数据库知识全解析
发表时间: 2020-04-23 16:46
数据库的发展基本上也是伴随着计算机技术经历了40年的历史,从最初的文件系统上的文件,到有结构的层次和网状数据库,一直到今天被广泛使用的关系型数据库。随着互联网和物联网行业的兴起,数据量飞速增长,对大数据的采集、存储和应用是每个数据库必备的技能。现在大多数应用都是数据存储密集型,而不是计算密集型。
众所周知,文明的发展离不开信息的积累,而任何东西的积累离不开存储。因此,信息存储是文明发展的重要环节,从某种意义上讲,甚至可以说是人类迈入文明社会的标志之一。在历史上,人类曾经创造过很多信息存储的方法。我们一起来看下存储发展历程。
古老的东方开始使用甲骨文记录着自己的数据。

到了东汉,人们开始用纸张记录数据。纸的出现使得信息的记录、传播和继承,有了革命性的进步,促进了人类文化的传播。同时纸也为后来打孔卡的出现奠定了基础。

到了近代有了打孔卡、磁带、软磁盘(记得小时候初中一年级见到的电脑好像是这种存储)、硬盘。以前大学上计算机课,总是听老师讲以前的U盘都是几M的,现在的U盘都有上百G的,而且很便宜。
存储现在发展的已经很快,现在存储数据很廉价。而数据库的必备功能就是存储数据。
传统的关系型数据库大家都接触的比较多,比如常见的Oracle、MySQL、PostgreSQL。数据库中每个属性都有特性的类型来定义,可以把数据想象成一个个表格存储着。和我们记录数据的认知非常相似,一行行记录着信息。
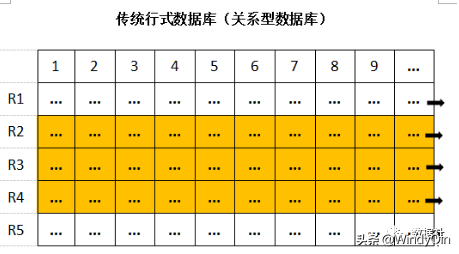
例如学生表里一条记录,就是一个学生他的属性描述,包括年龄、性别、出生年月日、所属班级等。但班级也有它的更详细的属性,那就可以在学生表里增加一个关系字段来表示该学生所属的班级索引,通过索引连接到班级表,可以查到这个班级的年级、班主任、学生人数等信息。
随着移动互联网时代的到来,需要存储的数据量越来越大,对机器的扩展要求成为了数据库的必备技能,这也是传统数据库的弱点,比如Oracle在做集群是很有限的。NoSQL对于数据库的扩展和高可用是它的强项。
那为什么NoSQL能够有可扩展和高可用呢?
我们都知道CAP理论,CAP理论指的是一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
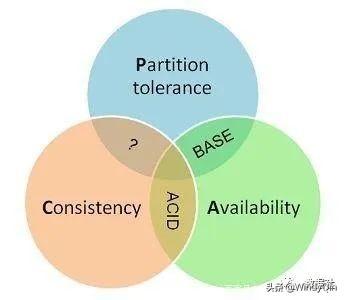
分布式系统的一致性通常称为ACID,即原子性、一致性、隔离性、永久性,传统的关系型数据库都能做到。简单的你可以理解一致性为数据写入数据库中,后续读取是否能立刻读取到更新的最新值。
另外,我们可以看到大多数NoSQL数据库都是“弱一致性”的,强调的是“最终一致性”,可以理解为如果你停止向数据库写入数据,并等待一段不确定的时间,那么最终所有的读取请求都会返回相同的值。换句话说,不一致性是暂时的,最终会解决。通过让系统放松对某一时刻数据一致性的要求来换取系统整体伸缩性和性能上改观。显然,NoSQL大都是用一致性来换取了可用性和分区容错性。那么牺牲一致性到底值不值得呢?举个例子,淘宝双十一当天,对于商品的评论和访问数可能不需要那么在意,首要是要保证服务器的高可用,崩了什么都白搭了!
在实际的应用中,存在一种场景,我们要求数据库必须保证ACID和高可用性,于是一批新型的数据库诞生了,比如蚂蚁金服的OcenBase和最近的“新晋网红”数据库TiDB。他们看似近乎完美的支持的分布式一致性和高可用性,支持标准SQL,对传统的关系型数据库提供迁移兼容方案。
还有一个数据库可以关注下,Vertica。很多人把Vertica划分到传统关系型数据库中,但是他与传统型关系库又有不同:
Vertica并不是一个广泛应用的数据库,我们上面提到了CAP理论,提到所有数据库不能同时满足“三性”,但是对于特性的应用场景设计,就能很大程度上在“三性”上取得平衡。
Vertica的原型称为“C-Store”,C-Store最早是2005年学术界的一个项目,作者是2015年图灵奖获得者 Mike Stonebraker,同时也是Vertica的创办者。
论文总结一下三点:
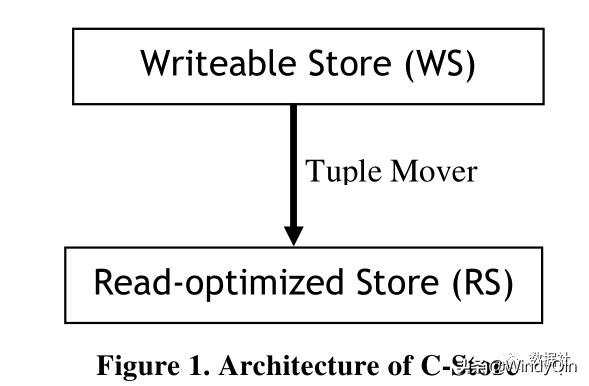
C-Store 应该是第一个将列存技术在实际系统中实现出来的,比Google的BigTable要早(公众号回复“列存储”,可下载C-Store和BigTable论文)。
其实以前的一些经典理论还是很有道理的,比如CAP、比如Raft呀,各个数据库还都是“术业有专攻”,别老想着用一种数据库打天下。比如,核心系统的事务数据还是选择使用MySQL或者postgreSQL。分析性数据库还是选择Vertica或者Greenplum。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号