从零开始:Swift语言在数据科学中的应用
发表时间: 2019-11-10 13:09
Python被广泛认为是数据科学中最好、最有效的语言。近年来我遇到的大多数调查都将Python列为这个领域的领导者。
但事实是数据科学是一个广阔并且不断发展的领域。我们用来构建数据科学模型的语言也会随之发展。还记得R是什么时候的流行语言吗?它很快就被Python超越了。Julia语言去年也出现在数据科学中。目前现在有另一种语言正在蓬勃发展。
是的,我说的是Swift语言。

"我总是希望当我开始学习一门新语言的时候,会有一些开阔思维的新想法,这点Swift绝对不会让我失望。Swift易于解释,并且灵活,简洁,安全,易于使用,快速。大多数其他语言在这些方面都有很大的限制。"——Jeremy Howard
当Jeremy Howard认可一种语言并开始在日常的数据科学工作中使用该语言时,你有必要开始思考这个语言的优点了。
在本文中,我们将了解Swift作为一种编程语言,以及它如何适应数据科学领域。如果你是Python用户,你将注意到两者之间的细微差别和惊人的相似之处。这里也有很多代码,让我们开始吧!
PyTorch是为了克服Tensorflow中的限制。但现在我们正接近Python的极限,而Swift有可能填补这一空白。"——Jeremy Howard
最近,Swift作为一种数据科学语言引起了很多人的兴奋和关注。每个人都在谈论它。以下是你应该学习Swift的几个理由:
以下是Jeremy Howard对Swift的评价视频
:https://youtu.be/drSpCwDFwnM
在我们开始使用Swift执行数据科学的细节之前,让我们简要介绍一下Swift编程语言的基础知识。
2.1 Swift的生态系统
当前数据科学的Swift主要由两个生态系统组成:
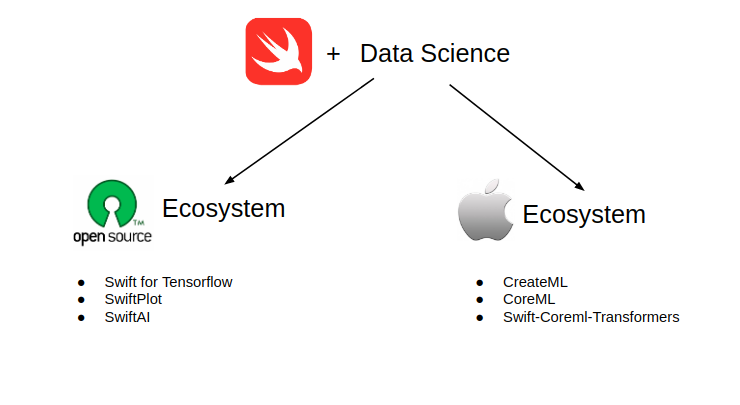
开源生态系统是我们可以下载并在任何操作系统或机器上运行Swift的地方。我们可以使用非常酷的Swift库来构建机器学习应用程序,比如用于TensorFlow的Swift、SwiftAI和SwiftPlot。
Swift还允许我们无缝地从Python中导入成熟的数据科学库,如NumPy、panda、matplotlib和scikit-learn。
另一方面,苹果的生态系统本身就令人印象深刻。有一些有用的库,比如CoreML,可以让我们用Python来训练大型模型,并直接将它们导入到Swift中进行推理。此外,它还提供了大量的预先训练过的先进模型,我们可以直接使用它们来构建iOS/macOS应用程序。
还有其他有趣的库,比如swift ,coreml,transformer,可以让我们在iPhone上运行最先进的文本生成模型,比如GPT-2、BERT等。
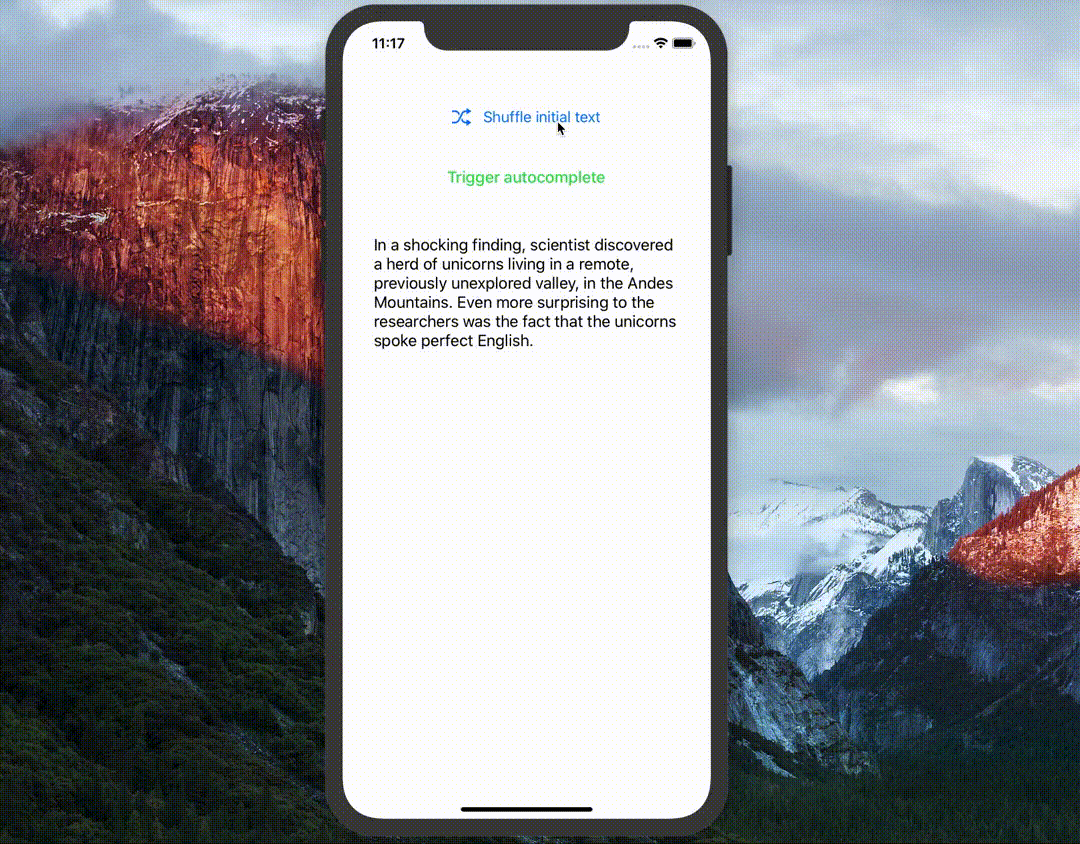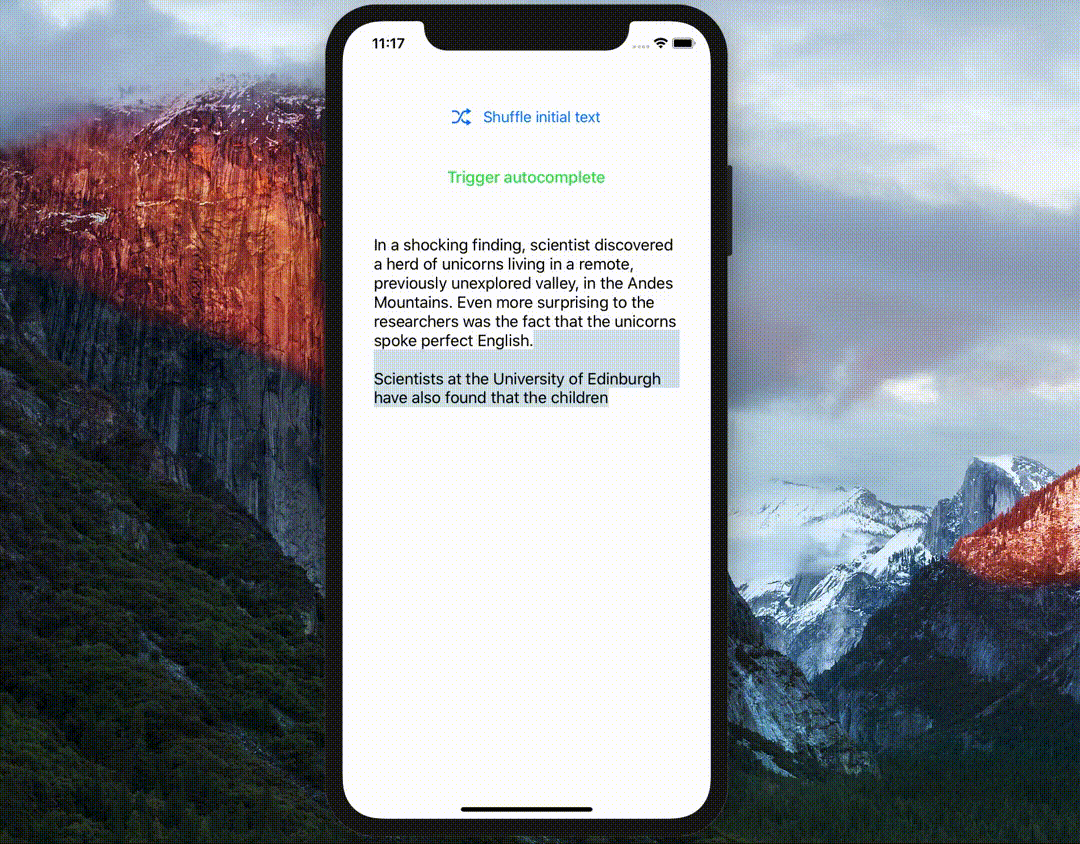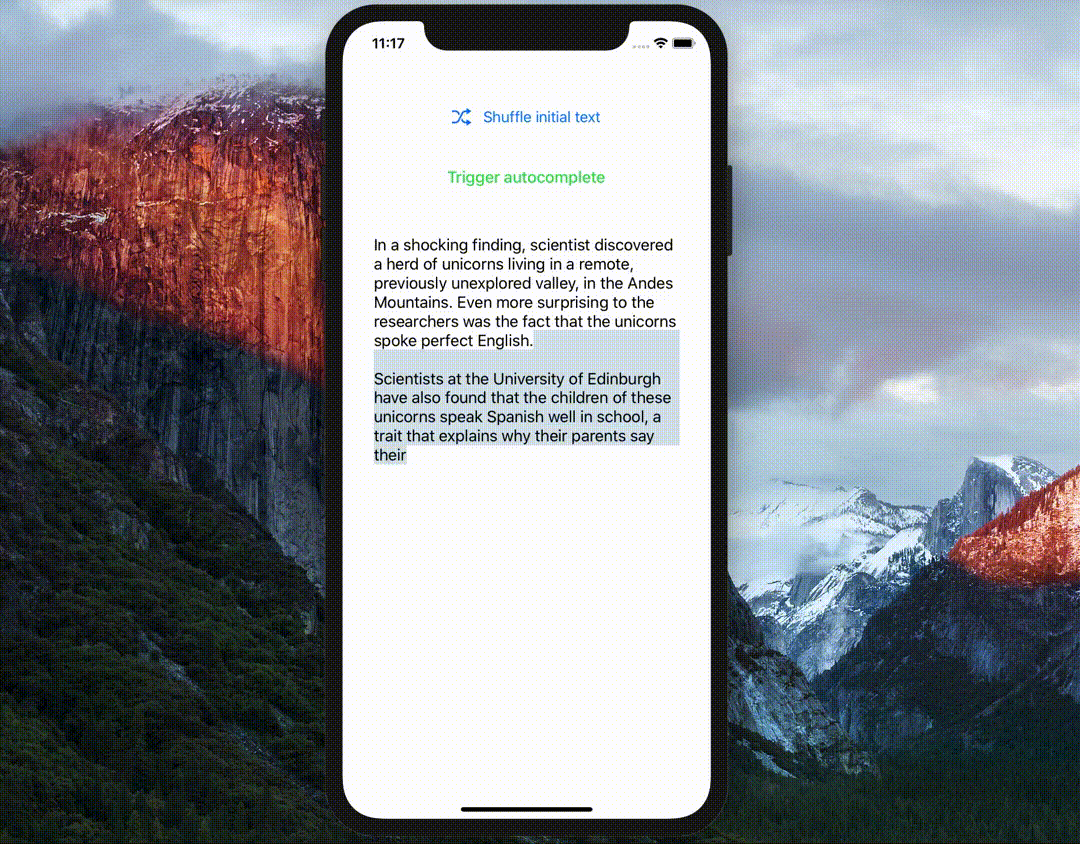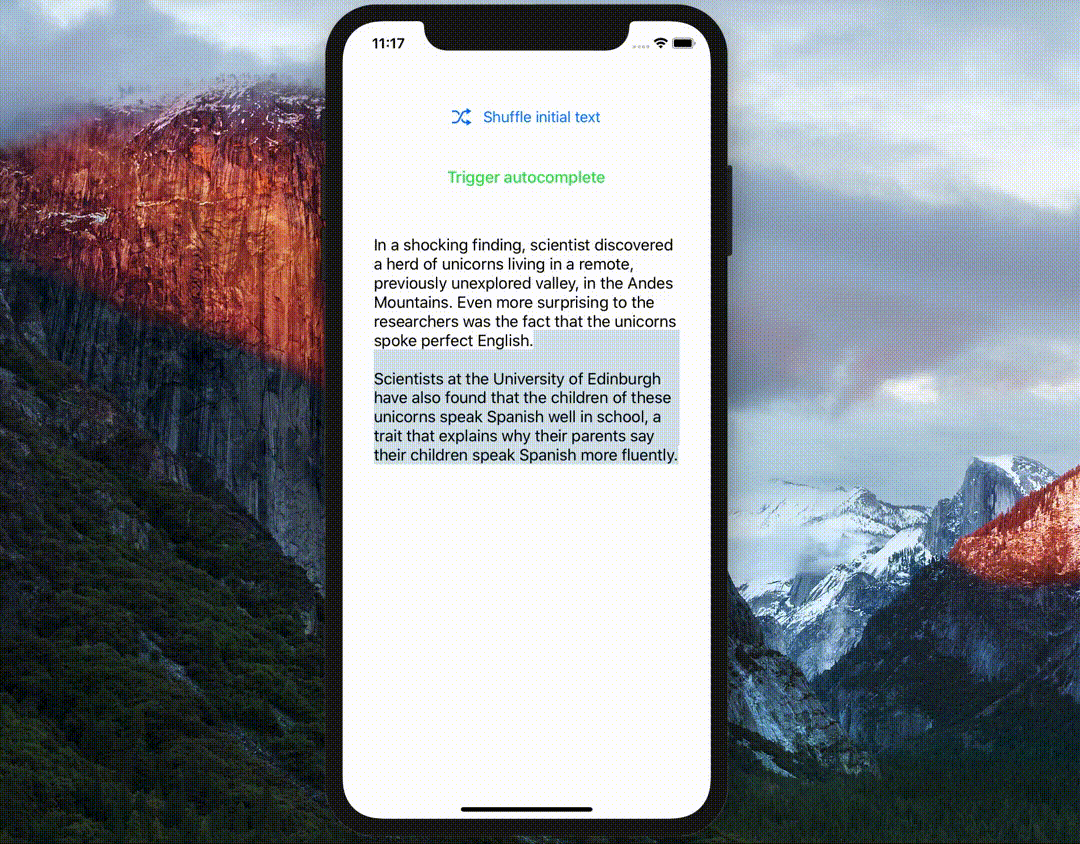
当你需要为Apple设备构建基于机器学习的应用程序时,还有许多其他的库可以提供良好的功能。
这两个生态系统之间存在多种差异。但最重要的是,为了使用苹果的生态系统,你需要有一台苹果的机器,你只能为苹果的设备开发,如iOS, macOS等。
既然你已经有了Swift作为数据科学语言的概述,让我们进入代码吧!
2.2 为Swift设置环境
Swift可用于谷歌Colab与GPU和TPU版本。我们将使用它,以便你可以快速跟上它的速度,而不必在安装过程中花费太多时间。

你可以按照下面的步骤打开一个Colab笔记本,这是快速激活的:
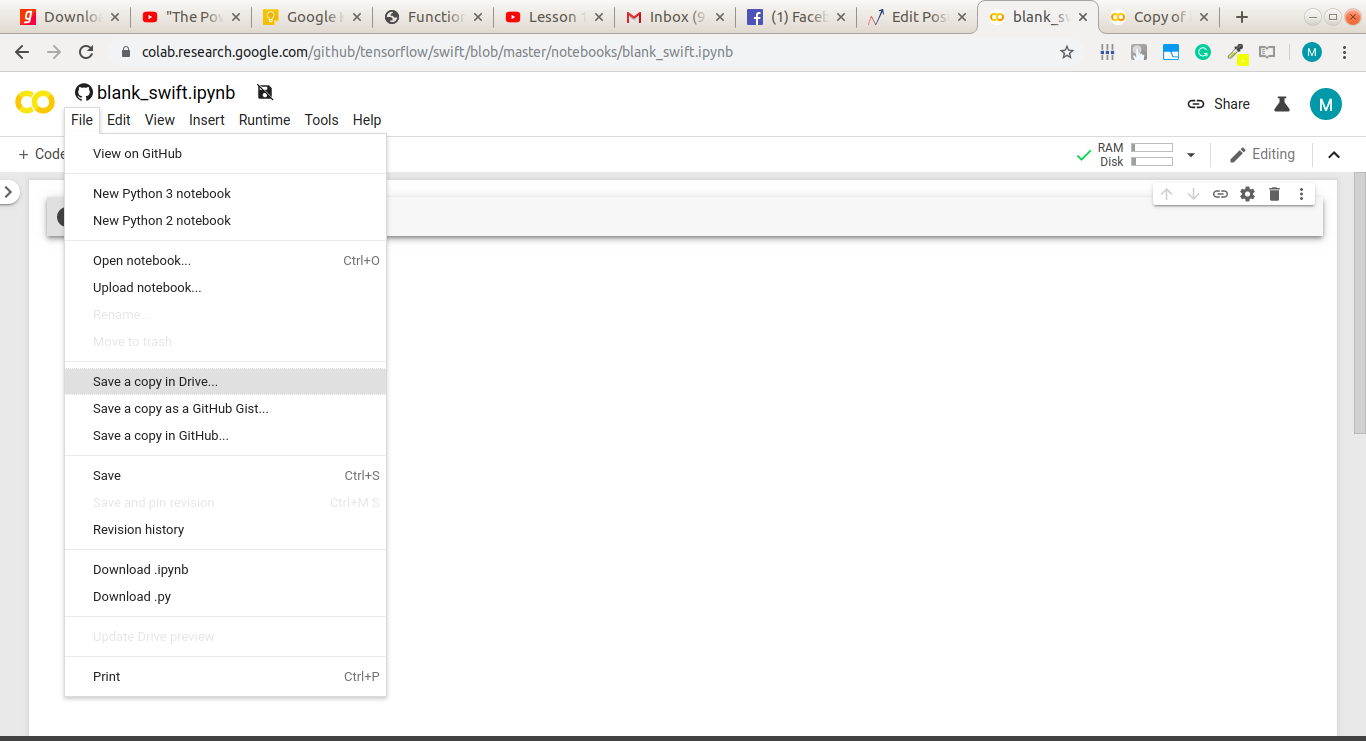
如果你想在你自己的系统上使用Swift,那么这里有一些你可以打开的链接:
现在,让我们快速介绍一下一些基本的Swift函数,然后再进入使用它的数据科学功能。
2.3 打印功能
我相信你用过这个。它的工作方式与Python中非常相似。只需调用print(),在括号内输入你想打印的内容:
2.4 Swift的变量
Swift提供了两个有用的选项来创建变量:let和var. let用来创建一个"常量",这个常量的值在程序的任何地方都不能改变。var与我们在Python中看到的变量非常相似——你可以在程序的任何时候更改存储在其中的值。
让我们看一个例子来看看区别。创建两个变量a和b:
现在,尝试改变a和b的值:
你会注意到,b能够不报错的更新其值,而a则给出一个错误:

这种创建常量与变量的能力非常有用,可以帮助我们防止代码中出现看不见的bug。你将在本文中进一步看到,我们将使用let来创建存储重要信息并且不需要变更值的常量,
这里有一个技巧:使用var来创建你想使用一些中间计算的结果,因为这些中间计算结果需要改变。类似地,使用let来存储训练数据或者结果,这些数据基本上就是你不想更改或弄乱的值。
此外,Swift还有一个很酷的功能,你甚至可以使用表情符号作为变量名!

这是因为Swift非常支持Unicode,所以我们可以用希腊字母来创建变量:
2.5 Swift的数据类型
Swift支持所有常见的数据类型,如整数、字符串、浮点数和双精度。我们可以赋值给任何变量,其类型会被Swift自动检测到:
你还可以在创建变量时显式地编写数据类型。这有助于防止程序中的错误,因为如果类型不匹配。Swift将抛出一个错误:
可以做个小测验。创建一个显式类型为"Float"的值为4的常量,结果是会报错的。
有一种简单的方法可以将变量的值包含在字符串中,方法是将变量放在括号中,并在括号前写入反斜杠()。例如:

可以对占用多行的字符串使用三个双引号(""")。
2.6 列表和字典
Swift支持列表和字典数据结构,就像Python一样(这又是一个比较!)这里与Python不同,我们不需要像字典的"{}"和列表的"[]"这样的单独语法。
让我们用Swift创建一个列表和字典:
我们可以通过在"[]"括号内写入索引或者键来访问列表或字典的元素(类似于Python):
上面的代码将把"Jayne"和"Public Relations"的键值对添加到字典中。如果你打印以上的字典以下就是输出:
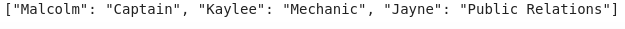
2.7 使用循环
循环是任何编程语言最重要的特性之一,Swift不会让你失望。它不仅支持所有传统的循环机制(for、while等),而且还实现了它自己的一些变体。
for..in 循环
非常类似于Python,你可以使用在Swift中的list或者range使用for循环:

第一个例子中的三个点表示Swift中的"range"。如果我们想做a到b范围内的事情,我们会使用a…b的语法。
类似地,如果我们想不要最后一个数字,我们可以把这三个点改成"..<"像"a.."。
这里需要注意的另一点是,与Python不同,Swift不使用缩进的概念,而是使用花括号"{}"来表示代码层次结构。
你可以在Swift中以类似的方式使用while和其他类型的循环。你可以这里了解更多关于循环的信息:
https://docs.swift.org/swift-book/LanguageGuide/ControlFlow.html。
2.8 条件(if-else)
Swift支持条件语句,如if, if..else, if..else..if, 嵌套if甚至switch语句(Python不支持)。if语句的语法非常简单:
boolean_expression可以是任何比较,只有在比较结果或表达式的计算结果为true时,才会执行if块中编写的语句。你可以在这里阅读其他条件语句
:https://docs.swift.org/swift-book/LanguageGuide/ControlFlow.html。
2.9 函数
Swift函数在语法上与Python中的函数非常相似。这里的主要区别是我们使用了func关键字而不是def,并且我们明确地提到了参数的数据类型和函数的返回类型。
一个基本的函数如下:

和条件语句一样,我们使用花括号"{}"来表示属于这个函数的代码块。
2.10 用代码编写注释
编写注释是优秀代码最重要的方面之一。这适用于任何行业。这是你应该学习的最重要的编程技巧!
在你的代码里包含注释文本,作为对自己的注释或提醒。注释在编译时会被Swift忽略。
单行注释以两个斜杠(//)开头:
多行注释以一个前斜杠和一个星号(/*)开始,以一个星号和一个前斜杠(*/)结束:
现在你已经熟悉了Swift的基础知识,让我们来学习一个有趣的功能——在Swift中使用Python库!
Swift支持与Python的互操作性。这意味着你可以从Swift导入有用的Python库,调用它们的函数,并在Swift和Python之间无缝地切换。
这给了Swift的数据科学生态系统不可思议的力量。这个生态系统还很年轻,还在发展中,你已经可以使用成熟的库,如Numpy、panda和Python的Matplotlib来填补现有Swift产品的空白。
为了在Swift中使用Python的模块,你可以直接导入Python并加载任何你想要使用的库!
这与你在Python中使用NumPy的方式非常相似,不是吗?你可以对其他包做同样的事情,如matplotlib:
你已经学了不少关于Swift的东西。现在是时候构建你的第一个模型了!

Swift4Tensorflow是Swift开源生态系统中最成熟的库之一。我们可以使用一个非常简单的keras类语法很容易的建立机器学习和深度学习模型。
它变得更加有趣!Swift4Tensorflow不仅仅是对TensorFlow的快速包装,它还被开发为该语言本身的一个特性。人们普遍认为,在不久的将来,它将成为该语言的核心部分。
这意味着来自苹果公司的Swift团队和谷歌的Tensorflow团队的工程师将确保你能够在Swift中进行高性能的机器学习。
该库还向Swift添加了许多有用的特性,比如对自动微分的原生支持(这让我想起了PyTorch中的Autograd),从而使它与数值计算更加兼容。

4.1 关于数据集
让我们来理解一下我们将在本节中使用的问题陈述。如果你以前接触过深度学习领域,你可能对它很熟悉。
我们将构建一个卷积神经网络(CNN)模型,使用MNIST数据集将图像分类为数字。该数据集包含6万张训练图像和1万张手写数字测试图像,可用于训练图像分类模型:

这个数据集是处理计算机视觉问题的一个相当常见的数据集,所以我不打算详细描述它。
4.2 开始项目
在开始构建模型之前,我们需要下载数据集并对其进行预处理。为了方便你,我已经创建了一个GitHub存储库,里面预处理了代码和数据
下载安装代码,下载数据集,导入必要的库:
你的数据集现在将在Colab上下载。让我们加载数据集:
4.3 加载数据集
4.4 探索MNIST
我们将从数据集绘制一些图像,以了解我们的工作是什么:
这是我们的图像是这样的:
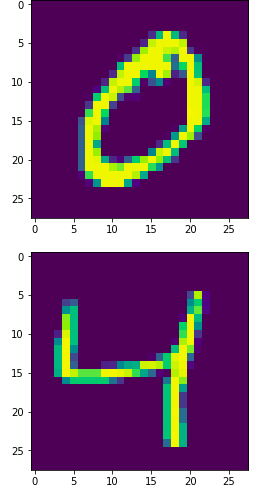
看起来很直观,对吧?第一个数字是手写的0,第二个数字是4。
4.5 定义模型的结构
现在让我们定义模型的体系结构。我使用的是LeNet-5架构,这是一个非常基础的CNN模型,使用了2个卷积层,平均池化层和3个全连接层。
最后一个全连接层的形状是10,因为我们有10个目标类,每个数字一个从0到9:
你可能已经注意到,这些代码看起来非常类似于Keras、PyTorch或TensorFlow等Python框架中。
编写代码的简单性是Swift最大的卖点之一。
Swift4Tensorflow你可以在这里阅读更多关于它的信息:
https://www.tensorflow.org/swift/api_docs/Structs
4.6 选择梯度下降作为优化器
类似地,我们需要一个优化器函数来训练我们的模型。我们将使用Swift4Tensorflow中提供的随机梯度下降(SGD):
Swift4Tensorflow支持许多额外的优化器。你可以根据你的项目选择:
4.7 模型训练
现在一切都设置好了,让我们来训练模型!
上面的代码运行一个训练循环,该循环将数据集示例提供给模型,以帮助它做出更好的预测。以下是我们的训练步骤:
epochCount变量是遍历数据集集合的次数。
你花了多少epoch才在测试集上达到90%以上的准确率?
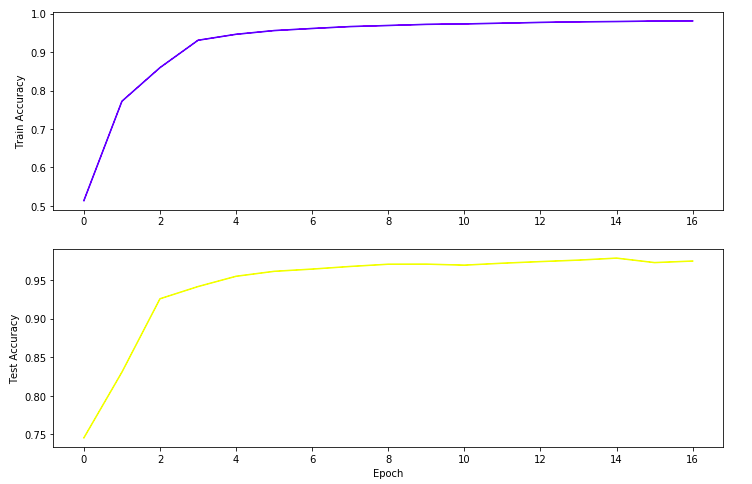
我在12个epoch内,在训练和测试集的准确率都达到了97%以上。

4.8 可视化训练和测试数据
虽然打印出模型的训练进度很有帮助,但是看到可视化图像通常更有帮助。
让我们将在模型训练期间捕获的训练和测试统计数据可视化。
这是训练和测试精度在训练过程中的演变过程:
行业专家们对Swift的反应是令人难以置信的,感觉它不仅有潜力成为数据科学的主流语言,而且它也是用于在现实世界构建基于机器学习的应用程序。
目前,它还处于起步阶段,围绕数据科学和数值计算的库仍在发展中。然而,它背后有强大的行业支持,我期待着未来它将拥有一个丰富的工具和库生态系统(甚至可能比现在的Python更好)。
这里有几个Swift的库,你可以进一步探索:
Swift AI:这是一个完全用Swift编写的高性能深度学习库。Github链接
:https://github.com/Swift-AI/Swift-AI
本文中使用的所有代码都可以在Github上找到:
https://github.com/mohdsanadzakirizvi/swift-datascience
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号