深度解析:Node.js在携程的实际应用与优化策略
发表时间: 2019-12-05 21:31
作者简介
潘斐斐,Trip.com高级研发经理。2008年加入携程,目前工作内容为Node.js框架平台整体构建、产品性能优化和创新型项目研发。本文来自在2019携程技术峰会上的分享。
本篇主要介绍在携程,Node.js技术栈是如何实现从0到1进行技术落地的,以及在不断磨合的过程中,总结出来的最佳实践。
在携程Node.js应用根据用户群,主要分两个方向:
DA(数据聚合服务)和SSR(服务端渲染)是服务于外部用户的,目标是提升用户体验。当然,DA和SSR同时也提升了开发效率,例如前端开发人员可以更加灵活的整合数据,例如同构给开发人员省去了大量重复的开发工作量;
公司桌面工具(例如内部IM等)是服务于内部员工的,一般是用Electron,开发维护成本低,产品迭代快。
一、Node.js工程化
基于上述三个场景,目前携程有一套Node.js的工程化方案。工程化的方案并不是一成不变的, 在任何阶段遇到了实际问题, 都会更新甚至推翻一些步骤,为的就是更好的服务于整个应用开发的生命周期。
工程化涵盖五大部分:开发、构建、测试、发布和运维。
1.1 开发
1)脚手架
有三个类型的脚手架:Web Application、DA Service和Desktop Tools。这三种类型的脚手架会服务于上述提到的三种场景。
这三种脚手架有共同点:标准化的Docker日志,预置统一的中间件。但同时他们也是有差异的,例如Desktop Tools和Web Application的应用模型不一样,Desktop有UI层,那么UI层和应用层上的应用日志和用户行为如何关联,方便后续的排障;DA Service需要将应用的健康状况周期性上报给治理中心、熔断机制等等,这些框架层面的差异,脚手架会集成进去,做业务开发同学可以不用关心这些基础设施的接入。
2)核心中间件
核心中间件主要是做基础设施的建设。目前有20多个中间件,主要的中间件如下:

图1 核心中间件介绍
1.2 构建
1)Docker镜像
Node.js的版本更新频率很快,每6个月会发布一个大版本的升级,期间会陆续出很多小版本。如果为每个版本都做一个镜像,会带来极高的开发和运维成本。基于更新频率,我们目前选取2个固定版本,在Node.js版本更替的时候,可以保证一个稳定的镜像。
2)安装依赖包
为了提升开发效率,在构建时安装依赖包需要保证速度快。如果中间件中用到一部分C++模块,那么在安装时会做实时编译,这样会导致耗时长,甚至会因为环境问题编译失败。所以我们会将用到C++模块的中间件做一下预编译,为windows、linux和mac这三个平台分别编译出2个固定版本的预编译包。
3)依赖包扫描
扫描的目的主要解决几个问题:
1.3 测试
目前测试环节包括单元测试、集成测试、压力测试和自动化测试。自动化测试主要针对Service和UI两方面测试。UI自动化测试使用的是Puppteer。每次代码更新,会走一遍自动化测试流程,保证代码质量。
1.4 发布
1)携程云和公有云
每个云的部署环境、网络、位置等差异,会带来应用访问差异,例如访问异常,网络延迟等。这些差异需要在基础设施层面抹平,避免放在应用逻辑层面处理。
2)应用一体化发布
一体化发布也可以理解为一键发布。一条发布指令包含了应用核心框架、静态资源、配置的同时发布,而不需要开发人员思考什么步骤需要发什么资源。这样不仅可以提升效率,还能有效的控制发布回滚。
3)私有npm包发布
私有包的发布和GIT做高度集成。原因是:第一可以通过git做快速的发布;第二有历史可查,方便的查看到每个版本发布的时间、人员;第三有权限控制,避免发生生产级别故障。
1.5 运维
运维是整个环节中最重要也是最容易被忽略的环节。一个应用上线只是开始,真正要关注的一定是运维指标。
1)日志监控
三种维度的监控:tracing、logging和metric。

图2 三种维度的监控
图片来源于网络:
http://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html
Tracing提供的是整个请求过程中的数据,例如请求信息(头部、地址)、响应信息(状态码,响应体)、请求耗时、调用链等信息。
Logging提供的是在请求处理过程中,每一个具体的事件埋点,这些埋点相对是分散的。可以是记录普通的日志,也可以是记录抛出的错误。
Metric提供的是聚合数据。最大的特征是可聚合的,它展现的是一个时间跨度中的某个维度的指标。一般用来记录量化的指标,例如访问量、性能等数据。
2)应用排障
一般我们排查问题的时候,会先通过Metric的聚合指标发掘出异常,然后追踪到某一批有异常的Tracing,可以查看到调用链、耗时等具体情况,也可以跟踪到某一个请求,查看里面的事件埋点。
也有其他方式的排障,例如下图中展示,可以在线直接通过一个特殊的地址访问到的一张火焰图,可以非常快速地去排障。当有用户说这个页面出现问题,打开这个页面排障,可以定位到底那个对应的地方出现问题。
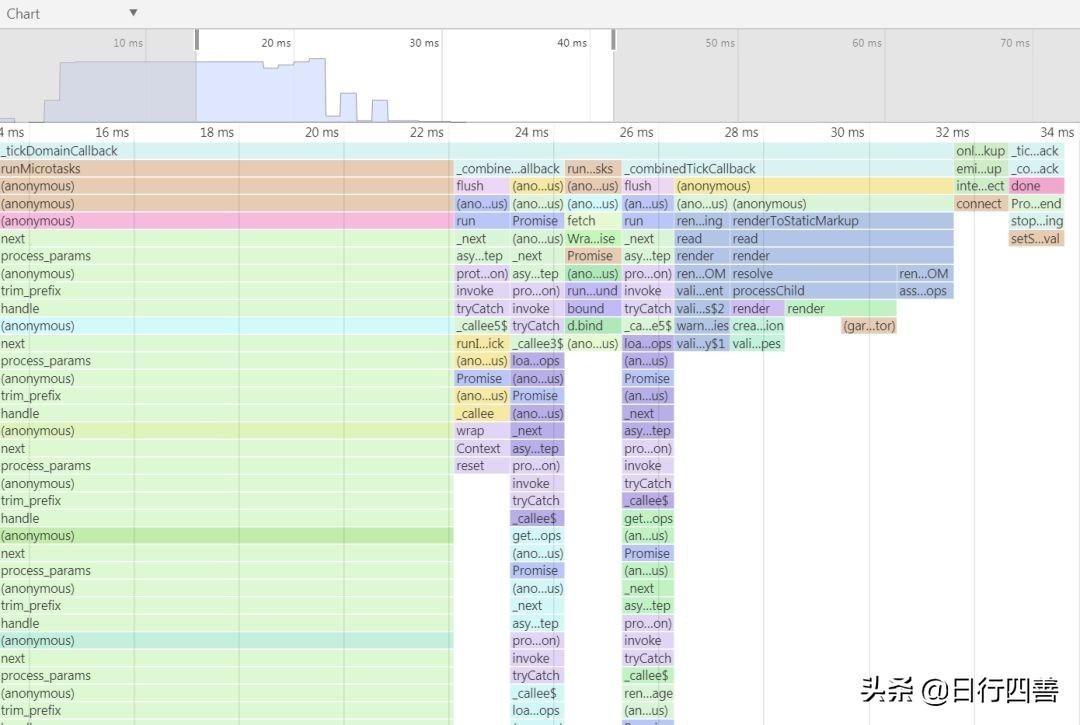
图3 火焰图
二、Node.js最佳实践
2.1 部署模型
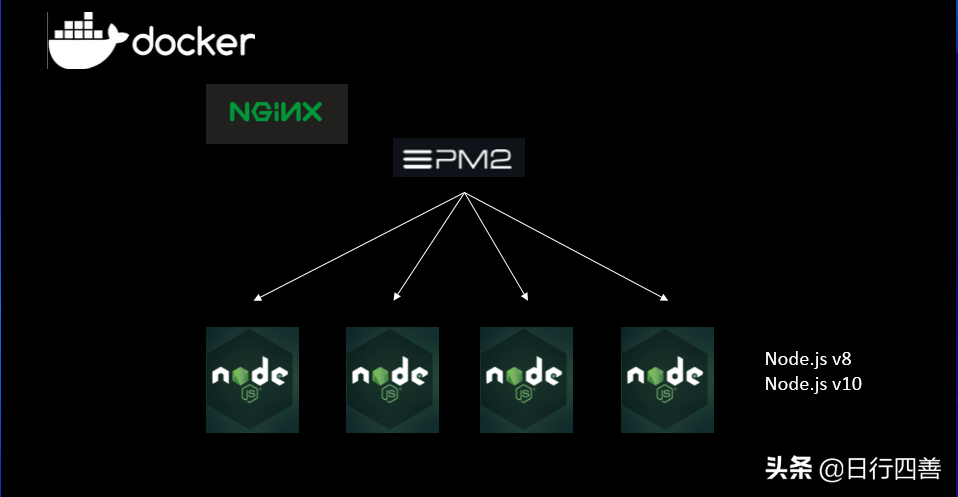
图4 部署模型
Node.js应用部署在Docker上,采用Nginx+PM2的模式。
2.2 问题一:多进程通信
多进程通信主要用于数据交换,最常见的有2种场景:
1)提供SequenceId:在单台机器需要提供唯一的并且按时间序列排列的ID。
2)提供远端配置信息:当获取远端配置信息时,需要考虑多进程的共享分发。
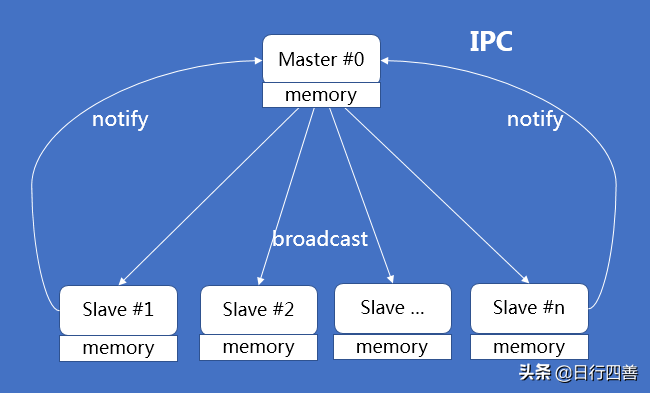
图5 多进程通信V1.0
在第一版本设计中,我们采用的是IPC机制进行多进程的通信。Master作为一个中转站,当Slave有消息分发时,通知给Master,再由Master分发给各Slave,从而达到进程之间通信的效果。
但是上线之后发现,这样的机制会遇到几个问题:数据量必须控制好体积;数据的同步会有延迟;Master必须时刻在线,一旦Master进程挂掉,就需要等待重启再重连。
基于这些问题,我们重新设计了第二个版本:
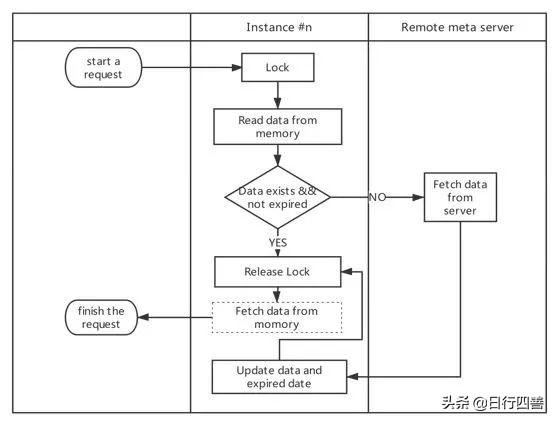
图6 多进程通信V2.0
在第二个版本的设计中,我们使用了共享内存(shared memory)。举一个场景为例,当需要获取某个配置的时候,先将这块内存锁定,尝试从内存中获取数据。如果判断数据存在且在有效期内,那么解锁并从内存中读取数据返回,否则从服务端获取数据,当服务端有数据返回时,将数据和有效期更新到内存中,解锁并从内存中读取数据返回。通过共享内存的机制,可以非常轻量级且高效的实现多进程之间的数据共享。
2.3 问题二:监控什么内容
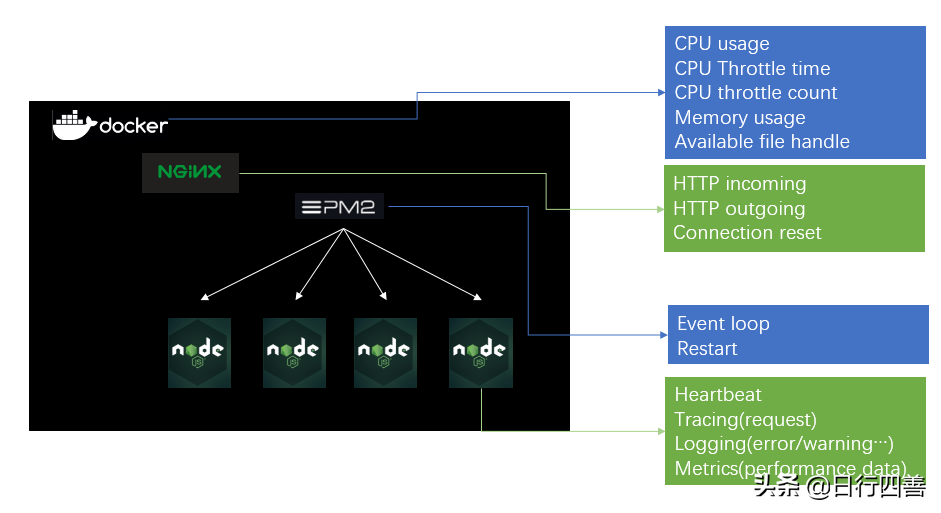
图7 监控指标
Nginx会监控整个Docker上所有应用的情况:
Nginx中监控的是整个Docker的情况,但是我们更需要的是监控应用的指标。应用一般采用PM2 cluster –i max模式启动,最大化利用CPU。
每个slave一分钟发送一次Heartbeat(心跳信息)给到CAT数据中心。一般来说,如果Heartbeat告警的话,需要立刻查看一下错误日志,是不是有异常错误导致进程已经退出了。
Heartbeat主要包括CPU、Memory、网络信息等。这些信息和上述提到的Nginx信息不是一个维度的。这个更细节的关注了应用的情况,而不是整个Docker的情况。如果需要分析应用细节的问题,是需要查看这里的Heartbeat信息。
一般来说,中间件会处理应用常规的性能日志记录。包括:
1)每一个响应的请求耗时(服务端逻辑处理耗时,不包括网络耗时)。
2)每一个Transaction的耗时。一个Transaction可以简单理解为一个有功能意义的代码片段。
3)跨应用调用的请求耗时。
错误告警信息是应用中需要重点关注的,包括:
1)应用逻辑出错,例如处理JSON数据出错等。
2)HTTP请求出错,会记录状态码、请求地址、返回内容。
3)应用中使用了不同版本的同一个包,会报一条告警信息通知开发工程师。
详细数据日志一般有开发工程师针对应用的逻辑埋点,而非中间件统一处理。这些日志会包括返回数据的记录,具体运行在哪一段transaction中。这些日志一般是故障发生时,用来复盘时的辅助手段。
2.4 问题三:全链路监控
全链路监控指的是端到端的监控,监控的是一系列的调用链情况。
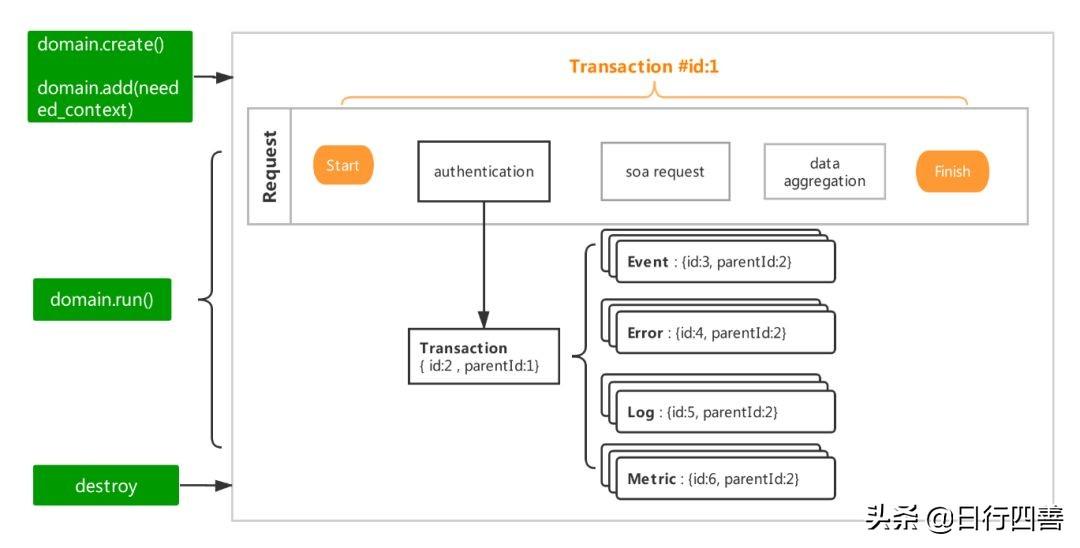
图8 Tracing模型
在介绍全链路模型之前,首先介绍Tracing模型(图8)。Tracing模型是一个树状结构的模型。以一个场景为例,当用户发起一个请求,这个请求的处理中有三段逻辑(authentication、soa request和data aggregation)。
在整个请求体外层会有一个Transaction#1,记录请求响应等信息。每一个逻辑段会对应一个Transaction#2,Transaction#2的父节点是Transaction#1。Transaction#2中可以有多个Logging信息,根据类型可以分为Event/Error/Log,也可以包含Metric信息。这些Logging和Metric都有父节点,是Transacation#2。按照这样的结构可以将一整个request的过程的监控信息记录下来。
要做全链路监控,就是需要将每个request和调用链做关联。
在过程中遇到的最核心的问题是,如何将上下文进行关联。第一个版本使用的是domain的模块,使用domain的add api将上下文信息记录下来,使用run api运行逻辑代码块。第二个正在测试中的版本是使用async_hook的模块,引入了生命周期的概念,通过executionAsyncId和ttriggerAsyncId可以追踪每个函数体。
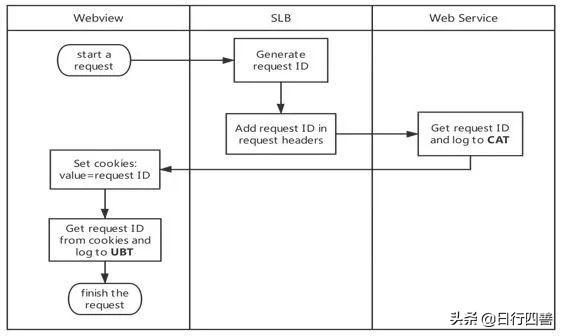
图9 页面请求模型
通过上图的页面请求模型可以将每个请求做关联,从而达到全链路监控的效果。
三、总结
本文来源微信公众号携程技术中心
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号