国产数据库的创新内核,展现真正的实力
发表时间: 2022-07-25 17:53
缺乏自主的关键技术是国产数据库被诟病最多的痛点。
众所周之,国产数据库中,绝大多数是基于开源数据库改造的,尤其是基MySQL或 PostgreSQL改造的居多,这本身无可厚非。
自研,并非只有从0开始完全自研一条路,基于开源数据库做半自研,然后逐渐深入关键核心模块,直至最终完全掌控开源数据库,也是自研。但是,这绝不是在开源数据库上穿个“衣”带个“帽”。毫无疑问,在数据库市场中,自研、内核创新、核心业务系统等词被滥用了。
那么,基于开源数据库的国产数据库中,到底有没有,具有自己的技术创新,甚至内核级创新的产品呢?答案,当然是有的。
今天,老鱼就想来聊一聊openGauss的技术创新,为此,老鱼采访了openGauss 技术委员会主席李国良,openGauss开源数据库首席架构师黄凯耀,听他们说一说openGauss内核与架构技术创新的故事。
李国良,清华大学计算机系副主任、教授、博士生导师。在数据库会议和期刊上发表论文150余篇,他引10000余次。获得了VLDB 2017 Early Career Research Contributions Award(亚洲首位)、IEEE TCDE Early Career Award(亚洲首位)。SIGMOD 2021大会主席,VLDB 2021 Demo 主席,ICDE 2022 Industry Chair,获国家科技进步二等奖、江苏省科技进步一等奖。
黄凯耀,openGauss开源数据库首席架构师,负责openGauss的技术规划与产品设计工作,在数据库高性能架构、高可用架构、OLTP性能优化、OLAP性能优化、一体化架构、软硬协同等领域有丰富的理论、工程与实践经验。
什么是数据库内核?学过数据库的都知道,内核通常指数据库最核心的部分,比如:优化器、解析器、执行器、存储引擎等。
openGauss对内核如何界定?老鱼找到一张官方图:
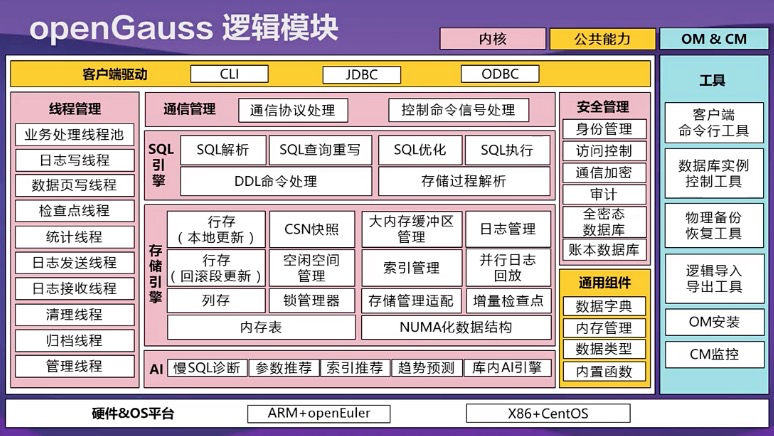
如上图,粉色的部分就是openGauss界定的内核部分,包括线程管理、通信管理、SQL引擎、存储引擎、安全管理、AI。那么,openGauss在内核上都有哪些创新?其实,上图已经能看出一部分东西。
众所周之,openGauss内核早期衍生自PostgreSQL-XC,但如今,openGauss与PostgreSQL-在架构和内核上,已经有了极大的差异。
如上图,openGauss执行模型,采用线程池模型。而PostgreSQL是进程模型。这么改有什么好处?进程模型,数据库进程通过共享内存实现通讯和数据共享,每个进程对应一个并发连接,这就存在高并发下,进程切换性能损耗,导致多核扩展性问题。而线程池技术的整体设计思想是线程资源池化、并且在不同连接之间复用,因此,高并发连接切换代价小,内存损耗小,执行效率高。
李国良说,openGauss尤其在核心的优化器、执行器、存储引擎方面,做了很多的改进和优化,与传统的关系型数据库,有了本质区别。
存储引擎方面,openGauss实现存储引擎融合,即一套架构支持多种存储模式。openGauss支持多引擎(行存储引擎、列存储引擎、内存引擎),而PostgreSQL仅支持行存储引擎。看起来只是多支持了2个引擎,但其中涉及很多关键技术。比如:openGauss行存储引擎采用原地更新(in-place update)设计(又名:Ustore存储引擎),追加写引擎(HEAP),支持MVCC(Multi-Version Concurrency Control,多版本并发控制),同时支持本地存储和存储、计算分离部署方式。
原地更新相比非原地更新有什么好处?李国良给老鱼打了个比方,简单的说,非原地更新是一张表一直往上加,有删有增,维护这张表代价非常大。openGauss 内核此前的版本使用的行存储引擎是Append Update(追加更新)模式,追加更新对于业务中的增、删以及HOT(Heap Only Tuple) Update(即同一页面内更新)有很好的表现,但对于跨数据页面的非HOT UPDATE场景,垃圾回收不够高效,因此,Ustore存储引擎应运而生。
众所周知,优化器的好坏会直接决定关系型数据库的强弱,优化器一般分为RBO(Rule-Based Optimizer)基于规则的优化器和CBO(Cost-Based Optimizer)基于代价的优化器,PostgreSQL支持CBO,openGauss支持CBO,SQL by pass。
虽然都支持CBO,但对复杂场景的优化能力是完全不同的。李国良说,openGauss在优化器的CBO上做了很多技术创新。首先,openGauss添加了很多查询重写规则,查询重写优化;其次,openGauss做了很多CBO代价的调优模型,适应不同场景;最后,openGauss加了基于机器学习的代价估计方法和优化算法,使得优化器更智能,适用于更多、更全面的复杂场景。
Sql-bypass是openGauss针对OLTP场景开发的一个轻量化执行器,它解决的是什么问题?在典型的OLTP场景中,简单SQL查询占了很大部分比例。试想一下,如果一个简单的SQL查询因为复杂的CBO逻辑,而消耗不必要的CPU资源浪费执行时间,那肯定是不行的。SQL by pass就是为了加速这类查询设计的,可以极大地缩短执行器通用框架处理逻辑,极大地提升执行的性能。
执行器方面,为了提高SQL的执行速度,解决传统数据处理引擎条件逻辑冗余的问题,openGauss执行器引入了自适应实时编译(Codegen)技术,其核心思想是为具体的查询生成定制化的机器码代替通用的函数实现,并尽可能地将数据存储在CPU寄存器中。
总的来说,openGauss内核创新围绕“四高”原则,即:高性能、高可用、高安全、高智能。比如:高性能,openGauss聚焦了很多新型技术,包括NUMA-Aware技术、智能优化技术、内核并行执行的技术,这些都是在内核创新方面引领的一些新型技术。
高智能,在数据库内核方面涉及到很多优化技术,包括很多优化NP问题,以及代价估算技术。传统方式都是基于一些独立性假设、均匀分布假设,这导致估算结果非常不准确,而openGauss通过众多智能技术(智能索引技术、智能数据化分析技术、智能优化内核技术)提升准确性、提升数据库内核优化效率,提高可复制性。

(密态数据库总体架构)
高安全,是openGauss非常重视的一个特性,openGauss引领了防篡改、全密态数据库发展,也得到了一些POC的测试。此后,openGauss会持续构筑这些能力,打造安全、稳定的数据库密态内核,达到商用产品化标准,保护用户敏感、隐私数据的全生命周期的安全。
黄凯耀则给老鱼分享了4个架构创新,工具创新的故事,分别是插件化架构、可观测内核架构、资源池化架构、数据安全架构,而这四个架构创新是基于用户场景驱动的,解决的是易迁移、易运维、易开发、易扩展的刚需问题。
篇幅所限,本文只解析插件化架构及可观测内核架构。

黄凯耀告诉老鱼,插件化架构的提出,是为了易迁移的目标,也就是为了实现方便简单的把其它数据库往openGauss迁移。为了达成这个目标,openGauss设计了数据库的插件化架构。首先,在计算引擎这一层上面,定义了数据库的扩展点。数据库内核开发者可以基于这些扩展点,去实现其它数据库语法的兼容插件。

同时,为了更方便支持应用开发者把原有的数据库迁移到openGauss上,在内核层面,openGauss实现了SQL兼容性评估插件。基于应用提供的SQL语句,去调用相应的数据库插件,基于该插件的能力,对SQL语句进行评估并得出可读性很强的评估报告,为什么说可读性很强?因为,它是从其它数据库迁移到openGauss的迁移建议的中文提示,而非模糊化的英文提示。
第二个故事,是可观测架构。可观测与可运维是社区开发者对openGauss提出的另外一项重大诉求,并不亚于迁移方面的呼声。黄凯耀说,解决的问题是怎样对openGauss进行更加全面系统地性能监控和故障诊断。
搞过数据库运维的人都知道一个棘手的场景,就是业务部门反馈系统慢,但DBA从有限的数据库监控指标上却看不出任何问题。因此,加强数据库可观测性是降低数据库使用成本一个非常重要的手段。
相较而言,要实现全栈的可观测、可跟踪架构,技术难度很高。因为,这不仅涉及到数据库内核,数据库运维,还涉及操作系统内核等,黄凯耀说。
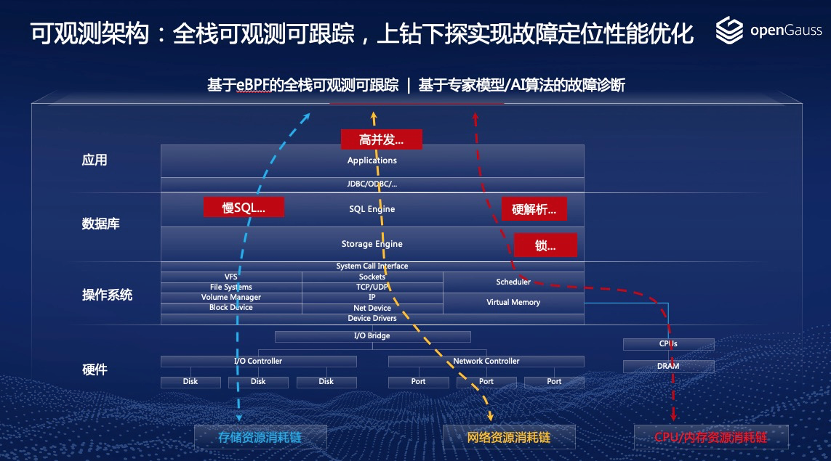
openGauss通过资源消耗链的角度,把整个系统的资源消耗分为三类:
存储资源消耗链
网络资源消耗链
CPU内存资源消耗链
在每一个资源消耗链上,可以通过上钻下探的方法,去实现系统性能问题的优化或者故障问题的定位。通过这种全面系统的上钻下探,就可以实现一个良好的可观测架构。
而这背后,需要对数据库内核代码做更多的增强,并且仅数据库内核增强还不够,还需要借助操作系统最先进的eBPF技术,才可能提供更全面、更丰富的可观测数据。而有了丰富的数据,诊断系统就可以基于这些数据做基于专家模型的推理或AI诊断。
通常,从一个业务指标,关联到数据库等待时间指标,再关联到操作系统的资源消耗指标,是目前主流数据库所提供的可观测能力。但openGauss更进了一步,直接把数据库内核中的热点函数也追踪起来,这样,实现了在等待事件之下的进一步的观测与诊断。
因此,openGauss可观测架构实现了从观测数据到诊断定位的全链条打通。
实际上,openGauss内核与架构技术创新的故事远不止这些,本文也只是管中窥豹,无法一一列举。比如:在Oracle 21c中才出现的区块链表 ,在openGauss 2.0中就已经被实现 。当然,即便如此,openGauss依然还需要持续提升和完善,创新之路上还有很长的路要走。但本文想表达的是,无论是内核创新,还是架构创新,事实上,无论是那种架构的创新,最终都与内核息息相关,只有完全掌握消化内核并在此基础上持续创新,才算是真正的自主可控。
数据库发展了半个多世纪,在旧的数据库技术上,中国与西方差距其实不大,大家都知道怎么去做。李国良说,但在软件工程能力上,我们与国外是有差距的,这需要我们努力,而超越机会更大的是创新性,我们要去引领创新,而不是跟随别人创新。
因为,你走别人的路,一直跟别人学,是永远不可能成功的。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号