数据库历史阶段一览图
发表时间: 2019-08-11 00:02
数据库(Database)是存储与管理数据的软件系统,就像一个存入数据的物流仓库。
在商业领域,信息就意味着商机,取得信息的一个非常重要的途径就是对数据进行分析处理,这就催生了各种专业的数据管理软件,数据库就是其中的一种。当然,数据库管理系统也不是一下子就建立起来,它也是经过了不断的丰富和发展,才有了今天的模样。
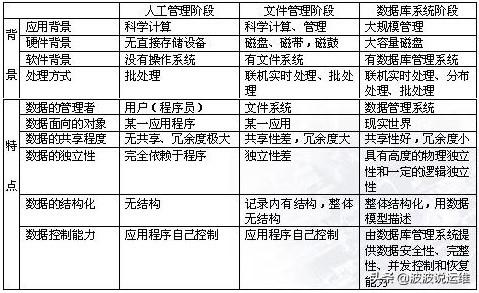
1.1、人工处理阶段
在20世纪50年代中期以前的计算机诞生初期,其处理能力很有限,只能够完成一些简单的运算,数据处理能力也很有限,这使得当时的计算机只能够用于科学和工程计算。计算机上没有专用的管理数据的软件,数据由计算机或处理它的程序自行携带。当数据的存储格式、读写路径或方法发生变化的时候,其处理程序也必须要做出相应的改变以保持程序的正确性。
人工管理数据具有如下特点:
1)数据不保存
2)数据需要由应用程序自己管理,没有相应的软件系统负责数据的管理工作
3)数据不共享
4)数据不具有独立性,数据的逻辑结构或物理结构发生变化后,必须对应用程序做相应的修改,这就进一步加重了程序员的负担。
1.2、文件系统
20世纪50年代后期到60年代中期,随着硬件和软件技术的发展,计算机不仅用于科学计算,还大量用于商业管理中。在这一时期,数据和程序在存储位置上已经完全分开,数据被单独组织成文件保存到外部存储设备上,这样数据文件就可以为多个不同的程序在不同的时间所使用。
虽然程序和数据在存储位置上分开了,而且操作系统也可以帮助我们对完成了数据的存储位置和存取路径的管理,但是程序设计仍然受到数据存储格式和方法的影响,不能够完全独立于数据,而且数据的冗余较大。
文件系统阶段特点为:
1)数据可以长期保存
2)由专门的软件即文件系统进行数据管理,程序和数据之间由软件提供的存取方法进行转换,使应用程序与数据之间有了一定的独立性,程序员可以不必过多地考虑物理细节,将精力集中于算法。
3)数据共享性差
4)数据独立性低
1.3、数据库管理系统
从20世纪70年代以来,计算机软硬件技术取得了飞跃式的发展,这一时期最主要的发展就是产生了真正意义上的数据库管理系统,它使得应用程序和数据之间真正的实现的接口统一、数据共享等,这样应用程序都可以按照统一的方式直接操作数据,也就是应用程序和数据都具有了高度的独立性。
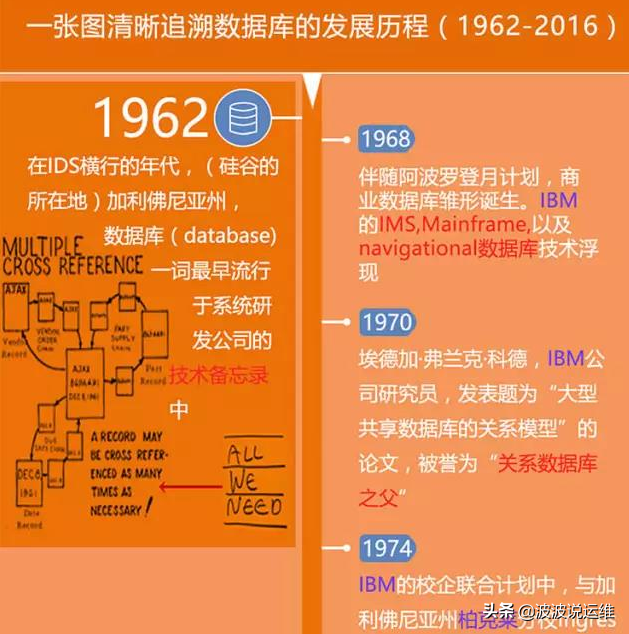
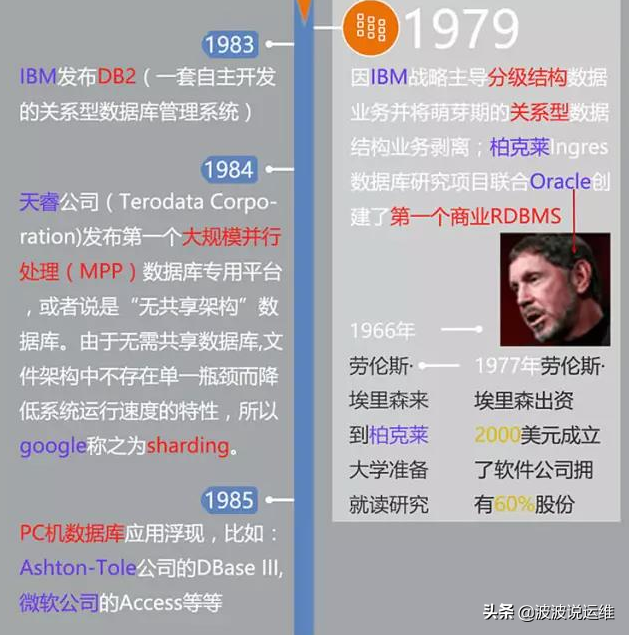
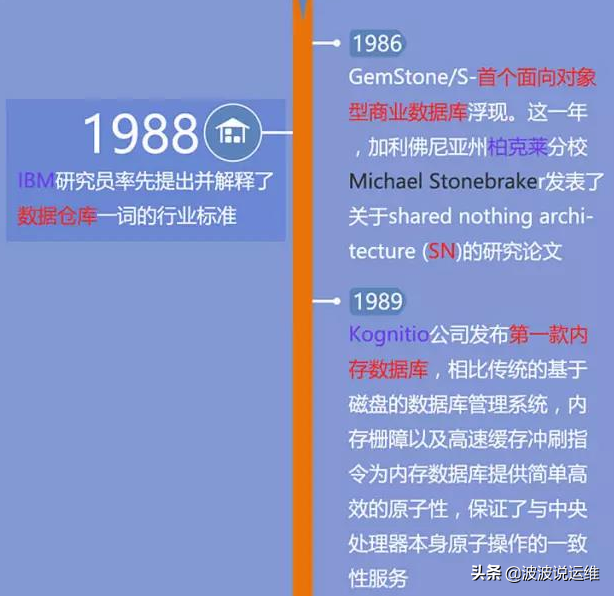

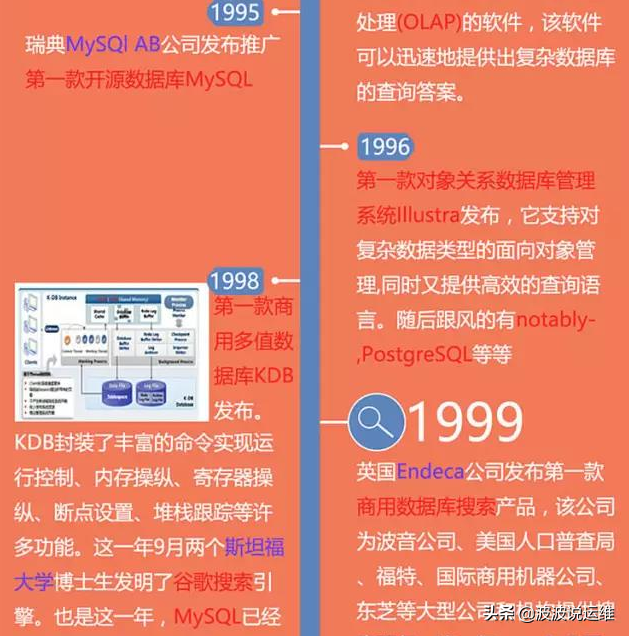

数据库系统阶段特点为:
1)数据结构化
2)数据的共享性好,冗余度低
3)数据独立性高
4)数据由DBMS统一管理和控制
发展了这么多年市场上出现了许多的数据库系统,最强的个人认为是Oracle,当然还有许多如:DB2、Microsoft SQL Server、MySQL、SyBase以及目前最火的PG等,下图列出常见数据库技术品牌、服务与架构。


数据库通常分为层次式数据库、网络式数据库和关系式数据库三种。
而不同的数据库是按不同的数据结构来联系和组织的。
而在当今的互联网中,最常见的数据库模型主要是两种,即关系型数据库和非关系型数据库。
3.1、关系型数据库
当前在成熟应用且服务与各种系统的主力数据库还是关系型数据库。
代表:Oracle、SQL Server、MySQL
3.2、非关系型数据库
随着时代的进步与发展的需要,非关系型数据库应运而生。
代表:Redis、Mongodb
NoSQL数据库在存储速度与灵活性方面有优势,也常用于缓存。
数据库设计过程分为六个阶段:
1、需求分析:准确了解与分析用户需求,(包括数据与处理)。需求分析是整个设计过程的基础,需求分析的结果是否准确反映了用户的实际需求,将直接影响到后面各个阶段的设计、并影响到设计结果是否合理和实用。
2、概念结构设计:数据库逻辑结构依赖于具体的DBMS,在将现实世界需求转换为机器世界的模型之前,我们先以一种独立于具体数据库管理系统的逻辑描述方法来描述数据库的逻辑结构,即设计数据库的概念结构。概念结构设计是整个数据库设计的关键,它通过对用户需求进行综合、归纳与抽象,形成一个独立于具体DBMS的概念模型。
3、逻辑结构设计:逻辑结构设计是将抽象的概念结构转换为所选用的DBMS支持的数据模型,并对其进行优化。
4、数据库物理设计:数据库物理设计是对为逻辑数据模型选取一个时候应用环境的物理结构(包括存储结构和存取方法)
5、数据库实施
6、数据库运行和维护
经过一系列的步骤,我们现在终于将客户的需求转换为数据表并确立这些表之间的关系,那么是否我们现在就可以在开发中使用呢?答案否定的,为什么呢!同一个项目,很多人参与了需求的分析,数据库的设计,不同的人具有不同的想法,不同的部门具有不同的业务需求,我们以此设计的数据库将不可避免的包含大量相同的数据,在结构上也有可能产生冲突,在开发中造成不便。
5.1. 什么是范式
要设计规范化的数据库,就要求我们根据数据库设计范式――也就是数据库设计的规范原则来做。范式可以指导我们更好地设计数据库的表结构,减少冗余的数据,借此可以提高数据库的存储效率,数据完整性和可扩展性。
设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴德斯科范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。一般说来,数据库只需满足第三范式(3NF)就行了。
5.2. 三大范式
第一范式(1NF)
所谓第一范式(1NF)是指在关系模型中,对列添加的一个规范要求,所有的列都应该是原子性的,即数据库表的每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项。即实体中的某个属性有多个值时,必须拆分为不同的属性。在符合第一范式(1NF)表中的每个域值只能是实体的一个属性或一个属性的一部分。简而言之,第一范式就是无重复的域。
第二范式(2NF)
在1NF的基础上,非Key属性必须完全依赖于主键。第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或记录必须可以被唯一地区分。选取一个能区分每个实体的属性或属性组,作为实体的唯一标识。
第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。简而言之,第二范式就是在第一范式的基础上属性完全依赖于主键。
第三范式(3NF)
第三范式是在第二范式基础上,更进一层,第三范式的目标就是确保表中各列与主键列直接相关,而不是间接相关。即各列与主键列都是一种直接依赖关系,则满足第三范式。
第三范式要求各列与主键列直接相关,我们可以这样理解,假设张三是李四的兵,王五则是张三的兵,这时王五是不是李四的兵呢?从这个关系中我们可以看出,王五也是李四的兵,因为王五依赖于张三,而张三是李四的兵,所以王五也是。这中间就存在一种间接依赖的关系而非我们第三范式中强调的直接依赖。
未来的数据库必将:
1、数据库会随着业务云化,未来一切的业务都会跑在云端,不管是私有云或者公有云,运维团队接触的可能再也不是真实的物理机,而是一个个隔离的容器或者「计算资源」
2、多租户技术会成为标配,一个大数据库承载一切的业务,数据在底层打通,上层通过权限,容器等技术进行隔离
3、OLAP和OLTP业务会融合,用户将数据存储进去后,需要比较方便高效的方式访问这块数据,但是OLTP和OLAP在SQL优化器/执行器这层的实现一定是千差万别的。以往的实现中,用户往往是通过ETL工具将数据从OLTP数据库同步到OLAP数据库,这一方面造成了资源的浪费,另一方面也降低了OLAP的实时性。对于用户而言,如果能使用同一套标准的语法和规则来进行数据的读写和分析,会有更好的体验。
4、在未来分布式数据库系统上,主从日志同步这样落后的备份方式会被Multi-Paxos / Raft这样更强的分布式一致性算法替代,人工的数据库运维在管理大规模数据库集群时是不可能的,所有的故障恢复和高可用都将是高度自动化的。
后面会分享更多devops和DBA方面的内容,感兴趣的朋友可以关注下~
如果你觉得这篇文章对你有帮助, 请小小打赏下~

声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号