革新训练方式:在小型计算机上实现人工智能的新突破
发表时间: 2021-02-03 10:51
深度学习是一种低效的能源消耗。它需要海量的数据和丰富的计算资源,这导致了其耗电量呈爆炸性增长。在过去的几年里,该领域的整体研究趋势使这一问题愈加严重。庞大的比例模型需要对数十亿数据点进行许多天的训练,但这些模型越来越流行,并且短时间很可能不会消失。
一些研究人员急于探寻新的方向,比如可以用更少数据进行训练的算法,或者可以更快运行这些算法的硬件。IBM 的研究人员提出了一个不同的方案。他们将减少表示数据所需的位(即 1 和 0)的数量,从目前的行业标准 16 位减少到 4 位。
研究人员在最大的年度人工智能研究会议 NeurIPS 上展示了这项工作,它可能会让训练深度学习的速度加快 7 倍,并将能源成本降低 7 倍以上。它还可能让在智能手机和其他小型设备上训练强大人工智能模型这一想法成为可能,这将有助于把个人信息保存在本地设备上,从而更好地保护隐私。而且,这将使资源丰富的大型科技公司以外的研究人员更容易实现深度学习这一过程。
你以前可能听说过电脑用二进制数 1 和 0 存储数据。这些基本的信息单位被称为比特,或位。当位 “打开” 时,它对应 1;当它 “关闭” 时,就变成 0。换句话说,每一个位只能存储两种信息。
但一旦把它们串在一起,能够编码的信息量就会呈指数增长。2 位可以表示 4 条信息,因为有 2 的二次方,也就是 4 种组合:00、01、10 和 11。4 位可以表示 2 的四次方,也就是 16 条信息。8 位可以表示 2 的 8 次方,也就是 256 条信息。
位的正确组合可以表示数字、字母和颜色等数据类型,或加法、减法和比较等操作类型。如今,大多数笔记本电脑都是 32 位或 64 位,但这并不意味着计算机总共只能编码 232 或 264 条信息。(那这台电脑就太垃圾了。)这表示它可以使用这么多复杂度的位来对每一段数据或单个操作进行编码。
4 位训练是什么意思?首先,我们有一台 4 位计算机,因此复杂度是 4 位。我们可以这样想:我们在训练过程中使用的每一个数字都必须是 - 8 到 7 之间的 16 个整数中的一个,因为计算机只能表示这些数字。我们输入神经网络的数据点,用来表示神经网络的数字,以及我们在训练期间需要存储的中间数字都是如此。
接下来要怎么做呢?我们先要考虑训练数据。想象一下,摆在我们面前的是一大堆黑白照片。第一步:我们需要把这些图像转换成数字,这样计算机才能理解它们。为此,我们根据灰度值来表示每个像素 ——0 表示黑色,1 表示白色,小数点表示灰色的深浅度。现在,我们的图像是一个范围从 0 到 1 的数字列表。但在 4 位域中,我们需要把范围扩展到从 - 8 到 7。这里的技巧是把数字列表线性缩放,所以 0 变成 - 8,1 变成 7,小数点映射到中间的整数。如下图所示:
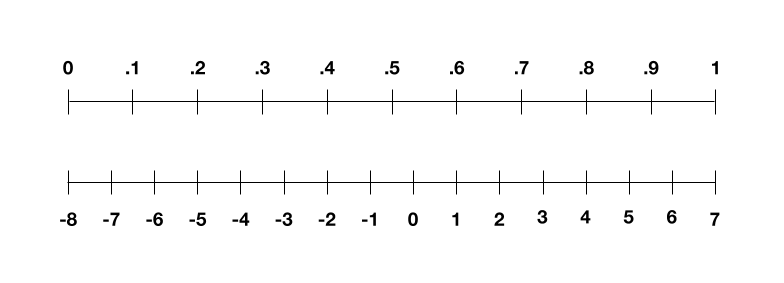
图|您可以将数字列表从 0 到 1 扩展到 - 8 到 7,然后将任意小数四舍五入到整数。
这个过程并不完美。比如说,如果你从 0.3 开始,你会得到缩放后的数字 - 3.5。但是我们的 4 位计算机只能表示整数,所以你必须四舍五入到 - 4。这样最终会失去图像中的一些灰色阴影,也就是精度。我们可以在下面的图片中看到它的样子。
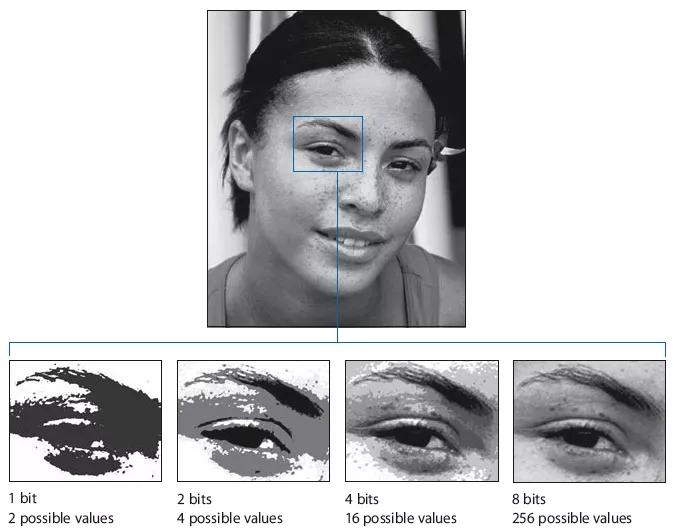
图|位数越低,照片的细节就越少。这就是精度损失。
这个技巧对于训练数据来说并不算难用。但当我们把它再次应用到神经网络本身时,事情就变得有点复杂了。
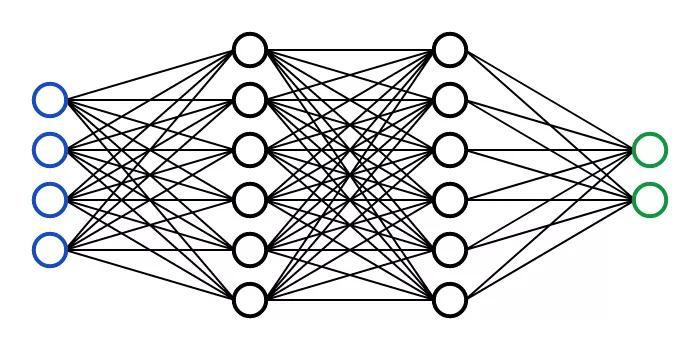
图|一个神经网络
神经网络经常被绘制成有节点和连接起来的东西,就像上图。但是对于计算机来说,这些都会变成一系列数字。每个节点都有一个激活值,通常取值范围为 0 到 1,每个连接都有一个权值,通常取值范围为 - 1 到 1。
我们同样可以用处理像素的方法来缩放它们,但激活值和权值也会随着每一轮训练而改变。例如,有时一轮训练的激活值范围是从 0.2 到 0.9,但在另一轮训练中是从 0.1 到 0.7。因此,IBM 团队在 2018 年想出了一个新方法:每轮训练重新调整这些范围,使其在 - 8 到 7 之间 (如下图所示),这有效地避免了损失太多精度。

图|IBM 的研究人员为每一轮训练重新调整神经网络的激活值和权值,以避免损失太多精度。
但我们还需要进行最后一个部分:如何用 4 位表示训练过程中突然出现的中间值。与我们处理图像,权值和激活值的数字不同,这些值可以跨越几个数量级。它们可能很小,比如 0.001,也可能很大,比如 1000。尝试将其线性缩放到 - 8 到 7 之间会失去缩放范围最小端的所有粒度。
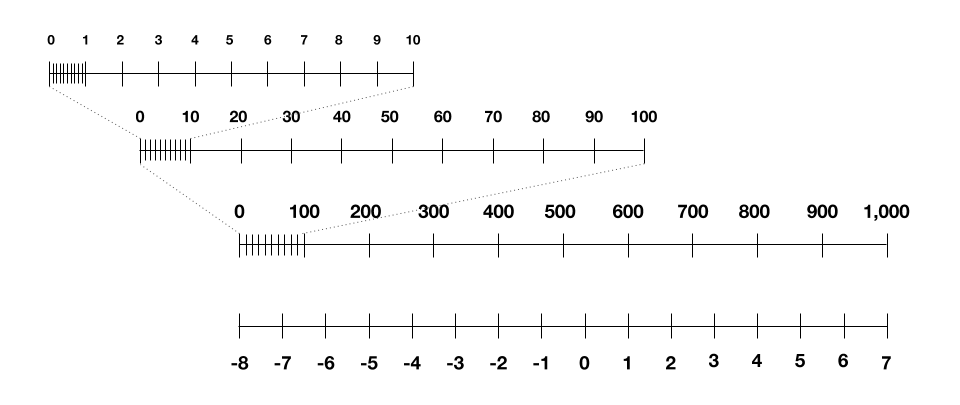
图|跨越几个数量级的线性缩放数字在极小的一端失去了所有的粒度。正如这张图所示,任何小于 100 的数都会被缩放成 - 8 或 - 7。精确度的降低会影响人工智能模型的最终性能。
经过两年的研究,研究人员终于解决了这个挑战:他们借鉴了别人的想法,将这些中间数字按对数比例缩放。下面这个对数缩放也许能让你明白我在说什么,以 10 为 “基数”,只使用了 4 位复杂度。(研究人员转而使用 4 为基数,因为反复试验表明这种方法效果最好。)你可以看到它是如何在位约束内编码小数字和大数字的。
图|以 10 为基数的对数缩放。
这篇最新的论文展示了如何把所有这些因素结合在一起。IBM 的研究人员进行了几个实验,他们在计算机视觉、语音和自然语言处理的各种深度学习模型上模拟 4 位训练。结果表明,与 16 位深度学习相比,模型的整体性能损失了有限的准确性,但整个过程也快了 7 倍多,并且会节能 7 倍多。
在 4 位深度学习成为实际应用之前还需要很多研究。本文仅模拟这类训练的结果。想应用在现实世界还需要新的 4 位硬件。2019 年,IBM 研究院成立了人工智能硬件中心,以加快开发和生产此类设备的进程。负责这项工作的 IBM 高级经理凯拉斯・戈帕拉克里希南表示,他预计三到四年内, 将出现能够为深度学习训练所用的 4 位硬件。
斯坦福大学教授鲍里斯・穆尔曼没有参与这项研究,但他称这些结果令人兴奋。他说:“这项进步为在资源有限的环境中进行训练打开了大门。” 它不一定会让新应用出现,但它会让现有应用的速度更快,更省电,“它有很大的优势”。例如,苹果和谷歌更加探寻如何将人工智能模型(如语音转文本和自动更正系统)的训练过程从云端转移到用户手机上。通过将用户的数据保存在个人手机上,能保护用户隐私,并提高设备的人工智能能力。
但穆尔曼也指出,还需要更多研究来验证这种方法的可靠性。2016 年,他的团队发表了一篇论文,展示了 5 位训练法。但这种方法多年来并没有奏效。“由于神经网络变得更加敏感,我们之前所用的简单方法已经无法使用了,” 他说,“所以还不清楚这样的技术是否能经受住时间的考验。”
尽管如此,他说,这篇论文 “将促使其他人更加认真地研究这一问题,并激发新的想法。这是一个非常受欢迎的进步。”
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号