后端产品经理的数据库查询笔记
发表时间: 2018-10-06 19:03
本文从实际工作中梳理出7个方面的总结:数据库、常用sql语句、数据传输、文档语法、逻辑规则、交互方案、扩展技能。

随着数据量增大,业务扩展,服务器吃紧,加上开发跑路比较频繁,常常导致后端网站很‘烂’,这可能是你一段时间内不得不面对的常态。
这就决定了后端产品思维更要接近技术,绕不开百万级数据、业务逻辑、数据规则。在工作中无法像前端产品那样做甩手掌柜:反正我要的告诉你了,怎么实现我不管。而事实上往往还要产品给开发一两个建议方案,并告诉他要避免哪些坑,尽管这些都是前任的锅。
1、前端看到的内容,如果不是代码写死的,那么就是从数据库读取的(本地缓存的数据也算)。
2、早期比较流行的数据库模型有三种:层次式数据库、网络式数据库和关系型数据库。现今最常用的即关系型数据库和非关系型数据库。
3、关系型数据库:MYsql为典范,以二位报表的形式展示,因此MYSQL和PHP的组合是比较完美(报表多)。
4、比MYsql强大的关系型数据库还有ORACLE。比如1000W条数据以上级别的数据,一般用的比较多的是ORACLE。
5、MYsql每张表只能有一个主键。但开发会创建多个字段的索引。目的是为了提高查询速度。至少提升上百倍查询速度。
6、非关系型数据库(NoSQL):
NoSQL是作为传统关系型数据库的一个有效补充,处理对存储要求高,且并发处理较高的场合。
主要是数据库Mongodb。数据是散漫的,以键值对的形式存储。
7、分布式账本数据库:区块连的数据存储方式。也有叫时间轴数据库的。略知即可。
8、图片的存储比较特别:
一种是:直接把图片转换成二进制文件存储在数据库中。适合存储量少且重要的图片信息。
另一种是:存储图片的路径到数据库,用的时候直接调用路径给image等图像控件即可。适合存储量大但不是太重要的图片。
第二种方法常用,简单,实用。
1、建表的时候一般会增加冗余字段,比如unique_code,用于存储备用字段来去重。
2、建表的时候可以增加预留字段:当数据量大的时候很难再加新字段,所以预估到数据增张较快的,一定要预留几个字段空位。便于日后数据表扩展。
3、当一个表无法再加字段的时候可以增加扩展表 ,后缀_ext ,与原表通过id关联起来。
4、新增表字段:要考虑,到数据初始化比如历史数据全部为空或刷为某一个值。
5、统一规范表名前缀,比如可以定义t_前缀标示类型, f_ 前缀表示从其他系统获取的。
1、产品经理一般不去建表、改表,所以create table <表名> 、alter table <表名>、drop table <表名>知道就可以。
产品更多是查询、统计,或者写出更新/插入/删除语句让开发执行。
2、 select语句是使用最多的,配合函数:
count:统计记录数
avg:计算字段值的平均值
sum:计算字段值的总和
max:查询字段的最大值
min:查询字段的最大值
比如:select count(id) from p_product;
3、排序:order by 字段 desc/ASC
select * from finance_order order by update_time desc limit 3;
4、不包含某个字符
select * from table where ziduan not in(select ziduan from table where name = ‘C’)
5、包含某个字符
select * from table where 列名 like ‘a%’ 利用模糊查询
6、查询表p_product中的第10、11、12、13行数据
select * from product limit 4 offset 9;
或 select * from product limit 9,4;
7、in 括号内为或的关系
select name from product where goods in (‘103702505′,’103702805’) and (shelf_time > ‘2014-09-15 16:53:21’ or title like ‘_tylish%’);
8、去重搜索:
SELECT distinct(goods) FROM
9、 GROUP BY 语句进行组合。
SELECT Customer,SUM(OrderPrice) FROM Orders GROUP BY Custome
10、前10条记录
select top 10 * form table1 where
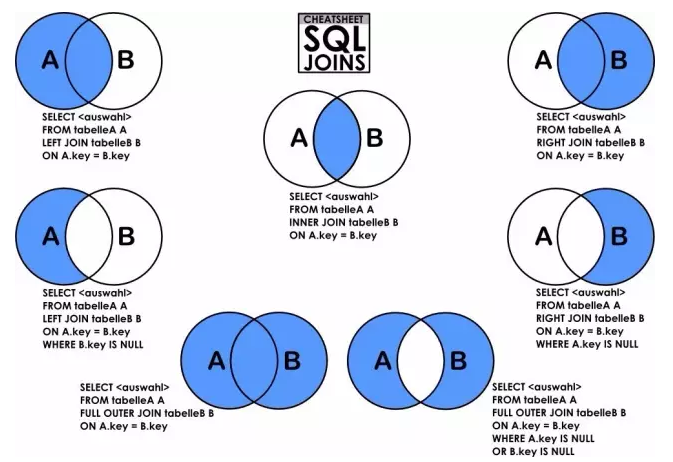
11、连表查询用join
Inner Join最常见,叫做内联接,可以缩写成Join,找的是两张表共同拥有的字段。
Left Join叫做左联接,以左表(join符号前的那张表)为主,返回所有的行。如果右表有共同字段,则一并返回,如果没有,则为空。
A Full Join B = A Left Join B + A Right Join B – A Inner Join B
还有其他连表方式既然用网络的图片:
12、查表 f_oms中字段order_number值相同的且数据量大于1个的
select order_number,count(*) from f_oms group by order_number having count(*)>1
13、从 “Persons” 表中选取居住的城市不以 “A” 或 “L” 或 “N” 开头的人:
我们可以使用下面的 SELECT 语句:
SELECT * FROM Persons WHERE City LIKE ‘[!ALN]%’
1、and优先级高于or,一般这种混合的句子建议用使关系清晰。
比如A>0 OR B<0 and c=0,相当于A>0 OR( B<0 and c=0)
2、点击‘美化SQL’按钮,可以将语句断层使层次清晰。比如where goods_sn in(‘A’,’B’,’C),美化后会变成:
where goods_sn in ('A','B','C)就可以用截取工具截取ABC,还原到excel表格的样式。
3、为防止数据导出因位数过长而使字符串变为科学计数法,导出的文件格式选择XLS格式的文档。
4、数据备份。
选中数据,右键点击复制为insert/update,可以直接将筛选的字段备份为更新或插入语句,一旦需要还原的时候可以直接执行这几个语句。

5、提升查询速度,SQL语句快于MYSQL自带的筛选选项,并且自带的只显示前一千条。所以优先使用语句查询。
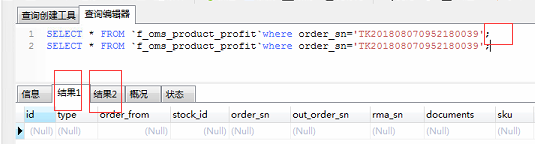
6、多个独立的查询语句之间可以用;隔开,同时执行,会分别输出。
7、导出的表头换成汉字注释的方式:
SELECT a.ds_sn as ‘编码’,a.pdt_name as ‘名称’ FROM p_pro
8、is和=有时是不同的,比如写作is null ,而不写=null
比<>!=规范。有时候不兼容。
本文由 @环滁皆山也 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号