实例解析:从Ruby到Rust的系统架构迁移
发表时间: 2019-02-18 16:29
前几年随着RoR(Ruby on Rails)框架的流行,很多初创企业选择Ruby和Rails作为基础开发框架,构建和快速迭代了其业务系统。但是随着业务规模的不断壮大,性能问题成了一个突出的问题,所以从RoR架构升级到一个高性能架构迫在眉睫。而且这方面也有很多有益的案例,比如Gitlab是富RoR的架构,但是现在也暴露很多Ruby性能问题,所以Gitlab项目逐渐将一些性能敏感组件用Golang代替,所以就出现了纯Golang写的Gitlab runner和Gitaly组件。
本文虫虫以Andrii在他们Dispatcher服务架构迁移为实例,介绍从Ruby到Rust的迁移,希望能抛砖引玉,供大家参考,用于解决实际问题。
Adrii的物流算法团队运行着一个名为Dispatcher的服务,目的是向骑行者以最佳方式提供订单服务。对于每个骑手,该服务建立了一个时间轴,它可以预测骑手在某个时间点的位置。通过该位置,给骑手提供最佳推荐建议。在构建时间线服务时候涉及很多的计算:使用不同的机器学习模型来预测事件耗时,筛选约束,计算分配成本。每一个计算都很快,但是由于涉及了很多的用户,需要检查所有可用的服务和用户以确定哪个分配是最好的。Dispatcher的第一个版本主要是用Ruby编写的。随着用户规模和服务的不断增加,调度过花费的时间越来越长,甚至,有时候会超过业务可以忍受的时间限制。系统性能成了最大的瓶颈!优化代码迫在眉睫,在尝试了常规性的优化:缓存、算法优化等后,明显地Ruby语言及其运行时成了瓶颈。
针对Ruby架构的Dispatcher性能成为瓶颈后,如何解决?
选择具有更好性能的编程语言并重写Dispatcher。
确定最大的瓶颈,重写代码的这些部分,并以某种方式将它们集成到当前代码中。
每一个架构师和有经验的开发人员都知道从头开始重写是有风险的,时间消耗,可能会引入的错误,痛苦的服务切换等等。因此,利用第二种方法找到系统瓶颈替换并集成,在初步的尝试之后(利用Rust实现了匈牙利路由匹配算法的原生gem扩展),得到很好效果。
利用Ruby集成其他语言写的扩展有几种方法可选:
构建外部服务并提供与之通信的API;
构建原生扩展。
但是构建外部服务的选项很快就被否决了,因为如果通过AI调用的话,需要在每个调度周期中调用外部服务数十万次,其通信的开销将抵消所有可能带来的性能优化,或者需要重新实现调度程序的一个重要部分,这与重写也差不多。
所以利用,构建原生扩展成了唯一的选择。所以,最后决定使用Rust,带来的好处是:
高性能(与C相当);
内存安全;
它可用于构建动态库,并加载到Ruby中(使用extern"C"接口);
最后,主要是作为一个门新的语言,Rust易于被团队成员接受。
架构变换的策略是使用Rust扩展逐步替换当前的ruby实现,逐个替换算法的部分内容。在Rust中实现单独的方法和类,并在Ruby调用它们,这不需要很大的跨语言交互开销。
有几种不同的方法在Ruby调用Rust:
使用extern"C"接口在Rust中编写动态库,并使用FFI调用它。
编写动态库,但使用Ruby API注册方法,可以直接从Ruby调用它们,就像调用任何其他Ruby代码一样。
使用FFI的第一种方法要求在Rust和Ruby中提出一些自定义C类接口,然后在两种语言中为它们创建包装器。使用Ruby API的第二种方法听起来更有前途,因为有很多现有的类库可以直接使用:ruru和rutie,Helix等
首先尝试了Helix的方法。Helix的宏看起来像在Rust中编写Ruby,这对对熟悉两种语言的开发者来说感觉非常酷。
强制协议没有很好地记录,并且不清楚如何将非原始Ruby对象传递给Helix方法
不确定安全性。看起来Helix没有使用rb_protect调用Ruby方法,这可能会导致一些未定义的行为。
在尝试之后,团队决定使用ruru/rutie,但保持Ruby层尽量廋和隔离,以便可以在将来切换。最后选择使用Rutie,它是Ruru的最新分支,开发也更加活跃。
以下是如何使用ruru/rutie中的一种方法创建类的一个小示例:
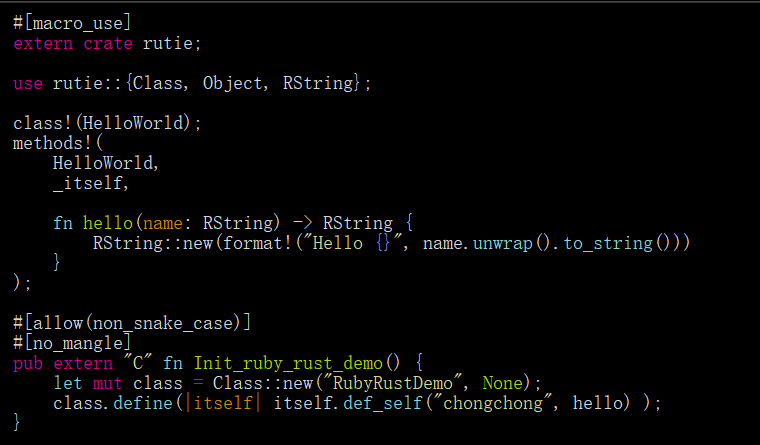
如果需要将一些基本类型(如String,Fixnum,Boolean等)传递给ruyb方法,效果非常好,但如果需要传递大量数据则不是很好。在这种情况下,需要传递整个对象,比如Order,然后需要调用该对象上需要的每个字段以将其移动到Rust中:
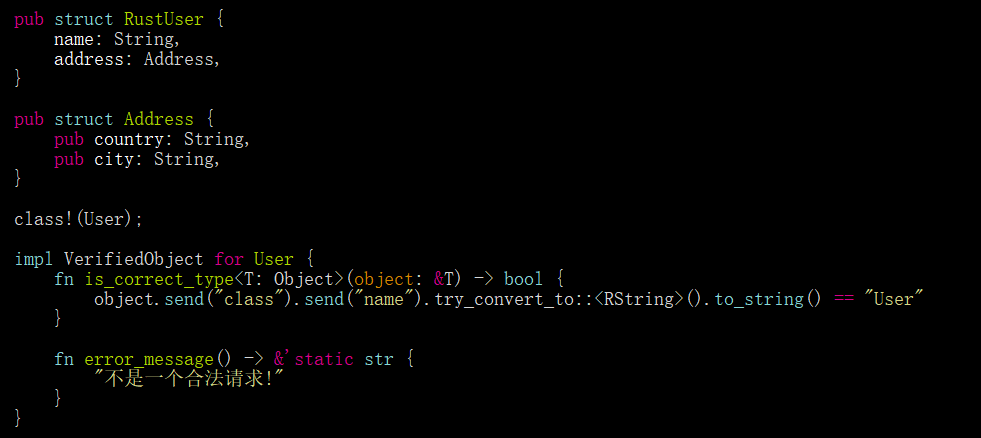
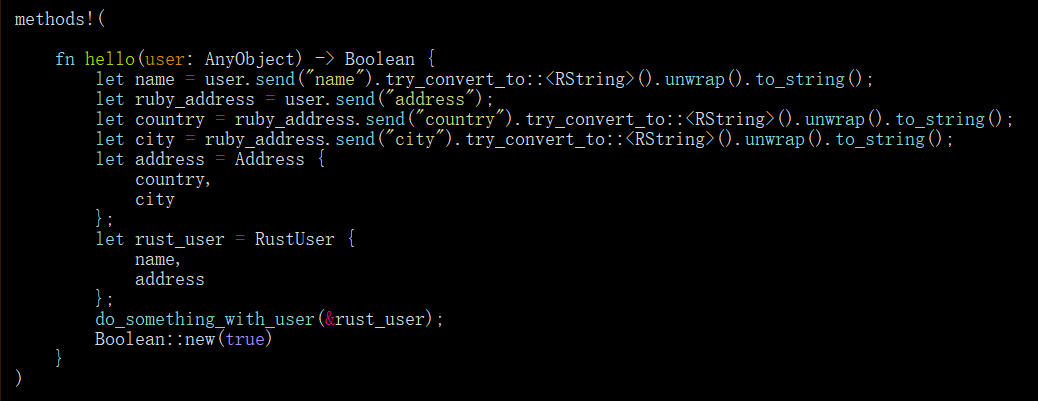
以上代码,有很例行和重复的代码,也缺少完善的错误处理。代码这看起来很像手动解析JSON或类似的东西。你可以将Ruby中的对象序列化为JSON,然后在Rust中解析它,它的工作原理很好,但你仍需要在Ruby中实现JSON序列化程序。
下面使用了相同的方法,但是使用了serde反序列化器和序列化器:
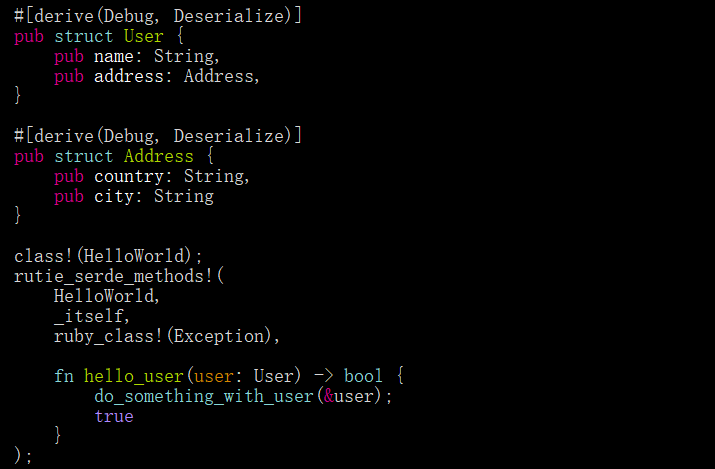
可以看到hello_user中的代码非常简单,我们不再需要手动解析用户了。因为serde也可以处理嵌套对象(正如你可以看到的那样)。我们还添加了一个内置的错误处理:如果serde无法"解析"对象,这个宏将引发我们提供的类的异常(在本例中为Exception),它还将方法体包装在panic::catch_unwind,并在Ruby中将异常重新引发为异常。
使用rutie-serde,可以快速,轻松地实现Ruby和Rust之间的弱接口。
在初步尝试之后,我们列出了一个逐步用Rust替换Ruby Dispatcher的所有功能的计划。我们首先使用Rust类做替换,这些类没有依赖于Dispatcher的其他部分并添加功能标志,类似于:

还有一个主开关(在这种情况下是rust_enabled?),它允许我们通过只切换一个功能标志来关闭所有Rust代码。
由于Ruby和Rust类的实现API大致相同,我们可以使用相同的测试用例来测试。
同样非常重要的是,在任何时候,基于需要,随时都可以关闭Rust集成,Dispatcher仍然可以工作(功能开关)。
当将更多的代码迁移到Rust中时,可以在监控系统看得到的性能改进:
在Dispatcher中,调度周期有3个主要阶段:
数据加载中;
运行计算,计算分配;
保存/发送作业。
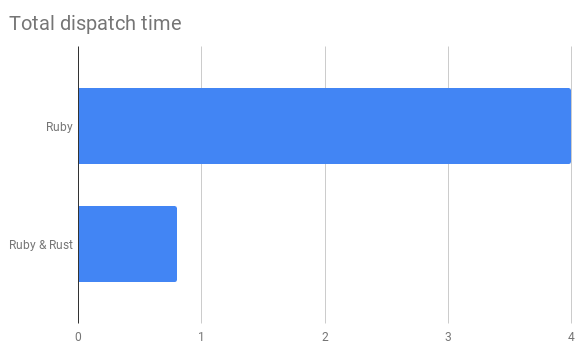
加载数据和保存数据阶段几乎线性地根据数据集大小进行变化,而计算阶段(迁移到Rust)在其中具有更高阶的多项式分量。不太担心加载/保存数据阶段,也没有优先加快这些阶段的速度。虽然加载数据和发送数据仍然是用Ruby编写的,但总调度时间显着减少了。例如,在我们较大的一个区域中,它从4秒下降到0.8秒(如下图)。
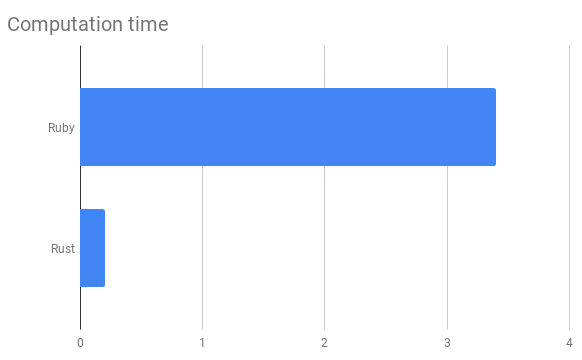
在这0.8秒中,在计算阶段,在Rust中花费了大约0.2秒。这意味着0.6秒是加载数据和向骑手发送任务的Ruby/DB开销。整体调度周期看起来仅快了5倍,但实际上,此示例时间内的计算时间从3.2秒减少到0.2秒,大概有了17倍的加速。
通过实践,Rust代码几乎是Ruby 1:1 拷贝,并且没有添加任何额外的优化(如缓存,在某些情况下避免内存复制),因此仍有改善的空间。
该项目架构迁移很成功,从Ruby转向Rust取得了预期的效果,大大加速dipatch流程,并为提供了更多的优化空间,还可以尝试实现更高级的算法。
渐进式迁移和细致特征标记减轻了项目的大部分风险。使得可以更小的增量部件交付。
Rust已经表现出了很好的性能,并且使得在构建Ruby原生扩展时可以很容易地将它用作C的替代品。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号