掌握这12个MySQL面试题,让你的面试通过率飙升!
发表时间: 2019-05-09 00:02
想知道mysql dba运维面试时都会被问到哪些问题吗?特整理出20个运维经典面试题供大家参考学习,据说知道一半答案的人,月薪能过万~
基本原理流程,3个线程以及之间的关联;
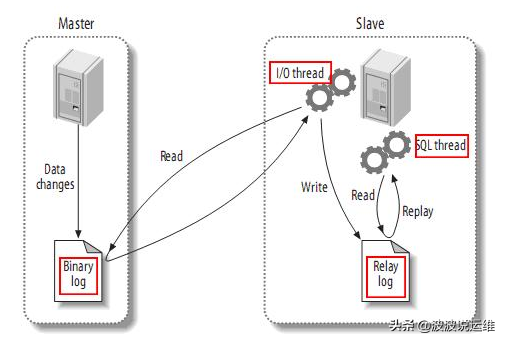
(1)主:binlog线程——记录下所有改变了数据库数据的语句,放进master上的binlog中;
(2)从:io线程——在使用start slave 之后,负责从master上拉取 binlog 内容,放进 自己的relay log中;
(3)从:sql执行线程——执行relay log中的语句;
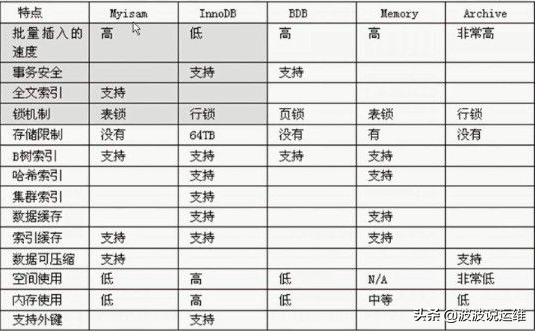
(1)、问5点不同:
1>.InnoDB支持事物,而MyISAM不支持事物
2>.InnoDB支持行级锁,而MyISAM支持表级锁
3>.InnoDB支持MVCC, 而MyISAM不支持
4>.InnoDB支持外键,而MyISAM不支持
5>.InnoDB不支持全文索引,而MyISAM支持。
(2)、innodb引擎的4大特性:
插入缓冲(insert buffer);
二次写(double write);
自适应哈希索引(ahi);
预读(read ahead)。
(3)、2者select count(*)哪个更快,为什么
myisam更快,因为myisam内部维护了一个计数器,可以直接调取。
(1)、varchar与char的区别
char是一种固定长度的类型,varchar则是一种可变长度的类型。
(2)、varchar(50)中50的含义
最多存放50个字符,varchar(50)和(200)存储hello所占空间一样,但后者在排序时会消耗更多内存,因为order by col采用fixed_length计算col长度(memory引擎也一样)。
(3)、int(20)中20的含义
是指显示字符的长度
但要加参数的,最大为255,比如它是记录行数的id,插入10笔资料,它就显示00000000001 ~~~00000000010,当字符的位数超过11,它也只显示11位,如果你没有加那个让它未满11位就前面加0的参数,它不会在前面加0
20表示最大显示宽度为20,但仍占4字节存储,存储范围不变;
(4)、mysql为什么这么设计
对大多数应用没有意义,只是规定一些工具用来显示字符的个数;int(1)和int(20)存储和计算均一样。
(1)、有多少种日志:
错误日志:记录出错信息,也记录一些警告信息或者正确的信息。
查询日志:记录所有对数据库请求的信息,不论这些请求是否得到了正确的执行。
慢查询日志:设置一个阈值,将运行时间超过该值的所有SQL语句都记录到慢查询的日志文件中。
二进制日志:记录对数据库执行更改的所有操作。
中继日志。
事务日志。
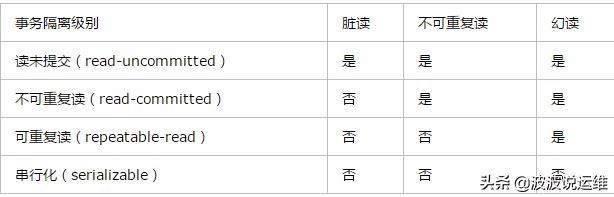
(2)、事物的4种隔离级别
mysql默认的事务隔离级别为repeatable-read
(3)、事务是如何通过日志来实现的
事务日志是通过redo和innodb的存储引擎日志缓冲(Innodb log buffer)来实现的,当开始一个事务的时候,会记录该事务的lsn(log sequence number)号; 当事务执行时,会往InnoDB存储引擎的日志缓存里面插入事务日志;当事务提交时,必须将存储引擎的日志缓冲写入磁盘(通过
innodb_flush_log_at_trx_commit来控制),也就是写数据前,需要先写日志。这种方式称为“预写日志方式”。
(1)、explain出来的各种item的意义;
select_type:表示查询中每个select子句的类型
type:表示MySQL在表中找到所需行的方式,又称“访问类型”
possible_keys:指出MySQL能使用哪个索引在表中找到行,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用
key:显示MySQL在查询中实际使用的索引,若没有使用索引,显示为NULL
key_len:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度
ref:表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值
Extra:包含不适合在其他列中显示但十分重要的额外信息。
(2)、profile的意义以及使用场景;
查询到 SQL 会执行多少时间, 并看出 CPU/Memory 使用量, 执行过程中 Systemlock, Table lock 花多少时间等等。
(1)、备份计划;
这里每个公司都不一样,别说那种1小时1全备什么的就行,建议根据数据量来说。
(2)、备份恢复时间;
这里跟机器,尤其是硬盘的速率有关系,以下列举几个仅供参考
20G的2分钟(mysqldump)
80G的30分钟(mysqldump)
111G的30分钟(mysqldump)
288G的3小时(xtra)
3T的4小时(xtra)
逻辑导入时间一般是备份时间的5倍以上
(3)、xtrabackup实现原理
在InnoDB内部会维护一个redo日志文件,我们也可以叫做事务日志文件。事务日志会存储每一个InnoDB表数据的记录修改。当InnoDB启动时,InnoDB会检查数据文件和事务日志,并执行两个步骤:它应用(前滚)已经提交的事务日志到数据文件,并将修改过但没有提交的数据进行回滚操作。
(1)、读取参数
global buffer pool以及 local buffer;
(2)、写入参数;
innodb_flush_log_at_trx_commit
innodb_buffer_pool_size
(3)、与IO相关的参数;
innodb_write_io_threads = 8
innodb_read_io_threads = 8
innodb_thread_concurrency = 0
(4)、缓存参数以及缓存的适用场景。
query cache/query_cache_type
并不是所有表都适合使用query cache。造成query cache失效的原因主要是相应的table发生了变更
第三个:小网站或者没有高并发的无所谓,高并发下,会看到 很多 qcache 锁 等待,所以一般高并发下,不建议打开query cache。
主从一致性校验有多种工具 例如checksum、mysqldiff、pt-table-checksum等。
(1)、选择拆成子表,还是继续放一起;
(2)、写出这样选择的理由。
答:拆带来的问题:连接消耗 + 存储拆分空间;不拆可能带来的问题:查询性能;
如果能容忍拆分带来的空间问题,拆的话最好和经常要查询的表的主键在物理结构上放置在一起(分区) 顺序IO,减少连接消耗,最后这是一个文本列再加上一个全文索引来尽量抵消连接消耗。
如果能容忍不拆分带来的查询性能损失的话:上面的方案在某个极致条件下肯定会出现问题,那么不拆就是最好的选择。
答:InnoDB是基于索引来完成行锁
例: select * from tab_with_index where id = 1 for update;
for update 可以根据条件来完成行锁锁定,并且 id 是有索引键的列,
如果 id 不是索引键那么InnoDB将完成表锁,,并发将无从谈起
在Mysqldump官方工具中,如何只恢复某个库呢?
全库备份
# mysqldump -uroot -p --single-transaction -A --master-data=2 >dump.sql
只还原erp库的内容
# mysql -uroot -pMANAGER erp --one-database <dump.sql
可以看出这里主要用到的参数是--one-database简写-o的参数,极大方便了我们的恢复灵活性。
那么如何从全库备份中抽取某张表呢,全库恢复,再恢复某张表小库还可以,大库就很麻烦了,那我们可以利用正则表达式来进行快速抽取,具体实现方法如下:
从全库备份中抽取出t表的表结构
# sed -e'/./{H;$!d;}' -e 'x;/CREATE TABLE `t`/!d;q' dump.sql DROP TABLE IF EXISTS`t`;/*!40101 SET@saved_cs_client =@@character_set_client */;/*!40101 SETcharacter_set_client = utf8 */;CREATE TABLE `t` ( `id` int(10) NOT NULL AUTO_INCREMENT, `age` tinyint(4) NOT NULL DEFAULT '0', `name` varchar(30) NOT NULL DEFAULT '', PRIMARY KEY (`id`)) ENGINE=InnoDBAUTO_INCREMENT=4 DEFAULT CHARSET=utf8;/*!40101 SETcharacter_set_client = @saved_cs_client */;从全库备份中抽取出t表的内容
# grep'INSERT INTO `t`' dump.sqlINSERT INTO `t`VALUES (0,0,''),(1,0,'aa'),(2,0,'bbb'),(3,25,'helei');
一个6亿的表a,一个3亿的表b,通过外间tid关联,你如何最快的查询出满足条件的第50000到第50200中的这200条数据记录。
1、如果A表TID是自增长,并且是连续的,B表的ID为索引
select * from a,b where a.tid = b.id and a.tid>500000 limit 200;
2、如果A表的TID不是连续的,那么就需要使用覆盖索引.TID要么是主键,要么是辅助索引,B表ID也需要有索引。
select * from b , (select tid from a limit 50000,200) a where b.id = a .tid;
后面会分享更多DBA方面的内容,感兴趣的朋友可以关注一下~

声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号