OpenAI机器人风靡全球:编程、剧本创作,马斯克惊叹其强大!
发表时间: 2022-12-05 18:11
作者 | 凌敏、平川
写代码、编故事、构建虚拟机……聊天机器人 ChatGPT 还有多少惊喜是我们不知道的?
近日,OpenAI 发布了一个全新的聊天机器人模型 ChatGPT,这也是 GPT-3.5 系列的主力模型之一。目前,ChatGPT 还处于测试阶段,只需登录就能免费使用,OpenAI 希望可以通过用户反馈开发出更好的 AI 系统。
虽然类似的聊天机器人并不少见,但 ChatGPT 一经发布迅速火爆全网,并收获了无数好评。有开发者认为,有些技术问题就算问谷歌和 Stack Overflow,都没有 ChatGPT 回答得靠谱。
连马斯克也在感叹“很多人疯狂地陷入了 ChatGPT 循环中”,“ChatGPT 好得吓人,我们离强大到危险的人工智能不远了”。

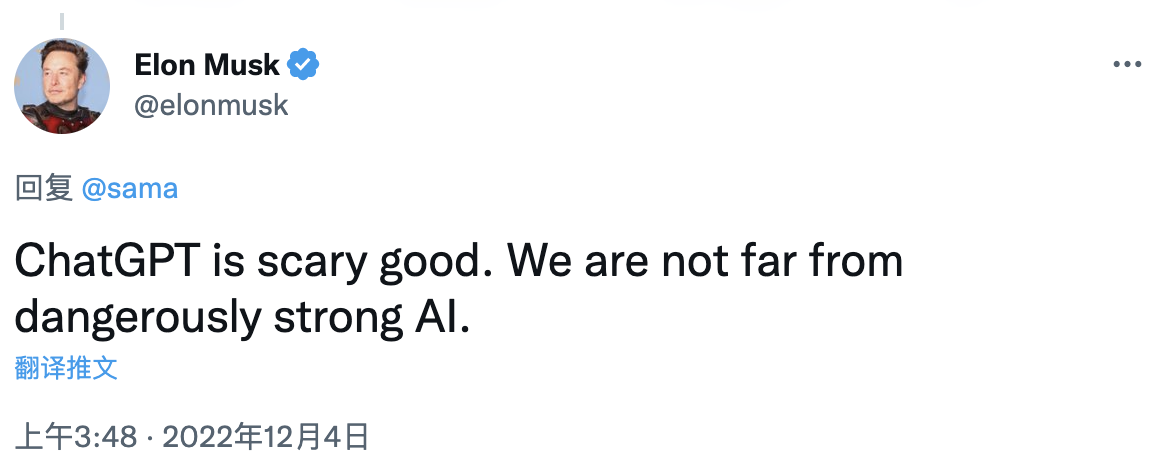
让马斯克盛赞、全网沸腾的 ChatGPT 到底有什么魔力?
根据 OpenAI 的介绍,ChatGPT 使用了与另一款 GPT-3.5 系列的模型 InstructGPT 相同的方法,但另外收集了 AI 与人类对话的数据,既包括人类自己的,也包括 AI 的,这些 AI 训练师可以参照建模建议写出自己的答案。

ChatGPT 开发过程
对于强化学习奖励模型,OpenAI 记录了 AI 训练师和聊天机器人之间的对话。然后,该团队随机选择了一个人工智能利用不同自动补全功能生成的回复,并让训练师对其进行评分。在进行微调时,OpenAI 使用了近端策略优化(proximal policy optimization),这个过程会反复进行多次。
目前,不少网友展示了与 ChatGPT 对话的有趣内容,并解锁了多个 ChatGPT 的用途。
有网友询问 ChatGPT 如何设计客厅,ChatGPT 给出了三种装饰方案,还贴心地给出了三幅设计图。
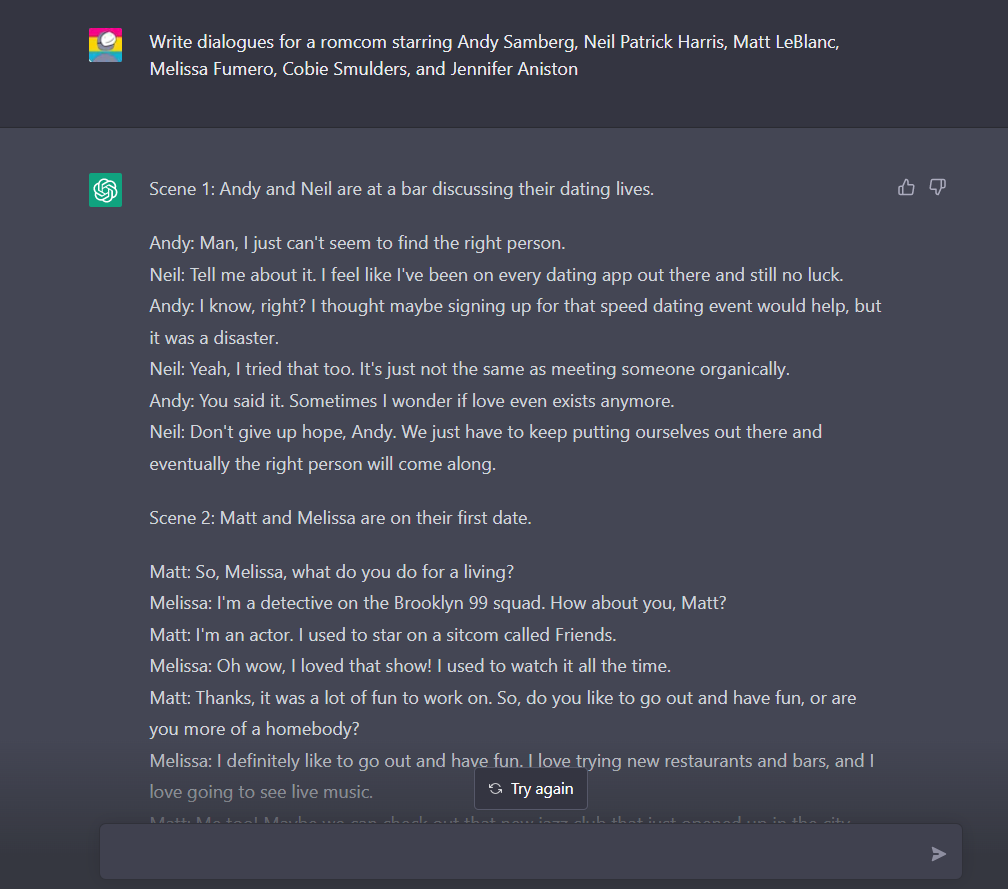
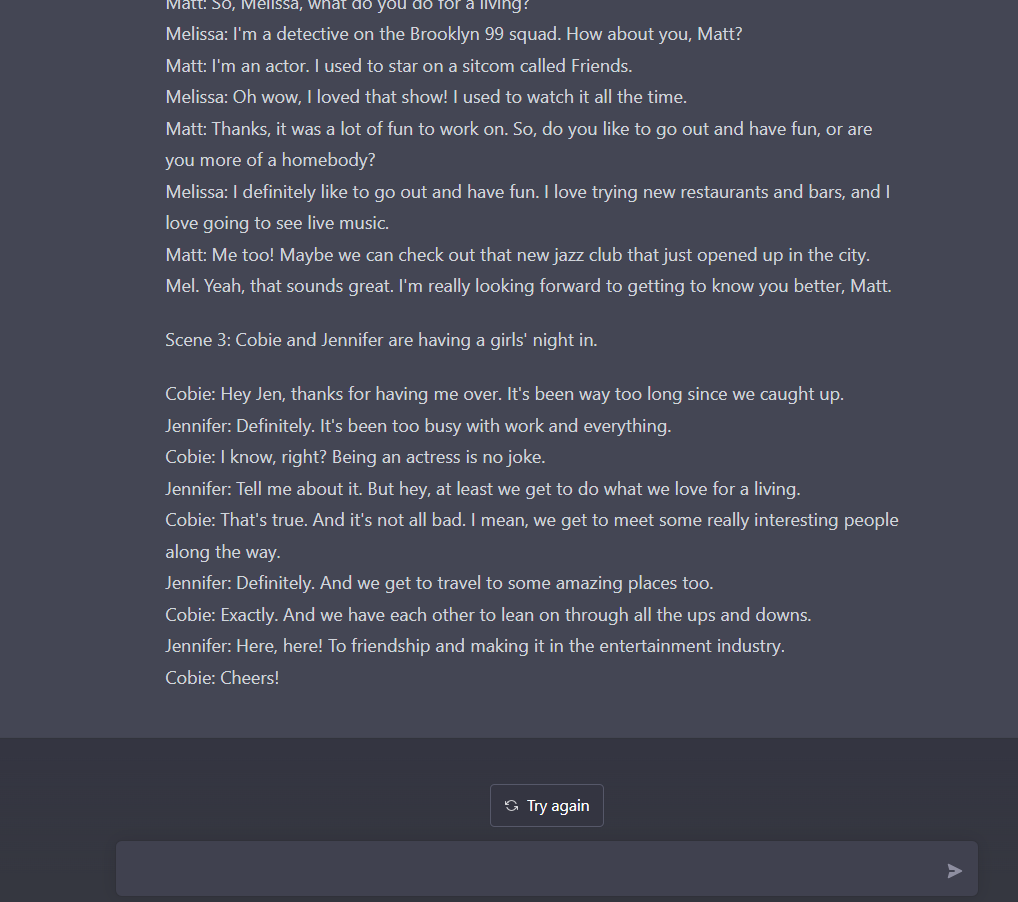
有网友用《老友记》等喜剧演员为角色,让 ChatGPT 写一些肥皂剧对白,ChatGPT 把好几个场景描绘得惟妙惟肖:
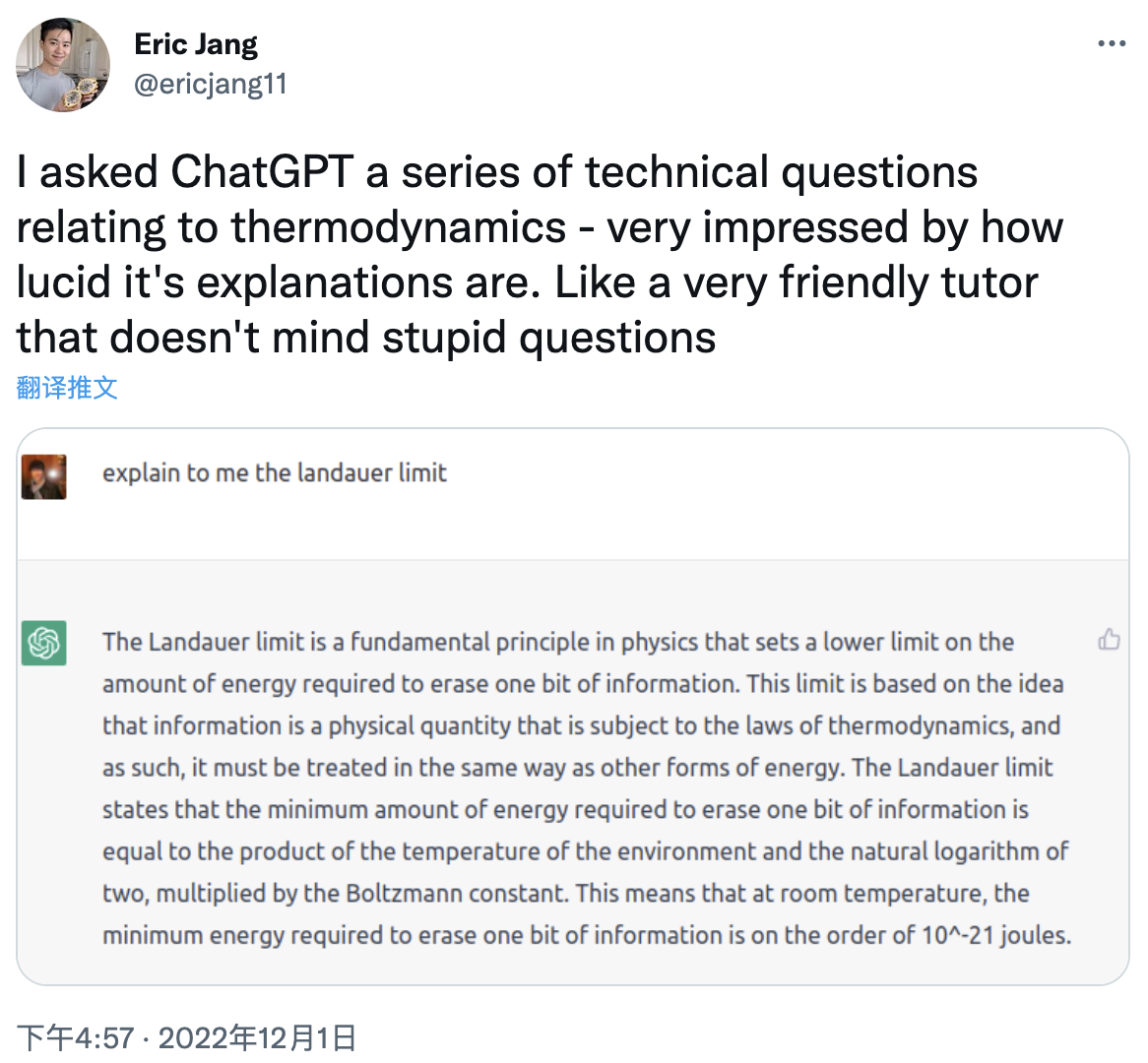
也能解释各种科学概念:
就连写论文这种比较有挑战的事情,ChatGPT 也冲上来试了试。

其中,最令人兴奋的当属 ChatGPT 在技术领域的用途。
区别于普通的聊天机器人,ChatGPT 显然更懂技术,它能写代码、改 Bug、创建编程语言、构建虚拟机……
与 GitHub 的 AI 编程神器 Copilot 相比,ChatGPT 似乎更能抢走程序员饭碗。技术公司 Replit CEO Amjad Masad 称赞 ChatGPT 是一个优秀的“调试伙伴”,“它不仅解释了错误,而且修复了它,并解释了修复方法”。
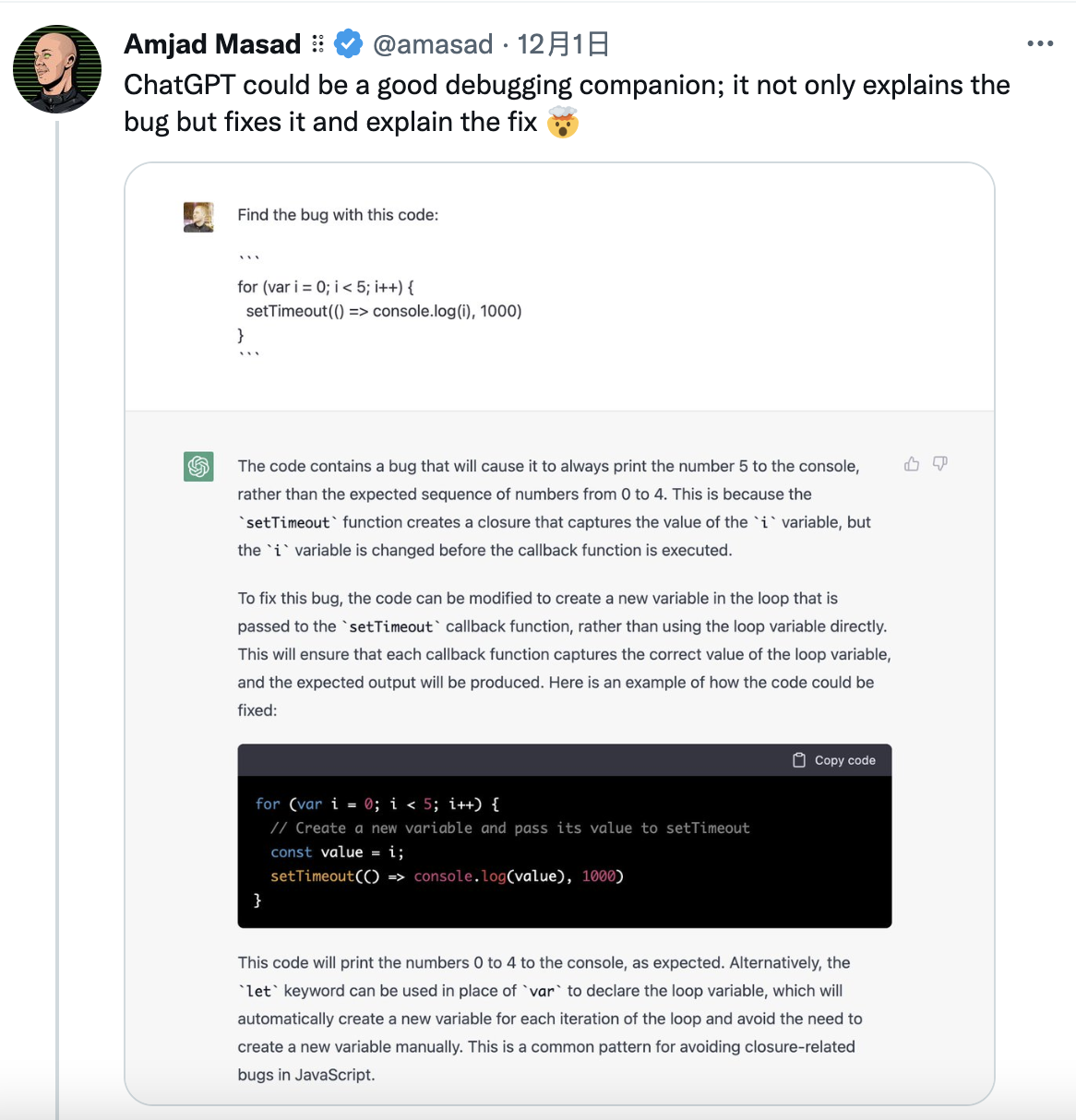
而对于一些更简单的问题,ChatGPT 更是“对答如流”,有网友在对比了谷歌的搜索结果和与 ChatGPT 的聊天结果之后,自信地宣称谷歌已经“完蛋”了。
虽然给大家带来了很多惊喜,但不得不承认,当前的 ChatGPT 还存在大型语言模型中常见的局限性。其中,部分网友对 ChatGPT 提供的回答准确性存在质疑。有网友指出,ChatGPT 提供的代码包含完全不相关的解释:
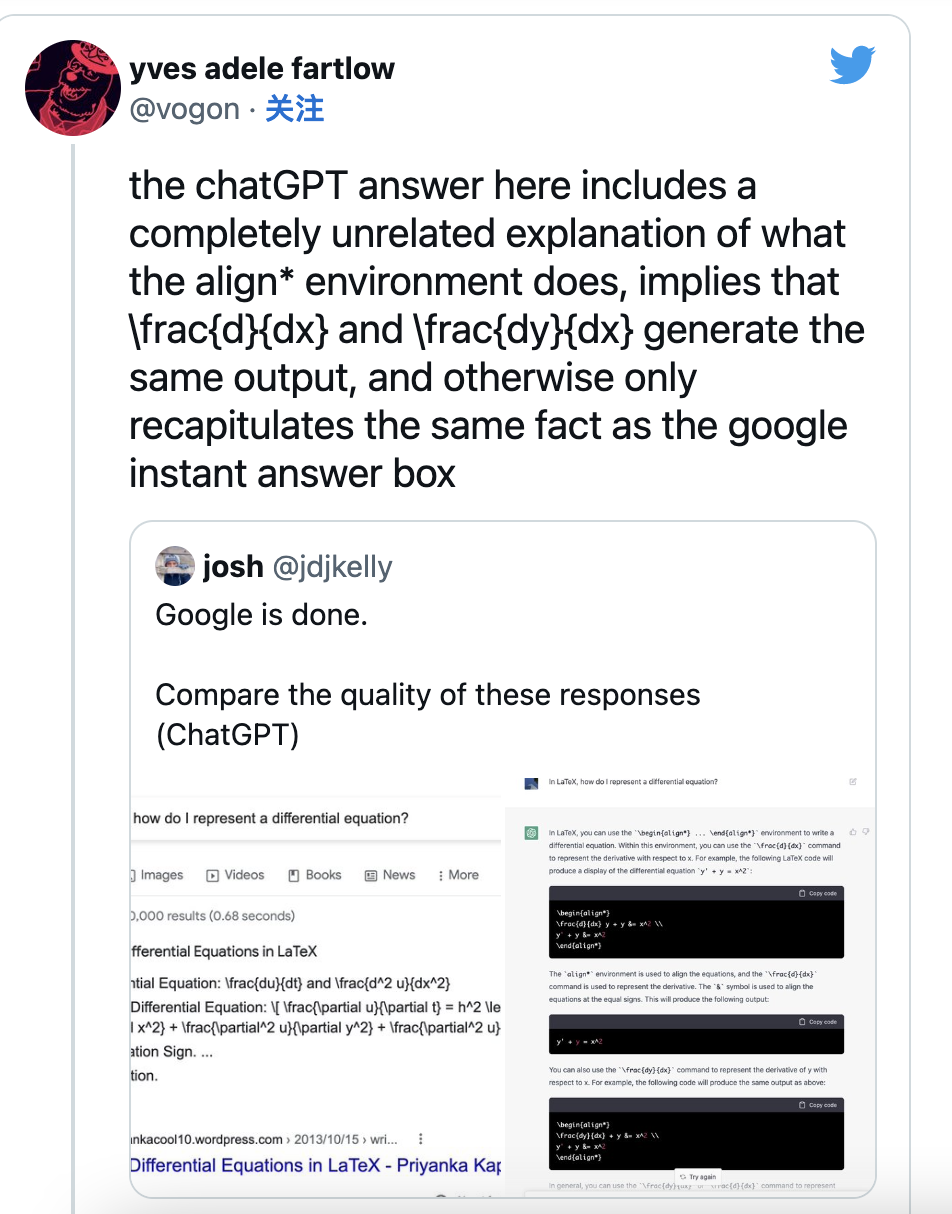
另外,ChatGPT 有时还会生成听起来合理,但既不正确又无意义的回复。按照 OpenAI 的说法,因为缺少单一事实来源,过度谨慎训练的模型会拒绝问题,而在有监督训练中,理想的答案取决于模型的知识,而不是人类演示者。
ChatGPT 对输入的微小变化也会有很大的反应。根据输入内容的不同,它可能不回答,回答错误内容,或者回答正确内容——根据 OpenAI 的说法,简单的重新措辞就可以了。此外,ChatGPT 的回答太过于冗长,大多使用短句,并爱说些车轱辘话。出现这种情况的原因是过度优化和人类导师的偏见,他们更喜欢人类反馈中那些比较详细的答案。
ChatGPT 不会用提问来回应不清楚的表述,而是尝试猜测用户的意图。有时,对于不恰当的请求,该模型会回应而不是拒绝它们。OpenAI 试图使用其适度性 API,来拒绝不符合其内容策略的请求。
如果你问 ChatGPT 它自己的意见,它会拒绝回答,给出的理由是没有接入互联网。
OpenAI 表示:“ChatGPT 模型还有许多局限性,所以我们计划定期更新模型,在这些方面做些改进。但我们也希望,通过提供 ChatGPT 的访问接口,获取宝贵的用户反馈,以发现我们尚未意识到的问题。”
虽然当前的 ChatGPT 还不算完美,但它像人们描述除了一个更光明的 AI 未来。谷歌母公司 Alphabet 的工程师评论道:
“像 GPT 这样的大型语言模型是谷歌活跃的 ML 研究的最大领域之一,并且有大量非常明显的应用程序可以用来回答查询、索引信息等。谷歌有大量预算与人员来处理这些类型的模型,并进行实际训练,这是非常昂贵的,因为训练这些超大型语言模型需要大量的计算能力。然而,我从谈话中收集到的是,在最大的谷歌产品(例如搜索、gmail)中实际使用这些语言模型的经济性还不完全存在。放一个大家感兴趣的演示是一回事,但考虑到服务成本,尝试将它深入集成到一个每天服务数十亿个请求的系统中是另一回事。我想我记得主持人说过他们希望将成本降低至少 10 倍,然后才能将这样的模型集成到搜索等产品中。
10 倍甚至 100 倍的改进显然是未来几年可以实现的目标,所以我认为这样的技术将在未来几年内出现。”
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号