OpenAI Whisper:突破性的语音转写工具体验分享
发表时间: 2024-07-17 09:50
速记员这个职业大家都不陌生,他们能在各类场合高效迅速地将演讲内容转化为会议记录。如果把速记员变成软件,其核心功能就是语音识别 + 转写。这类需求使用场景广泛,在线视频 AI 字幕、线上会议 / 网课的速记、生肉番剧 / 电影 / 歌曲字幕的制作和转译、通话录音等等,都会用到。
速记的精髓在于速度,快最重要,但在很多场景中,无论是人力还是软件,都无法达到超快的转写速度和准确率,而满足专业用户高效转写需求的工具,往往需要付费获取。如某品牌的语音转写畅想包订阅费用是 79 元连续包月,599 元 / 年;另一款则需要注册企业用户,然后找客服咨询费用标准,据说标准版费用是每个用户 199 元 / 年,高级版费用则是每个用户 299 元 / 年。
对企业 / 专业用户来说,付费订阅软件一定最佳选择,它们的速度快、无需高性能硬件成本(GPU)、准确率高、支持人工精校,肯花钱甚至可获得一对一的专属客服支持,但如果只是偶尔使用性价比就不是很高了。
另外,这些订阅软件的 AI 服务,通常需要用户将原始的视频或音频文件上传到服务器和全程联网,且通过厂商的专业设备在云端运行,如果视频或音频文件中包含个人隐私 / 商业等内容,显然也不太合适。
那有没有一款完全免费开源,不需要联网,完全依赖本地硬件算力去跑语音识别和转写,准确率还不低的语音转写软件呢?或许喜欢关注 AI 领域的朋友早就有了答案,它就是来自的 OpenAI 团队所开发的 Whisper。从官网的介绍文章日期上不难看到,Whisper 早在 2022 年 9 月就已经推出,但时至今日它依旧是最好用的免费语音转写工具。
说它最好用原因有三点,一是它的语种支持广泛(99 种),二是转写速度超快,三是识别准确性很高,且只需要一张高性能显卡就能办到,这几点我都会在后面的体验中给大家详细分析。
先给大家简单科普下 Whisper,它是一个多模态语音识别模型,基于 Transformer 引擎所打造,通过了 68 万个小时的语音数据训练,支持 99 种语言(包括中文),在具备语音识别能力的同时,还支持语音活性检测(VAD),声纹识别,说话人日志 (Speaker Diarization,即在多人对话场景下检测不同人物的说话时间段),语音翻译(翻译为英文),语音对齐等能力,其英文识别准确率非常强悍。
而上面所提到的 Transformer 引擎,恰好 NVIDIA 在 RTX 40 系列显卡上引入了一个针对 AI 计算的新硬件特性,具体来说 RTX 40 系显卡增加了对 FP8 低精度浮点数的支持,基于 Transformer 引擎,相比 AI 训练常用的 FP16 半精度浮点数来说,动态范围相当,在相同加速平台上的峰值性能显著超越后者,但 FP8 更少的位数有利于减小空间占用和提升网络利用效率,允许模型拥有更多的参数量,从而算得更快。
有意思的是 OpenAI 迄今为止推出的大模型,包括大家耳熟的 GPT,Sora.,Dell 以及今天提到的 Whisper,都是基于 Transformer 模型所开发,这类模型的参数量巨大,并利用了 Transformer 模型所拥有的 Scability(可扩展性)特性,可以不断叠加模型的参数和神经网络层数,获得更精细和强大的 AI 能力。
此外,OpenAI 团队也注意到了 Transformer 模型的自注意力机制,使其能够理解序列中任意两个词元间的联系并无视距离,提高输出的质量和连贯性。自注意力还可扩展为多头注意力,允许模型将数据信息切割细化为矩阵(头),然后对每个矩阵(头)分别进行自注意力计算,最后合并输出。
在这两种机制下,Transformer 模型捕捉的信息类型更全面,学习能力和表达能力也更突出。正是由于 OpenAI 将 Transformer 模型作为产品发展平台的策略,以及 RTX 40 系显卡对 FP8 Transformer 引擎的支持,才使得 RTX 40 显卡成为普通消费者现阶段体验 Whisper 最合适的硬件。
这就不得不提到本次体验用到的两个重要硬件,第一个是 i9-14900K 处理器,作为最新一代消费级市场旗舰级定位的 CPU,其采用了 24 核心 32 线程的核心规格,最高睿频频率可达 6GHz,不仅自身性能强悍,也不会影响显卡性能的发挥。
主角则是这款影驰 GeForce RTX 4070 Ti SUPER 星曜 OC 显卡,它基于 AD103 核心所打造,包含 8448 个 CUDA 核心,显存位宽提升到了 256bit,并拥有 16GB GDDR6X 的大显存。
它所搭载的第四代 Tensor Cores 核心专为 AI 而生,新增的 FP8 引擎支持,使其具有高达 1.32 petaflops 的 Tensor 处理性能,可实现混合精度计算,动态调整算力,对于万亿级参数生成式 AI 模型的训练速度提升 4 倍,性能可达 FP16 的 6 倍,推理性能提升 30 倍,非常适合拿来体验 Whisper 的性能。
而在外观上,影驰 GeForce RTX 4070 Ti SUPER 星曜 OC 显卡亦是设计感拉满,纯白卡身装甲,自带亚克力“水晶”外壳,三风扇支持 RGB 光环特效,还附送专属定制显卡支架,颜值非常出色,拿来组白色海景房简直是绝配。
那既然是拿它来跑 AI,显卡驱动也得选 Studio 驱动,否则跑出来的速度很可能不太理想。目前 NVIDIA 官网提供的最新 Studio 驱动版本为 555.99。
首先 Whisper 是一个模型而非软件,它基于 Python 编程语言开发,直接下载 GitHub 上的原版部署的话就需要通过命令行工具来运行。好在现在已经有不少支持 Whisper 的 GUI 软件,其中简单易用的代表就是 Buzz 和 Whisper Desktop 了。
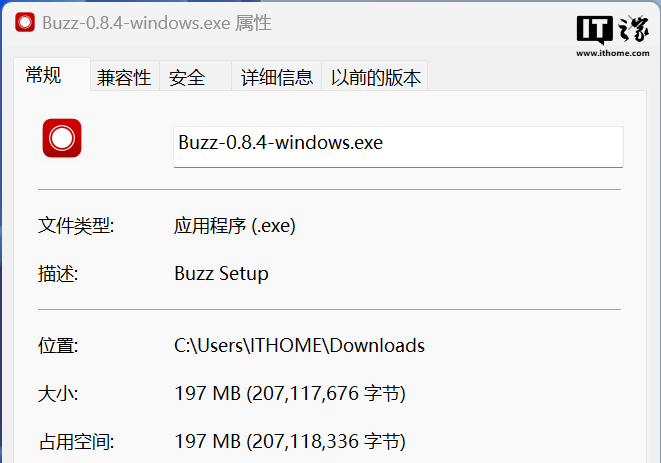
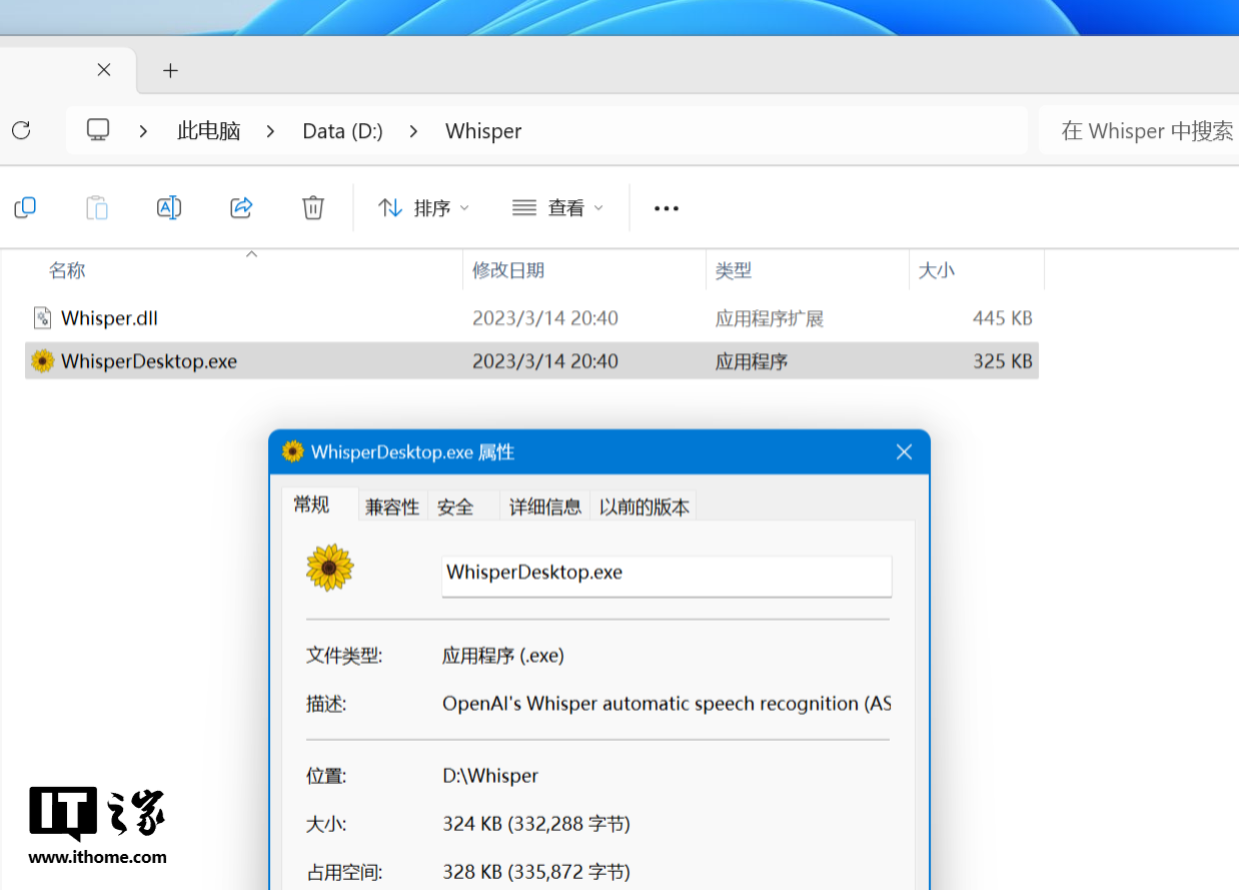
选择这两款 GUI 软件的原因也非常简单,第一是两款软件都免费,体积占用非常小,最新 v0.8.4 版本的 Buzz 安装包仅有 197MB,完全安装后的占用空间约 1.21GB,而 Whisper Desktop 甚至只需要 324kb 大小的单文件和一个配置文件就能运行。
第二是两款软件的界面非常简单,上手简单容易。首先来看 Buzz,它主要是通过 CPU 来跑 Whisper,因此兼容性更强,而且支持 Windows、Linux 和 MacOS 系统平台,非常全面。Windows 和 MacOS 用户都可以通过 GitHub 进行下载,Mac App Store 里的版本要价 9.99 美元,不是专业用户完全不推荐。
在安装好 Buzz 后,我们要下载 Whisper 的模型文件,推荐大家通过 Huggingface 镜像站进行下载,上面有 Whisper 模型的合集专题页,而且会保持更新。
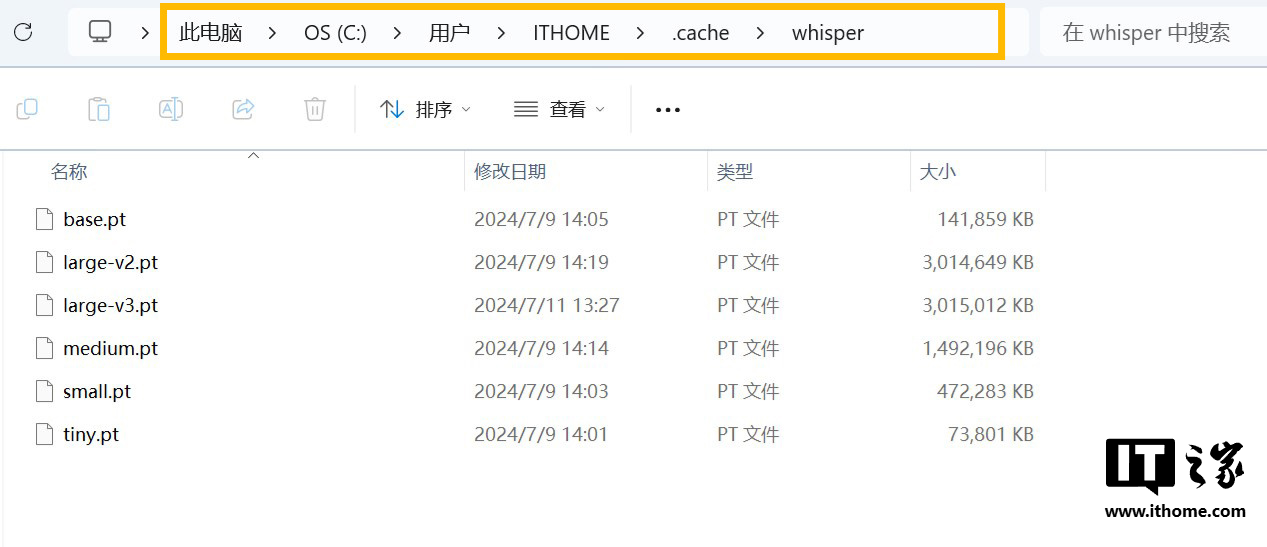
Whisper 官方提供了 Tiny、Base、Small、Medium 和 Large 五种不同大小的模型,占用的体积依次增加,模型越大处理音频的时间也越长,准确性越高。建议大家一步到位将五种大小的模型都下载下来,亲自试试效果。
这里需要注意的是,原版模型的文件名后缀是.pt,如果你下载的模型文件名和后缀不同,很可能是别人转换或者微调后的模型。下载完成后,还需要将模型文件统一放在“C:\Users\ 电脑用户名 \.cache\whisper”文件目录下,然后部署流程就搞定了,是不是非常简单。
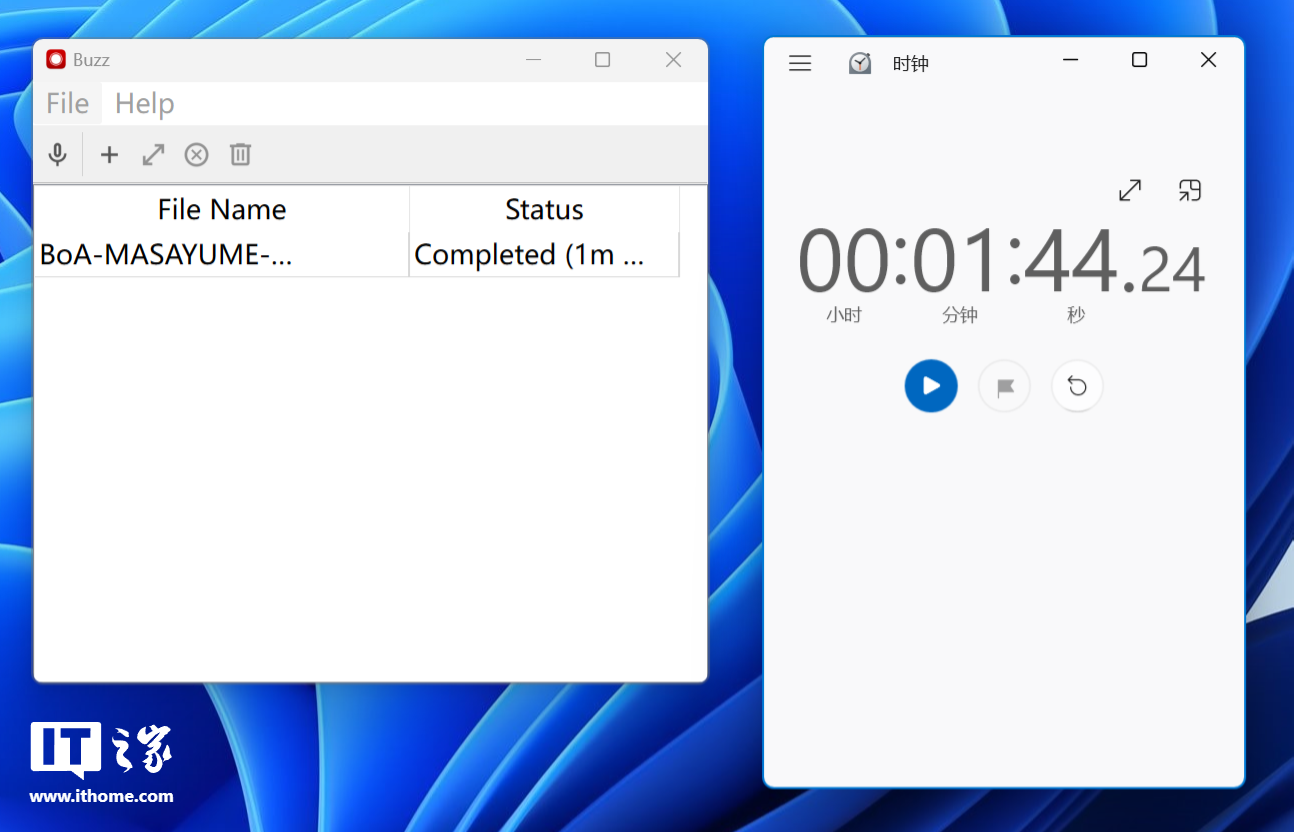
打开 Buzz 后,它的界面是这样的,非常简单粗暴,点击麦克风按钮将会采集系统声音来分析正在播放的音视频中的语音,不过这种方式的识别精度比较低,建议大家还是点击“+”号按钮手动指定本地音、视频文件进行运算更加稳妥。
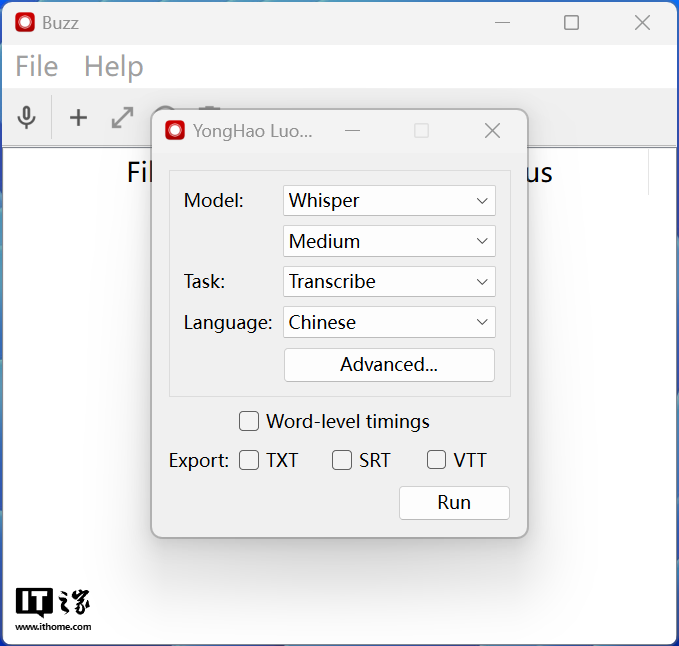
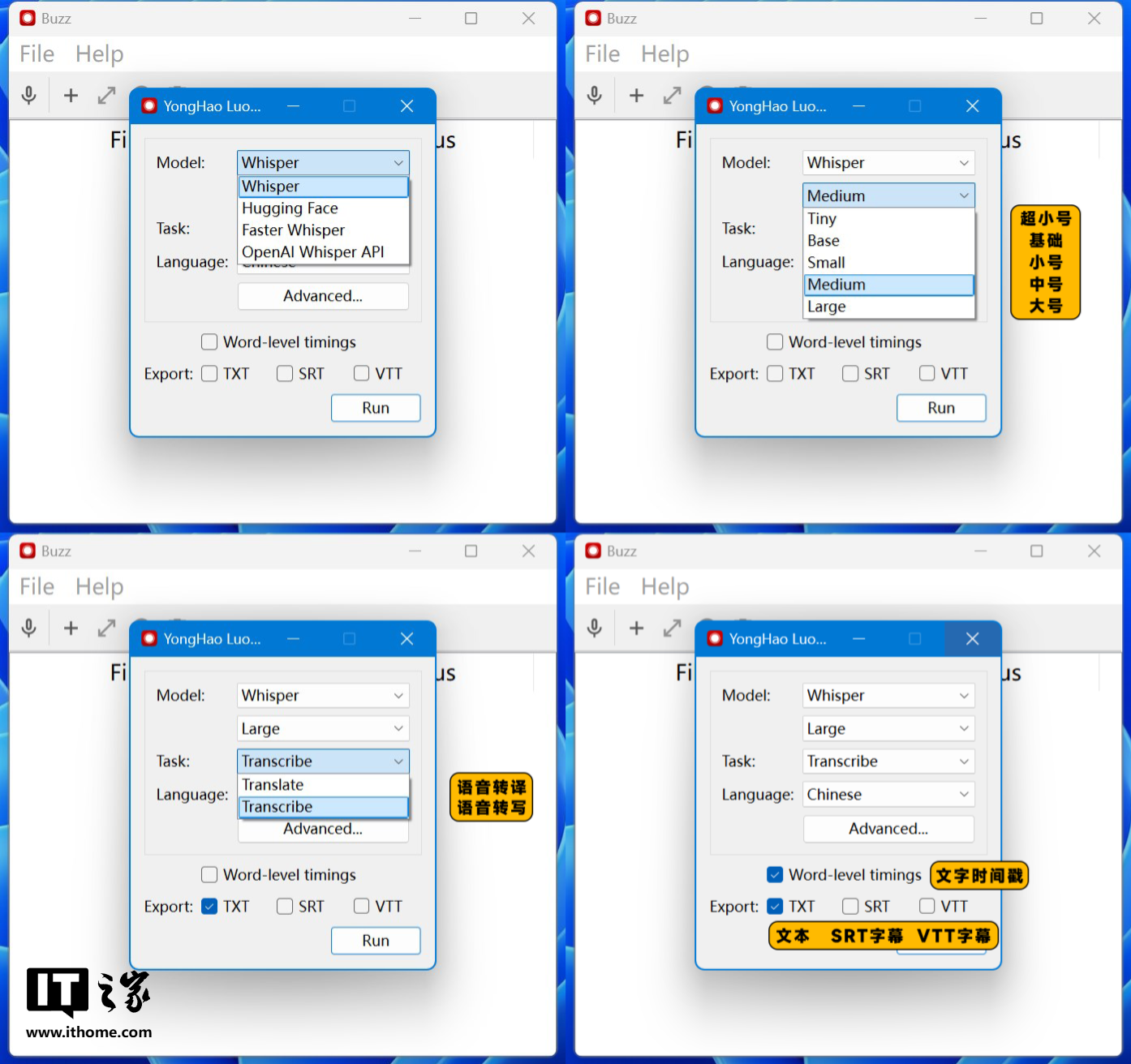
点击“+”号选择文件后,会弹出以上菜单窗口,需要依次选择模型类型、模型大小、处理方式以及识别语言,然后在底部的导出选项中选择字幕文件类型。
这里我给大家做了一些中文注释,模型类型直接选第一个 Whisper 就好,体积方面理论上转写英语音频选择 Small 模型就能有不错的效果,中文音频则需要 Medium 或 large 模型,处理类型选择转写,因为转译是将识别结果翻译成英文,而且只能翻译成英文,局限性较大。
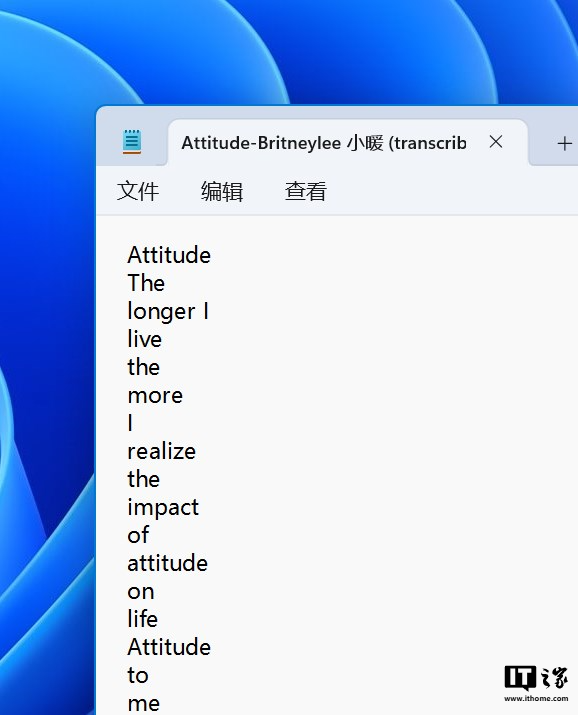
按理说对排版有要求一定要勾选文字时间戳选项,否则识别结果就会挤在一起,但是目前 Buzz 的文字时间戳选项有 BUG,勾选后不仅识别速度慢不少,识别结果每行几乎只有一个单词或单字,就像上图这样,好在不勾选它也会对每句话进行分段,最后导出文档类型大家按需选择。
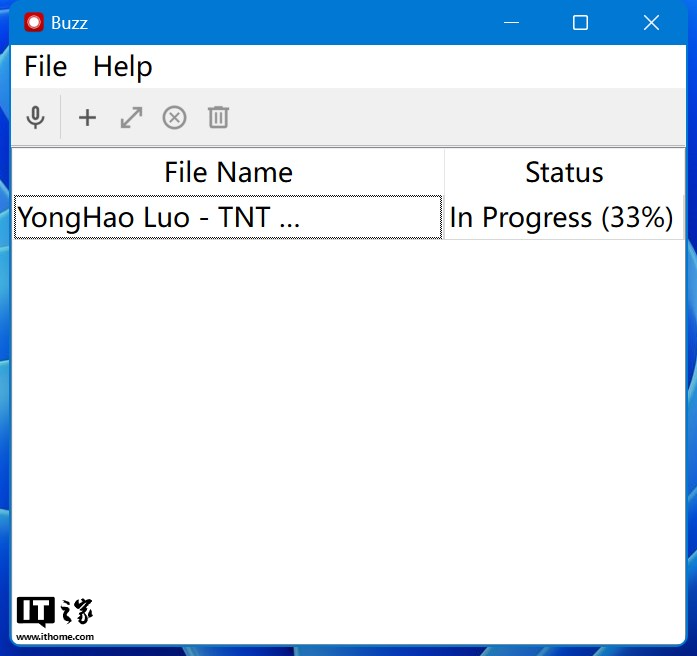
全部选好之后点击右下角的“Run”按钮即可运行,识别过程中 Buzz 会给出当前的识别进度百分比,直到完成转写。
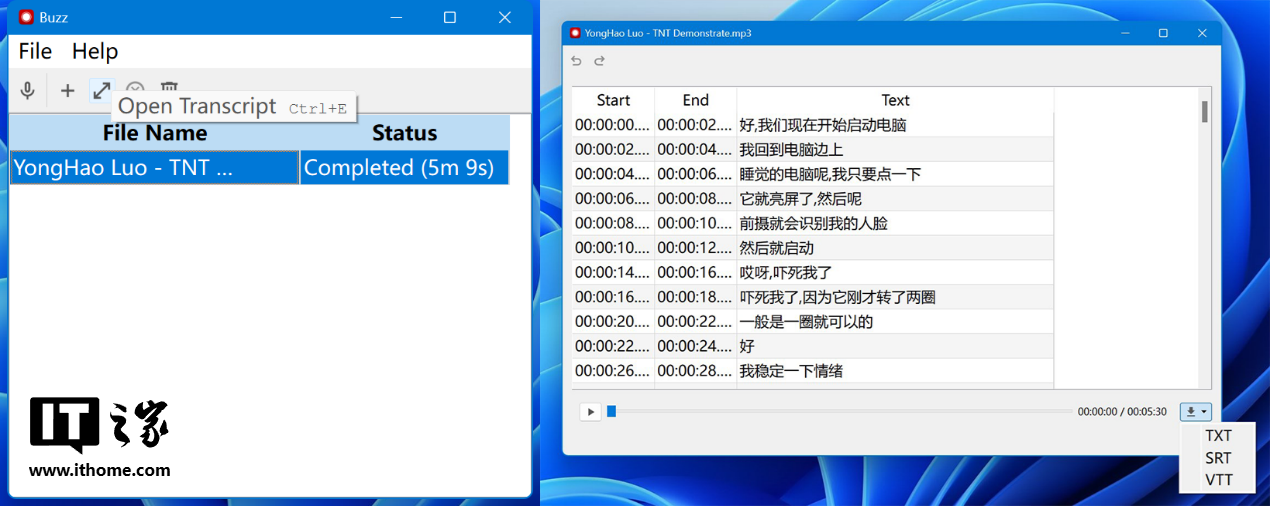
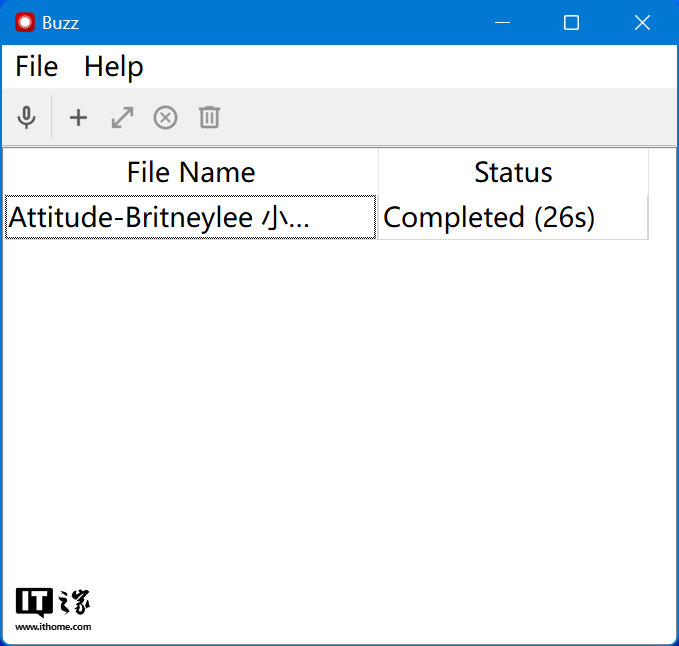
待识别进度变成 Completed(已完成)状态时,选中列表中的文件,点击“+”旁边的双箭头图标,会弹出识别结果的预览窗口,里面记录了每句话的时间起始和转写结果,再次点击右下角的下载按钮并选择导出文档类型即可下载到电脑。
再看下 Whisper Desktop,首先是下载,Whisper Desktop 软件和模型下载地址我贴在这里,同样也是五种大小的模型,只不过文件名前缀和文件类型后缀不同。
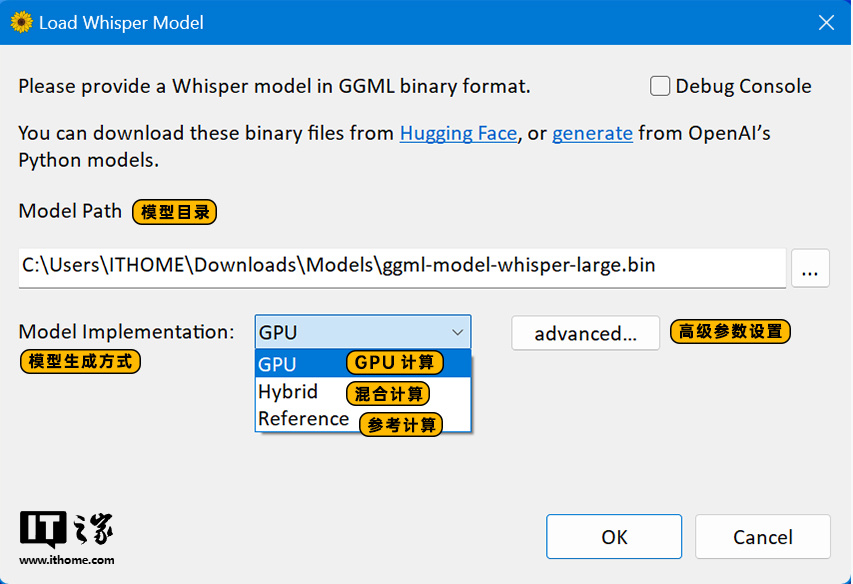
然后是 Whisper Desktop 的界面和操作。打开后我们首先需要选择模型,Whisper Desktop 不需要指定的模型存放目录,手动选择模型地址就行。
大家注意,Whisper Desktop 的模型文件并不是.pt 后缀的,而是.bin 后缀的,文件名中也多了 ggml-model 的字样,显然这是经过转换后的模型文件。
实际上,该软件就是 Whisper 的 ggml 版本,ggml 是一个用于机器学习的张量库,所使用的模型文件是 bin 格式的二进制文件,识别效果等同于 Whisper。
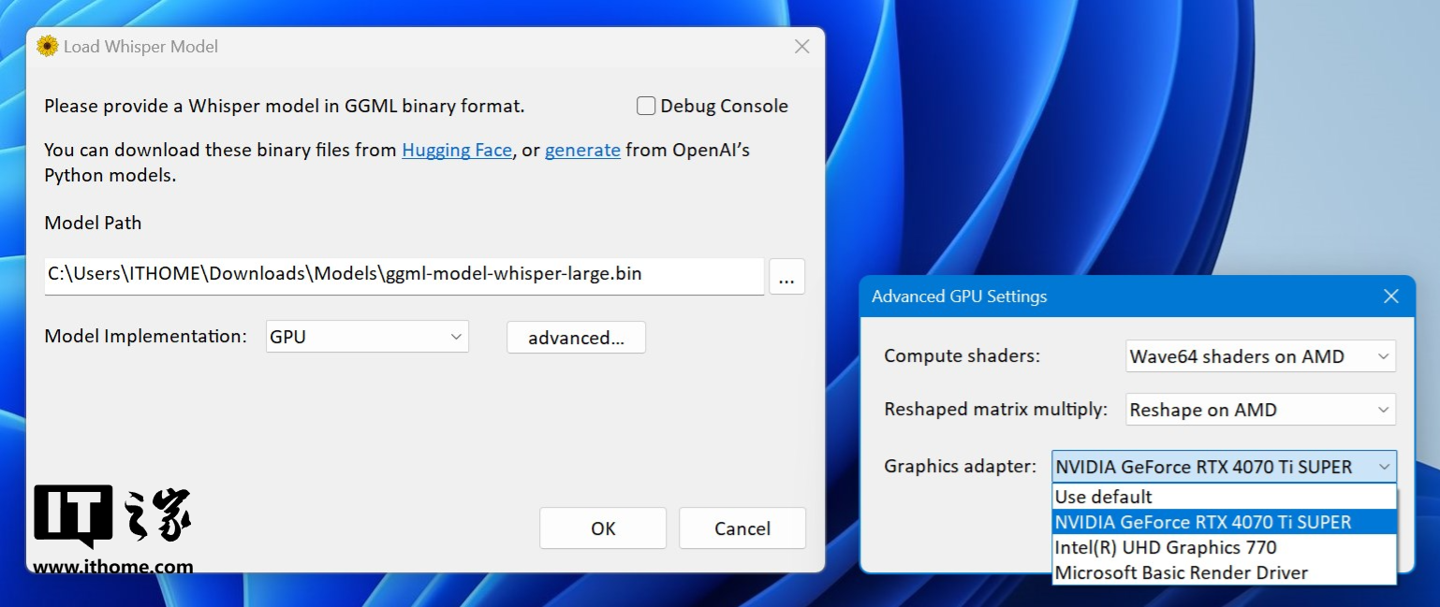
然后模型生成方式这里选择 GPU。高级参数设置中,有独显的选择独显,没有独显的则选择核显,我这里就直接选择影驰的 GeForce RTX 4070 Ti SUPER 星曜 OC 显卡就行了。
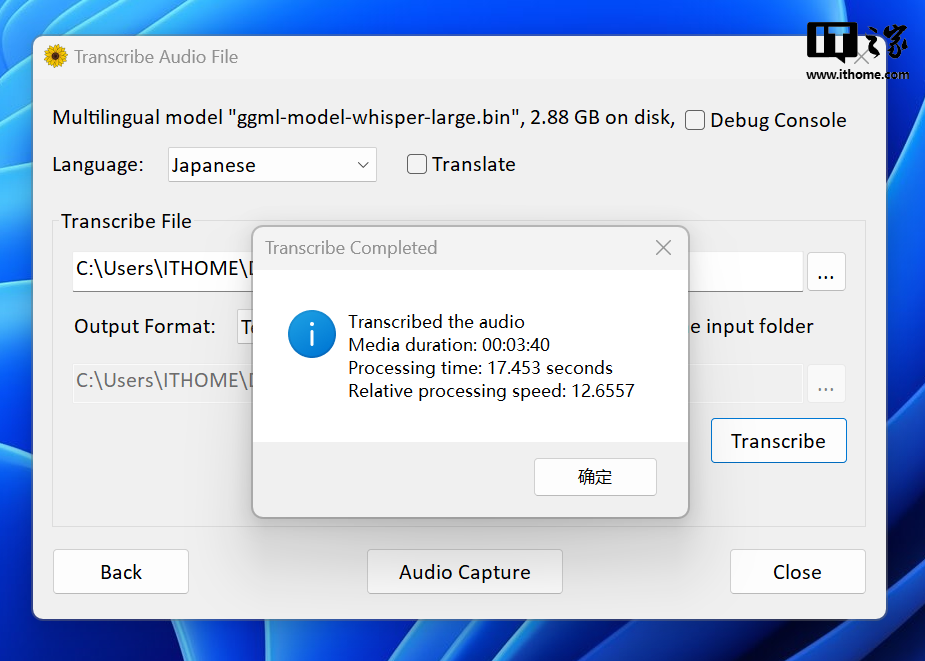
全部选好后点击 OK 进入二级页面,这里的操作步骤和 Buzz 比较类似,我也给大家都标注了中文注释,一看就会。选好后点击右下方的 Transcribe(转写)按钮即可。
测试环节我们将进行四组不同语种、语速、类型的音源文件比较,对比内容为识别 + 转写速度和识别准确率,比照对象则是以 Buzz 软件 + i9-14900K 的 CPU 处理阵营和以 Whisper Desktop + 影驰 GeForce RTX 4070 Ti SUPER 星曜 OC 显卡的 GPU 阵营。
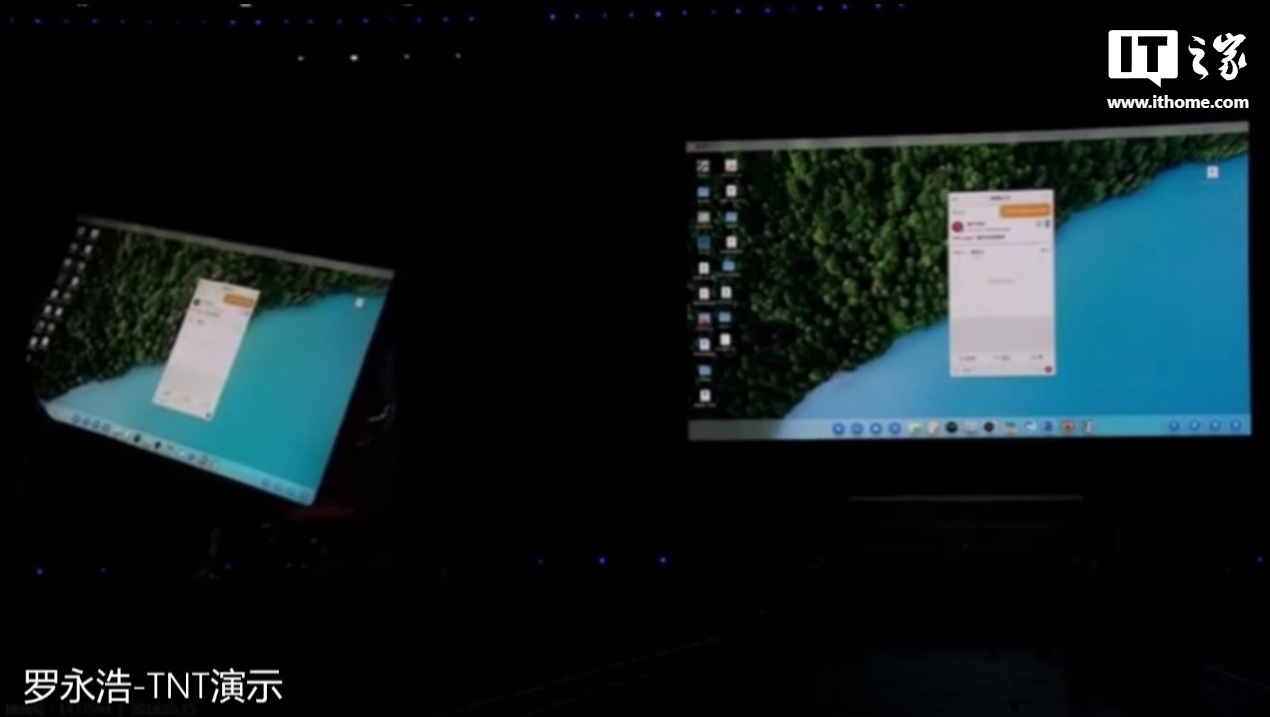
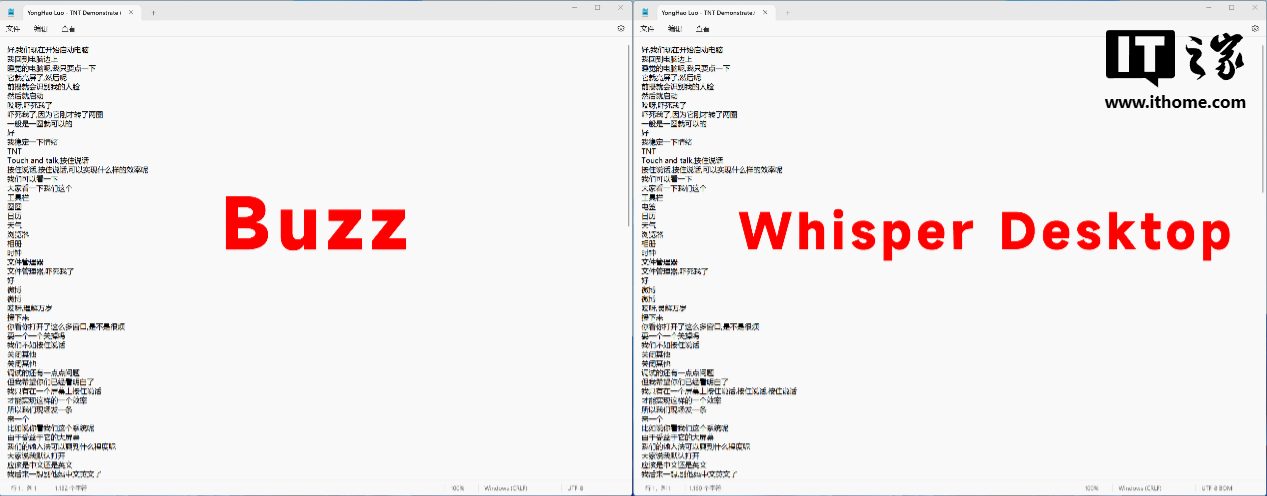
第一次先看中文识别效果,我们在网上下载了一段锤子科技当年在鸟巢举办的新品发布会上,老罗对 TNT 功能进行演示的视频片段,然后转换为去掉观众席声音的 5 分 30 秒 MP3 音频文件,这段中文语音中混杂了中文、英文和数字,比较考验 Whisper 的综合实力。
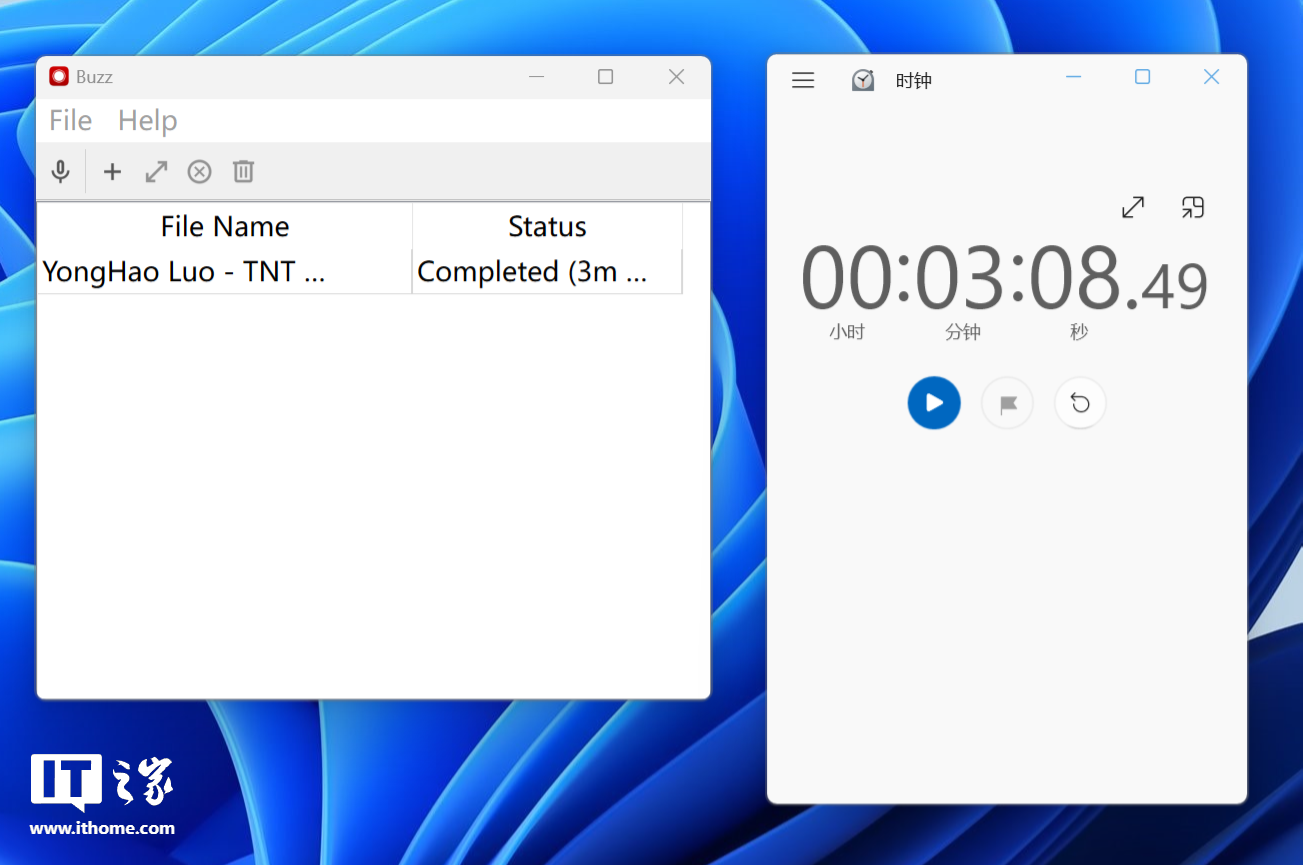
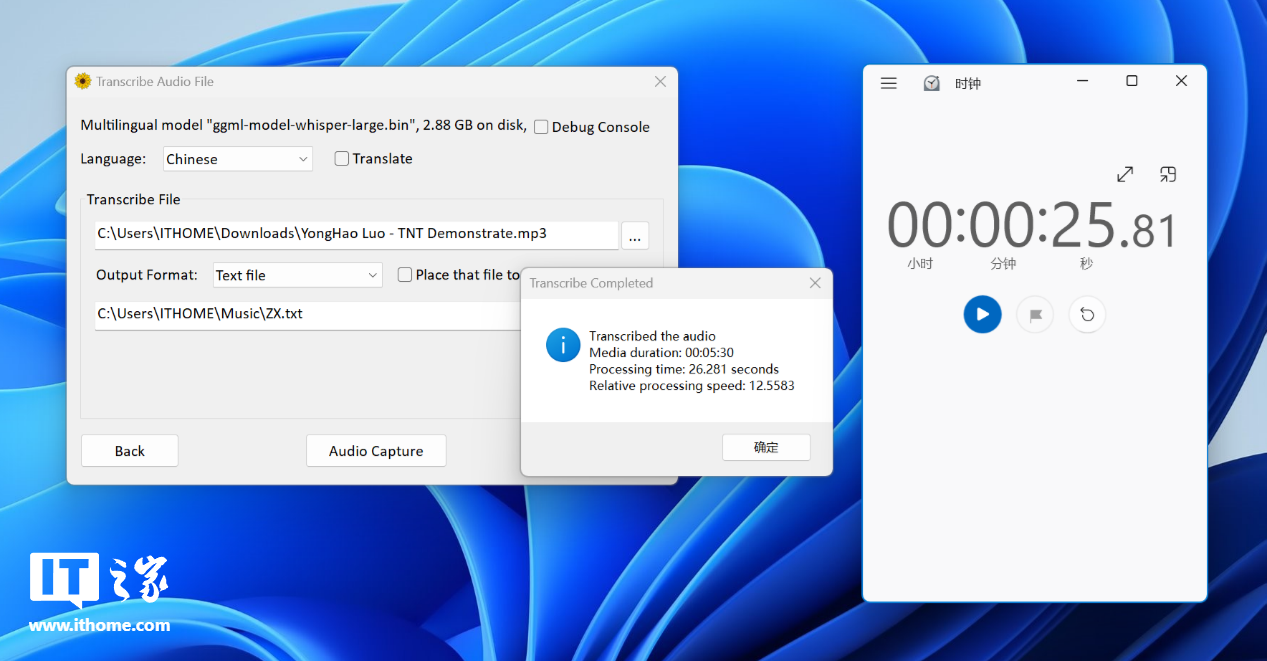
在同样选择 large 模型的情况下,Buzz 采用 i9-14900K 处理器渲染,最终转写速度为 3 分 08 秒左右,Whisper Desktop 采用影驰 GeForce RTX 4070 Ti SUPER 星曜 OC 显卡渲染,转写速度为 26 秒,Whisper Desktop 仅用了 Buzz 软件 1/6 不到的时间便完成转写,由此可见自带 Transformer 引擎的显卡对于 Wisper 的效率提升是巨大的。
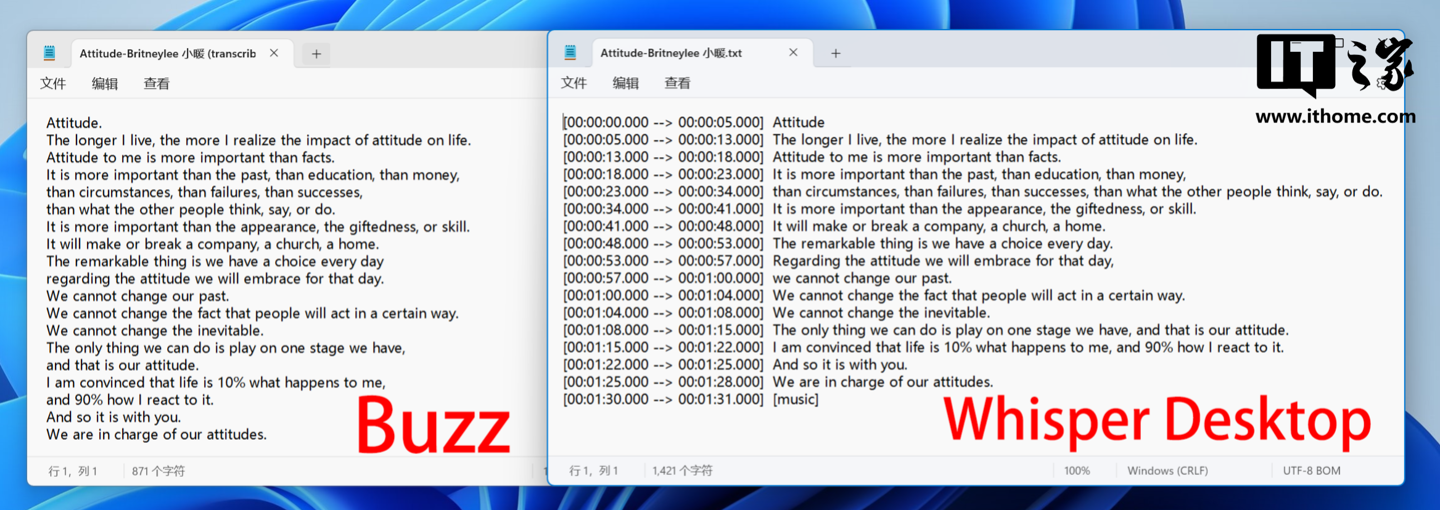
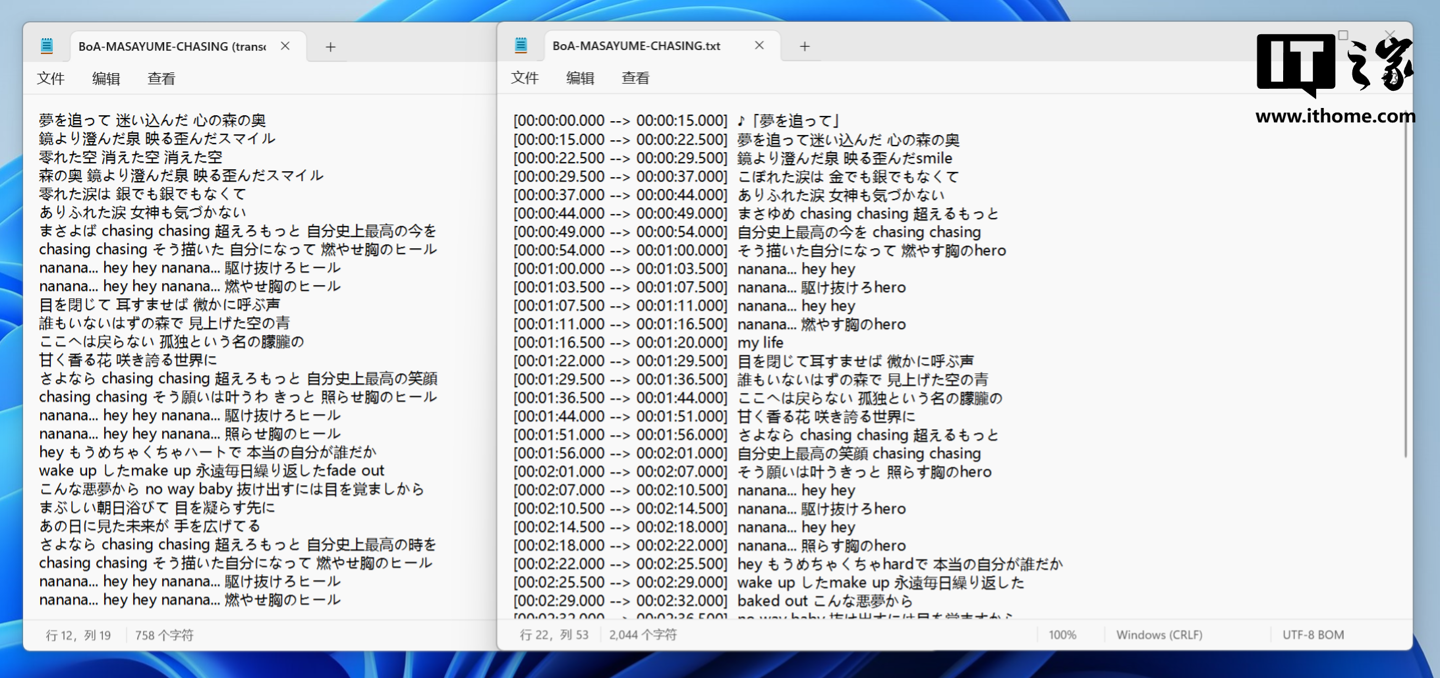
转写排版上 Buzz 和 Whisper Desktop 在不选择时间戳文本类型的 TXT 文件格式下,势均力敌,基本都能做到按照一句完整语音进行换行断句。
不过,在识别结果的字数上,两者竟然并不相同。Buzz 的转写字数为 910 字,而 Whisper Desktop 的转写字数为 933 字。识别准确性上,Buzz 识别错误 27 个字 / 词,准确率为 97%,Whisper Desktop 识别错误 9 个字 / 词,准确率 99%。为了不被偶然性影响,我们连续测试三次,基本都是这个比例。
两者在错误类型上,即使我只截识别错误的这句话,不联系上下文,大家都能一眼看出错在哪了,基本就是中英文混说 / 纯中文发音识别错误。
另外,Buzz 输出某些英文也会识别错误,而 Whisper Desktop 的英文和数字是完全没错误的。至于为什么 Whisper Desktop 的识别结果字数要多一些,主要是语音中存在重复说相同词语时,Buzz 有几率只转写一次,而且 Whisper Desktop 有些地方还会添油加醋,比如结尾莫名多出来一句谢谢观看,还挺贴心的哈。
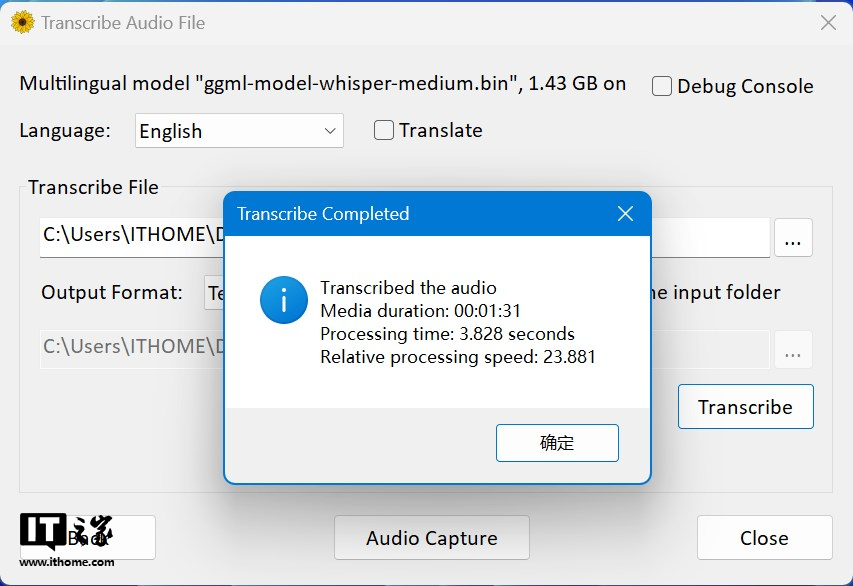
第二轮对比我们选择了一段 BGM 舒缓,类型为朗读的英文短篇,整体朗读速度较为适中,吐字清晰,音频时长为 1 分 31 秒的 MP3 音频,模型则选用了 medium。
这次的转写速度差距也非常明显,Buzz 转写耗时 26 秒,而 Whisper Desktop 仅用时 3.8 秒便完成转写。
在转写排版上,由于 Buzz 选择时间戳文本有 Bug,所以 Whisper Desktop 略胜一筹。不过在识别准确率上两者完全打平,因为都是 100%,比较前文也提到了 Whisper 的英文识别能力非常强悍。
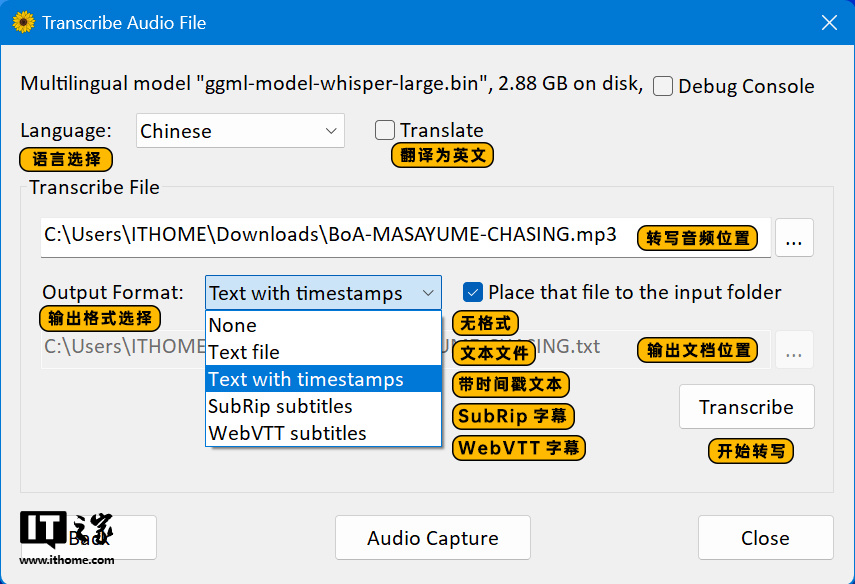
当然,大家非常关心的日文我们也进行了测试,这次我们选择了一首日本歌手 BoA 演唱的《妖精的尾巴》TV 动画 OP 主题曲《MASAYUME-CHASING》,这首歌的 BGM 比较燃,语速相对前面的英文朗诵也快不少,还有很多重复叠声词,歌曲时长为 3 分 40 秒,测试模型选择 Large。
转写速度上,Buzz 用时 1 分 44 秒完成,Whisper Desktop 用时 17 秒完成,影驰 GeForce RTX 4070 Ti SUPER 星曜 OC 显卡再次完胜。
转写排版和前面的英文差不多,只是两者在一些语句的断句长度上有所不同。而准确性上,两者的很多错误都一样,识别准确率都是 96%。但是 Buzz 有些地方错成了假名,而 Whisper Desktop 相同位置则错成了英文,比如歌词原句为“燃やせ胸の火を”,中文大致意思是“胸中之火熊熊燃烧”。Buzz 的转写结果为“燃やせ胸のヒール”,中文变成了“燃烧胸前的高跟鞋”,Whisper Desktop 的转写结果为“燃やす胸の hero”,中文变成了“燃烧胸前的英雄”。错的结构基本都是这种,懂日语的小伙伴可以在评论区解释一下。
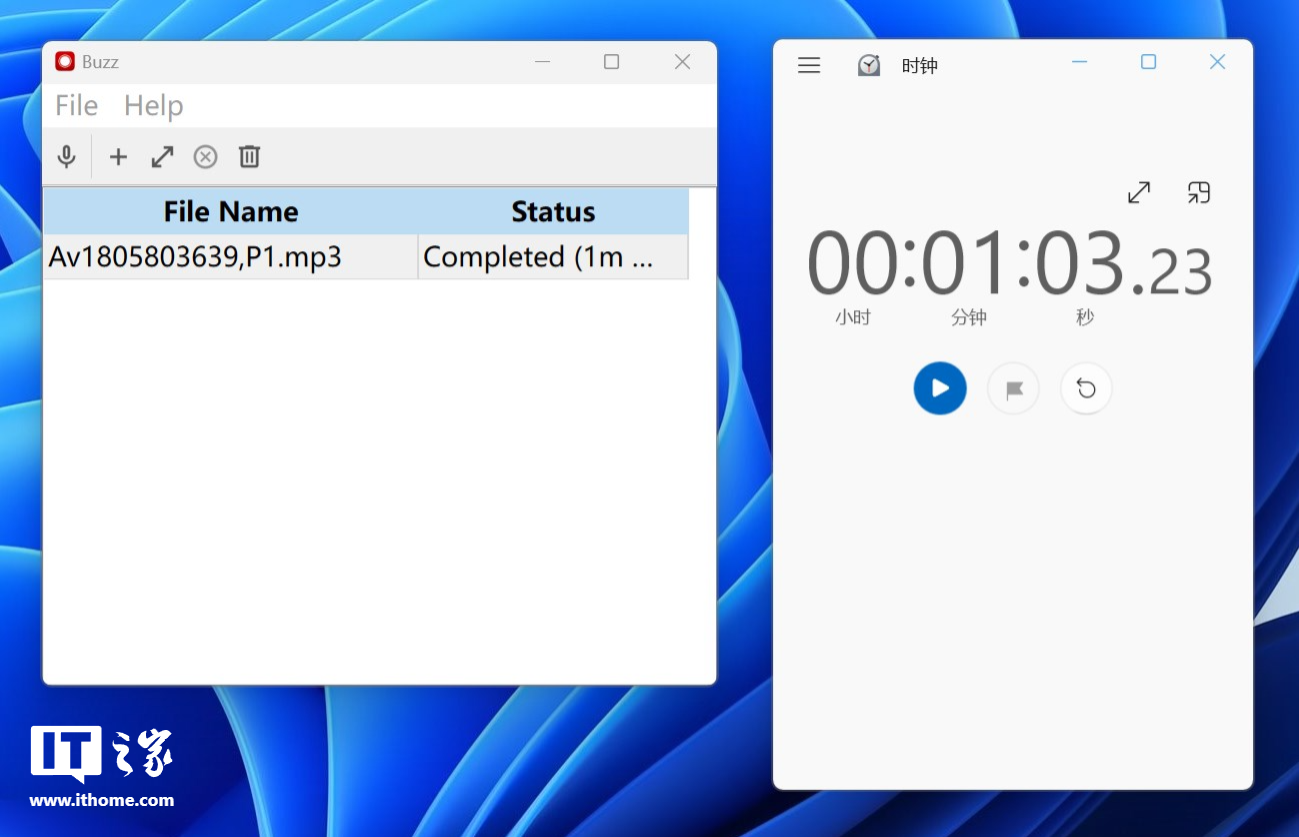
最后我们选择了一首英文说唱类型的视频,这个视频比较特殊,首先它虽然是作者二创填词,但声音选择了 AI 配音,有很重的“花果山口音”,其次语速很快,每句话中都有大量的英文单词,吐字也不算很清楚,属于稍微“鬼畜向”的作品,我们同样将其转成 MP3 格式,采用 medium 模型,看看这种音频 Whisper 能搞定吗?
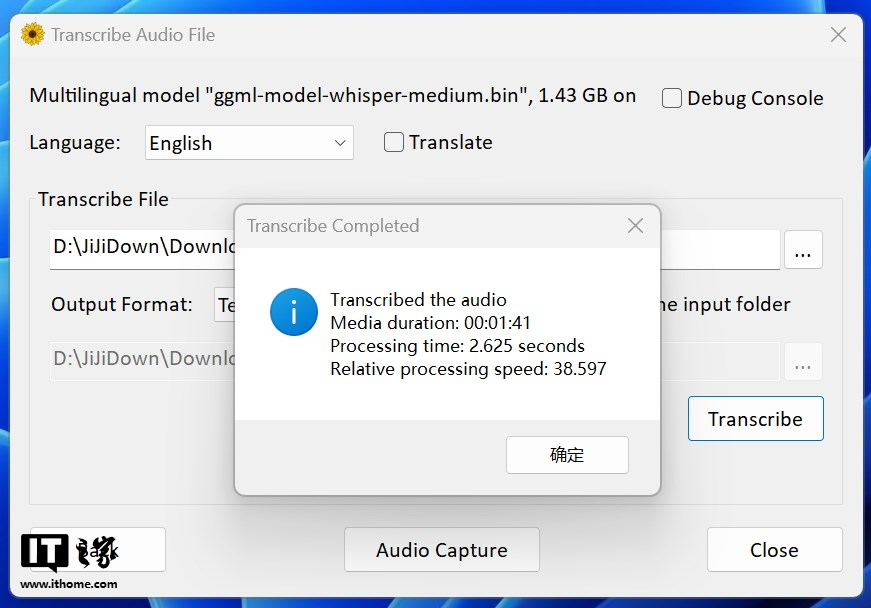
然而出乎意料的是,Whisper Desktop 仅用时 2.6 秒就完成了转写,这也太快了!Buzz 则花费了 1 分 03 秒完成。
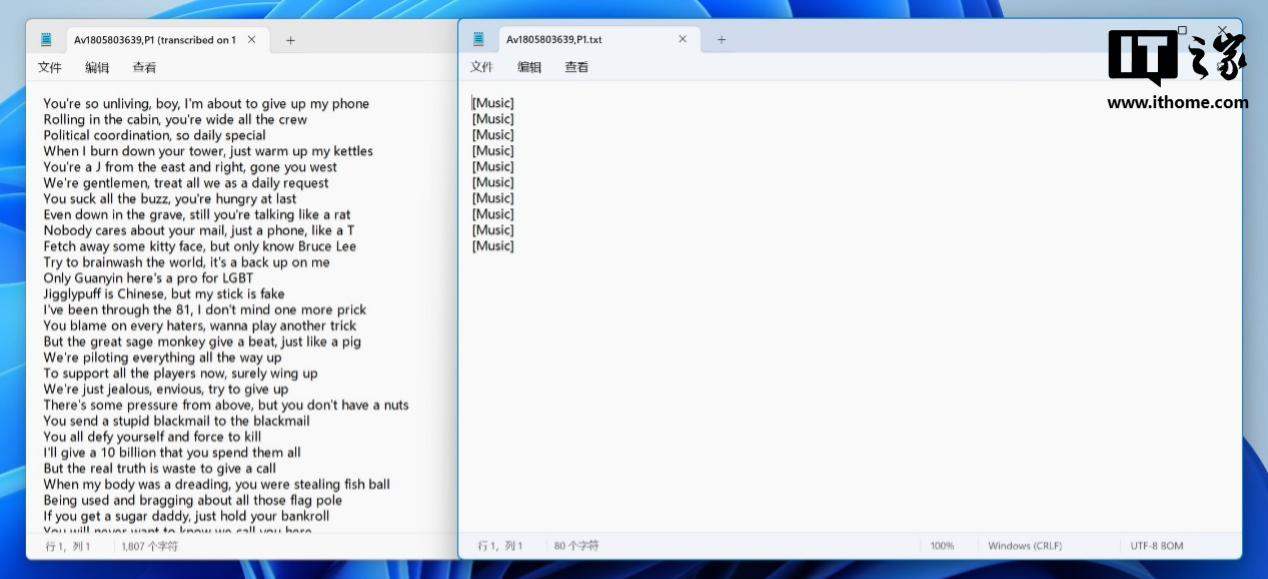
可是这次转写的结果着实令人哭笑不得,Buzz 似乎顺利识别出了整首歌的歌词,而 Whisper Desktop 直接扑街,一个字都没听出来,这下子高下立判了。
别急,仔细看 Buzz 的文档我又发现,它这个文案很多地方像“脑补”出来的,对比原视频只能说错对一半一半,关键很多话中错了几个词意思就完全对不上了。显然,在面对 AI 配音 + 口音 + BGM 的场景,Whisper 似乎也无能为力,所以大家就别指望用它来转写口语化很重、方言以及鬼畜视频了。
经过上面三组测试的对比,我们可以得出以下几点结论:
相比 CPU,RTX 40 系显卡的 AI 性能对 Whisper 这类基于 Transformer 引擎所打造的多模态大模型是有绝对优势的。
影驰 GeForce RTX 4070 Ti SUPER 星曜 OC 显卡即使在 Large 最大体积模型下,也能将 5 分钟以内的音频文件转写时间压缩到 60 秒以内,16GB 大显存可以轻松驾驭 Large 模型的负载。
Whisper 对于中文的识别精度目前还算不上很出色,难度相比日语、英语都要大。而日文、东亚语种的识别准确率也是明显会差于英语的。但从错误数量相对整个文本的占比来看,Whisper 依旧做到了 90% 以上的准确性,相比收费软件识别速度或许不一定会占优,但胜在免费、离线和低门槛,整体表现在免费转写工具中出类拔萃。
口音很重或者通过变声的 AI 配音、变声鬼畜向视频,不适合使用 Whisper 进行转写。
除此之外还要特别说明 2 点,一是拿 i9-14900K 进行对比,主要目的是给到大家识别速度上的参照物,并非为表明 RTX 40 显卡的 AI 性能一定比 intel CPU 强;二是大家使用 Whisper 进行识别转写前,最好还是通过三方软件,将音视频中的人声和 BGM 进行分离,识别效果会更好。
在 Whisper 配合两款 GUI 软件的体验过程中,除了部署阶段涉及到大量外网模型资源的下载有些麻烦,操作体验没有任何问题,非常人性化。
对于有非商业,非大批量语音识别 + 转写使用场景的用户来说,Whisper 足够满足他们的日常需求,而像影驰 GeForce RTX 4070 Ti SUPER 星曜 OC 显卡所拥有的 Tensor Core、CUDA 以及 16GB 大显存,能够轻松应付 Lager 模型给到的 AI 运算负载压力,给用户带来显著效率提升。
或许现在很多 AI 领域离我们的生活还很远,但不可否认的是,善用 AI 一定能让我们的生活变得更加美好。
最后,由于文中部分链接对网络环境要求较高,这里就给大家附上此次测试所用到的模型资源好了:
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12















 鲁公网安备37020202000738号
鲁公网安备37020202000738号