Redis是什么?从需求出发,深入浅出解析其发展历程
发表时间: 2022-06-14 17:01
Redis为什么会出现?
一个东西的出现,总是有些原因的,一般都是为了解决某些问题,只有能够解决问题才能够产生价值,才能够持续地存在,并不断的演化发展。
Redis出现之前就有了CPU的多级缓存、memcache内存数据存储等,作为Redis的参考和学习对象。
Redis的出现是为了解决数据库读写磁盘的速度低的性能问题,定位内存数据库,内存比磁盘的读写速度要高至少2个数量级。Redis与数据库配合使用,既提升了性能,又能保证数据的持久化。
Redis(Remote Dictionary Server ),即远程字典服务,其实Re就是Remote,di就是Dictionary,s就是Server,Redis是新创造的一个单词,从名字本身就可以知道,Redis的核心就是一个key-value数据库,而且是基于内存的KV数据库。
(1) Redis是单线程吗?
Redis的核心读写功能是单线程的,但是不代表Redis只有一个线程,比如后台线程(异步处理一些耗时的操作,比如AOF、lazy-free)、后台RDB进程、后台AOF rewrite进程。
(2) Redis为什么要采用单线程方案?
首先题目的描述修改为“Redis的核心读写为什么采用单线程方案?”。
Redis的瓶颈不是CPU的IO,而是网络带宽和内存大小,单线程切换开销小,容易实现,因此就采用了单线程方案。
Redis作为数据库,如MySQL的缓存,采用单机部署使用,把热点数据保存到Redis中,提高读性能,减轻数据库的读压力。
问题1:
如果Redis出现异常,导致Redis服务死掉,就会出现保存在内存数据的丢失,数据库压力的陡然增大。如何解决Redis单机死掉数据的丢失问题?
解答1-1:
支持数据持久化,Redis死掉之后,重启之后,能够从持久化的数据快速的恢复,但是这个RTO (Recovery Time Objective)就受Redis发现问题,重启速度的限制,而RPO (Recovery Point Object)因数据持久化方案而定。
解答1-2:
支持Redis的高可用部署,确保一个Redis进程死掉的时候,其他Redis服务的正常。
问题2:
Redis数据持久化是如何实现的?
解答2-1:
采用RDB(Redis DataBase)方案,定时保存Redis的快照到磁盘。RDB采用二进制和数据压缩的方式写磁盘,使得文件体积更小,数据恢复速度也快。但是单机Redis死掉之后重启,必然会造成数据的损失。
解答2-2:
采用AOF(Append Only File)方案,实时把Redis的写操作追加到持久化文件。此种方案持久化数据最全,但文件体积大,数据恢复速度慢。能最大化的恢复Redis死掉时的数据,不包括Redis写入成功,还没有来得及写入磁盘的最后数据。
解答2-2-1:
AOF方案数据库比较大,由于多个key存在多次修改的情况,如何合并只保留最后一次的只,可以减小AOF文件的大小,称为AOF rewrite。
解答2-3:
进一步思考,在每一次AOF rewrite时,能否AOF rewrite之后,进行RDB快照,保存成文件,在RDB之后继续追加APF,这样可以进一步的减小持久化数据大小,称为混合持久化方案。
问题3:
如何进行高可用的部署?
解答3-1:
Redis进行主从部署,主节点实时读写,从节点实时从主节点同步数据,同时从节点也可以承担一部分的读操作。当主节点宕机之后,可以把从节点升级为主节点,继续进行工作。如果从节点宕机,主节点继续工作,不影响正常使用。但是此方案有一个问题,就是出现宕机情况后,需要人工操作,需要一个从发现到操作的时间差,这段时间会对系统产生一定的影响。
问题4:
如何在高可用部署中实现故障的自动切换?
解答4-1:
我们引入一个观察者,称为哨兵,哨兵负责检测Redis主从服务的状态,如果主节点发生异常,则发起主从切换;如果从节点发生异常,则发起告警,并尝试重启从节点服务。
问题5:
单个哨兵检测异常如何处理,如网络问题?
解答5-1:
可以采用哨兵集群,并且通过集群内部选主的方式,选举出哨兵Leader,由Leader收集检测结果,发起主从切换。选主的算法为raft算法。
问题6:
如何实现读性能的横向扩展?
解答6-1:
采用一主多从的模式,从节点负责分担读的压力。
问题7:
如何实现写性能的横向扩展?
解答7-1:
提升写性能,就需要部署多个实例,一个实例就是一个集群。多个实例就涉及到了路由选择,每一个实例的数据都是全体的一部分,所有实例的数据才是全部。此方案称为分片集群。根据路由策略,可以分为客户端分片、服务端分片。客户端分片,就需要在客户端代码逻辑中加入路由策略,增加了客户端代码的耦合性。因此有人把Redis路由策略从客户端代码分离出来形成单独的SDK,Redis Cluster方案就是采用此种方案。服务端分片,就是在客户端和Redis之间增加一个代理中间层,如Twemproxy、Codis就是采用这种方案来实现的开源软件。
问题8:
为什么会出现缓存穿透?应该如何解决?
解答8-1:
缓存穿透是指在Redis和数据库中都不存在的key,请求时直接穿透缓存到了数据库,如果大量的不存在的key发起攻击,会对数据库造成很大的压力,存在巨大的风险。
接口校验,对于不符合key规则的请求直接过滤,对于没有认证的请求直接过滤。
空值缓存,对于Redis和数据库都不存在的key,进行缓存,具体情况根据业务场景而定;
布隆过滤器,布隆过滤器存储key,请求过来之后,先用布隆过滤器进行过滤,不存在的可以直接过滤,存在的key再查询缓存和数据库。
问题9:
为什么会出现缓存击穿?应该如何解决?
解答9-1:
缓存击穿是指一个热点key,在过期的一瞬间,大量的请求击穿了缓存,压力都到了数据库,会造成数据库的访问压力,严重的造成数据库服务异常。
热点key设置永不过期。
加互斥锁,针对于同一个key的相同业务请求,同一时间只处理一个。
问题10:
为什么会出现缓存雪崩?应该如何解决?
解答10-1:
缓存雪崩是指大量的key,在同一时间过期,造成大量的请求直接压到数据库,造成数据库的异常甚至挂机。缓存雪崩可以认为是缓存击穿的升级版。
过期时间设置不能够同时,必须要分散;
热点数据不过期;
加互斥锁,针对于同一个key的相同业务请求,同一时间只处理一个;
比如电商系统典型的下单场景,多个用户同时发起下订单的请求,并发的要去减库存的商品数量,此时商品数量作为关键资源,要保证商品同一时间只有一个请求能够减库存,由于电商系统是分布式系统,无法通过本地锁来保证减库存的串行化执行,因此就需要采用分布式锁。
问题1:
什么是分布式锁?
解答1-1:
分布式锁就是要保证多服务对于关键共享资源能够串行化访问,此时需要引入一个外部的“锁”系统,能够实现互斥功能,一个时间只允许一个请求获得锁,获得锁才能对共享资源访问,没有获得锁不能访问共享资源。“锁”系统的实现方式有很多,比如数据库模式、Redis模式、Zookeeper模式。
分布式锁与单机锁的目的都是一样的,就是保证多服务对于共享资源的串行化访问,要完成此任务需要自身具有高性能、高安全的特性。高性能保证加锁解锁不会严重影响正常业务的执行时间和复杂度,高安全保证不要因为潜在的风险引发正常业务的新问题。
问题2:
Redis能否支持分布式锁的实现?
解答2-1:
Redis的内部指令执行具有原子性,而且通过集成lua脚步可以实现多个内部指令的原子性执行。使用SETNX命令,尝试获取锁,如SETNX lock 1,如果设置成功,就代表了获取锁成功。使用完成之后,通过DEL lock命令删除锁,这样其他进程就可以获取锁了。
问题3:
解答2-1,是最简单的分布式锁,但是存在着问题,如果获得锁的进程出现异常无法释放锁,或者进程死掉,就会导致锁一直不释放,其他进程一直无法获取锁。
解答3-1:
Redis2.6.12版本之后,增加了原子命令,SET lock 1 EX 10 NX,同步进行变量值设置和过期时间设置,这样就能够保障即使获得锁的进程出现异常或死掉,也能够即使释放锁,保证其他进程对锁的请求。
问题4:
解答3-1还是存在问题,如果锁过期之后,进程1还在使用共享资源应该怎么处理?如果锁过期之后,进程2获得了锁,此时进程1完成任务,进行释放锁操作,就把进程2的锁释放了,因此存在锁过期、释放其他进程锁的问题,应该如何解决?
解答4-1:
针对于锁过期,可以启动一个守护线程,定时检测任务完成情况和缩到期情况,如果任务没有完成,延期锁过期时间。
针对于释放其他进程锁的问题,我们可以看到,我们只是去设置同一个变量进行设置,而变量的值是没有用处的,此时每一个进程使用唯一ID去作为变量的值,每一次释放锁使,判断值是否自己设置的,值相同才能释放。这里设计了简单的逻辑,Redis没有专门的命令可以完成,为了保证原子性,需要使用lua脚本完成。也不用每个人都去实现,已经有了完善的实现Redisson,其中守护线程称为【看门狗】,锁延期称为【自动续期】,我们直接使用就可以了。
问题5:
以上都是针对单机Redis的分布式锁实现方案,如果是Redis的主从+哨兵部署方式呢,以上的加锁方式还能够正常吗?当然不能。如果在加锁、释放锁的周期内,发生了主从迁移,造成加在原有主节点上的锁,没有同步到新的主节点,比如造成锁的异常,但是Redis作者提出了Redlock解决方案。
解答5-1:
Redlock方案只允许部署主库,没有从库和哨兵节点,而且建议至少5个主库。Redlock使用过程中要注意几点:
一是,保证各服务器的时间同步,通过NTP的方式实现;
二是,加锁成功后,如果发生与锁系统的异常,如网络异常、进程暂停等极端情况,包括zookeeper分布式锁在内的其他分布式锁都会存在问题,即在极端情况下,分布式锁都是不安全的;
问题6:
用Redis实现分布式锁的优缺点?
解答6-1:
Redis分布式锁的性能优异,适用于高并发的业务场景;
Redis实现遵循CAP原则的AP原则,因此极端情况下会存在数据不一致的情况,如果是更注重数据一致性的业务场景,建议使用zookeeper实现分布式锁;
消息队列的主要作用是业务解耦、削峰填谷、异步调用等,在分布式系统中具有广泛的应用。
问题1:
消息队列是什么?具有什么特性?
解答1-1:
消息队列要运转起来,需要三个角色,一个是消息生产者,一个是消息中间件,负责存储和转发者,一个是消息的消费者,三者相互协作,共同完成消息队列的使命。
生产者负责生产消息,并发送到消息中间件,消息中间件存储消息。根据NPC异常问题考虑,生产者在生产消息过程中出现进程异常,应该在进程恢复后,进行生产消息是否生产完成的检测机制,没有生产完成,重新生成;在发送消息阶段,由于进程异常或网络延迟,在恢复之后,要检测消息是否发送成功,不成功需要重新发送;消息中间件收到消息进行存储,如果此时出现进程异常,恢复之后要判断是否存储成功,如果无法判断,需要生产者自行判断,重复发送。如果消息存储成功,需要给生产者发送确认消息。
消费者消费消息,需要连接消息中间件,进行消息的消费,消费方式有推、拉两种模式。不管是推还是拉,在NPC问题出现时,消息中间件都需要满足消费者的重复消费。消费者消费消息的过程中,要进行幂等处理,防止因为生产者的重复发送而产生业务处理的错误。
消息中间件对于消息的存储时间,必须满足所有消费者消费完成之后,才能够进行消息删除。在NPC问题出现时,消息中间件需要满足消息的持久化存储,和消息存储的不可丢失性。
问题2:
Redis可以实现消息队列功能吗?怎么实现?
解答2-1:
使用链表来实现,lpush或rpush作为生产者,rpop或lpop作为消费者,Redis作为消息中间件。
问题3:
采用链表作为消息队列存在问题,rpop或lpop可以持续的从队列获取nil消息,导致CPU资源空耗。
解答3-1:
可以通过判断nil进行休眠。但是如果休眠时间,生产者生产了消息,就要延迟进行消费了。CPU空耗和消息延迟消费,鱼和熊掌不可兼得。
但是Redis为我们提供了阻塞式拉取命令,brpop或blpop命令,兼顾CPU空耗和消息延迟消费问题。
问题4:
基于链表实现的消息队列,没有办法进行消息的重复消费,以及存在消息丢失问题。
如果消费者通过brpop或blpop命令获得消息之后,如果在增加一个消费者,是无法获得刚才的消息的。
如果消费者通过brpop或blpop命令获得消息之后,因为进程异常或网络异常,导致消息没有收到,而此时消息中间件已经删除了消息,导致消息丢失。
解答4-1:
Redis发布订阅 (pub/sub)能够实现多个消费者对消息进行重复消费。
问题5:
Redis发布订阅 (pub/sub)不支持消费者下线之后,重新上线之后进行已消费消息的重新消费,也就是消费者发生异常就会发生丢数据的问题。
消费者全部下线之后,生产者发送的消息全部丢失,也就是必须生产者和消费者同时在线,而且消费者必须先订阅生产者,否则就会发生消息丢失问题。
Redis发布订阅 (pub/sub)没有对数据进行持久化,Redis服务死掉之后,数据全部丢失。
Redis发布订阅 (pub/sub)对消息进行单独的缓冲区处理,超过缓冲区容量,数据就会丢失。
解答5-1:
Redis发布订阅 (pub/sub)虽然支持多消费者,但是消息丢失的风险太大,基本上此种方案的消息队列使用者不多。
Redis5.0之后增加了更加完善的消息队列方案Stream。Stream通过xadd和xread命令实现消息队列的基本业务逻辑,支持阻塞式消息拉取、支持订阅发布模式、支持消息持久化,重复消费(消费者消费成功后,提交xack命令才进行消息删除),但是消息堆积超过限定范围之后,会删除老数据,保持最新的数据,存在数据丢失问题。
总结:
Redis在不断的演化中,通过链表、发布订阅模式、Stream实现了消息队列,尤其是Stream除了数据丢失问题没有彻底解决,已经非常接近专业的消息队列软件了。但是由于Redis自身定位于内存数据库的局限性,对于消息队列的实现还是存在问题。有问题的消息队列不是不能用,而是选择对于数据部分丢失不敏感的业务场景,毕竟Redis的部署、运维、使用相比较其他专业的消息队列软件更加简单。
Redis是一个高速的内存数据库,支持高速的读写,特别的适用于目前的三高系统。在Redis使用过程中,如果出现了数据读写的缓慢,就会影响系统的性能,存在不稳定的因素,如何才能够精确的排查出问题,是Redis应用的必不可少的工作。
问题1:
Redis是否变慢的量化标准是什么?
解答1-1:
Redis是否变慢需要有一个标准,超过这个标准的平均操作时间就是变慢了,这个标准从哪里来?由于不同的服务器硬件、CPU、内存、操作系统等,因此不同的服务器的标准也不是整齐划一的,我们针对于每一个Redis服务实例进行测试。Redis为我们提供了相关命令:
1、 测试Redis实例60秒内的最大响应延迟(下图最大延迟25微秒)
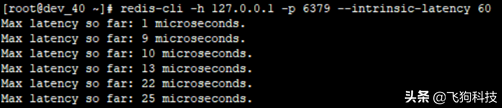
2、 查看一段时间内 Redis 的最小、最大、平均访问延迟(下图是10秒,平均耗时在0.24-0.28毫秒之间)
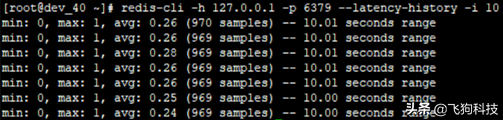
根据上面的验证,我们根据此Redis实例的慢执行为大于0.28*2=56微秒。
问题2:
影响Redis性能的因素有哪些?
解答2-1:
从Redis操作层面,到内存、CPU、磁盘、网络、计算机系统、操作系统等多层面,进行全面的排查,找出问题,提出解决问题的方法。
问题3:
如何判断那条指令或其他原因导致Redis变慢?
解答3-1:
一般耗时的Redis指令是操作比较复杂的聚合类指令,如sort;或者返回数据量比较大的指令,例如lrange key 0 100000000000。
首先是获得慢指令:使用Redis提供的查询慢日志功能,查找执行慢的指令。首先设置慢日志:
CONFIG SET slowlog-log-slower-than 560#设置Redis命令执行超过56微秒,记录到慢日志
CONFIG SET slowlog-max-len 1000#只记录最近的1000条
slowlog get 1#获取1条慢日志
其次是解决方案:过多的计算可以转移到客户端进行,一次返回的数据量要控制在比较小的范围之内,多次获取。
解答3-2:
bigkey在创建和删除的时候比较耗时,会造成Redis变慢。Redis提供了bigkey的查询命令:redis-cli -h 127.0.0.1 -p 6379 --bigkeys -i 0.01。
解决方案:尽量避免bigkey。自Redis4.0版本开始,引入lazy-free 机制,专门用于大健的回收,如在执行 DEL 命令时,释放内存会放到lazy-free线程中执行,不会造成主线程的负载。
Redis4.0版本时只有lazyfree_lazy_eviction、lazyfree_lazy_expire、lazyfree_lazy_server_del,Redis7.0版本包含lazyfree_lazy_eviction、lazyfree_lazy_expire、lazyfree_lazy_server_del、lazyfree_lazy_user_del、lazyfree_lazy_user_flush。
解答3-3:
主动集中过期,当大量的key在同一时间过期时,Redis主进程会陷入缓慢,造成执行命令的延迟和等待。
解决方案:分散过期,不要集中过期;Redis4.0版本以后,可以采用lazy-free机制,启动lazy-free线程,进行集中过期处理。
解答3-4:
实例内存达到上线,会启动数据淘汰策略。
淘汰策略包括allkeys-lru、volatile-lru、allkeys-random、volatile-random、allkeys-ttl、noeviction、allkeys-lfu、volatile-lfu。
解决方案:根据业务的特点尽可能选择效率高的淘汰策略;Redis4.0版本以后,可以采用lazy-free机制,启动lazy-free线程,进行集中淘汰处理。
解答3-5:
Redis设置后台进行RDB 和 AOF rewrite,当执行时,会启动fork创建子进程,子进程进行RDB 和 AOF rewrite操作,而fork操作耗时。
解决方案:控制Redis实例的内存在适当的大小,实例越大,fork越耗时;合理配置数据持久化策略;Redis实例不要部署在虚拟机上;降低主从库全量同步的概率。
解答3-6:
Redis服务器,建议关闭大页内存。
应用程序向操作系统申请内存时,是按内存页进行申请的,而常规的内存页大小是 4KB。但是在Linux2.6以后增加了大页内存功能,支持默认2M的页。申请内存时,如果是2M,需要更多的时间,对于Redis这种高性能的服务,小页内存效率更高。
解答3-7:
AOF开启之后,会涉及到数据刷盘的策略选择问题,提供了三种策略appendfsync always(实时刷盘)、appendfsync no(操作系统决定刷盘时间)、appendfsync everysec(每隔一秒刷盘)。
Redis的AOF后台子线程刷盘操作,撞上了子进程AOF rewrite,会造成写进程,Redis提供了一个配置项,当子进程在AOF rewrite期间,可以让后台子线程不执行刷盘(不触发 fsync 系统调用)操作(o-appendfsync-on-rewrite yes)。
有条件的化,可以更换更为高效能的SSD磁盘,提高磁盘的IO能力,保证AOF期间有充足的磁盘资源可以使用。
解答3-8:
Redis绑定CPU就能够提升性能吗?当然不是,如果把Redis绑定到某个CPU,Redis的单线程模式,只是主线程,还有很多后台线程,会出现上下文切换,有可能造成Redis性能的损失。
Redis在6.0版本推出了多线程的详细配置,对主线程、后台线程、后台RDB 进程、AOF rewrite进程,绑定固定的CPU逻辑核心。
解答3-9:
SWAP影响。
如果你对操作系统有些了解,就会知道操作系统为了缓解内存不足对应用程序的影响,允许把一部分内存中的数据换到磁盘上,以达到应用程序对内存使用的缓冲,这些内存数据被换到磁盘上的区域,就是Swap。
如果Redis使用了磁盘存储,比如造成性能的下降。
解答3-10:
碎片整理。
Redis的数据都存储在内存中,当我们的应用程序频繁修改Redis中的数据时,就有可能会导致 Redis产生内存碎片。
Redis的碎片整理工作是也在主线程中执行的,当其进行碎片整理时,必然会消耗CPU资源,产生更多的耗时,从而影响到客户端的请求。
解答3-11:
网络过载。
Redis的高性能,除了操作内存之外,就在于网络IO了,如果网络IO存在瓶颈,那么也会严重影响Redis的性能。
Redis底层数据结构包括RAW、INT、HT、ZIPMAP、LINKEDLIST、ZIPLIST、INTSET、SKIPLIST、EMBSTR、QUICKLIST、STREAM、LISTPACK,是在不断的增加中的,其中LISTPACK就是在Redis7.0中增加的。
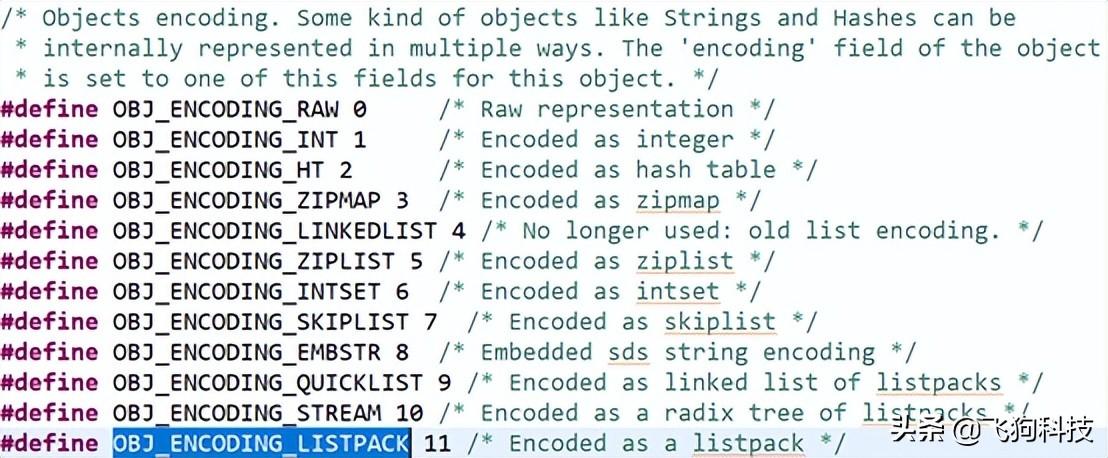
Redis底层数据结构
简单动态字符串(Simple Dynamic String,SDS),Redis中包含字符串值的键值对在底层都是由SDS实现的。
链表,Redis的链表是双向链表,除了链表对象外,还用于发布和订阅、慢查询、监视器等功能。
字典,Redis使用MurmurHash2算法来计算键的哈希值,并且使用链地址法来解决键冲突,被分配到同一个索引的多个键值对会连接成一个单向链表。应用于键空间和哈希对象。
跳跃表(Skip List),是基于单向链表,增加关键节点作为分层索引(类似于二分法),通过增加空间的方式,减少检索时间(空间换时间),应用于有序集合对象。
整数集合(intset)是集合对象的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis就会使用整数集合作为集合对象的底层实现。
压缩队列(ziplist)是列表对象和哈希对象的底层实现之一。当满足一定条件时,列表对象和哈希对象都会以压缩队列为底层实现。压缩队列是 Redis 为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构。
Redis使用SDS、链表、字典、跳跃表、整数集合、压缩队列等,构建了面向用户的5种数据结构String、Hash、List、Set、Sorted Set, 这5中数据结构都是通过redisObject进行组织的。

redisObject对象
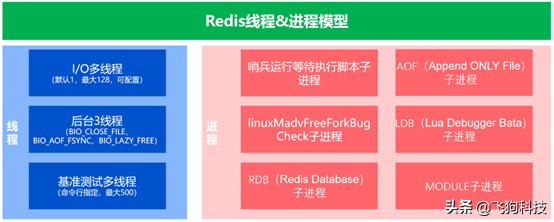
Redis线程&进程模型
(1) Redis7.0.0的I/O多线程
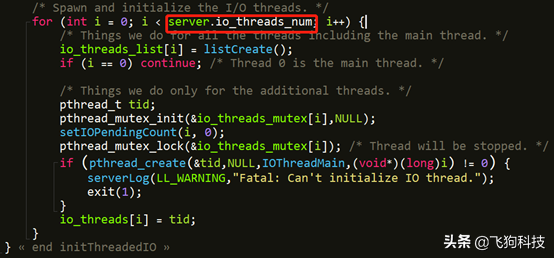
I/O线程的最大值为128,默认为1,其中第1个为主线程,其他为辅助线程,可以在redis.conf配置。
(2) 后台3线程

文件句柄的关闭、aof文件持久化、懒空间释放。
(3) 基准测试多线程
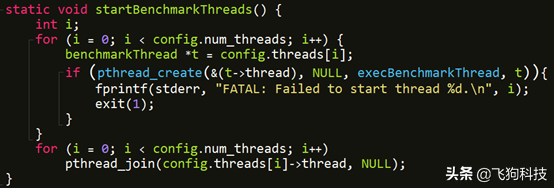
redis-benchmark命令,--threads <num>指定线程数,最大值为500。
(4) 哨兵运行等待执行脚本进程
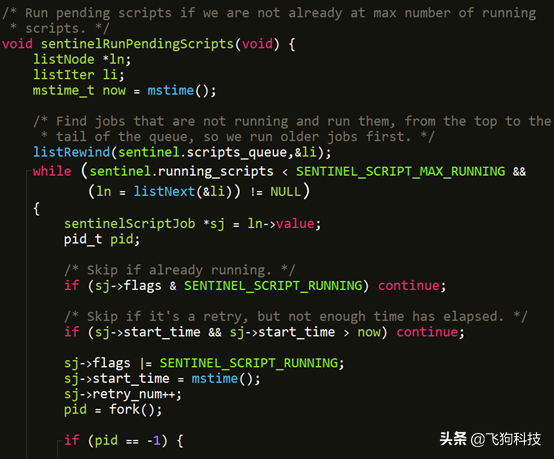
(5) linuxMadvFreeForkBugCheck进程
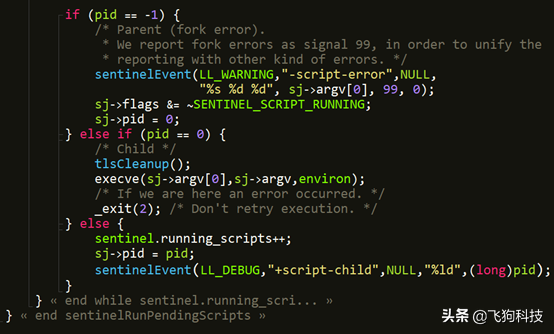
(6) 子进程(RDB(Redis Database)子进程、AOF(Append ONLY File)子进程、LDB(Lua Debugger Bata)子进程、MODULE子进程)
Redis对于TCP Socket API进行了封装,保存在anet源文件中。
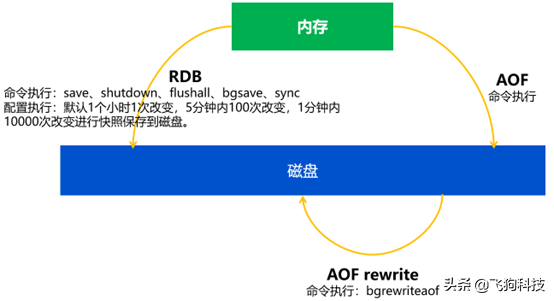
RDB
命令执行:save、shutdown、flushall、bgsave、sync
配置执行:默认1个小时1次改变,5分钟内100次改变,1分钟内10000次改变进行快照保存到磁盘。

Redis1.3.6版本源码,通过调用fwrite、fflush、fsync函数,进行数据存储。
AOF
执行命令时,同步进行AOF写操作到磁盘。
Redis1.3.6版本源码,通过调用write、fsync函数,进行数据存储。
AOF rewrite
执行bgrewriteaof命令时,进行AOF rewrite。
Redis1.3.6版本源码,通过调用fwrite、fflush、fsync函数,进行数据存储。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号