大数据的定义与应用:一篇文章带你全面了解
发表时间: 2019-09-30 08:15
大家好,我是一个字节。

我是表示数据量的基本单位。
大家平时看到的MB、GB、TB就是很多个我凑在一起,这些都是可以表示数据存储量的计量单位。
1024个我组成1个KB,1024个KB组成1个MB,1024个MB组成1个GB,1024个GB组成1个TB……
别动!你现在手指划过屏幕就在产生数据。
你刚刚点击关注小咖的公号(没关注的现在就动动你手指,点击标题下面的蓝字关注我们)、你看完文章点“在看”,你在留言区给我留言,你看完文章后转发朋友圈,所有的这些都在产生数据。
你的每一个上网行为会产生数据;你现在用的手机在工厂里生产制造时,自动化生产线会产生数据;之后你在京东商城买手机,会产生交易数据,手机送到你手上的过程还会产生物流数据……
很多人说,我们将成为和石油一样重要的资源。数据中蕴藏着未来的重要商机、推动社会进步以及科学发现的动力。可现实情况似乎并不乐观,有个叫IDC的知名分析机构说了,过去两年创建的那些我的同族们,其中只有不到 2% 的经过了分析。
我想,可能是因为我们和石油一样,同样需要被勘探与挖掘,而这个过程都不简单。在我们数据一族,这种“挖掘与勘探”的过程被称为数据分析与洞察,这让我们产生价值。

很多很多个我们凑在一起,人们习惯把我们叫作“大数据”。如果只是单独的一个我,或者很少的几个我们,是无法产生价值的。所以,让我们发挥价值的第一步是要搜集数据,第二步是分析数据,第三步是根据数据分析结果做出决策。这些都需要依托于计算机系统的计算能力与存储能力。
而我们数据一族又有很多种,有些被人们叫做结构化数据,简单来说就是数据库,比如企业ERP、财务系统、医疗HIS数据库、政府行政审批、其他核心数据库产生的数据;有些被人们叫做非结构化数据,他们“伪装成”视频、音频、图片、图像、文档、文本等形式。非结构化数据是数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。
有位牛津大学教授名叫维克托·迈尔-舍恩伯格,人们将他奉为“大数据之父”,他在《大数据时代》的书中写道:“只有5%的数字数据是结构化的且能适用于传统数据库。”企业要想采用智能分析、图像识别等一系列先进算法来使大数据结构化,是需要付出高额花费的。
听说,现在我的同族太多太多了,而且,还总在源源不断地冒出来,我们出现的这种方式被人们叫做“数据洪流”。
据IDC在2018年11月公布的数据来看,全球超过一半的数据创建于过去两年。预计从2018到2023年,全球数据空间的复合增长率(CAGR)将达25.8%。海量数据的产出已经成为日常。随着数字化进程的加速,各种来源的数据都在以 GB、TB 甚至 PB 级的规模出现。
人们发现,比数据量更值得关注的是数据价值,后者来自数据分析及其中所蕴含的洞察。数据中可能蕴藏着未来的重要商机、推动社会进步以及科学发现的动力。
于是,企业数据的存储与处理能力也在不断受到挑战。Gartner副总裁兼杰出分析师Donald Feinberg就曾经表示:“数据量正在快速增多,实时将数据转化成价值的紧迫性也在同样快速增加。新的服务器工作负载不仅需要更快的CPU性能,而且还需要大容量内存及更快的存储。”

云计算来了以后,我就经常出现在数据中心里。服务器比我早些年经常待的PC机空间大了不少,不过CPU依旧是“寸土寸金”,同样,越接近CPU,数据的存取速度越快。虽然CPU片上的高速缓存时延为纳秒级,不过主流服务器上的CPU缓存基本上也只能接近100MB。以往,这一重任落在DRAM内存上(动态随机存取存储器 Dynamic Random Access Memory)。但通常,DRAM内存容量也比较小,要换装大容量的又成本太高。而且一断电,内存上我的族群们就会全部走丢,所以,之后系统和应用在重新启动时,还需要花费相当多的时间去重新把他们找回来,加载到内存中。
人们为了我们数据家族可真是操碎了心。整个行业都在采用基础设施创新、多种工具与手段、以及最佳实践等方法来推动数据分析和挖掘,也取得了很多的成果。随着数据量和种类的增多,用户期待以越来越快的速度获取数据洞察。
真正有效利用所有数据,促进数据流动,提升数据的可处理性,一直是人们所关心的,如今,需要寻找机会突破数据吞吐量的瓶颈,我们的更多价值才能够被发现。
为了让我的族群可以多一层缓冲,更流畅地流动、被处理和被分析,减少我们加速“换档”时的“顿挫感” ,英特尔推出了傲腾数据中心级持久内存,这是位于DRAM内存层和存储层之间的一种新型内存。
我发现,在Gartner发布的2019年十大数据与分析技术趋势里,“持久内存服务器”就位列其中。
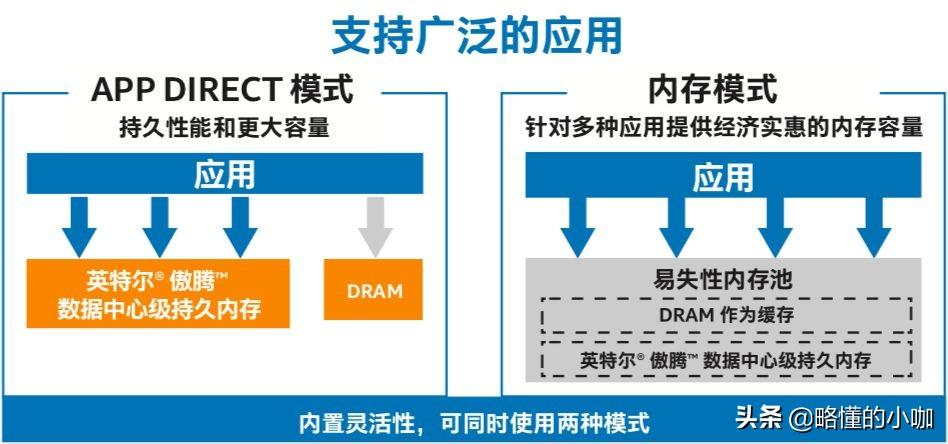
英特尔傲腾数据中心级持久内存的三种应用模式
英特尔傲腾数据中心级持久内存既可以是内存,也可以是存储,它可以通过两种特殊的运行模式—— App Direct模式和内存模式来实现独特的能力。利用 App Direct模式,经过专门调试的应用程序可从产品固有的持久性中充分获取价值并获得更大的容量;在内存模式下,可将该产品用作易失性存储,从而在无需重写软件的情况下有效利用最高达512GB的内存模块。如果用户既对内存模式有需求,又有工作负载需要运行在 App Direct 模式下,那么,英特尔傲腾TM 数据中心级持久内存就可激活第三种工作模式——双重模式。
现在,已经有很多在云基础设施及数据分析任务中被内存资源不足所困扰的企业,采用了英特尔傲腾数据中心级持久内存来缓解压力。
百度Feed 流服务的核心模块Feed-Cube 逐步从纯 DRAM 内存的配置模式迁移至纯英特尔傲腾数据中心级持久内存的配置,其系统构建成本也随之不断降低,百度卓有成效地降低了总拥有成本。
微软Windows Server 2019/Hyper-V多租户虚拟化的联机事务处理 (On-Line Transaction Processing,OLTP)云基准测试中,使用DRAM内存和英特尔傲腾数据中心级持久内存组合的平台,与仅使用DRAM内存的平台相比,内存容量提升达33%,每节点虚拟机数量提升达到36%,使每台虚拟机的硬件成本降低30%。
SAP的大型数据计算平台HANA分别在3TB DRAM内存平台和3TB DRAM内存+6TB英特尔傲腾数据中心级持久内存平台上进行了性能测试。结果表明,后者可以让系统重启速度从20分钟缩短到90秒,大幅减少的停机时间可以使每TB数据库容量的成本节约 39%。
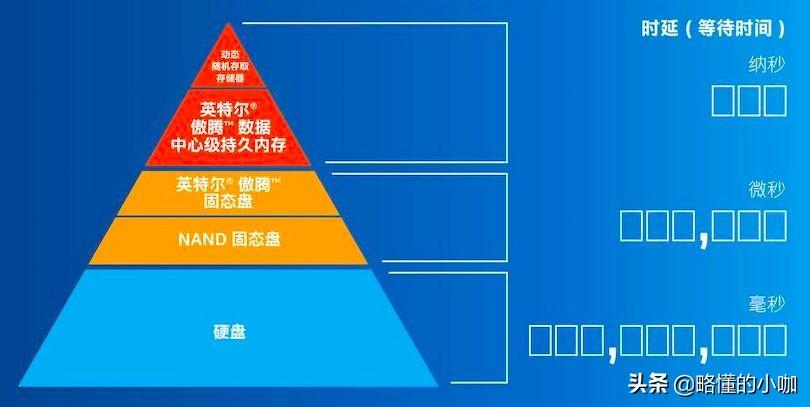
英特尔傲腾数据中心级持久内存填补了内存/存储金字塔中的重要缺口
英特尔傲腾数据中心级持久内存提供的新内存层,为高性能工作负载提供经济高效的大容量内存。第二代英特尔至强可扩展处理器所支持的傲腾数据中心级持久内存能够以更快的速度为每个平台提供更大的总内存容量,以更快的速度进行对持久数据的字节可寻址访问。
英特尔傲腾数据中心级持久内存,与英特尔第二代至强可扩展处理器相辅相承,将云和数据库中的关键数据工作负载转为内存分析和分发网络,让数据从负担变“富矿”。
正如两河流域的洪流哺乳了人类古老文明一样,英特尔傲腾数据中心级持久内存成为DRAM内存层和存储层之间的一种新型内存。作为一个字节,我和我的族人们在这里汇聚,这里蕴藏着无数的机遇与挑战。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号