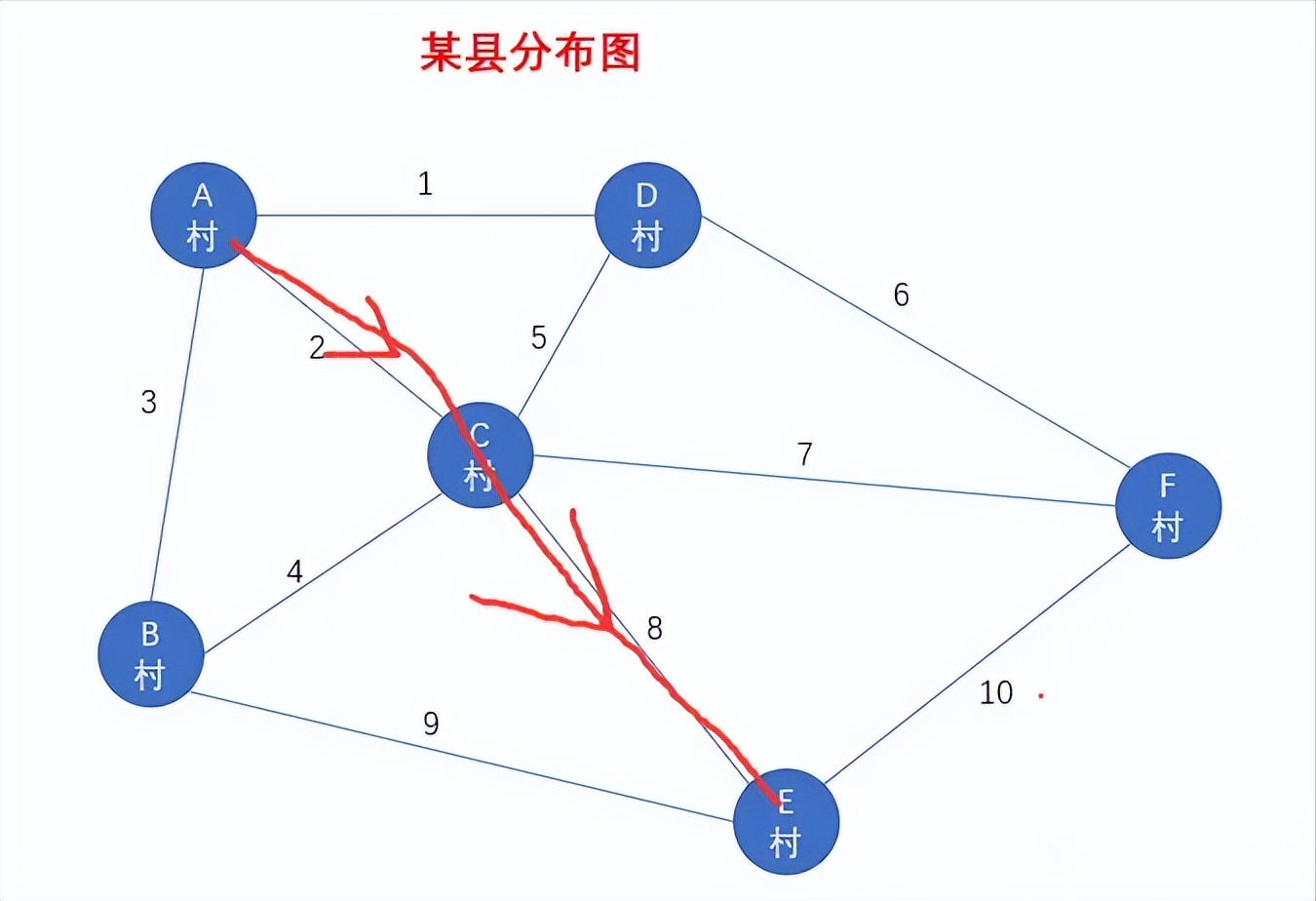
途中我们经过了 顶点A 、顶点C 、顶点E ,没有重复经过某个顶点,因此我们称这条路线为简单路径
此时,若你选择的路线是这样的,如图所示
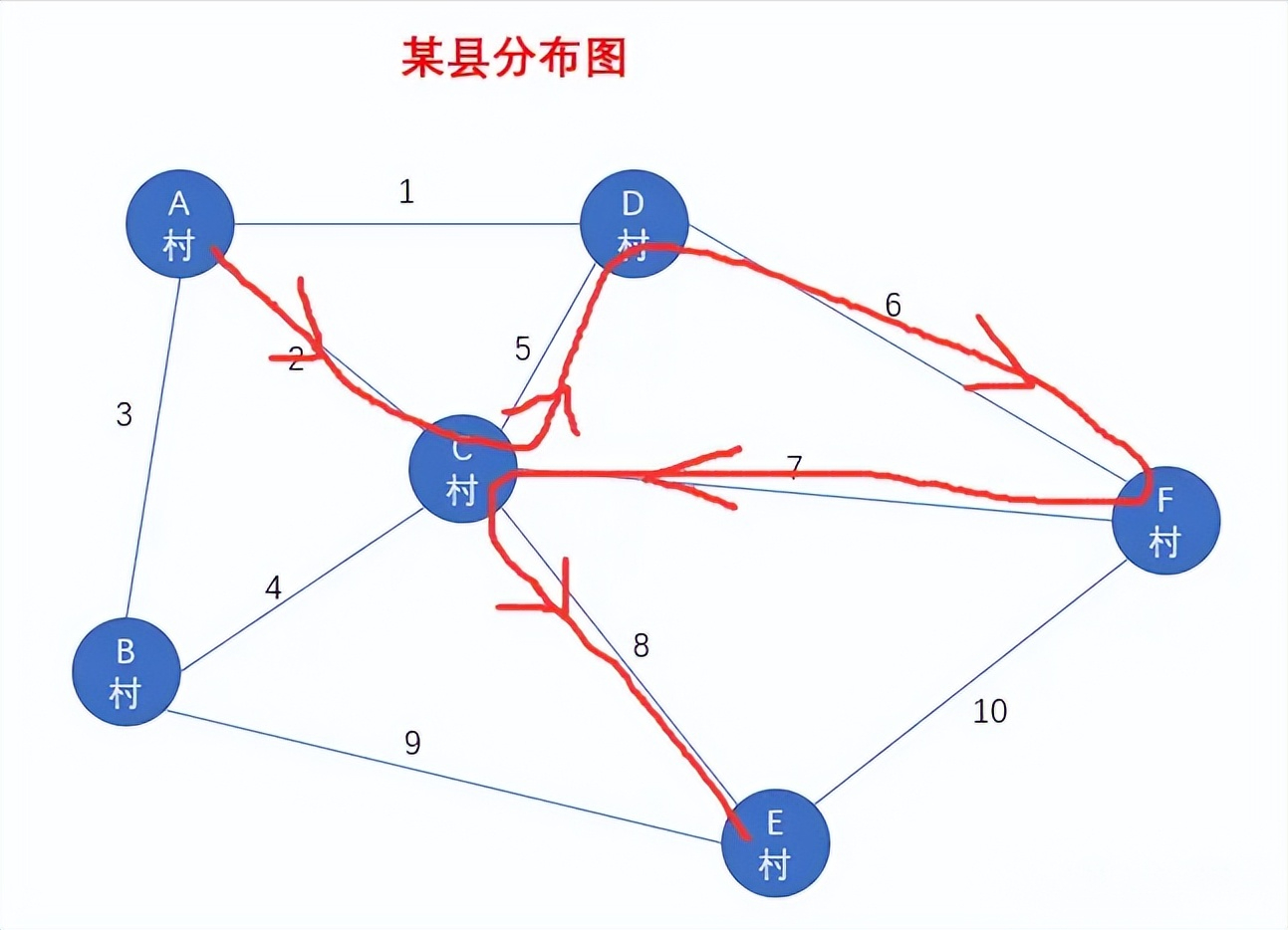
途中经过两次 顶点C ,此时我们就不能称这条路线为简单路径了
到了晚上,你准备起身回家,但选择经过B村再回家,那么此时你一整天的路线是这样的,如图所示

因为你当前的出发点和结束点都是A村(顶点A),因此这样的路线我们称之为回路
第二天,你接到一个任务,尽快将一个包裹送往E村,为了节省时间,你查阅资料获取到了各条路的长度,如图所示
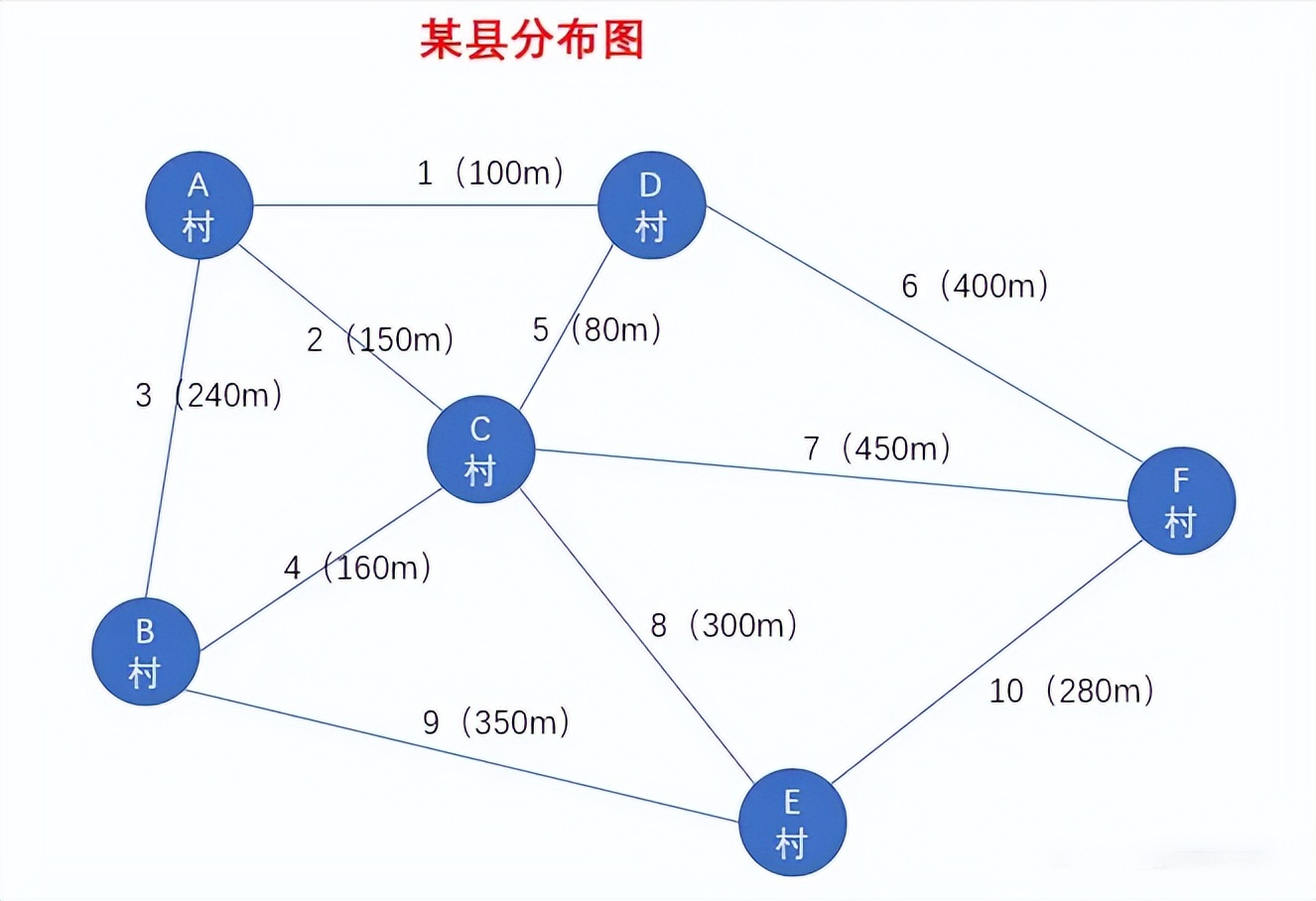
此时的图结构上每条边就带上了权重值,我们称这个图为有权图
通过计算,最后选择了 A村 -> C村 -> E村 这条路线,等到包裹送到E村以后,你正准备原路返回,但发现来时的路都是单向的,现在不允许走这条路回去了,于是你又查阅资料,查看这个县各条路的方向情况,结果如图所示

此时的图结构上每条边都有一定的方向,我们称这个图为有向图
最后你选择了 E村 -> B村 -> A村 这条路线成功回到了家

对称矩阵:就是n阶矩阵满足a[i][j]=a[j][i](0<=i,j<=n)。即从矩阵的左上角到右下角的主对角线为轴,右上角的源与左下角相对应的元都是相等的。
根据这个矩阵,我们可以很容易地知道图中的信息。
对于上面的无向图,二维对称矩阵似乎浪费了一半的空间。若是存放有向图,会更大程度利用起来空间
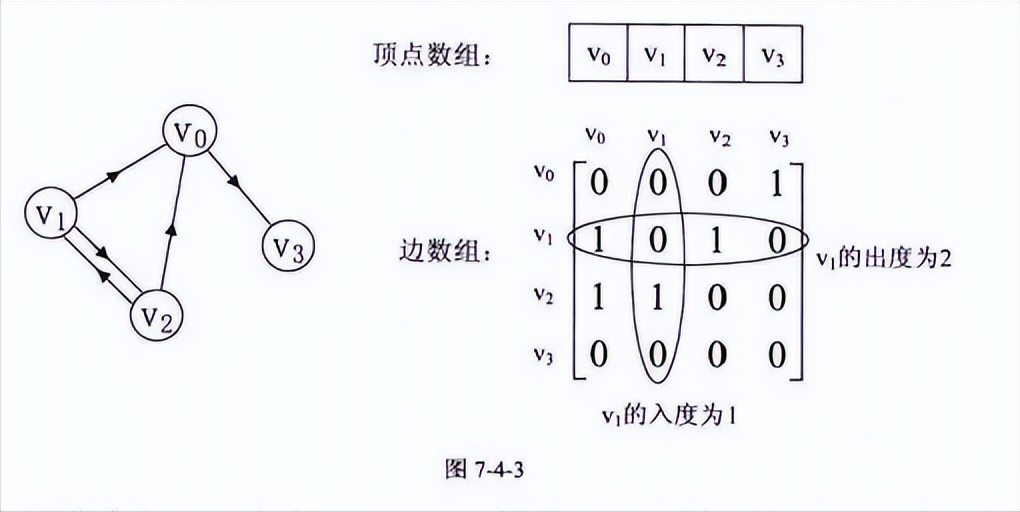
其中顶点数组是一样的和无向图,弧数组也是一个矩阵,但因为是有向图,所以这个矩阵并不对称:例如v1->v0有弧,arc[1][0]=1,而v0到v1没有弧,所以arc[0][1]=0。
另外有向图,要考虑入度和出度,顶点v1的入度为1,正好是第v1列的各数之和,顶点v1的出度为2,正好是第v2行的各数之和
每条边上带有权的有向图就叫做网
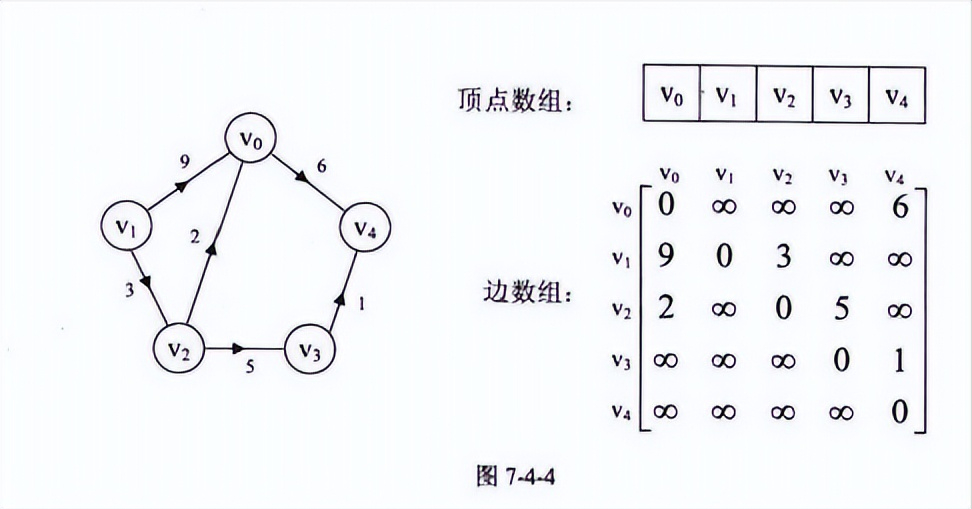
这里‘∞’表示一个计算机允许的,大于所有边上权值得值
3-1图
图的存储结构相较线性表与树来说就更加复杂了。首先,我们口头上说的“顶点的位置”或“邻接点的位置”只是一个相对的概念。其实从图的逻辑结构定义来看,图上任何一个顶点都可被看成是第一个顶点,任一顶点的邻接点之间也不存在次序关系。比如上面的的3-1四张图,仔细观察发现,它们其实是同一个图,只不过顶点的位置不同,就造成了表象上不太一样的感觉。
也正由于图的结构比较复杂,任意两个顶点之间都可能存在联系,因此无法以数据元素在内存中的物理位置来表示元素之间的关系,也就是说,图不可能用简单的顺序存储结构来表示。而多重链表的方式,即以一个数据域和多个指针域组成的结点表示图中的一个顶点,尽管可以实现图结构,但其实在树中,我们也已经讨论过,这是有问题的。如果各个顶点的度数相差很大,按度数最大的顶点设计结点结构会造成很多存储单元的浪费,而若按每个顶点自己的度数设计不同的顶点结构,又带来操作的不便。因此,对于图来说,如何对它实现物理存储是个难题,不过我们的前辈们已经解决了,现在我们来看前辈们提供的五种不同的存储结构。
考虑到图是由顶点和边或弧两部分组成。合在一起比较困难,那就很自然地考虑到分两个结构来分别存储。顶点不分大小、主次,所以用一个一维数组来存储是很不错的选择。而边或弧由于是顶点与顶点之间的关系,一维搞不定,那就考虑用一个二维数组来存储。于是我们的邻接矩阵的方案就诞生了。
图的邻接矩阵(Adjacency Matrix)存储方式是用两个数组来表示图。一个一维数组存储图中顶点信息,一个二维数组(称为邻接矩阵)存储图中的边或弧的信息。
设图G有n个顶点,则邻接矩阵是一个n×n的方阵,定义为:
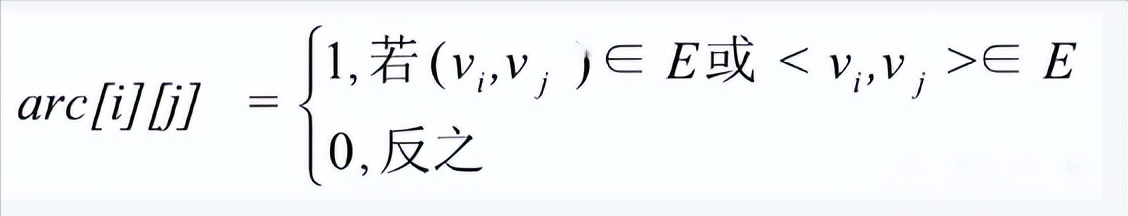
图3-2-1
我们来看一个实例,下面图3-2-2的左图就是一个无向图。
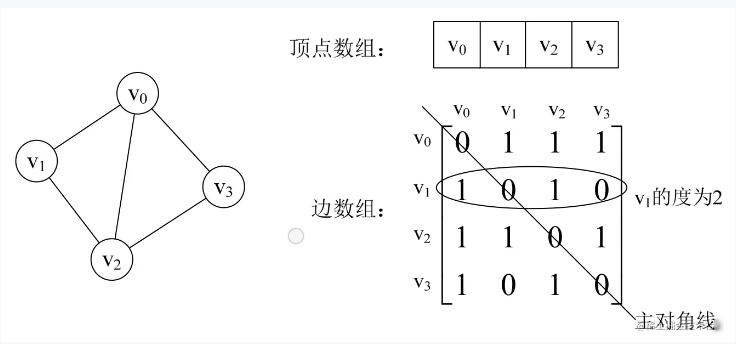
图3-2-2
我们可以设置两个数组,顶点数组为vertex[4]={v0, v1, v2, v3},边数组arc[4][4]为上图图3-2-2右图这样的一个矩阵。简单解释一下,对于矩阵的主对角线的值,即arc[0][0]、arc[1][1]、arc[2][2]、arc[3][3],全为0是因为不存在顶点到自身的边,比如v0到v0。arc[0][1]=1是因为v0到v1的边存在,而arc[1][3]=0是因为v1到v3的边不存在。并且由于是无向图,v1到v3的边不存在,意味着v3到v1的边也不存在。所以无向图的边数组是一个对称矩阵。
所谓对称矩阵就是n阶矩阵的元满足aij=aji,(0≤i,j≤n)。即从矩阵的左上角到右下角的主对角线为轴,右上角的元与左下角相对应的元全都是相等的。
有了这个矩阵,我们就可以很容易地知道图中的信息。
1.我们要判定任意两顶点是否有边无边就非常容易了。
2.我们要知道某个顶点的度,其实就是这个顶点vi在邻接矩阵中第i行(或第i列)的元素之和。比如顶点v1的度就是1+0+1+0=2。
3.求顶点vi的所有邻接点就是将矩阵中第i行元素扫描一遍,arc[i][j]为1就是邻接点。
我们再来看一个有向图样例,如下图3-2-3所示的左图。
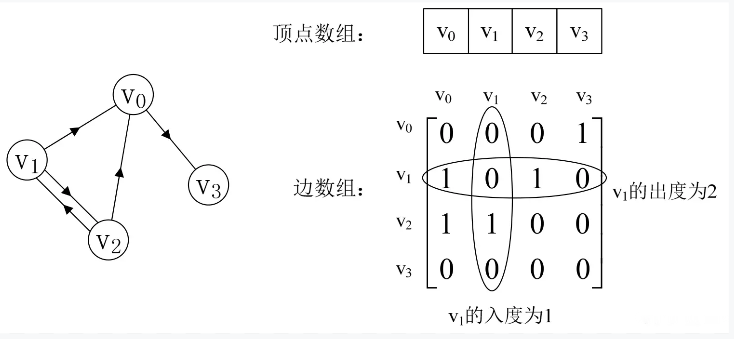
图3-2-3
顶点数组为vertex[4]={v0, v1, v2, v3},弧数组arc[4][4]为图3-2-3右图这样的一个矩阵。主对角线上数值依然为0。但因为是有向图,所以此矩阵并不对称,比如由v1到v0有弧,得到arc[1][0]=1,而v0到v1没有弧,因此arc[0][1]=0。
有向图讲究入度与出度,顶点v1的入度为1,正好是第v1列各数之和。顶点v1的出度为2,即第v1行的各数之和。
与无向图同样的办法,判断顶点vi到vj是否存在弧,只需要查找矩阵中arc[i][j]是否为1即可。要求vi的所有邻接点就是将矩阵第i行元素扫描一遍,查找arc[i][j]为1的顶点。
在图的术语中,我们提到了网的概念,也就是每条边上带有权的图叫做网。那么这些权值就需要存下来,如何处理这个矩阵来适应这个需求呢?我们有办法。
设图G是网图,有n个顶点,则邻接矩阵是一个n×n的方阵,定义为:

这里wij表示(vi,vj)或<vi,vj>上的权值。∞表示一个计算机允许的、大于所有边上权值的值,也就是一个不可能的极限值。有同学会问,为什么不是0呢?原因在于权值wij大多数情况下是正值,但个别时候可能就是0,甚至有可能是负值。因此必须要用一个不可能的值来代表不存在。如下图3-2-4左图就是一个有向网图,右图就是它的邻接矩阵。
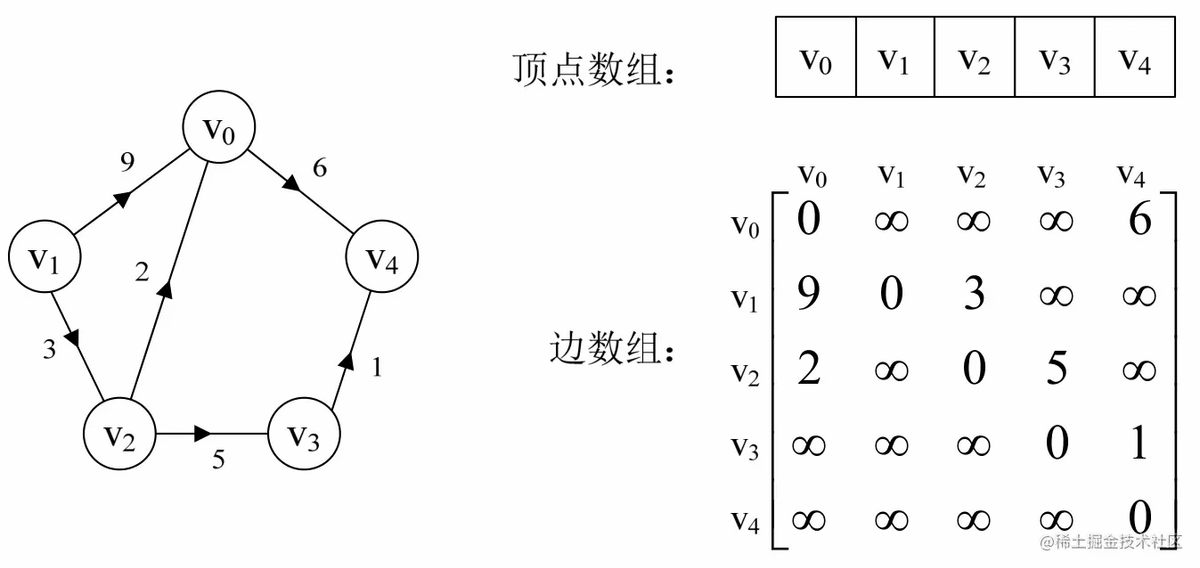
图3-2-4
public class G2 { public static void main(String[] args) {//1、无向图//定点数组vertex String[] v1 = new String[]{"V0", "V1", "V2", "V3"};//矩阵表示边的关系edge 其中1表示两个顶点之间存在关系,0表示无关,不存在顶点间的边。 int[][] e1 = new int[][]{ {0, 1, 1, 1}, {1, 0, 1, 0}, {1, 1, 0, 1}, {1, 0, 1, 0} }; System.out.println("输出无向图:"); for (int i = 0; i < v1.length; i++) { System.out.print(v1[i] + "\t"); } System.out.println(); for (int i = 0; i < v1.length; i++) { for (int j = 0; j < v1.length; j++) { System.out.print(e1[i][j] + "\t"); } System.out.println(); } System.out.println("--------------------");//2、有向图 String[] v2 = new String[]{"V0", "V1", "V2", "V3"}; int[][] e2 = new int[][]{ {0, 0, 0, 1}, {1, 0, 1, 0},//V1的出度为2 {1, 1, 0, 0},//V2的出度为2 {0, 0, 0, 0}//V1的入度为1 }; System.out.println("输出有向图:"); for (int i = 0; i < v2.length; i++) { System.out.print(v2[i] + "\t"); } System.out.println(); for (int i = 0; i < v2.length; i++) { for (int j = 0; j < v2.length; j++) { System.out.print(e2[i][j] + "\t"); } System.out.println(); } System.out.println("--------------------");//3、网,每条边上带有权的图就叫做网 String[] v3 = new String[]{"V0", "V1", "V2", "V3", "V4"};//m表示不可达 int m = 65535; int[][] e3 = new int[][]{ {0, m, m, m, 6}, {9, 0, 3, m, m}, {2, m, 0, 5, m}, {m, m, m, 0, 1}, {m, m, m, m, 0} }; System.out.println("输出网:"); for (int i = 0; i < v3.length; i++) { System.out.print(v3[i] + "\t"); } System.out.println(); for (int i = 0; i < v3.length; i++) { for (int j = 0; j < v3.length; j++) { System.out.print(e3[i][j] + "\t"); } System.out.println(); } }}代码中的图跟上面说的图一一对应,运行结果如下:
输出无向图:V0 V1 V2 V30 1 1 11 0 1 01 1 0 11 0 1 0--------------------输出有向图:V0 V1 V2 V30 0 0 11 0 1 01 1 0 00 0 0 0--------------------输出网:V0 V1 V2 V3 V40 65535 65535 65535 69 0 3 65535 655352 65535 0 5 6553565535 65535 65535 0 165535 65535 65535 65535 0以下图无向图为例,创建邻接表如图。
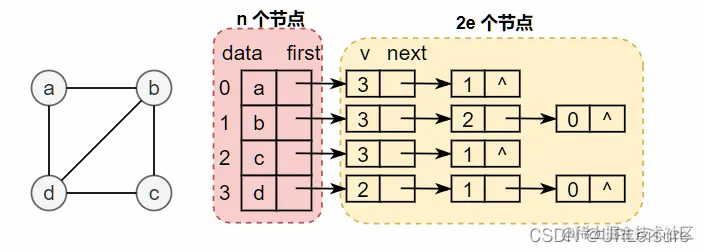
以下图有向图为例,创建邻接表如图。
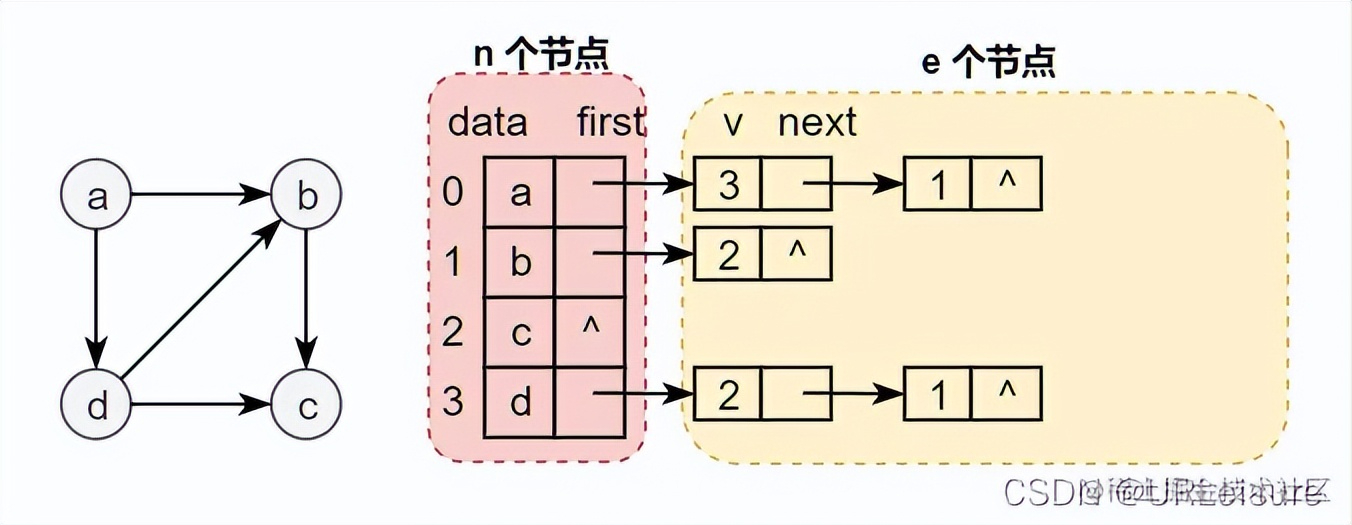
只看出度:
以下图有向图为例,创建逆邻接表如图。
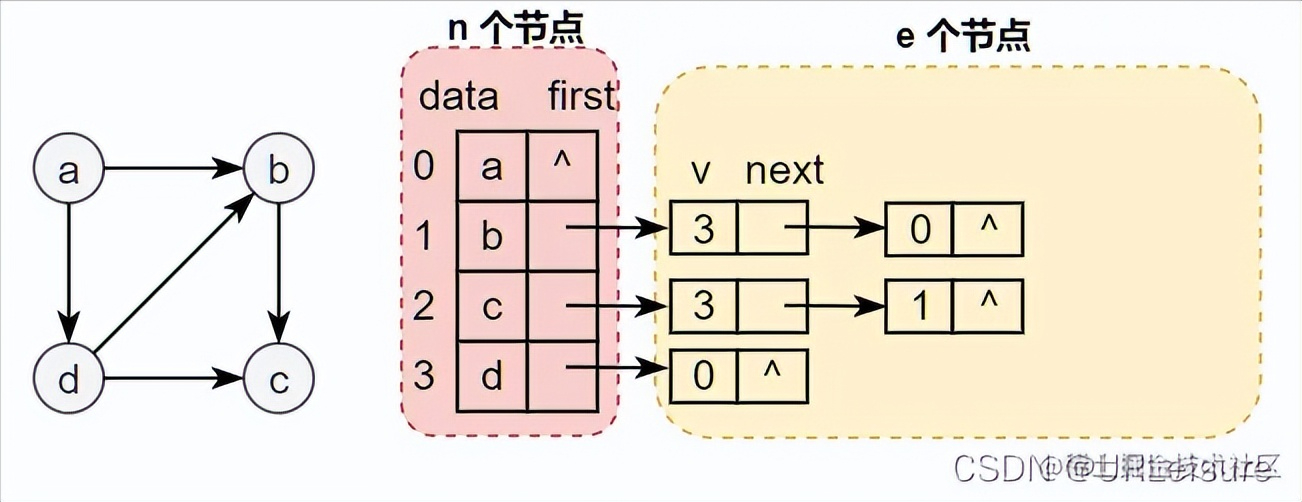
1). 解释
逆邻接表是按照入度建表。
2). 特点
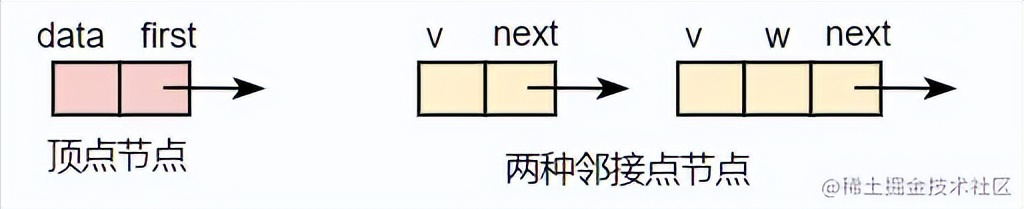
算法步骤:
public static void createGraph(AlGraph g) { g.vexnum = sc.nextInt(); g.edgenum = sc.nextInt(); for (int i = 0; i < g.vexnum; i++) { g.vex[i] = new VexNode(); g.vex[i].data = sc.next(); g.vex[i].first = null; } String u, v; while (g.edgenum-- > 0) { u = sc.next(); v = sc.next(); int i = locateVex(g, u); int j = locateVex(g, v); if (i != -1 && j != -1) { insertEdge(g, i, j); } else { System.out.println("错误"); g.edgenum++; } } }java代码如下(示例):
import java.util.Scanner;public class A { private static final int MaxVnum = 100; private static Scanner sc = new Scanner(System.in); public static class AdjNode { int v; AdjNode next; } public static class VexNode { String data; AdjNode first; } public static class AlGraph { VexNode vex[] = new VexNode[MaxVnum]; int vexnum, edgenum; } public static int locateVex(AlGraph g, String x) { for (int i = 0; i < g.vexnum; i++) { if (g.vex[i].data.equals(x)) { return i; } } return -1; } public static void insertEdge(AlGraph g, int i, int j) { AdjNode s = new AdjNode(); s.v = j; s.next = g.vex[i].first; g.vex[i].first = s; } public static void createGraph(AlGraph g) { g.vexnum = sc.nextInt(); g.edgenum = sc.nextInt(); for (int i = 0; i < g.vexnum; i++) { g.vex[i] = new VexNode(); g.vex[i].data = sc.next(); g.vex[i].first = null; } String u, v; while (g.edgenum-- > 0) { u = sc.next(); v = sc.next(); int i = locateVex(g, u); int j = locateVex(g, v); if (i != -1 && j != -1) { insertEdge(g, i, j); } else { System.out.println("错误"); g.edgenum++; } } } public static void print(AlGraph g) { for (int i = 0; i < g.vexnum; i++) { System.out.print(g.vex[i].data); AdjNode t = g.vex[i].first; while (t != null) { System.out.print("->[" + t.v + "]"); t = t.next; } System.out.println(); } } public static void main(String[] args) { AlGraph g = new AlGraph(); createGraph(g); print(g); }}/*4 5a b c da ba db cd bd c*/思路:
主要思路是从图中一个未访问的顶点 V 开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底...,不断递归重复此过程,直到所有的顶点都遍历完成,它的特点是不撞南墙不回头,先走完一条路,再换一条路继续走。
树是图的一种特例(连通无环的图就是树),接下来我们来看看树用深度优先遍历该怎么遍历。
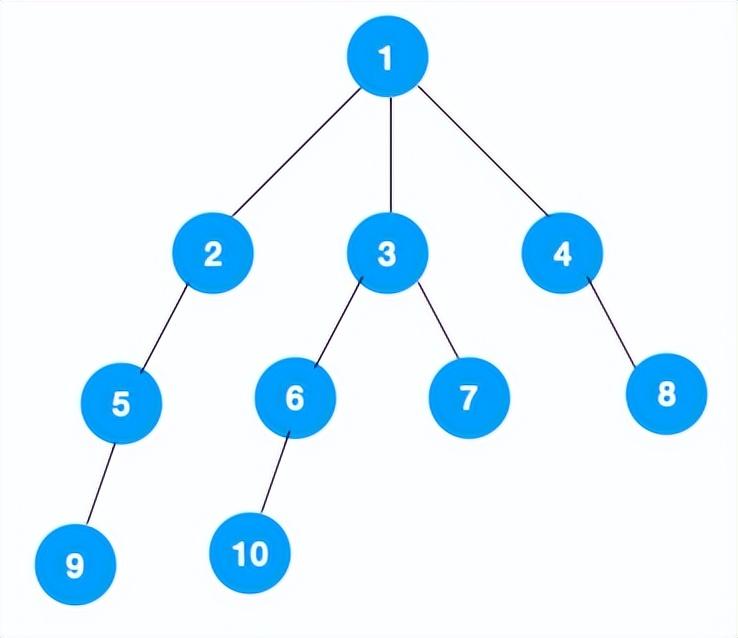
1、我们从根节点 1 开始遍历,它相邻的节点有 2,3,4,先遍历节点 2,再遍历 2 的子节点 5,然后再遍历 5 的子节点 9。
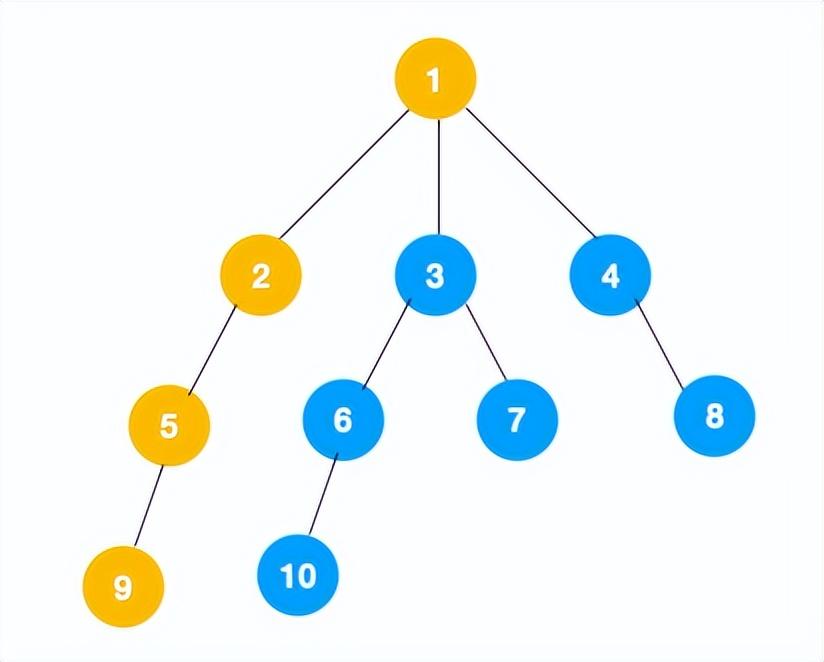
2、上图中一条路已经走到底了(9是叶子节点,再无可遍历的节点),此时就从 9 回退到上一个节点 5,看下节点 5 是否还有除 9 以外的节点,没有继续回退到 2,2 也没有除 5 以外的节点,回退到 1,1 有除 2 以外的节点 3,所以从节点 3 开始进行深度优先遍历,如下:
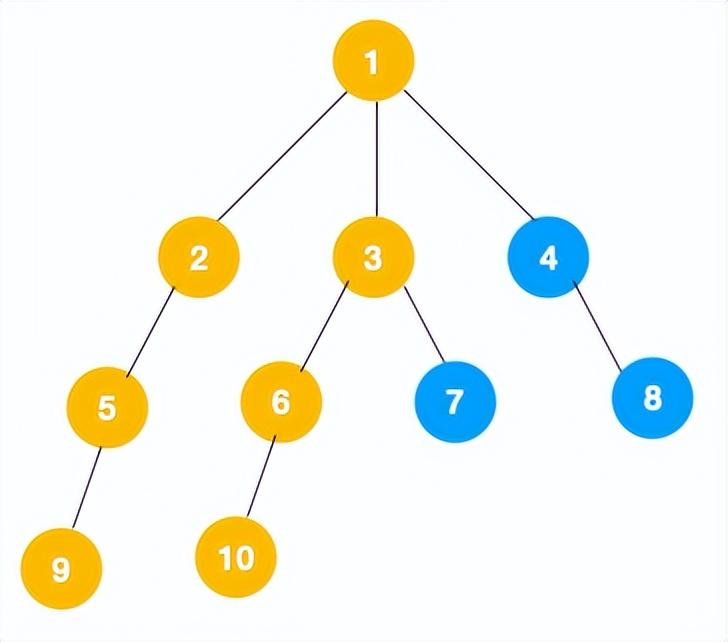
3、同理从 10 开始往上回溯到 6, 6 没有除 10 以外的子节点,再往上回溯,发现 3 有除 6 以外的子点 7,所以此时会遍历 7。
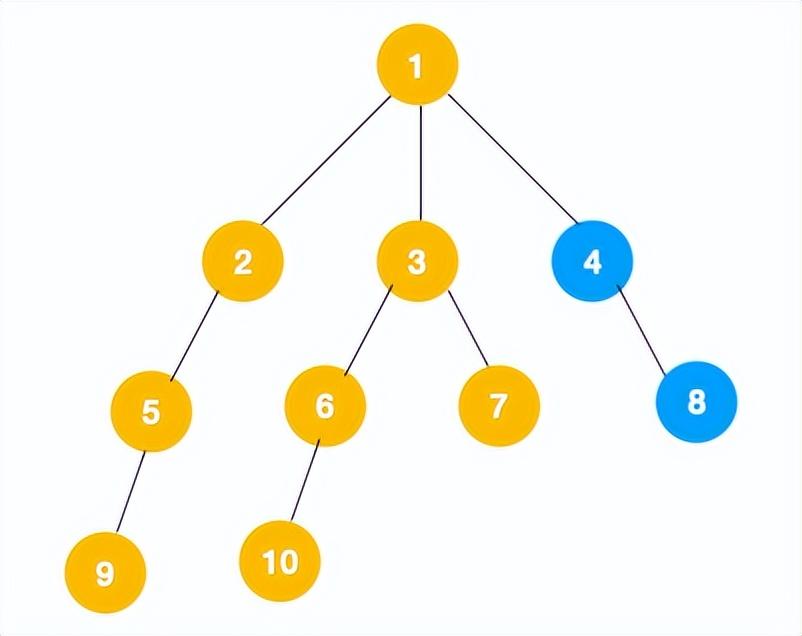
4、从 7 往上回溯到 3, 1,发现 1 还有节点 4 未遍历,所以此时沿着 4, 8 进行遍历,这样就遍历完成了。
完整的节点的遍历顺序如下(节点上的的蓝色数字代表):
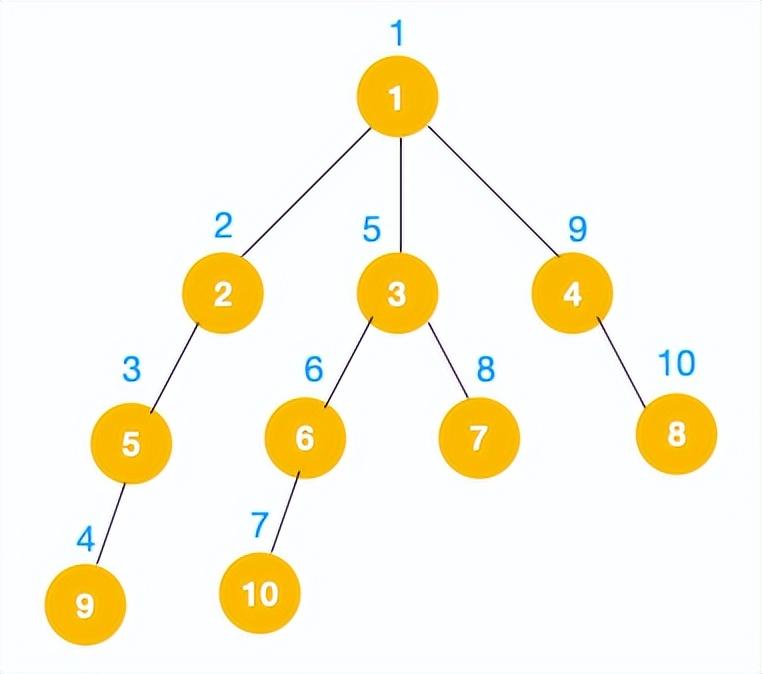
相信大家看到以上的遍历不难发现这就是树的前序遍历,实际上不管是前序遍历,还是中序遍历,亦或是后序遍历,都属于深度优先遍历。
那么深度优先遍历该怎么实现呢,有递归和非递归两种表现形式,接下来我们以二叉树为例来看下如何分别用递归和非递归来实现深度优先遍历。
递归实现
递归实现比较简单,由于是前序遍历,所以我们依次遍历当前节点,左节点,右节点即可,对于左右节点来说,依次遍历它们的左右节点即可,依此不断递归下去,直到叶节点(递归终止条件),代码如下:
public class Solution { private static class Node { /** * 节点值 */ public int value; /** * 左节点 */ public Node left; /** * 右节点 */ public Node right; public Node(int value, Node left, Node right) { this.value = value; this.left = left; this.right = right; } } public static void dfs(Node treeNode) { if (treeNode == null) { return; } // 遍历节点 process(treeNode) // 遍历左节点 dfs(treeNode.left); // 遍历右节点 dfs(treeNode.right); } }递归的表达性很好,也很容易理解,不过如果层级过深,很容易导致栈溢出。所以我们重点看下非递归实现。
非递归实现
仔细观察深度优先遍历的特点,对二叉树来说,由于是先序遍历(先遍历当前节点,再遍历左节点,再遍历右节点),所以我们有如下思路:
对于每个节点来说,先遍历当前节点,然后把右节点压栈,再压左节点(这样弹栈的时候会先拿到左节点遍历,符合深度优先遍历要求)。
弹栈,拿到栈顶的节点,如果节点不为空,重复步骤 1, 如果为空,结束遍历。
我们以以下二叉树为例来看下如何用栈来实现 DFS。
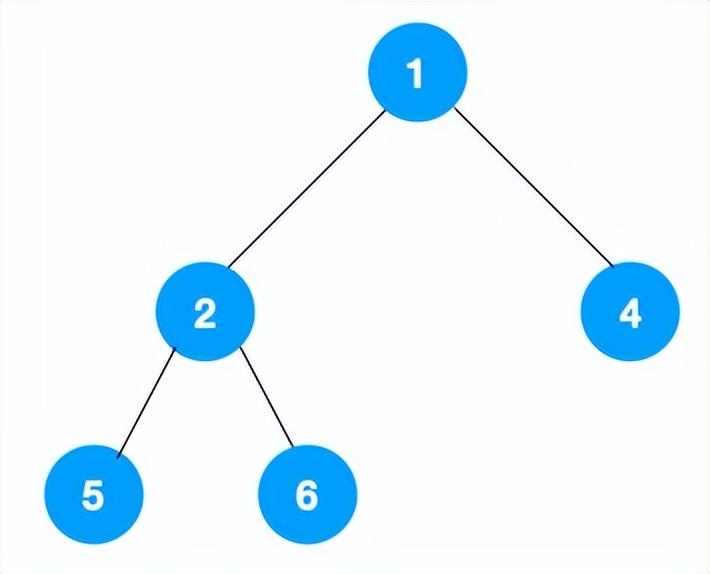
整体动图如下:
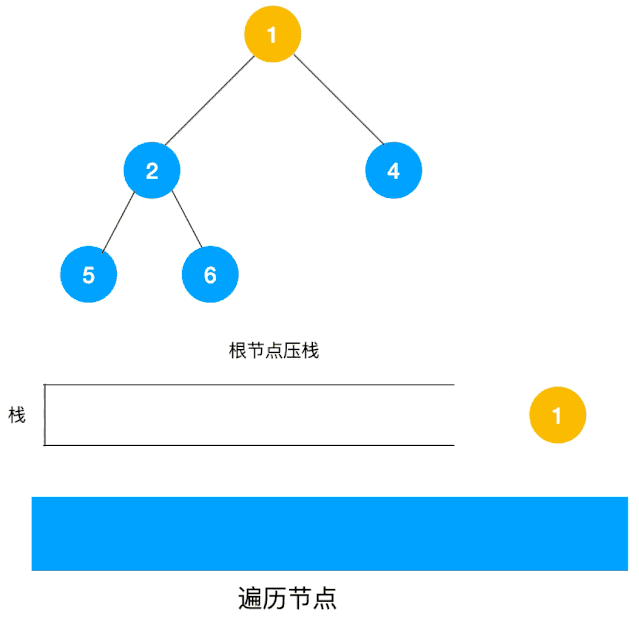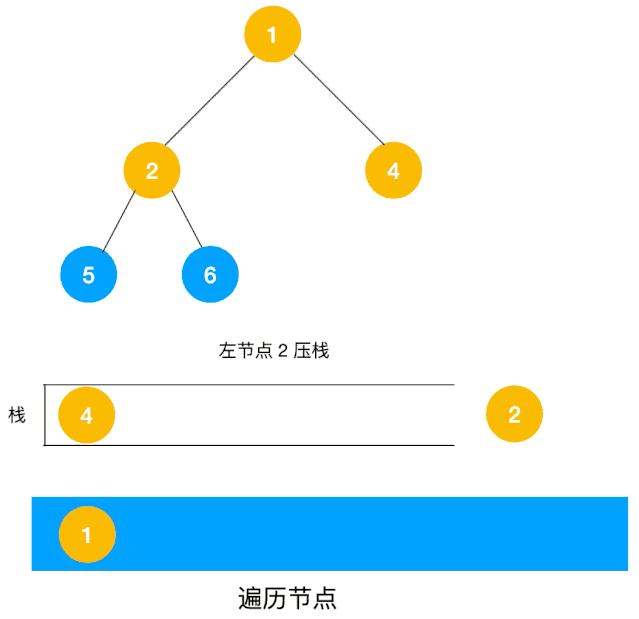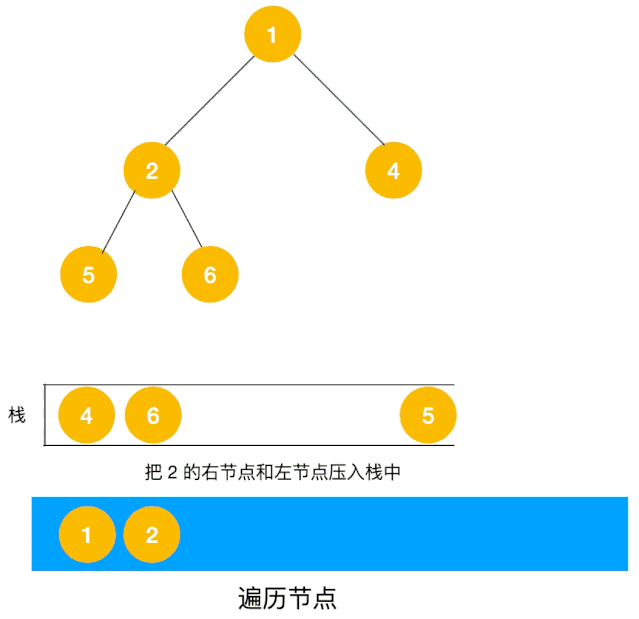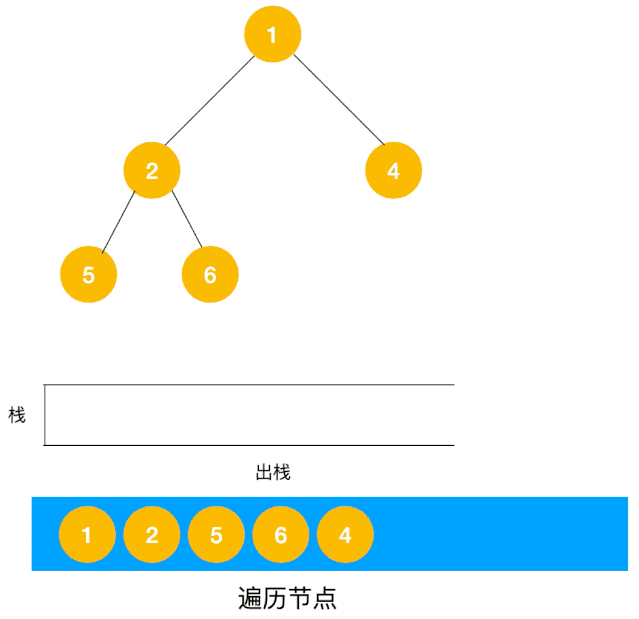
整体思路还是比较清晰的,使用栈来将要遍历的节点压栈,然后出栈后检查此节点是否还有未遍历的节点,有的话压栈,没有的话不断回溯(出栈),有了思路,不难写出如下用栈实现的二叉树的深度优先遍历代码:
/** * 使用栈来实现 dfs * @param root */ public static void dfsWithStack(Node root) { if (root == null) { return; } Stack<Node> stack = new Stack<>(); // 先把根节点压栈 stack.push(root); while (!stack.isEmpty()) { Node treeNode = stack.pop(); // 遍历节点 process(treeNode) // 先压右节点 if (treeNode.right != null) { stack.push(treeNode.right); } // 再压左节点 if (treeNode.left != null) { stack.push(treeNode.left); } } } 可以看到用栈实现深度优先遍历其实代码也不复杂,而且也不用担心递归那样层级过深导致的栈溢出问题。
广度优先遍历,指的是从图的一个未遍历的节点出发,先遍历这个节点的相邻节点,再依次遍历每个相邻节点的相邻节点。
上文所述树的广度优先遍历动图如下,每个节点的值即为它们的遍历顺序。所以广度优先遍历也叫层序遍历,先遍历第一层(节点 1),再遍历第二层(节点 2,3,4),第三层(5,6,7,8),第四层(9,10)。

深度优先遍历用的是栈,而广度优先遍历要用队列来实现,我们以下图二叉树为例来看看如何用队列来实现广度优先遍历。
动图如下:
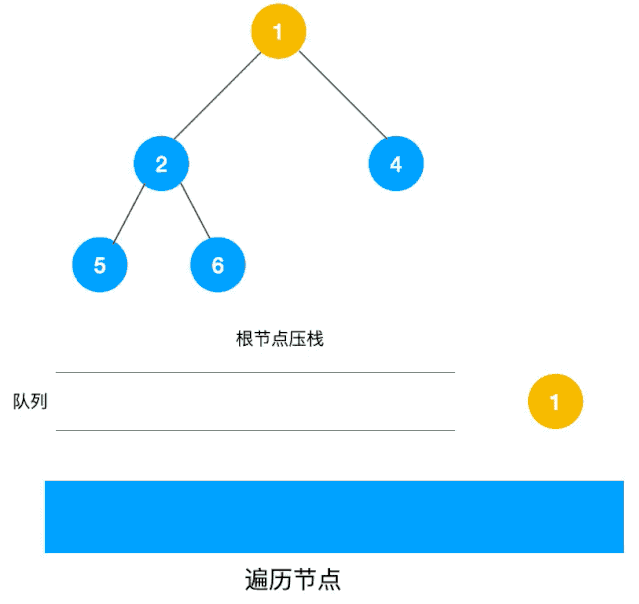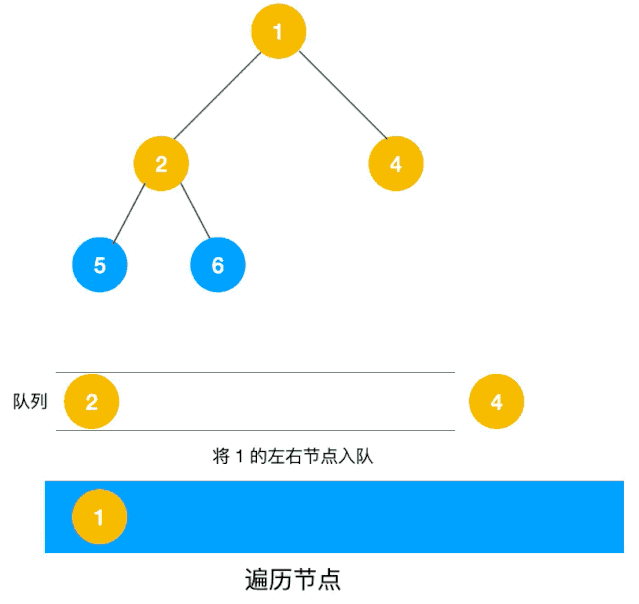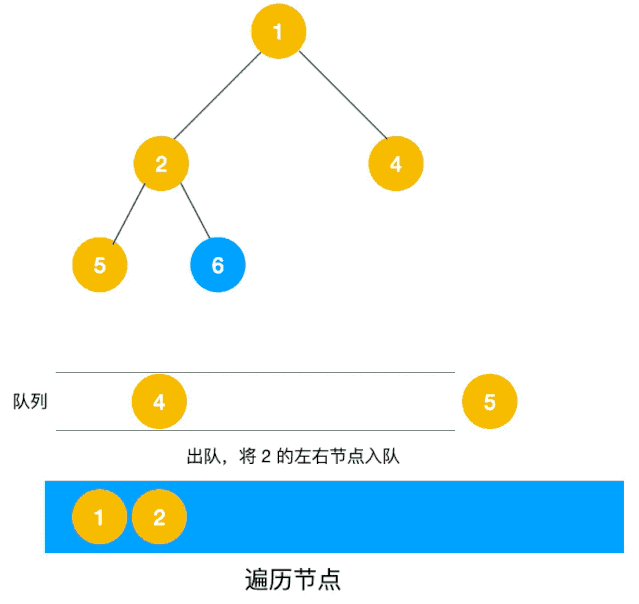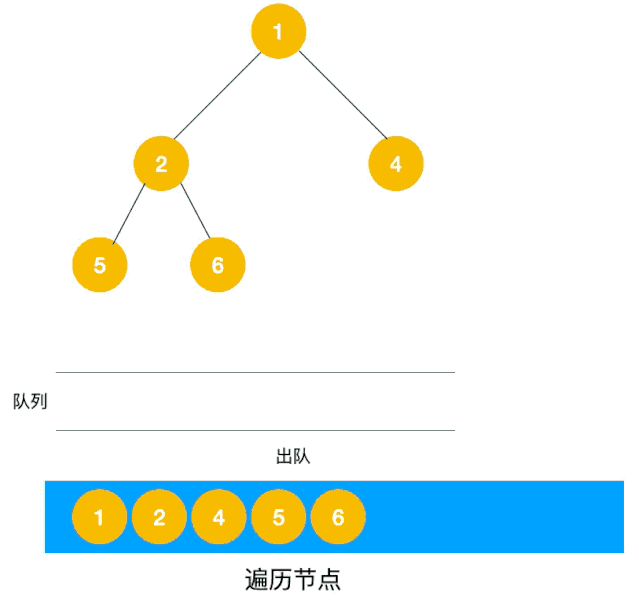
相信看了以上动图,不难写出如下代码:
/** * 使用队列实现 bfs * @param root */ private static void bfs(Node root) { if (root == null) { return; } Queue<Node> stack = new LinkedList<>(); stack.add(root); while (!stack.isEmpty()) { Node node = stack.poll(); System.out.println("value = " + node.value); Node left = node.left; if (left != null) { stack.add(left); } Node right = node.right; if (right != null) { stack.add(right); } } } 拓扑排序(Topological Order)是指,将一个有向无环图(Directed Acyclic Graph简称DAG)进行排序进而得到一个有序的线性序列。
这样说,可能理解起来比较抽象。下面通过简单的例子进行说明!
例如,一个项目包括A、B、C、D四个子部分来完成,并且A依赖于B和D,C依赖于D。现在要制定一个计划,写出A、B、C、D的执行顺序。这时,就可以利用到拓扑排序,它就是用来确定事物发生的顺序的。
在拓扑排序中,如果存在一条从顶点A到顶点B的路径,那么在排序结果中B出现在A的后面。
拓扑排序算法的基本步骤:
1. 构造一个队列Q(queue) 和 拓扑排序的结果队列T(topological);
2. 把所有没有依赖顶点的节点放入Q;
3. 当Q还有顶点的时候,执行下面步骤:
3.1 从Q中取出一个顶点n(将n从Q中删掉),并放入T(将n加入到结果集中);
3.2 对n每一个邻接点m(n是起点,m是终点);
3.2.1 去掉边<n,m>;
3.2.2 如果m没有依赖顶点,则把m放入Q;
注:顶点A没有依赖顶点,是指不存在以A为终点的边。
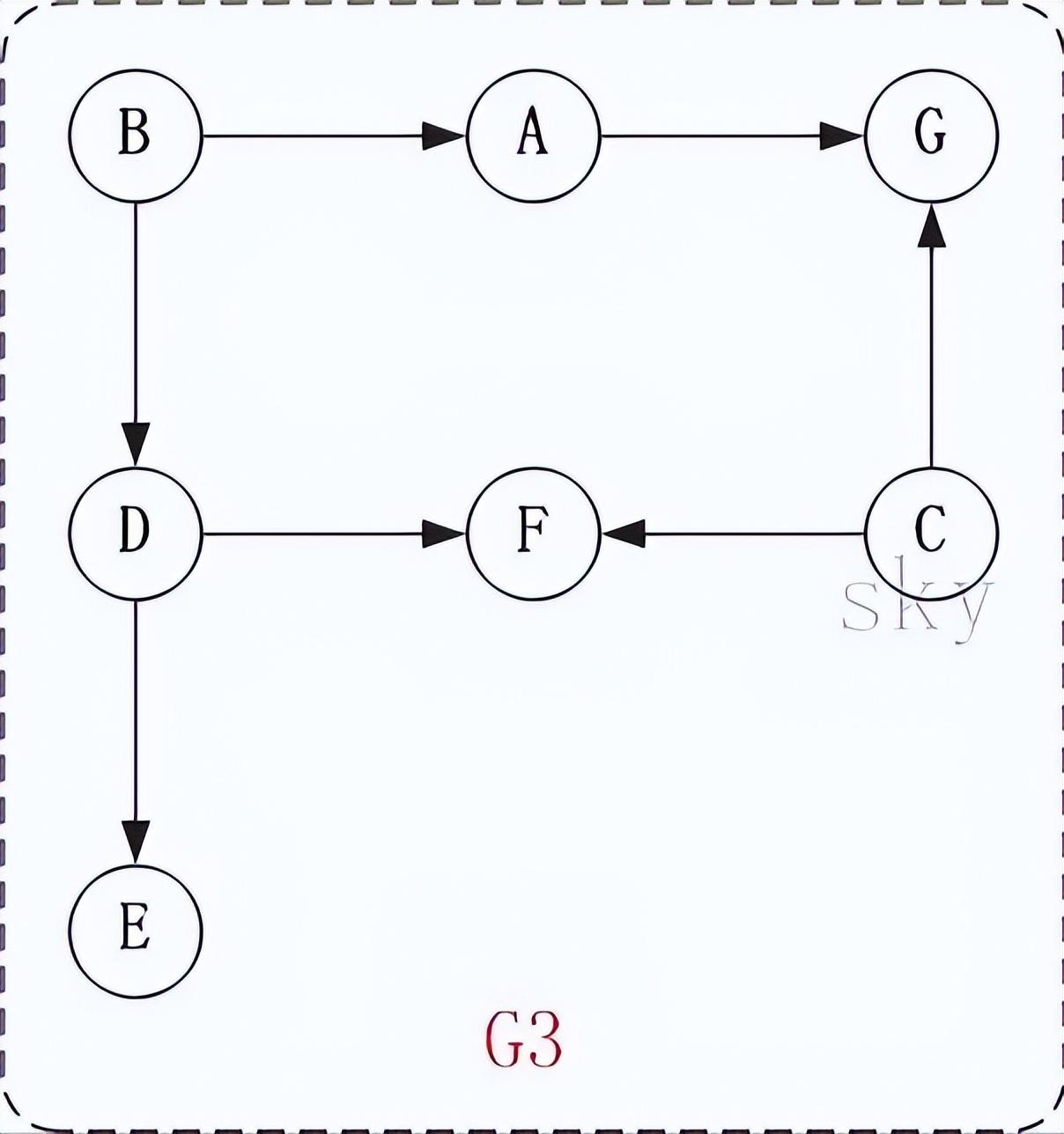
以上图为例,来对拓扑排序进行演示。
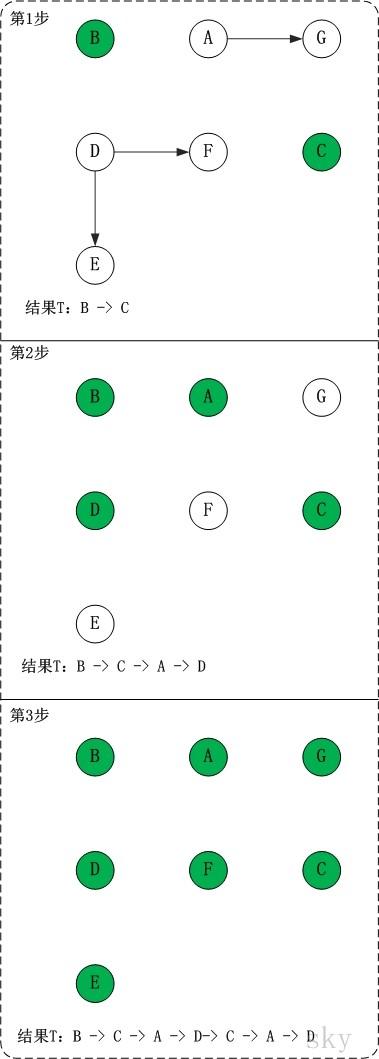
第1步:将B和C加入到排序结果中。
顶点B和顶点C都是没有依赖顶点,因此将C和C加入到结果集T中。假设ABCDEFG按顺序存储,因此先访问B,再访问C。访问B之后,去掉边<B,A>和<B,D>,并将A和D加入到队列Q中。同样的,去掉边<C,F>和<C,G>,并将F和G加入到Q中。
(01) 将B加入到排序结果中,然后去掉边<B,A>和<B,D>;此时,由于A和D没有依赖顶点,因此并将A和D加入到队列Q中。
(02) 将C加入到排序结果中,然后去掉边<C,F>和<C,G>;此时,由于F有依赖顶点D,G有依赖顶点A,因此不对F和G进行处理。
第2步:将A,D依次加入到排序结果中。
第1步访问之后,A,D都是没有依赖顶点的,根据存储顺序,先访问A,然后访问D。访问之后,删除顶点A和顶点D的出边。
第3步:将E,F,G依次加入到排序结果中。
因此访问顺序是:B -> C -> A -> D -> E -> F -> G
拓扑排序是对有向无向图的排序。下面以邻接表实现的有向图来对拓扑排序进行说明。
/* * 拓扑排序 * * 返回值: * -1 -- 失败(由于内存不足等原因导致) * 0 -- 成功排序,并输入结果 * 1 -- 失败(该有向图是有环的) */public class ListDG {// 邻接表中表对应的链表的顶点 private class ENode { int ivex; // 该边所指向的顶点的位置 ENode nextEdge; // 指向下一条弧的指针 }// 邻接表中表的顶点 private class VNode { char data; // 顶点信息 ENode firstEdge; // 指向第一条依附该顶点的弧 } ; private VNode[] mVexs; // 顶点数组...}(01) ListDG是邻接表对应的结构体。 mVexs则是保存顶点信息的一维数组。
(02) VNode是邻接表顶点对应的结构体。 data是顶点所包含的数据,而firstEdge是该顶点所包含链表的表头指针。
(03) ENode是邻接表顶点所包含的链表的节点对应的结构体。 ivex是该节点所对应的顶点在vexs中的索引,而nextEdge是指向下一个节点的。
public int topologicalSort() { int index = 0; int num = mVexs.size(); int[] ins; // 入度数组 char[] tops; // 拓扑排序结果数组,记录每个节点的排序后的序号。 Queue<Integer> queue; // 辅组队列 ins = new int[num]; tops = new char[num]; queue = new LinkedList<Integer>(); // 统计每个顶点的入度数 for(int i = 0; i < num; i++) { ENode node = mVexs.get(i).firstEdge; while (node != null) { ins[node.ivex]++; node = node.nextEdge; } } // 将所有入度为0的顶点入队列 for(int i = 0; i < num; i ++) if(ins[i] == 0) queue.offer(i); // 入队列 while (!queue.isEmpty()) { // 队列非空 int j = queue.poll().intValue(); // 出队列。j是顶点的序号 tops[index++] = mVexs.get(j).data; // 将该顶点添加到tops中,tops是排序结果 ENode node = mVexs.get(j).firstEdge;// 获取以该顶点为起点的出边队列 // 将与"node"关联的节点的入度减1; // 若减1之后,该节点的入度为0;则将该节点添加到队列中。 while(node != null) { // 将节点(序号为node.ivex)的入度减1。 ins[node.ivex]--; // 若节点的入度为0,则将其"入队列" if( ins[node.ivex] == 0) queue.offer(node.ivex); // 入队列 node = node.nextEdge; } } if(index != num) { System.out.printf("Graph has a cycle\n"); return 1; } // 打印拓扑排序结果 System.out.printf("== TopSort: "); for(int i = 0; i < num; i ++) System.out.printf("%c ", tops[i]); System.out.printf("\n"); return 0; } 说明:
(01) queue的作用就是用来存储没有依赖顶点的顶点。它与前面所说的Q相对应。
(02) tops的作用就是用来存储排序结果。它与前面所说的T相对应。
第1步:将B和C加入到排序结果中。
顶点B和顶点C都是没有依赖顶点,因此将C和C加入到结果集T中。假设ABCDEFG按顺序存储,因此先访问B,再访问C。访问B之后,去掉边<B,A>和<B,D>,并将A和D加入到队列Q中。同样的,去掉边<C,F>和<C,G>,并将F和G加入到Q中。
(01) 将B加入到排序结果中,然后去掉边<B,A>和<B,D>;此时,由于A和D没有依赖顶点,因此并将A和D加入到队列Q中。
(02) 将C加入到排序结果中,然后去掉边<C,F>和<C,G>;此时,由于F有依赖顶点D,G有依赖顶点A,因此不对F和G进行处理。
第2步:将A,D依次加入到排序结果中。
第1步访问之后,A,D都是没有依赖顶点的,根据存储顺序,先访问A,然后访问D。访问之后,删除顶点A和顶点D的出边。
第3步:将E,F,G依次加入到排序结果中。
因此访问顺序是:B -> C -> A -> D -> E -> F -> G
在含有n个顶点的连通图中选择n-1条边,构成一棵极小连通子图,并使该连通子图中n-1条边上权值之和达到最小,则称其为连通网的最小生成树。
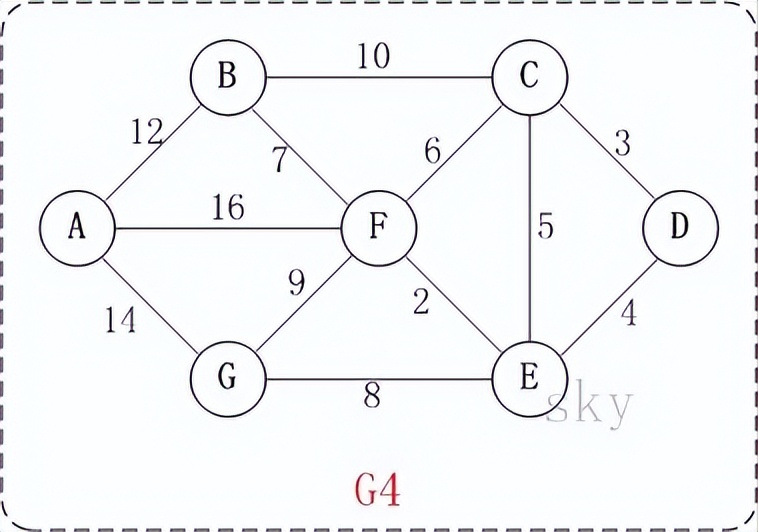
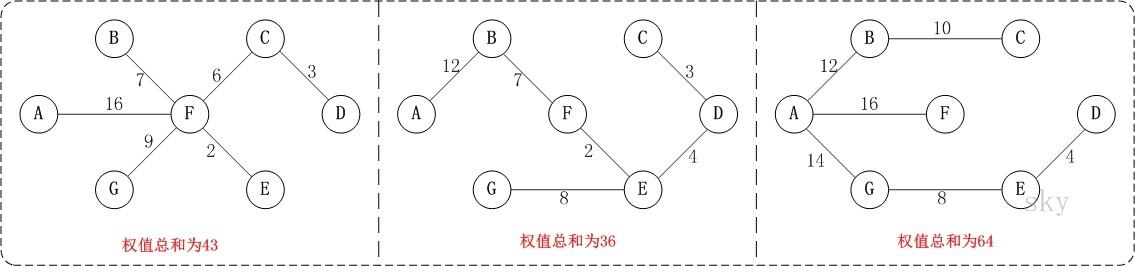
例如,对于如上图G4所示的连通网可以有多棵权值总和不相同的生成树。
克鲁斯卡尔(Kruskal)算法,是用来求加权连通图的最小生成树的算法。
基本思想:按照权值从小到大的顺序选择n-1条边,并保证这n-1条边不构成回路。
具体做法:首先构造一个只含n个顶点的森林,然后依权值从小到大从连通网中选择边加入到森林中,并使森林中不产生回路,直至森林变成一棵树为止。
以上图G4为例,来对克鲁斯卡尔进行演示(假设,用数组R保存最小生成树结果)。
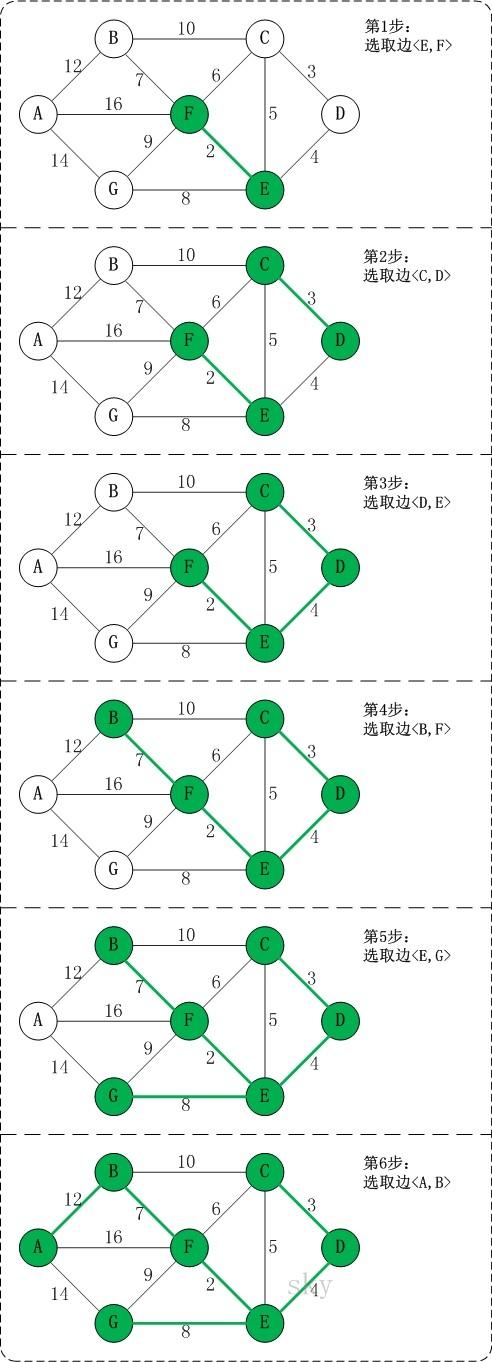
第1步:将边<E,F>加入R中。
边<E,F>的权值最小,因此将它加入到最小生成树结果R中。
第2步:将边<C,D>加入R中。
上一步操作之后,边<C,D>的权值最小,因此将它加入到最小生成树结果R中。
第3步:将边<D,E>加入R中。
上一步操作之后,边<D,E>的权值最小,因此将它加入到最小生成树结果R中。
第4步:将边<B,F>加入R中。
上一步操作之后,边<C,E>的权值最小,但<C,E>会和已有的边构成回路;因此,跳过边<C,E>。同理,跳过边<C,F>。将边<B,F>加入到最小生成树结果R中。
第5步:将边<E,G>加入R中。
上一步操作之后,边<E,G>的权值最小,因此将它加入到最小生成树结果R中。
第6步:将边<A,B>加入R中。
上一步操作之后,边<F,G>的权值最小,但<F,G>会和已有的边构成回路;因此,跳过边<F,G>。同理,跳过边<B,C>。将边<A,B>加入到最小生成树结果R中。
此时,最小生成树构造完成!它包括的边依次是:<E,F> <C,D> <D,E> <B,F> <E,G> <A,B>。
根据前面介绍的克鲁斯卡尔算法的基本思想和做法,我们能够了解到,克鲁斯卡尔算法重点需要解决的以下两个问题:
问题一 对图的所有边按照权值大小进行排序。
问题二 将边添加到最小生成树中时,怎么样判断是否形成了回路。
问题一很好解决,采用排序算法进行排序即可。
问题二,处理方式是:记录顶点在”最小生成树”中的终点,顶点的终点是”在最小生成树中与它连通的最大顶点”(关于这一点,后面会通过图片给出说明)。然后每次需要将一条边添加到最小生存树时,判断该边的两个顶点的终点是否重合,重合的话则会构成回路。 以下图来进行说明:
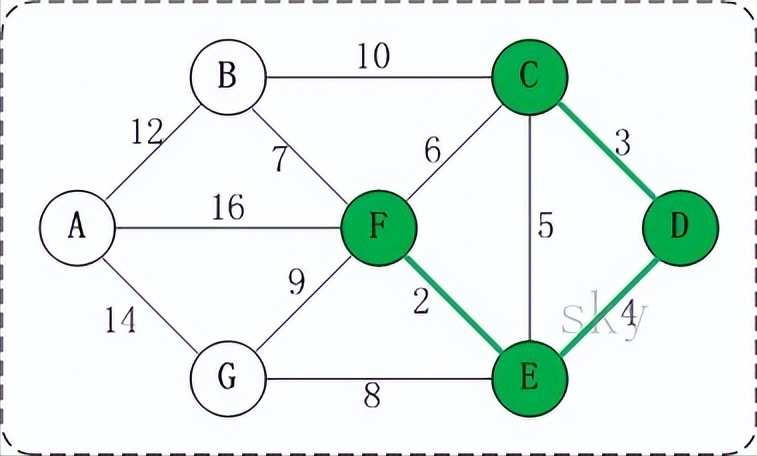
在将<E,F> <C,D> <D,E>加入到最小生成树R中之后,这几条边的顶点就都有了终点:
(01) C的终点是F。
(02) D的终点是F。
(03) E的终点是F。
(04) F的终点是F。
关于终点,就是将所有顶点按照从小到大的顺序排列好之后;某个顶点的终点就是”与它连通的最大顶点”。 因此,接下来,虽然<C,E>是权值最小的边。但是C和E的重点都是F,即它们的终点相同,因此,将<C,E>加入最小生成树的话,会形成回路。这就是判断回路的方式。
有了前面的算法分析之后,下面我们来查看具体代码。这里选取”邻接矩阵”进行说明,对于”邻接表”实现的图在后面的源码中会给出相应的源码。
1. 基本定义
// 边的结构体 private static class EData { char start; // 边的起点 char end; // 边的终点 int weight; // 边的权重 public EData(char start, char end, int weight) { this.start = start; this.end = end; this.weight = weight; } }; EData是邻接矩阵边对应的结构体。
public class MatrixUDG { private int mEdgNum; // 边的数量 private char[] mVexs; // 顶点集合 private int[][] mMatrix; // 邻接矩阵 private static final int INF = Integer.MAX_VALUE; // 最大值 ... } MatrixUDG是邻接矩阵对应的结构体。mVexs用于保存顶点,mEdgNum用于保存边数,mMatrix则是用于保存矩阵信息的二维数组。例如,mMatrix[i][j]=1,则表示”顶点i(即mVexs[i])”和”顶点j(即mVexs[j])”是邻接点;mMatrix[i][j]=0,则表示它们不是邻接点。
2. 克鲁斯卡尔算法
/* * 克鲁斯卡尔(Kruskal)最小生成树 *public void kruskal(){ int index=0; // rets数组的索引 int[]vends=new int[mEdgNum]; // 用于保存"已有最小生成树"中每个顶点在该最小树中的终点。 EData[]rets=new EData[mEdgNum]; // 结果数组,保存kruskal最小生成树的边 EData[]edges; // 图对应的所有边 // 获取"图中所有的边" edges=getEdges(); // 将边按照"权"的大小进行排序(从小到大) sortEdges(edges,mEdgNum); for(int i=0;i<mEdgNum; i++){ int p1=getPosition(edges[i].start); // 获取第i条边的"起点"的序号 int p2=getPosition(edges[i].end); // 获取第i条边的"终点"的序号 int m=getEnd(vends,p1); // 获取p1在"已有的最小生成树"中的终点 int n=getEnd(vends,p2); // 获取p2在"已有的最小生成树"中的终点 // 如果m!=n,意味着"边i"与"已经添加到最小生成树中的顶点"没有形成环路 if(m!=n){ vends[m]=n; // 设置m在"已有的最小生成树"中的终点为n rets[index++]=edges[i]; // 保存结果 } } // 统计并打印"kruskal最小生成树"的信息 int length=0; for(int i=0;i<index; i++){ length+=rets[i].weight; System.out.printf("Kruskal=%d: ",length); for(int i=0;i<index; i++){ System.out.printf("(%c,%c) ",rets[i].start,rets[i].end); System.out.printf("\n"); } } } 普利姆(Prim)算法求最小生成树,也就是在包含n个顶点的连通图中,找出只有(n-1)条边包含所有n个顶点的连通子图,也就是所谓的极小连通子图
普利姆的算法如下:
1)、设G=(V,E)是连通网,T=(U,D)是最小生成树,V,U是顶点集合,E,D是边的集合
2)、若从顶点u开始构造最小生成树,则从集合V中取出顶点u放入集合U中,标记顶点v的visited[u]=1
3)、若集合U中顶点ui与集合V-U中的顶点vj之间存在边,则寻找这些边中权值最小的边,但不能构成回路,将顶点vj加入集合U中,将边(ui,vj)加入集合D中,标记visited[vj]=1
4)、重复步骤②,直到U与V相等,即所有顶点都被标记为访问过,此时D中有n-1条边
有胜利乡有7个村庄(A, B, C, D, E, F, G) ,现在需要修路把7个村庄连通;各个村庄的距离用边线表示(权) ,比如 A – B 距离 5公里,问:如何修路保证各个村庄都能连通,并且总的修建公路总里程最短?(如下图:)
修路问题本质就是最小生成树问题
五、普里姆算法——解决修路问题的代码实现
使用邻接矩阵表示村庄修路的图,(如下图)
1)、表格中A行A列=10000,表示A和A两点不连通
2)、表格中A行B列=5,表示A和B两点可以连通,权值是5
3)、表格中A行C列=7,表示A和C两点可以连通,权值是7
4)、表格中A行D列=10000,表示A和D两点不连通
5)、依此类推…
package com.rf.springboot01.Algorithm.prim; import java.util.Arrays; /** * @description: 普里姆算法(Prim算法)示例 * @author: xz * @create: 2020-11-13 20:47 */ public class PrimAlgorithm { public static void main(String[] args) { //定义图的各个顶点的值 char[] data=new char[]{'A','B','C','D','E','F','G'}; //根据图的各个顶点的值,获取图对应的顶点个数 int verxs=data.length; //使用二维数组表示邻接矩阵的关系 ,10000:表示两个点不连通 int[][] weight=new int[][]{ {10000,5,7,10000,10000,10000,2}, {5,10000,10000,9,10000,10000,3}, {7,10000,10000,10000,8,10000,10000}, {10000,9,10000,10000,10000,4,10000}, {10000,10000,8,10000,10000,5,4}, {10000,10000,10000,4,5,10000,6}, {2,3,10000,10000,4,6,10000} }; //创建Graph对象 Graph graph = new Graph(verxs); //创建MinTree对象 MinTree minTree=new MinTree(); //创建图的邻接矩阵 minTree.createGraph(graph,verxs,data,weight); //显示图的邻接矩阵 System.out.println("图的邻接矩阵----------------------"); minTree.showGraph(graph); //测试普里姆算法 System.out.println("普里姆算法=============="); minTree.prim(graph,0); } } /** * @Description: 创建最小生成树->村庄的图 * @Author: xz * @Date: 2020/11/13 21:53 */ class MinTree{ /** * @Description: 创建图的邻接矩阵 * @Param: graph 图对象 * verxs 图对应的顶点个数 * data 图的各个顶点的值 * weight 图的邻接矩阵 * @Author: xz * @Date: 2020/11/13 21:56 */ public void createGraph(Graph graph, int verxs, char[] data, int[][] weight){ for(int i=0;i<verxs;i++){ graph.data[i]=data[i]; for(int j=0;j<verxs;j++){ graph.weight[i][j]=weight[i][j]; } } } //显示图的邻接矩阵 public void showGraph(Graph graph) { for(int[] link: graph.weight) { System.out.println(Arrays.toString(link)); } } /** * @Description: prim算法,得到最小生成树 * @Param: graph 图 * v 表示从图的第几个顶点开始生成'A'->0 'B'->1... * @Author: xz * @Date: 2020/11/13 22:08 */ public void prim(Graph graph, int v) { //visited[] 标记结点(顶点)是否被访问过,visited[] 默认元素的值都是0, 表示没有访问过 int visited[] = new int[graph.verxs]; //把当前这个结点标记为已访问 visited[v] = 1; //h1 和 h2 记录两个顶点的下标 int h1 = -1; int h2 = -1; int minWeight = 10000; //将 minWeight 初始成一个大数,后面在遍历过程中,会被替换 int sumMinWeight=0;//所有对应边的最小权值的总和 for(int k = 1; k < graph.verxs; k++) {//因为有 graph.verxs顶点,普利姆算法结束后,有 graph.verxs-1边 //这个是确定每一次生成的子图 ,和哪个结点的距离最近 for(int i = 0; i < graph.verxs; i++) {// i结点表示被访问过的结点 for(int j = 0; j< graph.verxs;j++) {//j结点表示还没有访问过的结点 if(visited[i] == 1 && visited[j] == 0 && graph.weight[i][j] < minWeight) { //替换minWeight(寻找已经访问过的结点和未访问过的结点间的权值最小的边) minWeight = graph.weight[i][j]; h1 = i; h2 = j; } } } //退出双重for循环后就找到一条边是最小 System.out.println("对应的边<" + graph.data[h1] + "," + graph.data[h2] + "> 权值:" + minWeight); sumMinWeight += minWeight; //将当前这个结点标记为已经访问 visited[h2] = 1; //minWeight 重新设置为最大值 10000 minWeight = 10000; } System.out.println("所有对应边的最小权值的总和="+sumMinWeight); } } /** * @Description: 创建图 * @Author: xz * @Date: 2020/11/13 21:50 */ class Graph{ int verxs;//图的节点个数 char[] data;//存放图节点的数据 int[][] weight; //存放边,表示邻接矩阵 //构造函数 public Graph(int verxs){ this.verxs=verxs; data=new char[verxs]; weight=new int[verxs][verxs]; } } 迪杰斯特拉(Dijkstra)算法是典型最短路径算法,用于计算一个节点到其他节点的最短路径。
它的主要特点是以起始点为中心向外层层扩展(广度优先搜索思想),直到扩展到终点为止。
基本思想
通过Dijkstra计算图G中的最短路径时,需要指定起点s(即从顶点s开始计算)。
此外,引进两个集合S和U。S的作用是记录已求出最短路径的顶点(以及相应的最短路径长度),而U则是记录还未求出最短路径的顶点(以及该顶点到起点s的距离)。
初始时,S中只有起点s;U中是除s之外的顶点,并且U中顶点的路径是"起点s到该顶点的路径"。然后,从U中找出路径最短的顶点,并将其加入到S中;接着,更新U中的顶点和顶点对应的路径。 然后,再从U中找出路径最短的顶点,并将其加入到S中;接着,更新U中的顶点和顶点对应的路径。 ... 重复该操作,直到遍历完所有顶点。
操作步骤
(1) 初始时,S只包含起点s;U包含除s外的其他顶点,且U中顶点的距离为"起点s到该顶点的距离"[例如,U中顶点v的距离为(s,v)的长度,然后s和v不相邻,则v的距离为∞]。
(2) 从U中选出"距离最短的顶点k",并将顶点k加入到S中;同时,从U中移除顶点k。
(3) 更新U中各个顶点到起点s的距离。之所以更新U中顶点的距离,是由于上一步中确定了k是求出最短路径的顶点,从而可以利用k来更新其它顶点的距离;例如,(s,v)的距离可能大于(s,k)+(k,v)的距离。
(4) 重复步骤(2)和(3),直到遍历完所有顶点。
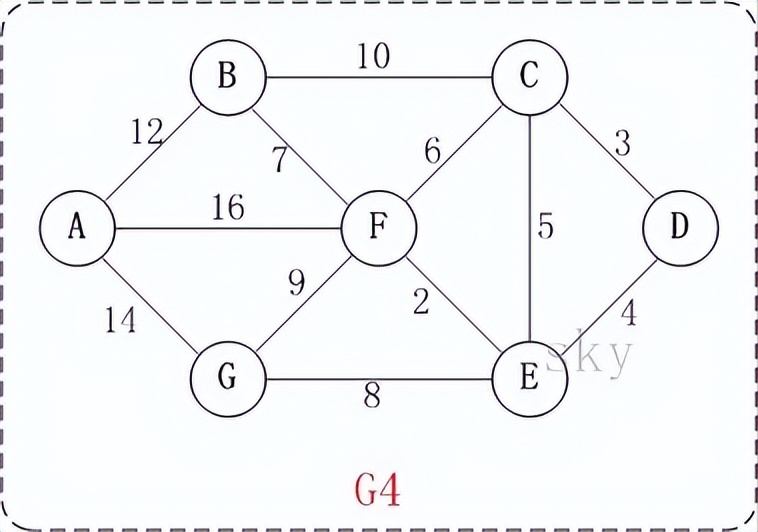
以上图G4为例,来对迪杰斯特拉进行算法演示(以第4个顶点D为起点)。
初始状态:S是已计算出最短路径的顶点集合,U是未计算除最短路径的顶点的集合!
第1步:将顶点D加入到S中。
此时,S={D(0)}, U={A(∞),B(∞),C(3),E(4),F(∞),G(∞)}。 注:C(3)表示C到起点D的距离是3。
第2步:将顶点C加入到S中。
上一步操作之后,U中顶点C到起点D的距离最短;因此,将C加入到S中,同时更新U中顶点的距离。以顶点F为例,之前F到D的距离为∞;但是将C加入到S之后,F到D的距离为9=(F,C)+(C,D)。
此时,S={D(0),C(3)}, U={A(∞),B(23),E(4),F(9),G(∞)}。
第3步:将顶点E加入到S中。
上一步操作之后,U中顶点E到起点D的距离最短;因此,将E加入到S中,同时更新U中顶点的距离。还是以顶点F为例,之前F到D的距离为9;但是将E加入到S之后,F到D的距离为6=(F,E)+(E,D)。
此时,S={D(0),C(3),E(4)}, U={A(∞),B(23),F(6),G(12)}。
第4步:将顶点F加入到S中。
此时,S={D(0),C(3),E(4),F(6)}, U={A(22),B(13),G(12)}。
第5步:将顶点G加入到S中。
此时,S={D(0),C(3),E(4),F(6),G(12)}, U={A(22),B(13)}。
第6步:将顶点B加入到S中。
此时,S={D(0),C(3),E(4),F(6),G(12),B(13)}, U={A(22)}。
第7步:将顶点A加入到S中。
此时,S={D(0),C(3),E(4),F(6),G(12),B(13),A(22)}。
此时,起点D到各个顶点的最短距离就计算出来了:A(22) B(13) C(3) D(0) E(4) F(6) G(12)。
5.4.1.3迪杰斯特拉算法的代码说明
以"邻接矩阵"为例对迪杰斯特拉算法进行说明,对于"邻接表"实现的图在后面会给出相应的源码。
1. 基本定义
public class MatrixUDG {private int mEdgNum; // 边的数量private char[] mVexs; // 顶点集合private int[][] mMatrix; // 邻接矩阵private static final int INF = Integer.MAX_VALUE; // 最大值...}MatrixUDG是邻接矩阵对应的结构体。mVexs用于保存顶点,mEdgNum用于保存边数,mMatrix则是用于保存矩阵信息的二维数组。例如,mMatrix[i][j]=1,则表示"顶点i(即mVexs[i])"和"顶点j(即mVexs[j])"是邻接点;mMatrix[i][j]=0,则表示它们不是邻接点。
2. 迪杰斯特拉算法
/** * Dijkstra最短路径。 * 即,统计图中"顶点vs"到其它各个顶点的最短路径。 * * 参数说明: * vs -- 起始顶点(start vertex)。即计算"顶点vs"到其它顶点的最短路径。 * prev -- 前驱顶点数组。即,prev[i]的值是"顶点vs"到"顶点i"的最短路径所经历的全部顶点中,位于"顶点i"之前的那个顶点。 * dist -- 长度数组。即,dist[i]是"顶点vs"到"顶点i"的最短路径的长度。 */ public void dijkstra(int vs,int[]prev,int[]dist){ // flag[i]=true表示"顶点vs"到"顶点i"的最短路径已成功获取 boolean[]flag=new boolean[mVexs.length]; // 初始化 for(int i=0;i<mVexs.length;i++){ flag[i]=false; // 顶点i的最短路径还没获取到。 prev[i]=0; // 顶点i的前驱顶点为0。 dist[i]=mMatrix[vs][i]; // 顶点i的最短路径为"顶点vs"到"顶点i"的权。 } // 对"顶点vs"自身进行初始化 flag[vs]=true; dist[vs]=0; // 遍历mVexs.length-1次;每次找出一个顶点的最短路径。 int k=0; for(int i=1;i<mVexs.length;i++){ // 寻找当前最小的路径; // 即,在未获取最短路径的顶点中,找到离vs最近的顶点(k)。 int min=INF; for(int j=0;j<mVexs.length;j++){ if(flag[j]==false&&dist[j]<min){ min=dist[j]; k=j; } } // 标记"顶点k"为已经获取到最短路径 flag[k]=true; // 修正当前最短路径和前驱顶点 // 即,当已经"顶点k的最短路径"之后,更新"未获取最短路径的顶点的最短路径和前驱顶点"。 for(int j=0;j<mVexs.length;j++){ int tmp=(mMatrix[k][j]==INF?INF:(min+mMatrix[k][j])); if(flag[j]==false&&(tmp<dist[j])){ dist[j]=tmp; prev[j]=k; } } } // 打印dijkstra最短路径的结果 System.out.printf("dijkstra(%c): \n",mVexs[vs]); for(int i=0;i<mVexs.length;i++){ System.out.printf(" shortest(%c, %c)=%d\n",mVexs[vs],mVexs[i],dist[i]); } } 2. 弗洛伊德算法(Floyd)计算图中各个顶点之间的最短路径
3. 迪杰斯特拉算法用于计算图中某-一个顶点到其他项点的最短路径。
4. 弗洛伊德算法VS迪杰斯特拉算法:迪杰斯特拉算法通过选定的被访问顶点,求出从出发访问顶点到其他项点的最短路径:弗洛伊德算法中每-个顶点都是出发访问点,所以需要将每-一个顶点看做被访问顶点,求出从每一个顶点到其他顶点的最短路径。
图解:
面对问题:求出每一个点到其他点的距离;
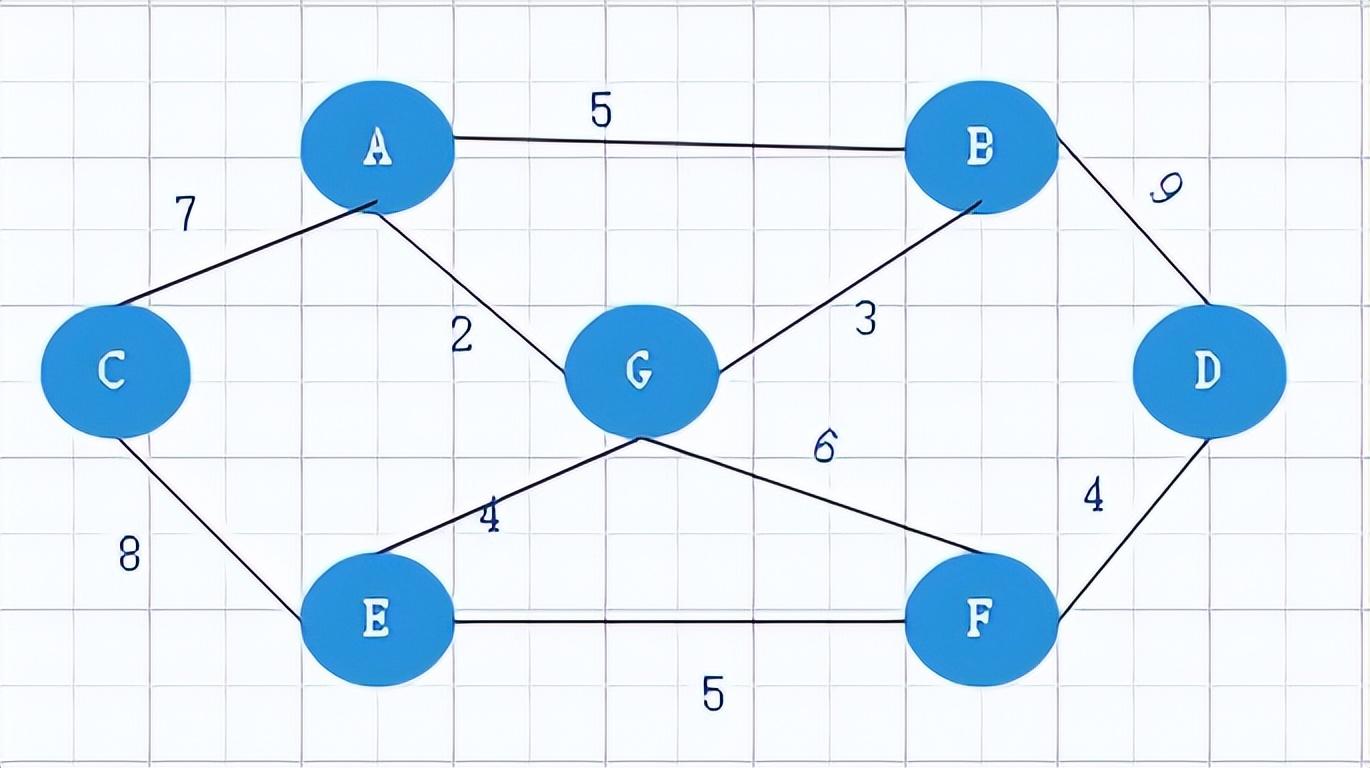
package FloydAlgorithm; import java.util.Arrays; public class Floyd { public static void main(String[] args) { char[] vertex = new char[] { 'A', 'B', 'C', 'D', 'E', 'F', 'G' }; int[][] arr = new int[vertex.length][vertex.length]; final int N = 100; arr[0] = new int[] { 0, 5, 7, N, N, N, 2 }; arr[1] = new int[] { 5, 0, N, 9, N, N, 3 }; arr[2] = new int[] { 7, N, 0, N, 8, N, N }; arr[3] = new int[] { N, 9, N, 0, N, 4, N }; arr[4] = new int[] { N, N, 8, N, 0, 5, 4 }; arr[5] = new int[] { N, N, N, 4, 5, 0, 6 }; arr[6] = new int[] { 2, 3, N, N, 4, 6, 0 }; Graph gp = new Graph(vertex, arr, vertex.length); gp.floyd(); gp.show(); } } //创建图 class Graph { private char[] vertex; private int[][] dis; // 从顶点出发到其他节点的距离 private int[][] pre; // 目标节点的前驱节点 // 顶点数组 邻接矩阵 长度大小 public Graph(char[] vertex, int[][] dis, int len) { this.vertex = vertex; this.dis = dis; this.pre = new int[len][len]; // 对pre数组进行初始化 for (int i = 0; i < len; i++) { Arrays.fill(pre[i], i); } } public void show() { char[] vertex = new char[] { 'A', 'B', 'C', 'D', 'E', 'F', 'G' }; for (int i = 0; i < dis.length; i++) { for (int j = 0; j < dis.length; j++) { System.out.print(vertex[pre[i][j]] + " "); } System.out.println(); for (int j = 0; j < dis.length; j++) { System.out.print("( " + vertex[i] + " -> " + vertex[j] + " 的最短路径 " + dis[i][j] + " ) "); } System.out.println(); } } // 弗洛伊德算法 public void floyd() { int len = 0; // 从中间节点进行遍历 for (int k = 0; k < dis.length; k++) { // 对出发节点进行遍历 for (int i = 0; i < dis.length; i++) { // 遍历终点节点 for (int j = 0; j < dis.length; j++) { len = dis[i][k] + dis[k][j]; if (len < dis[i][j]) { dis[i][j] = len; pre[i][j] = pre[k][j]; } } } } } } 声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号