程序员必备:数据结构与算法基础全面解析——数据结构篇
发表时间: 2021-01-06 15:37
对于绝大多少程序员来说,数据结构与算法绝对是一门非常重要但又非常难以掌握的学科。最近自己系统学习了一套数据结构与算法的课程,也开始到Leetcode上刷题了。这里对课程中讲到的一些数据结构与算法基础做了一些回顾和总结,从宏观上先来了解整个知识框架。
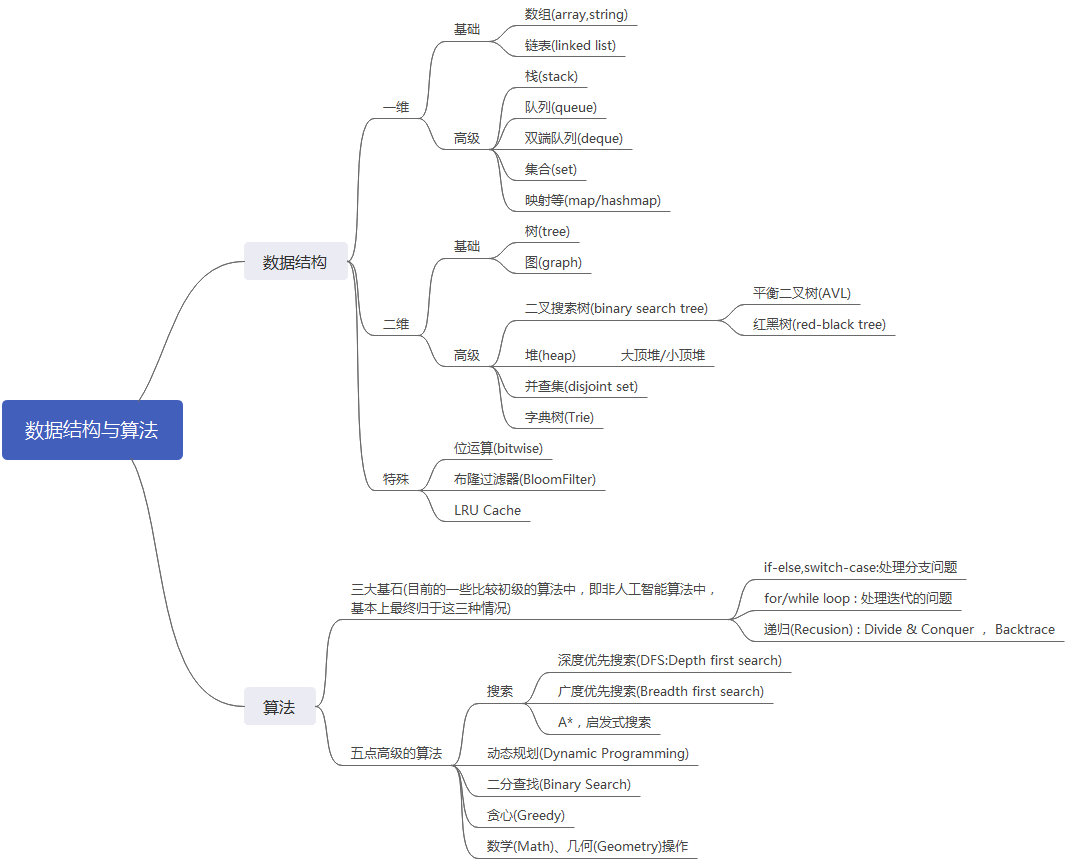
数据结构与算法总览图
1、数组(Array)
数组的底层硬件实现是,有一个叫内存控制器的结构,为数组分配一个段连续的内存空间,这些空间中存储着数组中对应的值(值为基本数据类型)或者地址(值为引用类型)。当根据index访问数组中的某个元素时,内存控制器直接定位到该index所在的地址,无论是第一个元素、中间元素还是最后一个元素,都能一次性定位到,时间复杂度为O(1)。
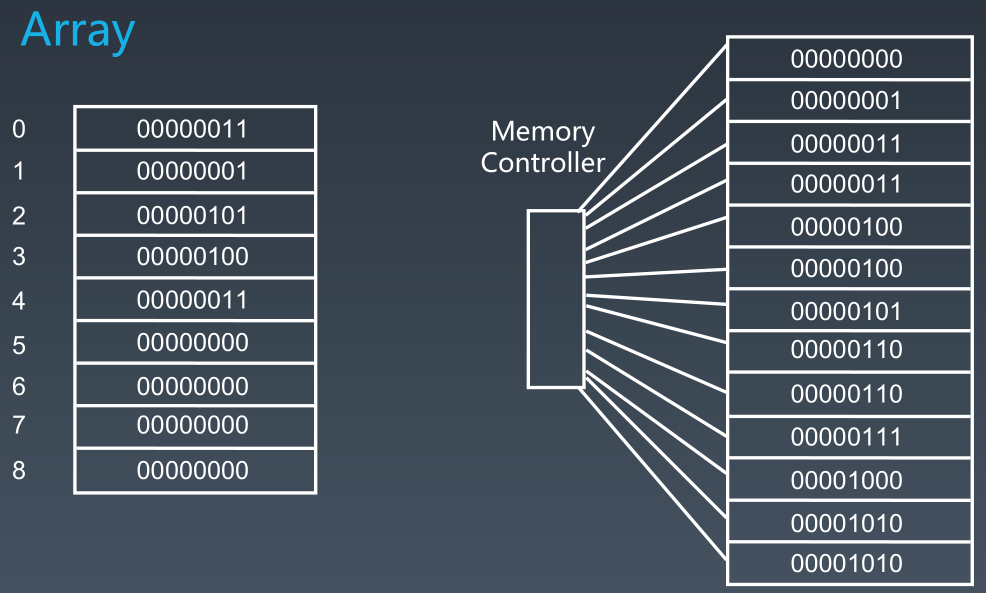
Java中ArrayList是对数组的一个典型使用,其内部维护着一个数组,ArrayList的增、删、查等,都是对其中数组进行操作。所以根据index进行查找时比较快,时间复杂度为O(1);但增加和删除元素时需要扩容或者移动数组元素的位置等操作,其中扩容时还会开辟更大容量的数组,将原数组的值复制到新数组中,并将新数组复制给原数组,所以此时时间复杂度和空间复杂度为O(n)。对于频繁查找数据时,使用ArrayList效率比较高。
2、链表(Linked List)
可以通过使用双向链表或者设置头尾指针的方式,让操作链表更加方便。
Java中LinkedList是对链表的一个典型使用,其内部维护着一个双向链表,对数据的增,删、查、改操作实际上都是对链表的操作。增、删、改非首位节点本身操作时间复杂度为O(1),但是要查找到对应操作的位置,实际上也要经过遍历查找,而链表的时间复杂度为O(n)
3、跳表(Skip List)
跳表是在一个有序链表的基础上升维,添加多级索引,以空间换时间,其空间复杂度为O(n),用于存储索引节点。其有序性对标的是平衡二叉树,二叉搜索树等数据结构
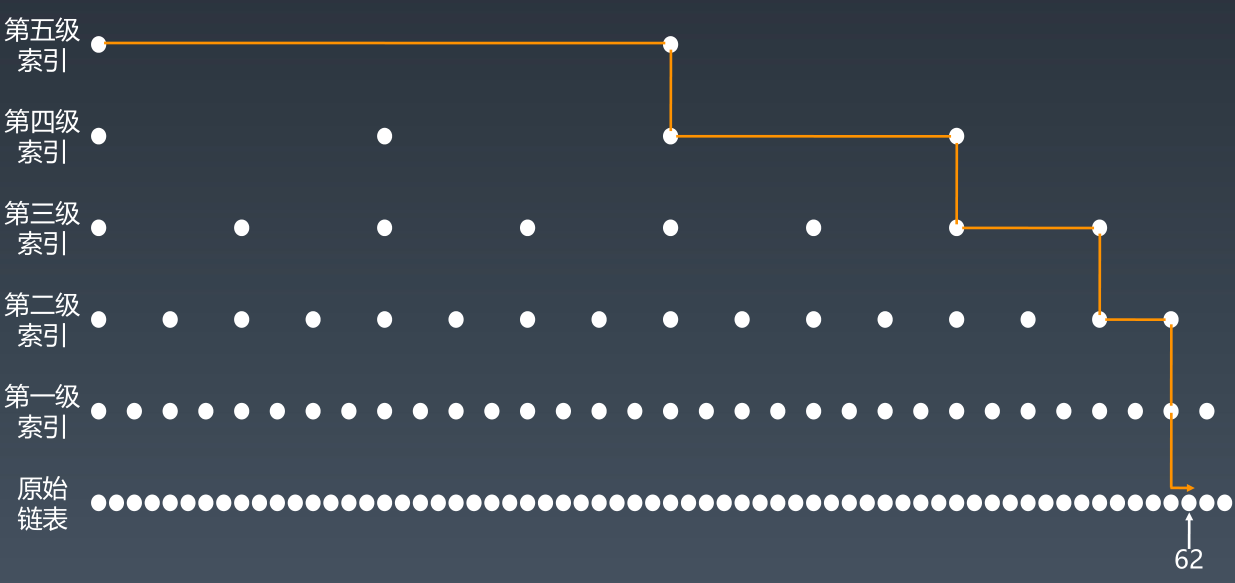
数组、链表、跳表对增、删、查时间复杂度比较:
数组链表跳表preppendO(n)O(1)O(logn)appendO(1)O(1)O(logn)lookupO(1)O(n)O(logn)insertO(n)O(1)O(logn)deleteO(n)O(1)O(logn)
4、栈(Stack)
Java中虽然提供了Stack类(内部维护的实际上也是一个数组)用于实现栈,但官方文档 https://www.apiref.com/java11-zh/java.base/java/util/Stack.html中明确说明,应该优先使用Deque来实现:
Deque<Integer> stack = new ArrayDeque<Integer>();
Deque接口及其实现,提供了一套更完整和一致的LIFO(Last in first out ,后进先出)堆栈操作,这里列举几个用于栈的方法:
public E peek():检索但不移除此双端队列表示的队列的头部(换句话说,此双端队列的第一个元素),如果此双端队列为空,则返回 null 。
public E pop:从此双端队列表示的堆栈中弹出一个元素。
public void push(E e):在不违反容量限制的情况下执行此操作, 可以添加元素到此双端队列表示的堆栈(换句话说,在此双端队列的头部),如果当前没有可用空间则抛出 IllegalStateException 。
ArrayDeque实现类中,实际上也是维护的一个数组,下面会对该类做进一步介绍。
5、队列(Queue)
Java中提供了实现接口Queue,源码为:http://fuseyism.com/classpath/doc/java/util/Queue-source.html ;参考文档:https://www.apiref.com/java11-zh/java.base/java/util/Queue.html。Java还提供了很多实现类,比如ArrayDeque、LinkedList、PriorityQueue等,可以使用如下方式来使用Queue接口:
Queue<String> queue = new LinkedList<String>();
Queue接口针对入队、出队、查看队尾操作提供了两套API:
第一套为,boolean add(E e) 、E element()、E remove(),在超过容量限制或者得到元素为null时,会报异常。
第二套为,boolean offer(E e)、E peek()、E poll(),不会报异常,而是返回true/false/null,一般工程中使用这一套api。
实现类LinkedList中实际维护的是一个双向链表,前面已经介绍过了。
6、双端队列(Deque)
Deque是Double end queue的缩写,参考文档:https://www.apiref.com/java11-zh/java.base/java/util/Deque.html。
Deque既提供了用于实现Stack LIFO的push、pop、peek,又提供了用于实现Queue FIFO(First In First Out:先进先出)的offer、poll、peek(add、remove、element等也有,这里仅列出推荐使用的),所以可以用于实现Stack,也可以用于实现Queue。同时,Deque还提供了全新的接口用于对应Stach和Queue的方法,如offerFirst/offerLast、peekFirst/peekLast,pollFirst/pollLast等,另外还提供了一个addAll(Collection c),批量插入数据。
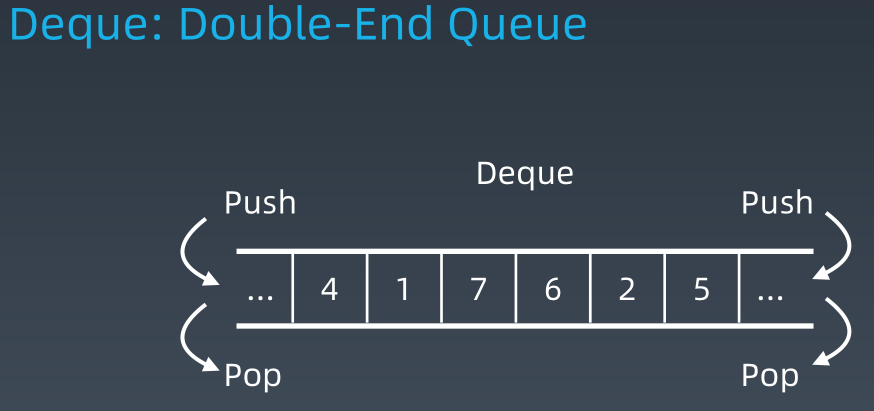
前面讲Stack的时候已经介绍过了,Deque是一个接口,一般在工程中的使用方式为:
Deque<Integer> deque = new ArrayDeque<Integer>();
ArrayDeque内部维护的是一个数组。
7、优先队列(PriorityQueue)
Java中提供了PriorityQueue类来实现优先队列,是接口Queue的实现类。和Queue的FIFO不同的是,PriorityQueue中的元素是按照一定的优先级排序的。默认情况下,其内部是通过一个小顶堆来实现排序的,也可以自定义排序的优先级。堆是一个完全二叉树,可以用数组来表示,所以PriorityQueue内部实际上是维护的一个数组。
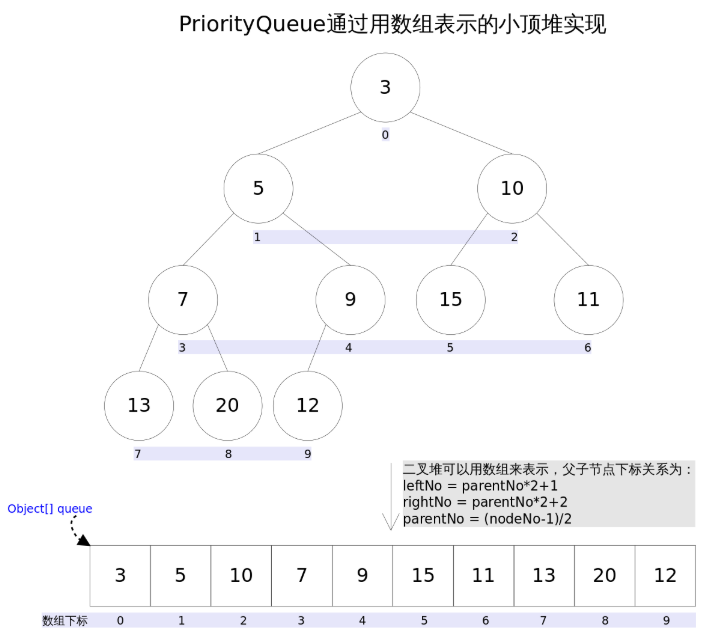
PriorityQueue提供了对队列的基本操作:offer用于向堆中插入元素,插入后会堆会进行调整;peek用于查看但不删除数组的第一个元素,也就是堆顶的元素,是优先级最高(最大或者最小)的元素;poll用于获取并移除堆顶元素,堆会再进行调整。当然,对应的还有add/element/remove方法,这在前面Queue部分讲过了。
8、哈希表(Hash Table)
哈希表也叫散列表,通过键值对key-value的方式直接进行存储和访问的数据结构。它通过一个映射函数将Key映射到表中的对应位置,从而可以一次性找到对应key-value结点的位置。
Java中提供了HashTable、HashMap、ConcurrentHashMap等类来实现哈希表,这三者也经常被拿来做比较,这里简单介绍一下这三个类:
HashTable:1)内部通过数组 + 单链表实现;2)主要方法都加了Synchronized锁,线程安全,但也是因为加了锁,所以效率比其它两个差;3)Key和Value均不允许为null;
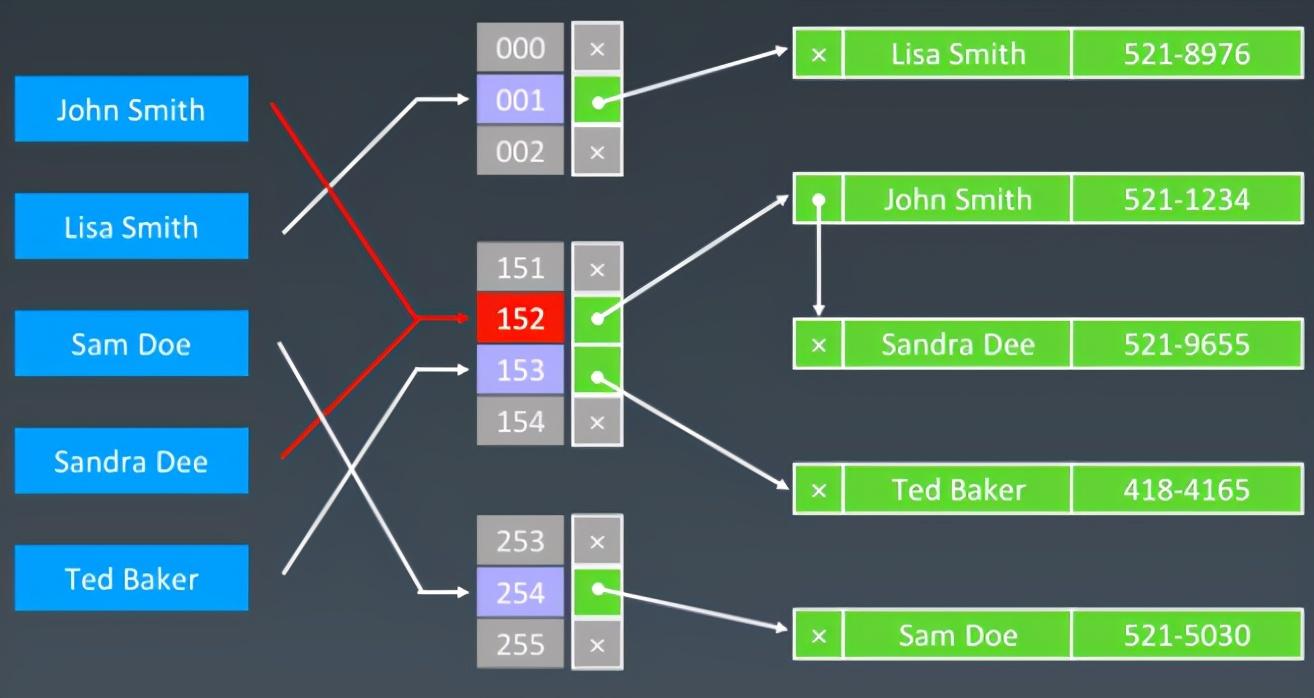
HashTable内部结构图
HashMap:1)Jdk1.7及之前,内部通过数组 + 单链表实现;Jdk1.8开始,内部通过 数组 + 单链表 + 红黑树实现 ;2)非线程安全,如果要保证线程安全,一般通过 Map m = Collections.synchronizedMap(new HashMap(...));的方式来实现,由于没有加锁,所以HashMap效率比较高;3)允许一个Key为null,Value也可以为null。
ConcurrentHashMap:分段加锁,相比HashMap它是线程安全的,相比HashTable它效率高,可以看成是对HashMap和HashTable的综合。
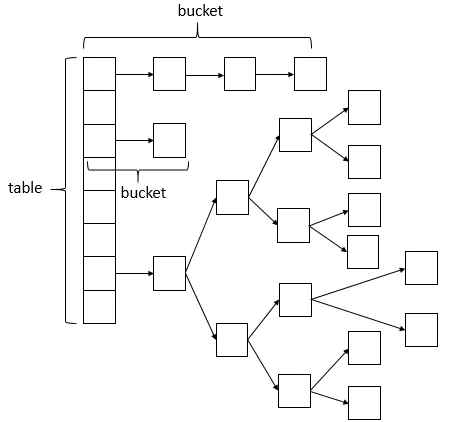
HashMap内部结构图
9、映射(Map)
映射中是以键值对Key-Value的形式存储元素的,其中Key不允许重复,但Value可以重复。Java中提供了Map接口来定义映射,还提供了如HashMap、ConcurrentHashMap等实现类,这两个类前面有简单介绍过
10、集合(Set)
集合中不允许有重复的元素,添加元素时如果有重复,会覆盖掉原来的元素。Java中提供了Set接口来定义集合,也提供了HashSet实现类。HashSet类的内部实际上维护了一个HashMap,将添加的对象作为HashMap的key,Object对象作为value,以此来实现集合中的元素不重复。
1 //HashSet部分源码 2 public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable { 3 ...... 4 private transient HashMap<E,Object> map; 5 private static final Object PRESENT = new Object(); 6 public HashSet() { 7 map = new HashMap<>(); 8 } 9 ......10 public boolean add(E e) {11 return map.put(e, PRESENT)==null;12 }13 ......14 public boolean remove(Object o) {15 return map.remove(o)==PRESENT;16 }17 ......18 }11、树(Tree)
在单链表的基础上,如果一个节点的next有一个或者多个,就构成了树结构,所以单链表是一棵特殊的树,其child只有一个。关于树有很多特定的结构,用于平时的工程中,出现得比较多得就是二叉树,而二叉树根据用途和性质又有多种类型,常见的有:
完全二叉树:若设二叉树的深度为k,除第 k 层外,其它各层 (1~k-1) 的结点数都达到最大个数,第k 层所有的结点都连续集中在最左边,这就是完全二叉树。完全二叉树可以按层存储在数组中,如果某个结点的索引为i,那么该结点如果有左右结点,那么左右结点的索引分别为2i+1,2i+2;
满二叉树:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且结点总数是(2^k) -1 ,则它就是满二叉树。所以,满二叉树也是完全二叉树。
二叉搜索树(Binary Search Tree):又称为二叉排序树、有序二叉树、排序二叉树等。其特征为:任意一个结点的左子树的值都小于/等于该结点的值,右子树的值都大于/等于根结点的值;中序遍历的结果是一个升序数列;任意一个结点的左右子树也是二叉搜索树。如下图所示:
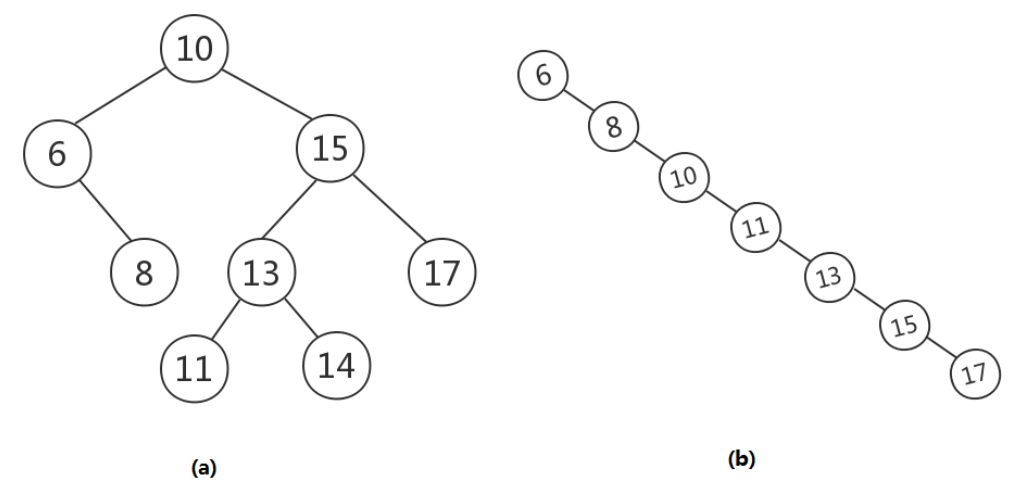
在极端的情况下,二叉搜索树会呈一个单链表。
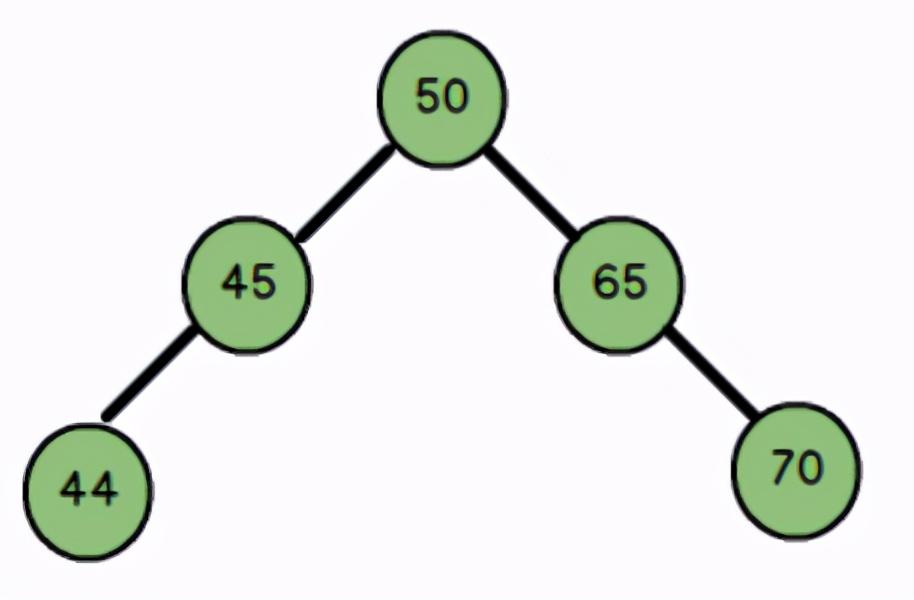
平衡二叉树(AVL):它或者是一颗空树,或它的左子树和右子树的深度之差(平衡因子)的绝对值不超过1,且它的左子树和右子树都是一颗平衡二叉树。平衡二叉树也是一棵二叉搜索树,由于具有平衡性,所以整棵树比较平衡,不会出现一长串单链表的结构,在查找时最坏的情况也是O(logn)。为了保持平衡性,每次插入的时候都需要调整以达到平衡。
如下图所示,任意一个结点的左右子树的深度差绝对值都不超过1,且符合二叉搜索树的特点:
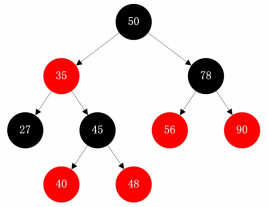
12、红黑树
红黑树是一颗平衡二叉搜索树,具有平衡性和有序性,结点的颜色为红色或者黑色。这里的“平衡”和平衡二叉树的“平衡”粒度上不同,平衡二叉树更为严格,导致在插入或者删除数据时调整树结构的频率太高了,这会导致一定的性能问题。而红黑树的平衡是任意一个结点的左右子树,较高的子树与较低子树之间的高度差不超过两倍,这样就能从一定层度上避免过于频繁调整结构。可以认为红黑树是对平衡二叉树的一种变体。
13、图(Graph)
单链表是特殊的树,树是特殊的图。
14、堆(Heap)
堆是一种可以迅速找到最大值或者最小值的数据结构,内部维护着一棵树(注意这里说的是树,而不是限制于二叉树,也可以是多叉)。如果该堆的根结点是最大值,则称之为大顶堆(或大根堆);如果根结点是最小值,则称为小顶堆(或小根堆)。堆的实现有很多,这里主要介绍一下二叉堆。
二叉堆,顾名思义,就是堆中的树是一棵二叉树,且是完全二叉树(这里要注意区别于二叉搜索树),所以可以用数组表示,前面介绍的PriorityQueue就是一个堆的实现。如果是大顶堆,任何一个结点的值都 >= 其子结点的值大;如果是小顶堆,则任何一个结点的值都 <= 其子节点的值。下图展示了一个二叉大顶堆,其对应的一维数组为[110, 100, 90, 40, 80, 20, 60, 10, 30, 50, 70]:
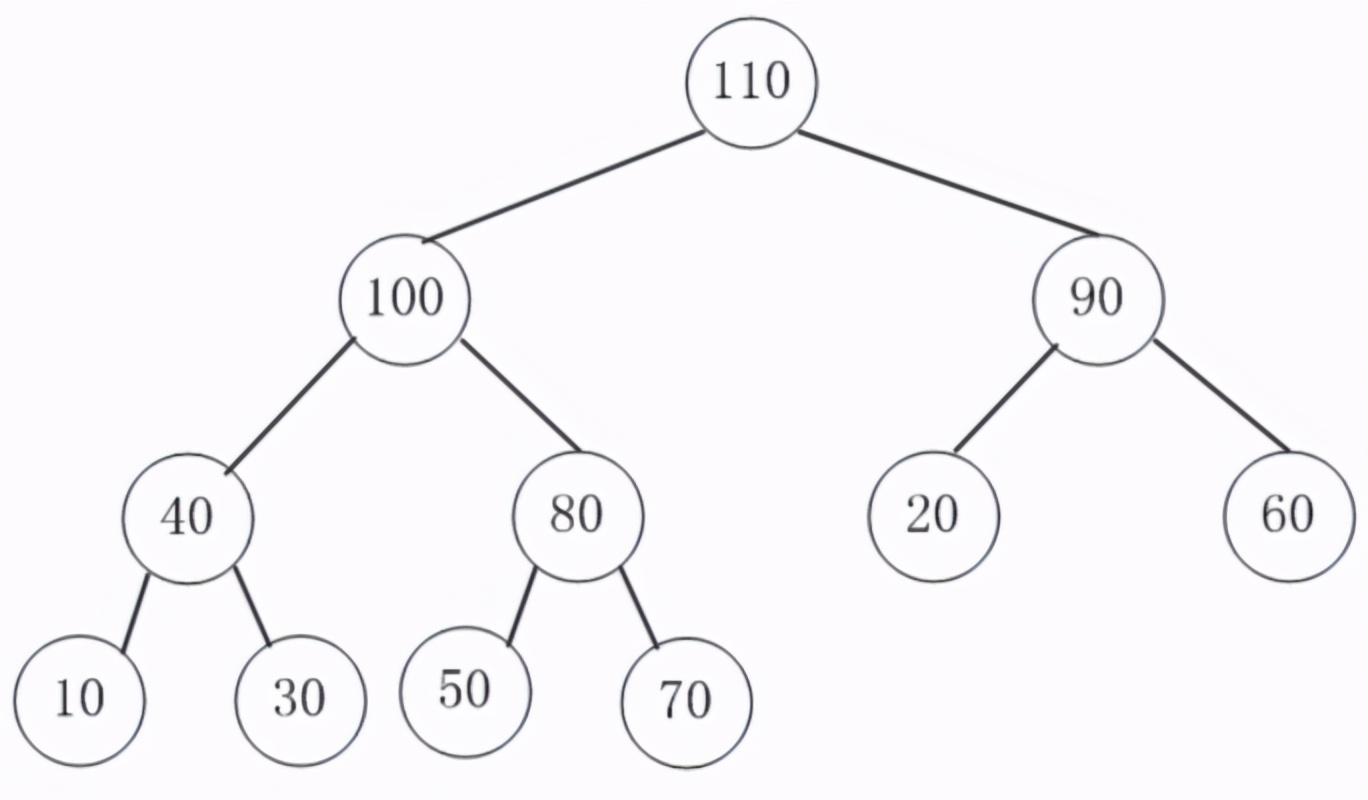
对于大顶堆而言,一般常使用的操作是查找最大值、删除最大值和插入一个值,其时间复杂度分别为:查找最大值的时间复杂度是O(1),因为最大值就是根结点的值,位于数组的第一个位置;删除最大值,找到最大值的时间复杂度是O(1),但是删除后该堆需要重新调整,将最底层最末尾的结点移到根结点,然后根节点再与子结点点比较,并与较大的结点交换,直到该结点不小于子结点为止,由于是从最末尾的结点直接升到根结点,所以该结点的值肯定是相对很小的,需要调整多次才能再次符合堆的定义,所以时间复杂度为O(logn);插入一个结点,其做法是在数组的最后插入,也就是二叉树的最后一个层的末尾位置插入,然后再和其父结点比较,如果新结点大就和父结点交换位置,直到不大于根结点为止,所以插入新的结点可能一次到位,时间复杂度为O(1),也有可能还需要调整,最坏的时候比较和交换O(logn),即时间复杂度为O(logn)。同理,小顶堆也是如此。
15、并查集(Disjoint Set)
并查集一般用于解决元素,组团或者配对的问题,即是否在一个集合的问题。它管理着一系列不相交的集合,主要提供如下三种基本操作:
(1)makeSet(s),创建并查集:创建一个新的并查集,其中包含s个单元素集合;
(2)unionSet(x,y),合并集合:将x元素和y元素所在的集合不相交,就将这两个集合合并;如果这两个结合相交,则不合并;
(3)find(x),查找代表:查找x元素所在集合的代表元素,该操作可以用于判断两个元素是否在同一个集合中,如果两个元素的代表相同,表示在同一个集合;否则,不在同一个集合。
如果想避免并查集太高,还可以进行路径压缩。
实现并查集的基本代码模板:
1 public class UnionFind { 2 private int count = 0; 3 private int[] parent; 4 5 //初始化并查集,用数组存储每个元素的父节点,一开始将他们的父节点设为自己 6 public UnionFind(int n) { 7 count = n; 8 parent = new int[n]; 9 for (int i = 0; i < n; i++) {10 parent[i] = i;11 }12 }13 14 //找到元素x所在集合的代表元素15 public int find(int x) {16 while (x != parent[x]) {17 x = parent[x];18 }19 return x;20 }21 22 //合并x和y所在的集合23 public void union(int x, int y) {24 int rootX = find(x);25 int rootY = find(y);26 if (rootX == rootY)27 return;28 parent[rootX] = rootY;29 count--;30 }31 }16、字典树(Trie)
字典树,即Trie树,又称为前缀树、单词查找树或者键树,是一种树形结构。Trie的优点是最大限度地减少无谓的字符串比较,查询效率比hash表高。其典型应用是统计字符串(不限于字符串)出现的频次,查找具有相同前缀的字符串等,所以经常被搜索引擎用于统计单词频次,或者关键字提示,如下图所示:
Trie树具有如下特性:
(1)结点本身不存储完整单词;
(2)从根结点到某一结点,路径上经过的字符串联起来,对应的就是该结点表示的字符串;
(3)每个结点所有的子结点路径代表的字符都不相同。
实际工程中,结点可以存储一些额外的信息,如下图就表示一棵Trie树,每个结点存储了其对应表示的字符串,以及该字符串被统计的频次。
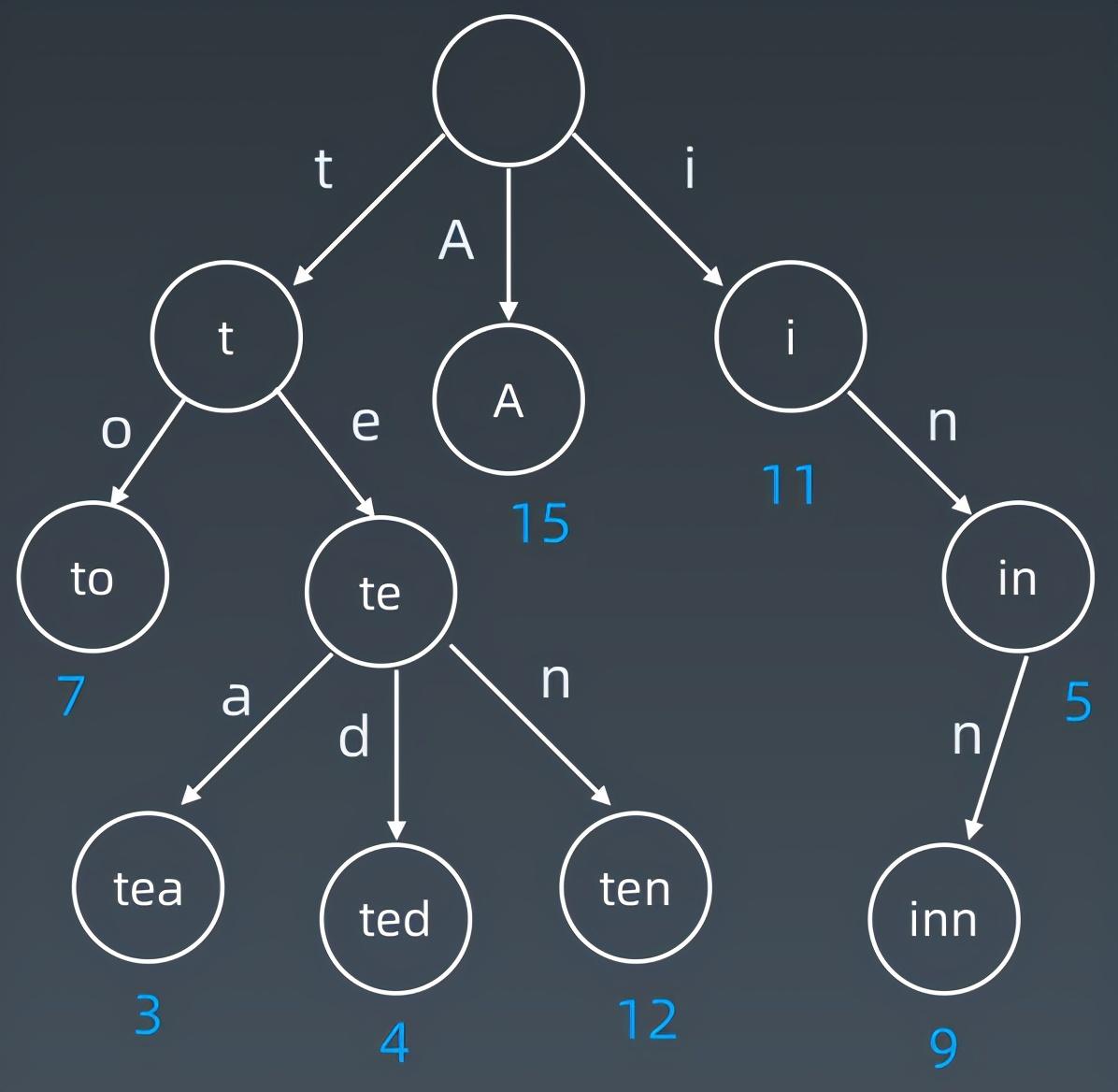
对于一个仅由26个小写英文字母组成的字符串形成的Trie树,其结点的内部结构为:
Trie树的核心思想是以空间换时间,因为需要额外创建一棵Trie树,它利用字符串的公共前缀来降低查询的时间的开销从而提升效率
17、布隆过滤器(Bloom Filter)
布隆过滤器典型应用有,垃圾邮件/评论过滤、某个网址是否被访问过等场景,它是由一个很长的二进制向量和一系列的hash函数实现的,其结构如下图所示:
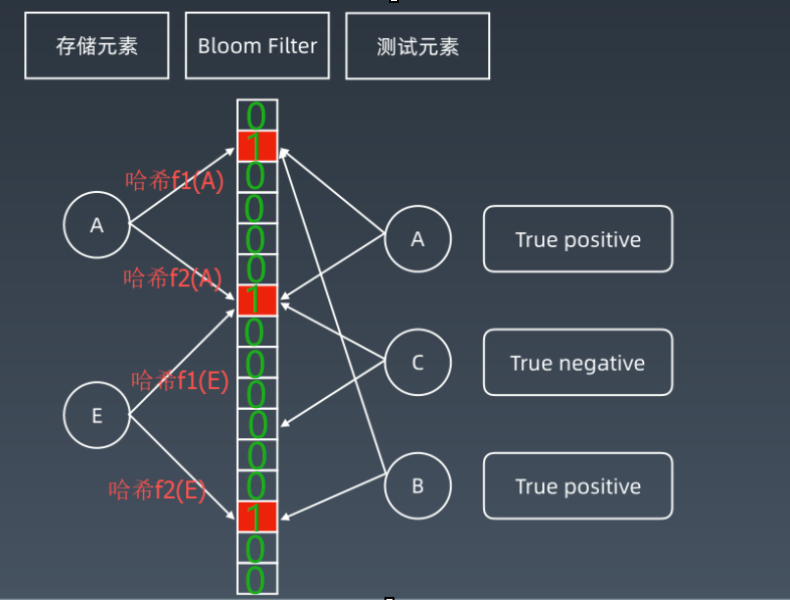
一个元素A经过多个hash函数(本例中是两个)计算后得到多个hash code,在向量表中code对应的位置的值就设置为1。
其具有如下特点:
(1)存储的信息是比较少的,不会存储整个结点的信息,相比于HashMap/HashTable而言,节约了大量的空间;
(2)如果判断某个元素不存在,则一定不存在;
(3)具有一定的误判率,而且插入的元素越多,误判率越过,如果判断某个元素存在,那只能说可能存在,需要再做进一步的判断,所以称为过滤器;
所以,其优点是空间效率和查询时间都远远优于一般的算法;缺点是具有一定的误判率,且删除元素比较困难(向量表中每一个位置可能对应着众多元素)。
18、LRU Cache
LRU,即Least Recently Used,最近最少使用,应用非常广泛,在Android的网络图片加载工具ImageLoader等中都具有使用。其思想为,由于空间资源有限,当缓存超过指定的Capacity时,那些最近最少使用的缓存就会被删除掉,其工作机制如下图所示:
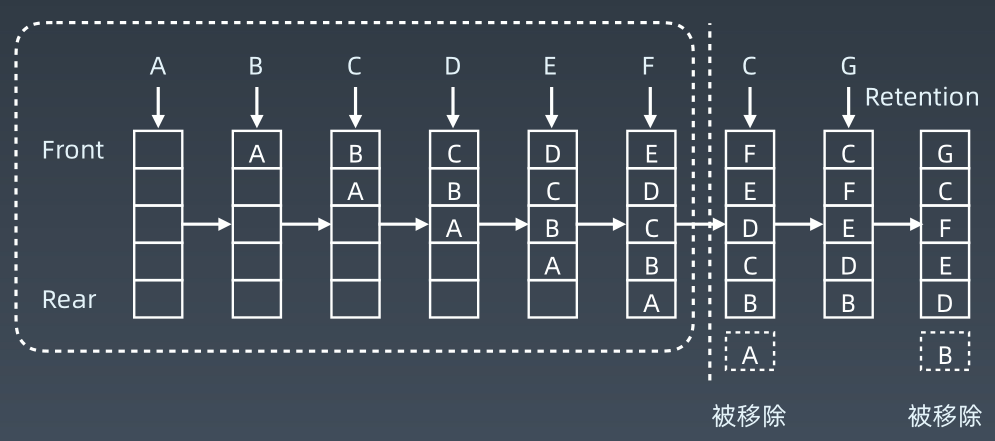
不同的语言中都提供了相应的类来实现LRU Cache,Java中提供的类为LinkedHashMap,内部实现思想为HashMap + 双向链表。我们也可以通过HashMap + 双向链表自己实现一个LRU Cache。
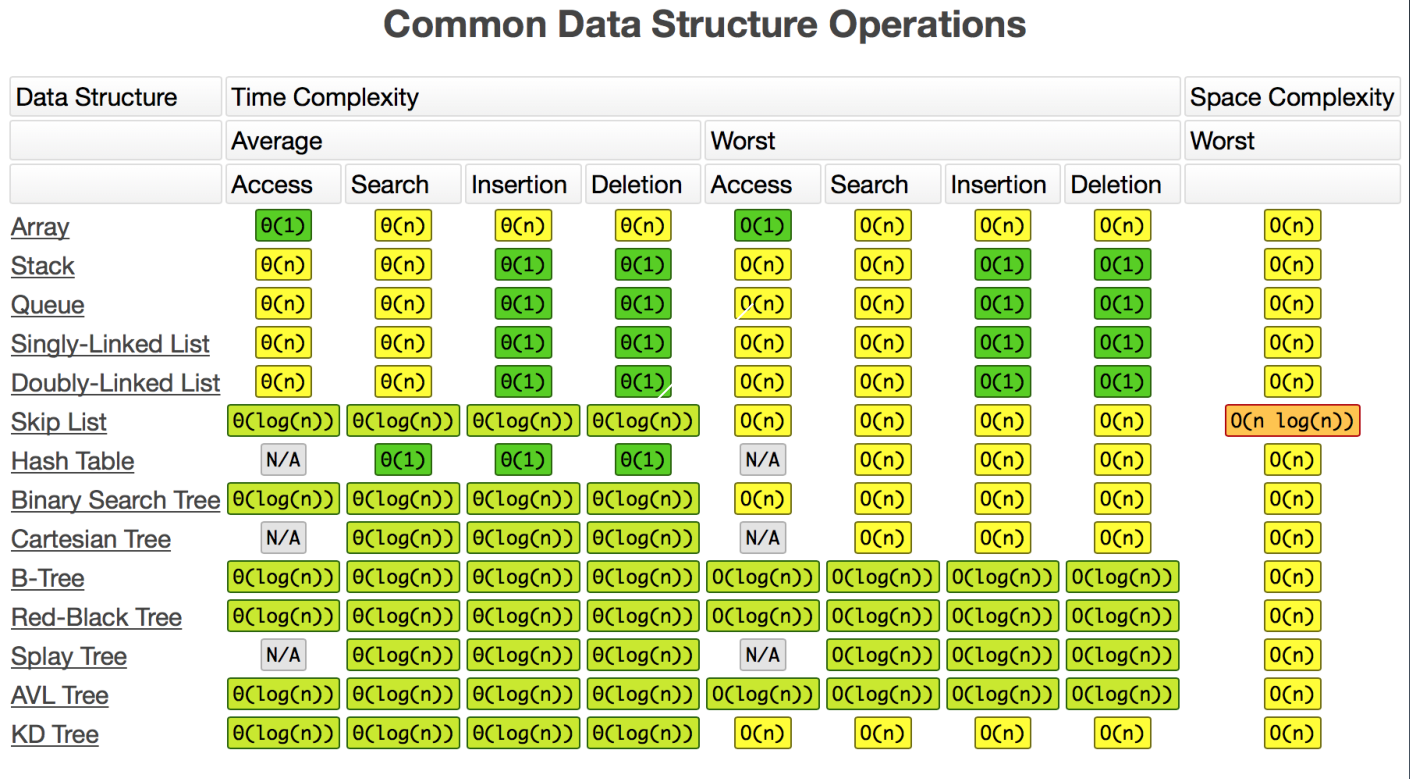
1 //空间复杂度O(k),k表示容量 2 //小贴士:在双向链表的实现中,使用一个伪头部(dummy head)和伪尾部(dummy tail)标记界限,这样在添加节点和删除节点的时候就不需要检查相邻的节点是否存在。 3 class LRUCache { 4 HashMap<Integer, LNode> cache = new HashMap<>();//使用hashmap可以根据key一次定位到value 5 int capacity = 0;//容量 6 int size = 0; 7 //采用双链表 8 LNode head; 9 LNode tail;10 11 public LRUCache(int capacity) {12 this.capacity = capacity;13 //初始化双链表14 head = new LNode();15 tail = new LNode();16 head.next = tail;17 tail.prev = head;18 }19 20 //时间复杂度:O(1)21 public int get(int key) {22 //先从缓存里面查,不存在返回-1;存在则将该节点移动到头部,表示最近使用过,且返回该节点的value23 LNode lNode = cache.get(key);24 if (lNode == null) return -1;25 moveToHead(lNode);26 return lNode.value;27 }28 29 //时间复杂度O(1)30 public void put(int key, int value) {31 LNode lNode = cache.get(key);32 //如果hashmap中不存在该key33 if (lNode == null) {34 size++;35 //如果已经超过容量了,需要先删除尾部节点,且从hashmap中删除掉该元素36 if (size > capacity) {37 cache.remove(tail.prev.key);38 removeNode(tail.prev);39 size--;40 }41 //将新的节点存入hashmap,并添加到链表的头部42 lNode = new LNode(key, value);43 cache.put(key, lNode);44 addToHead(lNode);45 } else {46 //如果hashmap中存在该key,则修改该节点的value,且将该节点移动到头部47 lNode.value = value;48 removeNode(lNode);49 addToHead(lNode);50 }51 }52 53 /**54 * 将节点移动到头部55 */56 public void moveToHead(LNode lNode) {57 removeNode(lNode);58 addToHead(lNode);59 }60 61 /**62 * 移除节点63 */64 public void removeNode(LNode lNode) {65 lNode.prev.next = lNode.next;66 lNode.next.prev = lNode.prev;67 lNode.next = null;68 lNode.prev = null;69 }70 71 /**72 * 在头部添加节点73 */74 private void addToHead(LNode lNode) {75 head.next.prev = lNode;76 lNode.next = head.next;77 head.next = lNode;78 lNode.prev = head;79 }80 }81 82 class LNode {83 int key;84 int value;85 LNode prev;86 LNode next;87 88 public LNode() {89 }90 91 public LNode(int key, int value) {92 this.key = key;93 this.value = value;94 }95 }最后附上一张常见数据结构的时间和空间复杂度表
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号