后端产品经理的数据传输与写入心得
发表时间: 2018-10-08 10:07
在后端数据量大起来之后,大部分的工作都是在“玩数据”。就像一捧沙子,左手换到右手,右手指缝间分流而出,再由另一双手接住。所以作为产品经理,不仅要知道数据从哪来,还要理清楚获取数据之后的运算逻辑、异常规则,以及异常情况、数据日志等等。

本文继数据库之后,梳理了数据交互笔记,有兴趣的朋友可以一起交流。
(1)公司的后端数据之所以存在不同的数据库上,本质是为了解耦数据,提高单个数据库的运算速度。多个子系统之间的交互,其本质就是数据传输。
数据传输方式:MQ(队列)、http接口、otter、爬取、导入。
(2)MQ适用于公司内部,数据量大,规律性强,批量往来的数据。一般的配置是一方推出增量数据,另一方被动消费,像排队进厕所一样,不用设定频率。
(3)http接口是最常用的。叫 interface,也有的叫 protocol。
如果数据源是一缸水,那么接口就像是凿了一个口。所以接口必须是在数据源这边,由数据方定义接口。
接口规则就像过滤器一样,设定推送前的筛选、转化等运算规则,这就是接口的核心内容。
接口交互数据可以是主动推送,也可以是请求获取。
(4)接口定义是开发的事情,但产品需要确定出范围:
接口定义的规则是什么?传参和返回参数是什么?重复传参时是跳过还是再次获取(一般都再获取)?必传参数是什么?是否回传接收结果给数据生产方?
比如下图:每小时/次取对方表中第一页最新的50条数据。超过的数据下个小时继续取。
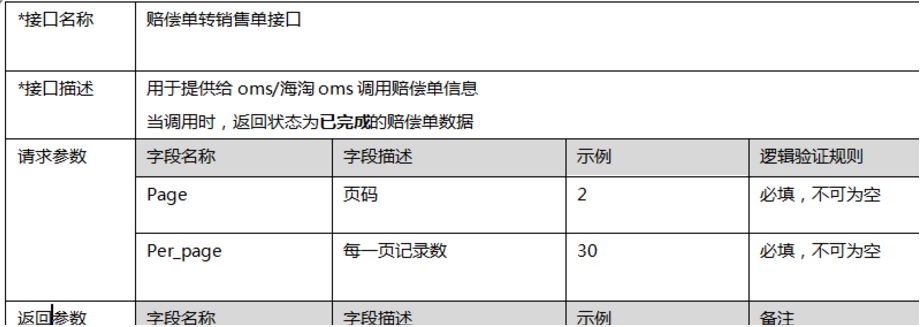
(5)确保接口获取的数据及时。
除了生产数据需要及时向下游推送之外,还有基础数据的更新也需要及时给下游同步,有时要做到同时。
方法是两种:触发式和定时脚本。
请求的频率需要与更新的频率相协调,比如:每次取6小时内更新的数据。每2小时取一次,则不会有问题。但是若每天取一次 就会有漏掉,也就是取数据的频率要高于更新频率。
(6)数据量大的时候,可以用otter:
otter 方法:
(7)爬取数据
一些第三方公司为了保密,会把文件存在网盘或网页上,比如:第三方支付公司与协议公司约定好账号密码,登录到SFTP筛选出需要的数据然后解析后保持到本地,这也实现了一个服务器之间的转移。
(8)导入:数据量大的,且有规则数据也可以通过导入的方式。
文档一般用csv格式,文件较小,兼容性好,然后需要定义好excel表格对应字段的关系即可。上传时需要对文件检验,建议方案是一旦一处错误,就全部不予导入。
(9)爬取第三方数据的防止丢包机制
案例:到SFTP服务器抓取并解析字段,写入数据表。
方案:
(1)先落地到中间表
如果获取后还要再本地进行规则运算,则最好先落地到中间表,再由中间表写入最终表。比如:从A系统获取的数据取到B系统,要进行分摊后再写入表。那么最好先落地到B系统的中间表,然后再由中间表写入目标表。
好处是,正向数据:可以异步处理,A——>中间表——>最终表,互相不影响。逆向数据:一旦数据异常,则方便追溯原因。
(2)去重规则:设置去重规则,以便再重复获取数据时更新、插入或者跳过
注意去重规则一旦改变,则需要考虑到历史数据对新数据的影响,因为二者的判重维度不一样,可能会有交叉。
(3)数据日志:目的是记录数据的来龙去脉,追溯以分析bug
产品经理告诉开发加日志,开发就会再后台加,因为log4j开源代码定义了5个主要级别的log:FATAL、ERROR、WARN、INFO、DEBUG,一般可以配置INFO或DEBUG级别的日志。如果需要保留的时间长,则可以将其保存到本地。
本地的需求可以展示给用户看,比如可以从以下维度展示:
(4)单进程锁
脚本执行的频率的时候,为保证数据是按单进程执行,不交叠,就要设置单进程锁。比如:一小时一次,8点没执行完 9点就不要执行。
另外在跑数据的规则上面,不要设置8点跑更新时间7点的,一旦小故障,就容易漏取。正确的要么是更新时间为当前之前更久的,要么就以状态来限定, 比如:取is_use为否的。
(5)同步基础数据的时候 是否提前过滤
比如:A系统维护了用户基础信息(其中有个状态为是否启用),B系统取用,但不做数据维护,只有启用状态的能用,那么是否只取启用状态的到B,还是两种状态都取。
答案是:在数据量差异不大的情况下,取全量。
原因之一:若启用状态的用户忽然被A系统禁用,那么可能该用户在B系统的生产数据报错,这时候到中间表看状态就可以看出来问题,而不需跨系统或跨部门沟通查证。
本文由 @ 环滁皆山也 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Pexels,基于 CC0 协议
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号