Node.js 如何定位模块?
发表时间: 2022-11-18 11:06
大家好,我是前端西瓜哥,今天我们来看看 Node.js 模块查找的原理。
模块有三种来源。
需要注意的是,"a/b" 这种不属于路径写法,它属于前两种,比如 "fs/promises"、"@babel/core"。
这里给一个例子:
const http = require('http'); // Node.js 内置包const { defaultContent } = require('./default'); // 开发者自己写的模块文件http.createServer((req, res) => { res.writeHead(200, { 'Content-Type': 'text/plain' }); res.end(defaultContent);}).listen(3200);我们使用 require() 方法,传入一个字符串标识符,模块查找的旅途就开始了。
首先分析标识符的风格,如果是不是路径的写法,我们会先找 Node.js 内置的包有没有匹配的,如果匹配,就导入对应模块,比如 require('http') 就能拿到一个 http 对象,可用于创建 web 服务等功能。
如果不匹配,会在当前文件的目录下,找 node_modules 目录,看里面有没有对应的包。如果找不到,就继续往父目录找,直到根目录。如果找不到,会报 Cannot find module '包名' 的错误。
包通常是一个文件夹,里面会有 package.json 文件,Node.js 会提取其中 main 字段对应的文件作为模块文件。如果没有,就依次查找该目录下的 index.js、index.json、index.node 文件。
需要查找的目录可以通过 module.paths 变量得到。
如果你熟悉 JavaScript 的原型链,你会发现它们非常相似,可以做类比以加深理解。
如果标识符是路径,会通过计算得到一个绝对路径,然后找到的是个目录,同上面找 npm 包的逻辑。
要是找不到,就加上后缀再找。后缀按顺序添加为:.js 、.json、.node,找到就立即返回。若一个文件没有后缀但被匹配到了,它会被当作 js 文件。
上面没说缓存的情况,其实我们会对模块做缓存,下面详细说明一下。
每当加载一个模块后,这个模块就会被缓存起来。
你可以在随意一个文件中输入得到缓存的内容,是一个哈希表,key 为模块的绝对路径,确保缓存命中,value 则是模块对象。
const { Module } = require("module");console.log(Module._cache);也能用 require.cache 变量拿到,它和 Module._cache 指向同一个对象。
Node.js 内置的模块也需要缓存,但它不会记录到 Module._cache 中,而是保存在 Module.
下面是一个例子,index.js 导入了 a.js,a.js 下引入了 lodash.get 包,模块缓存结果为:
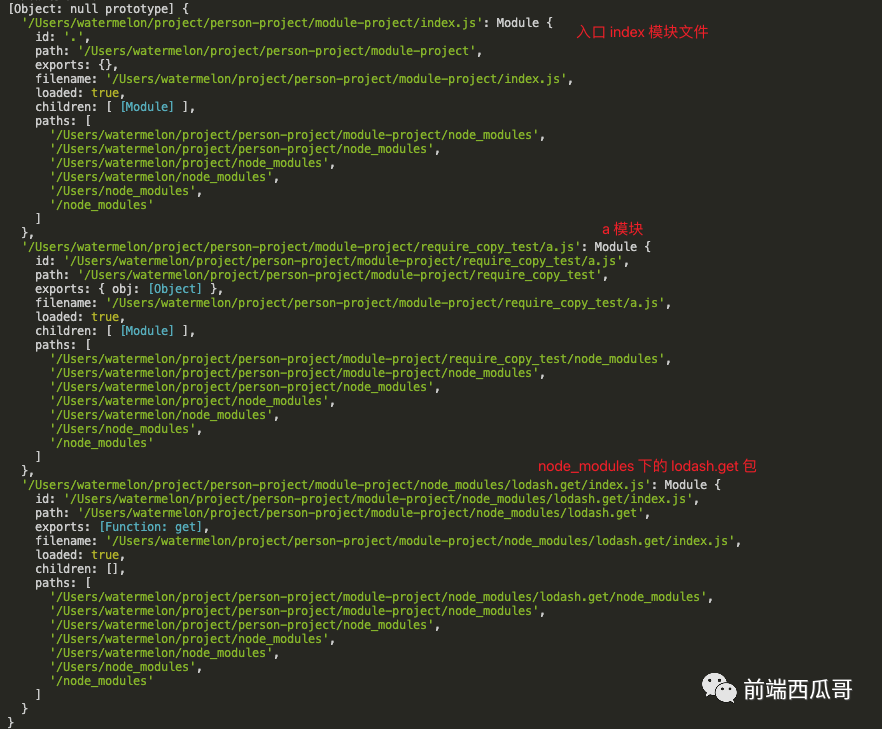
因为缓存的存在,所以 一个模块文件只会被执行一次,然后将 module.exports 缓存下来。
之后被多次导入,不会再执行这个模块文件,而是直接取出对应的 module.exports。
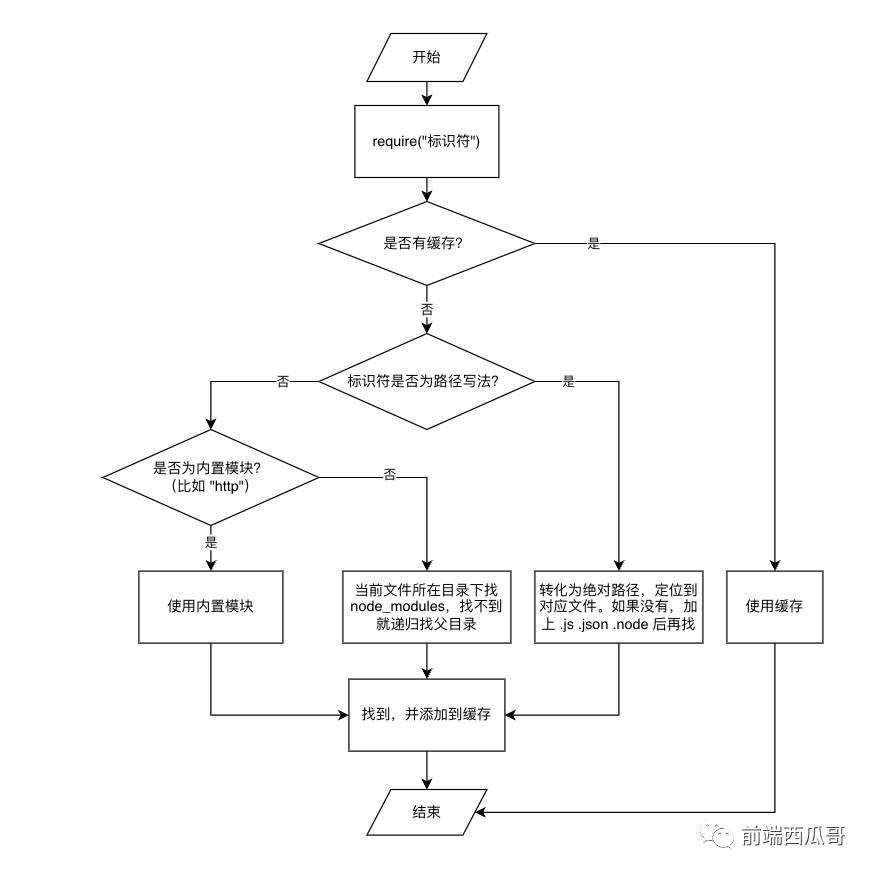
画了个流程图,丢掉了一些细节(路径定位到目录后的逻辑)。
我是前端西瓜哥,欢迎关注我,学习更多前端知识。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号