Java Web 抓取:程序员如何运用技巧?
发表时间: 2018-08-06 10:58


Web抓取非常有用,它可以收集信息供多种用途使用,如数据分析、统计、提供第三方信息,还可以给深神经网络和深度学习提供数据。

Web抓取是什么?
有一种非常广泛的误解,人们似乎把Web抓取和Web爬虫当成了同一种东西。所以我们先明确这一点。
两者有个非常显著的区别:
Web爬虫,指搜索或“爬”网页以获得任意信息的过程。通常是搜索引擎如Google、Yahoo或Bing的功能,以便给我们显示搜索结果。
Web抓取,指从特定的网站上利用特别定制的自动化软件手机信息的过程。

注意!
尽管Web抓取本身是从网站获取信息的合法方式,但如果使用不当,可能会变成非法。
有几种情况需要特别注意:
如果你想开发一个强大的抓取软件,请务必考虑以上几点,遵守法律和法规。

Web抓取框架
就像许多现代科技一样,从网站提取信息这一功能也有多个框架可以选择。最流行的有JSoup、HTMLUnit和Selenium WebDriver。我们这篇文章讨论JSoup。

JSoup
JSoup是个开源项目,提供强大的数据提取API。可以用它来解析给定URL、文件或字符串中的HTML。它还能操纵HTML元素和属性。
使用JSoup解析字符串
解析字符串是JSoup的最简单的使用方式。
public class JSoupExample {
public static void main(String[] args) {
String html = "<html><head><title>Website title</title></head><body><p>Sample paragraph number 1 </p><p>Sample paragraph number 2</p></body></html>";
Document doc = Jsoup.parse(html);
System.out.println(doc.title());
Elements paragraphs = doc.getElementsByTag("p");
for (Element paragraph : paragraphs) {
System.out.println(paragraph.text());
}
}
这段代码非常直观。调用parse()方法可以解析输入的HTML,将其变成Document对象。调用该对象的方法就能操纵并提取数据。
在上面的例子中,我们首先输出页面的标题。然后,我们获取所有带有标签“p”的元素。然后我们依次输出每个段落的文本。
运行这段代码,我们可以得到以下输出:
Website title
Sample paragraph number 1
Sample paragraph number 2
使用JSoup解析URL
解析URL的方法跟解析字符串有点不一样,但基本原理是相同的:
public class JSoupExample {
public static void main(String[] args) throws IOException {
Document doc = Jsoup.connect("https://www.wikipedia.org").get();
Elements titles = doc.getElementsByClass("other-project");
for (Element title : titles) {
System.out.println(title.text());
}
}
}
要从URL抓取数据,需要调用connect()方法,提供URL作为参数。然后使用get()从连接中获取HTML。这个例子的输出为:
Commons Freely usable photos & more
Wikivoyage Free travel guide
Wiktionary Free dictionary
Wikibooks Free textbooks
Wikinews Free news source
Wikidata Free knowledge base
Wikiversity Free course materials
Wikiquote Free quote compendium
MediaWiki Free & open wiki application
Wikisource Free library
Wikispecies Free species directory
Meta-Wiki Community coordination & documentation
可以看到,这个程序抓取了所有class为other-project的元素。
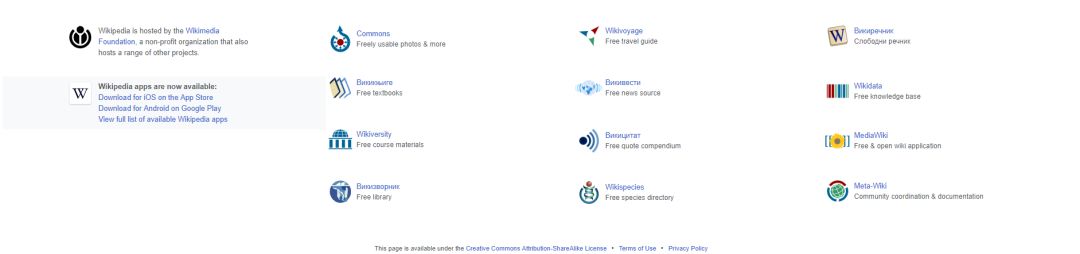
这种方法是最常用的,因此我们看一些通过URL进行抓取的其他例子。
抓取指定URL的所有链接
public void allLinksInUrl() throws IOException {
Document doc = Jsoup.connect("https://www.wikipedia.org").get();
Elements links = doc.select("a[href]");
for (Element link : links) {
System.out.println("\nlink : " + link.attr("href"));
System.out.println("text : " + link.text());
}
}
运行结果是一个很长的列表:
Link : //en.wikipedia.org/
Text : English 5 678 000+ articles
Link : //ja.wikipedia.org/
Text : 日本語 1 112 000+ 記事
Link : //es.wikipedia.org/
Text : Español 1 430 000+ artículos
Link : //de.wikipedia.org/
Text : Deutsch 2 197 000+ Artikel
Link : //ru.wikipedia.org/
Text : Русский 1 482 000+ статей
Link : //it.wikipedia.org/
Text : Italiano 1 447 000+ voci
Link : //fr.wikipedia.org/
Text : Français 2 000 000+ articles
Link : //zh.wikipedia.org/
Text : 中文 1 013 000+ 條目
<!--A bunch of other languages -->
Text : Wiktionary Free dictionary
Link : //www.wikibooks.org/
Text : Wikibooks Free textbooks
Link : //www.wikinews.org/
Text : Wikinews Free news source
Link : //www.wikidata.org/
Text : Wikidata Free knowledge base
Link : //www.wikiversity.org/
Text : Wikiversity Free course materials
Link : //www.wikiquote.org/
Text : Wikiquote Free quote compendium
Link : //www.mediawiki.org/
Text : MediaWiki Free & open wiki application
Link : //www.wikisource.org/
Text : Wikisource Free library
Link : //species.wikimedia.org/
Text : Wikispecies Free species directory
Link : //meta.wikimedia.org/
Text : Meta-Wiki Community coordination & documentation
Link : https://creativecommons.org/licenses/by-sa/3.0/
Text : Creative Commons Attribution-ShareAlike License
Link : //meta.wikimedia.org/wiki/Terms_of_Use
Text : Terms of Use
Link : //meta.wikimedia.org/wiki/Privacy_policy
Text : Privacy Policy
与此相似,你还可以得到图像的数量、元信息、表单参数等一切你能想到的东西,因此经常被用于获取统计数据。
使用JSoup解析文件
public void parseFile() throws URISyntaxException, IOException {
URL path = ClassLoader.getSystemResource("page.html");
File inputFile = new File(path.toURI());
Document document = Jsoup.parse(inputFile, "UTF-8");
System.out.println(document.title());
//parse document in any way
}
如果要解析文件,就不需要给网站发送请求,因此不用担心运行程序会给服务器增添太多负担。尽管这种方法有许多限制,并且数据是静态的,因而不适合许多任务,但它提供了分析数据的更合法、更无害的方式。
得到的文档可以用前面说过的任何方式解析。
设置属性值
除了读取字符串、URL和文件并获取数据之外,我们还能修改数据和输入表单。
例如,在访问亚马逊时,点击左上角的网站标志,能返回到网站的首页。
如果想改变这个行为,可以这样做:
public void setAttributes() throws IOException {
Document doc = Jsoup.connect("https://www.amazon.com").get();
Element element = doc.getElementById("nav-logo");
System.out.println("Element: " + element.outerHtml());
element.children().attr("href", "notamazon.org");
System.out.println("Element with set attribute: " + element.outerHtml());
}
获取网站标志的id后,我们可以查看其HTML。还可以访问它的子元素,并改变其属性。
Element: <div id="nav-logo">
<a href="/ref=nav_logo/135-9898877-2038645" class="nav-logo-link" tabindex="6"> <span class="nav-logo-base nav-sprite">Amazon</span> <span class="nav-logo-ext nav-sprite"></span> <span class="nav-logo-locale nav-sprite"></span> </a>
<a href="/gp/prime/ref=nav_logo_prime_join/135-9898877-2038645" aria-label="" tabindex="7" class="nav-logo-tagline nav-sprite nav-prime-try"> Try Prime </a>
</div>
Element with set attribute: <div id="nav-logo">
<a href="notamazon.org" class="nav-logo-link" tabindex="6"> <span class="nav-logo-base nav-sprite">Amazon</span> <span class="nav-logo-ext nav-sprite"></span> <span class="nav-logo-locale nav-sprite"></span> </a>
<a href="notamazon.org" aria-label="" tabindex="7" class="nav-logo-tagline nav-sprite nav-prime-try"> Try Prime </a>
</div>
默认情况下,两个<a>子元素都指向了各自的链接。将属性改变为别的值之后,可以看到子元素的href属性被更新了。
添加或删除类
除了设置属性值之外,我们还可以修改前面的例子,给元素添加或删除类:
public void changePage() throws IOException {
Document doc = Jsoup.connect("https://www.amazon.com").get();
Element element = doc.getElementById("nav-logo");
System.out.println("Original Element: " + element.outerHtml());
<!--Setting attributes -->
element.children().attr("href", "notamazon.org");
System.out.println("Element with set attribute: " + element.outerHtml());
<!--Adding classes -->
element.addClass("someClass");
System.out.println("Element with added class: " + element.outerHtml());
<!--Removing classes -->
element.removeClass("someClass");
System.out.println("Element with removed class: " + element.outerHtml());
}
运行代码会给我们以下信息:
Original Element: <div id="nav-logo">
<a href="/ref=nav_logo/135-1285661-0204513" class="nav-logo-link" tabindex="6"> <span class="nav-logo-base nav-sprite">Amazon</span> <span class="nav-logo-ext nav-sprite"></span> <span class="nav-logo-locale nav-sprite"></span> </a>
<a href="/gp/prime/ref=nav_logo_prime_join/135-1285661-0204513" aria-label="" tabindex="7" class="nav-logo-tagline nav-sprite nav-prime-try"> Try Prime </a>
</div>
Element with set attribute: <div id="nav-logo">
<a href="notamazon.org" class="nav-logo-link" tabindex="6"> <span class="nav-logo-base nav-sprite">Amazon</span> <span class="nav-logo-ext nav-sprite"></span> <span class="nav-logo-locale nav-sprite"></span> </a>
<a href="notamazon.org" aria-label="" tabindex="7" class="nav-logo-tagline nav-sprite nav-prime-try"> Try Prime </a>
</div>
Element with added class: <div id="nav-logo" class="someClass">
<a href="notamazon.org" class="nav-logo-link" tabindex="6"> <span class="nav-logo-base nav-sprite">Amazon</span> <span class="nav-logo-ext nav-sprite"></span> <span class="nav-logo-locale nav-sprite"></span> </a>
<a href="notamazon.org" aria-label="" tabindex="7" class="nav-logo-tagline nav-sprite nav-prime-try"> Try Prime </a>
</div>
Element with removed class: <div id="nav-logo">
<a href="notamazon.org" class="nav-logo-link" tabindex="6"> <span class="nav-logo-base nav-sprite">Amazon</span> <span class="nav-logo-ext nav-sprite"></span> <span class="nav-logo-locale nav-sprite"></span> </a>
<a href="notamazon.org" aria-label="" tabindex="7" class="nav-logo-tagline nav-sprite nav-prime-try"> Try Prime </a>
</div>
可以把新的代码以.html形式保存到本机,或者通过HTTP请求发送大欧网站上,不过要注意后者可能是非法的。

结论
在许多情况下Web抓取都很有用,但使用时务必要遵守法律。本文介绍了流行的Web抓取框架JSoup,以及使用它解析信息的几种方式。
原文:
https://able.bio/DavidLandup/introduction-to-web-scraping-with-java-jsoup--641yfyl作者:David Landup,Java开发人员,科技撰稿人
译者:弯月,责编:郭芮
“征稿啦!”
CSDN 公众号秉持着「与千万技术人共成长」理念,不仅以「极客头条」、「畅言」栏目在第一时间以技术人的独特视角描述技术人关心的行业焦点事件,更有「技术头条」专栏,深度解读行业内的热门技术与场景应用,让所有的开发者紧跟技术潮流,保持警醒的技术嗅觉,对行业趋势、技术有更为全面的认知。
如果你有优质的文章,或是行业热点事件、技术趋势的真知灼见,或是深度的应用实践、场景方案等的新见解,欢迎联系 CSDN 投稿,联系方式:微信(guorui_1118,请备注投稿+姓名+公司职位),邮箱(guorui@csdn.net)。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号