提升PostgreSQL查询性能:实战经验分享
发表时间: 2022-03-15 02:48
在过去的一年里,我学到了很多关于如何优化 PostgreSQL 性能的知识,在这篇文章中,我想分享一些关于如何充分利用我们的数据库的关键知识。
您是否曾收到您的团队或客户关于产品应用程序运行缓慢的问题?很可能你有。
在我的经验中,
数据库性能 == 应用程序性能导致数据库性能问题的最常见错误是 (1) 查询缺少索引或 (2) 未使用为查询创建的索引。
让我们考虑一个存储有关艺术家、他们的曲目和他们各自专辑的数据的数据库。

如果我想用 查询曲目Name = Levitating,我将使用以下查询:
SELECT * FROM Track WHERE Name='Levitating';数据库中的数据以数据页的形式存储在磁盘上。这些页面的结构类似于链表,因为它们包含一个数据部分和另一个部分用于指向下一个块的指针。这些块不需要以连续的顺序存储。
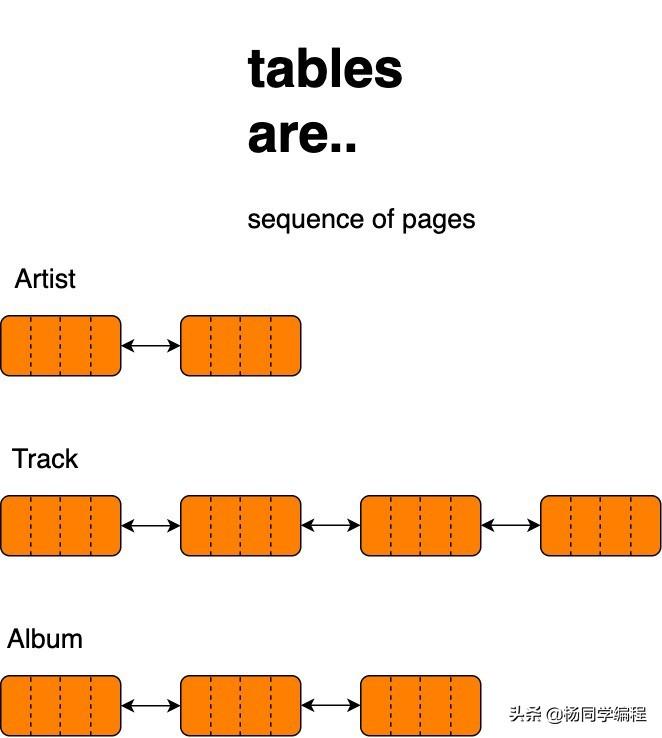
表格是一系列页面
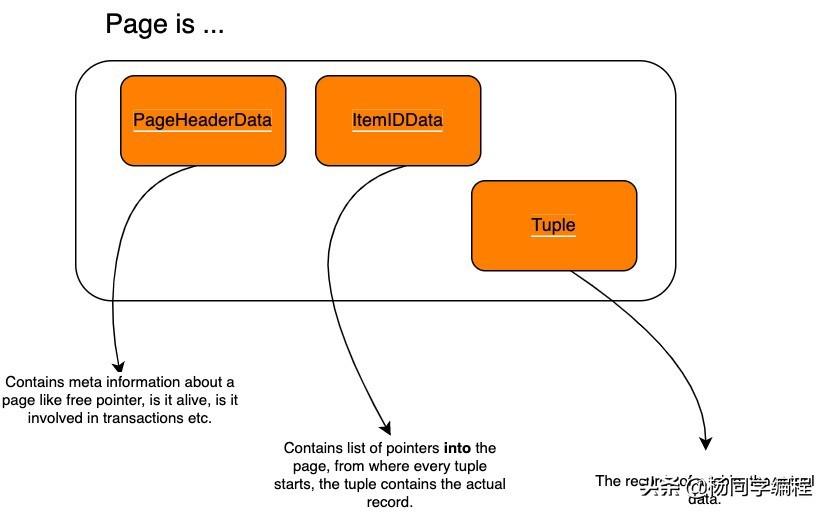
页面构成
当一条记录变得太大而无法存储在一个块中时,PostgreSQL 会将其存储在一张TOAST表中。记录将被分割成块,因此主表也称为堆将包含一个指向TOAST表中正确块的指针。
根据Track表的模式,一个块的Track数据部分将包含多个字段。记录只能在一个字段中排序这一事实,在这样的字段上搜索Name不是主键,因为Name它是一个非唯一字段,因此默认情况下不排序,搜索Name将需要全表扫描。
这意味着要使用上述查询找到轨道,Name=’Levitating’必须扫描所有约 1 亿行。那太疯狂了。需要几秒钟才能得到结果,这是对计算资源的不良使用和对环境的不良影响
索引是一种数据结构,通过向数据库客户端提供指向所请求记录的指针,可以更快地查询数据。一旦知道记录的位置,就可以通过查找确切的内存地址来快速获取数据。
底层查询协议允许数据库客户端批量获取结果,而不是一次全部获取。
让我们通过执行以下查询在表的Name字段上创建索引:Track
使用 btree(名称)在轨道上同时创建索引;索引被实现为 B 树。在剖析上述查询之前,我先让你深入了解一下 B-Trees。
B 树是为在磁盘上存储数据而创建的结构,其中访问内存位置大约需要 5 毫秒,因此,数据局部性是其设计的一个关键方面,它允许将多个值存储到每个树节点中。
由于 B 树的高分支因子,只需很少的磁盘读取即可到达存储数据的所需位置。
具有值的 B-Tree 节点m将最多具有m+1指向子节点的指针。每个指针都指向包含其两个父级之间的值的子树。
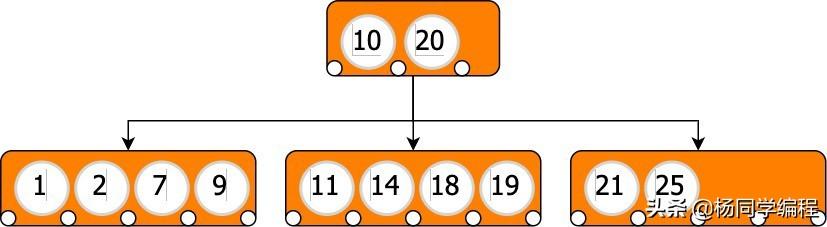
具有分支因子 3 的 B 树
在上面的 B 树中:
如果我想为5B-Tree 添加值,根节点的第一个子节点将发生拆分,结果树将转换为以下树:
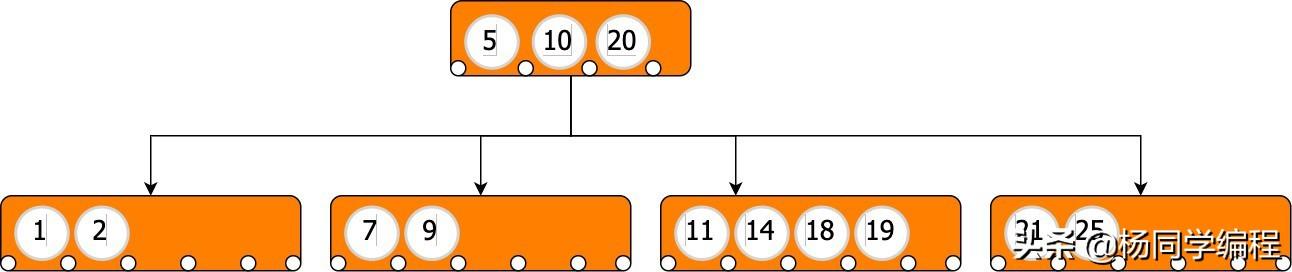
具有分支因子 4 的 B 树
分裂将孩子的中位数插入到父母中。这意味着分裂也会重新平衡树。
在上面的 B-Tree 中,插入5会导致拆分,将子节点的中值移动到父节点中,并且重新平衡会引入新的子节点。
这确保了二叉树的最大深度为log(m/2)n,其中m是分支因子,n是树中值的数量。
关于 B-Tree 需要注意的要点是:
创建列上的索引后,如果索引的 包含与查询中的列一起使用的运算符,则查询计划器将使用查询计划器使用该索引列对表的任何查询,以创建最佳查询执行计划。operator class
执行相同的查询,得到一个轨道,Name=’Levitating’再次以毫秒为单位产生结果,因为查询计划器将使用索引,并且能够通过两到三个磁盘读取找到所需数据的位置。此方案中使用的扫描将是索引扫描。
就像生活中所有美好的事物一样,索引是有代价的。虽然它们提供了速度,但需要空间来存储索引。这个空间的范围可以从兆字节到甚至千兆字节,有时取决于被索引的数据量。
您可以在多个字段上创建索引,也称为复合索引,并且您可以在同一个表上拥有多个索引,具体取决于该表所需的各种类型的查询。
因此,需要特别注意了解查询是如何在数据库上执行的,以及我们创建的索引是否被使用。
创建索引时需要考虑的几个非常重要的点:
命令中CONCURRENTLY使用的注意事项CREATE INDEX
当一个表被索引时,PostgreSQL 锁定表以防止写入。仍然可以执行读取操作,但写入、更新或删除操作被阻止。在大型表可能需要数小时才能建立索引的生产环境中,这可能是不希望的。
使用时CONCURRENTLY,不会阻塞写操作,PostgreSQL 将等待此类事务完成。由于允许继续正常操作,因此建立索引的时间也会随着数据库服务器的 CPU 和内存利用率而增加。
假设我们想要找出在数据库上运行的前三个慢查询。我们怎么能这样做呢?
从 pg_stat_statements ORDER BY total_time DESC LIMIT 3中选择 queryid、调用、mean_time、子字符串(查询 100) ;这将为我们提供前三个昂贵查询的列表:
| 查询ID | 来电 | 平均时间 | 子串 | |------------|-------|------------|-----------| | 1819595255 | 18000 | 500.12 | 查询 1 | | 10013512 | 100 | 273.25 | 查询 2 | | 50123753 | 3000 | 252.37 | 查询 3 |下一步是分析昂贵的查询并了解查询计划器是如何执行它们的。
EXPLAIN SELECT * FROM Album WHERE Name = 'Favourite Worst Nightmare'; 查询计划 ------------------------------------------------ ------------ Seq Scan on Album (cost=0.00..169375.85 rows=10000000 width=32) Filter: (Name = 'Favourite Worst Nightmare'::text)EXPLAIN提供查询计划器为给定查询生成的执行计划。执行计划显示查询引用的表将如何被扫描。
PostgreSQL 使用了多种扫描策略:
顺序扫描 — 表的所有页面都按顺序扫描。它基本上是线性搜索。顺序扫描发生在两种情况下:
WHERE1.子句中的键上没有可用的索引
2. 大多数行作为查询结果的一部分被返回
索引扫描 — 这是一个两步扫描。第 1 步是从索引中查询数据。索引返回主表或堆中数据的TID。第 2 步是直接访问堆页面以获取整个数据。
第 2 步是必需的,因为查询可能已请求获取比索引中可用的更多的列。
仅索引扫描 — 这类似于索引扫描,除了不需要第 2 步并且所有数据都从索引中获取。这是可用的最快扫描。有几个条件必须满足,这样 Query Planner 才能选择 Index Only Scan。您可以在wiki中阅读所有相关信息。
还有另外两种类型的扫描策略需要额外的上下文才能正确解释,也许我稍后会写一篇关于它们的文章。一种是Bitmap Scan,另一种是TID Scan。
不带任何选项使用EXPLAIN没有多大帮助;它不执行查询,只显示查询将如何执行的计划。
EXPLAIN与 一起使用时ANALYZE,将实际运行查询并显示计划和执行查询所花费的时间。在识别查询性能和瓶颈时,这些信息非常宝贵。
让我们看一下在创建EXPLAIN ANALYZE索引后执行第一个查询时的输出:Name
EXPLAIN ANALYZE SELECT * FROM Track WHERE Name='Levitating'; 查询计划 ------------------------------------------------ ---------------Index Scan using idx_name on Track (cost=0.00..32.97 rows=1 width=64) (实际时间=0.352..0.357 rows=1 loops=1) Index Cond: (Name='Levitating') Planning Time: 3.011 ms执行时间:0.379 毫秒查询计划表明使用的扫描策略是索引扫描,这是有道理的,因为我们正在查询可能不存在于索引中的行的所有列。
actual time=0.352..0.357访问第一行所花费的平均时间和读取所有行所花费的时间。
在我看来,EXPLAIN ANALYZE对于简单的查询,阅读 的输出是可以的,但是对于复杂的查询,就变得困难了。我遇到了一个名为explain.depesz.com的工具,它通过将输出分解为其组件并为查询执行的每个阶段提供统计信息来简化输出。
我强烈建议您在尝试查找慢速查询中的瓶颈时使用该工具。
好吧,我会在这里停下来。我真的很喜欢写这篇文章,也许我会写更多关于数据库的主题,比如:
直到下一次
如果您喜欢我的内容,请考虑分享它,如果我的帖子为您的提要增加了价值,请考虑订阅我的时事通讯:)。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号