Python语言下的数据结构与算法入门篇
发表时间: 2020-03-27 15:02
一个不太恰当的理解, 兵法如果将写好运行的程序比作战场, 码农就是指挥这场战斗的指挥官, 手中的代码就是被指挥的士兵和武器. 兵法就是取得这场战斗的胜利的关键所在. 运筹帷幄之中, 决胜于千里之外.
我们的数据结构和算法, 就是程序员取胜的关键. 没有看过数据结构与算法, 有时面对问题没有任何的思路, 不知如何下手;虽然大部分时间可能解决了问题, 可是对程序运行的效率和开销没有意识, 性能底下; 面对强敌时, 有着兵法, 领军打战; 同样问题是, 算法就是我们的兵法.
如果 a+b+c=1000, 且a^2+b^2=c^2(a, b, c为自然数), 如何求出所有a, b, c可能的值
通过枚举a b c的值一个一个来试, 总有一个是我们想要的.
设计程序abc在1000范围内一个一个的来遍历直接三个循环算完了就得到答案了.
程序如下:
def first(): start_time = time.time() for a in range(1000): for b in range(1000): for c in range(1000): if a+b+c == 1000 and a**2 + b**2 == c**2: print ('a:b:c:%d, %d, %d' % (a, b, c)) end_time = time.time() print ('程序所需时间', start_time - end_time) print ('finished!!!')运行结果:
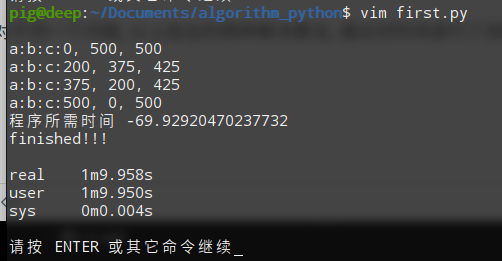
三次循环运行结果
66.929 我们的第一次持续了66秒
算法是计算机处理信息的本质, 计算机的程序本质上是一个算法来告诉计算机确切的步骤执行一个指定的任务.
算法是独立存在的一种解决问题的方法和思想对于算法而言, 实现的语言并不重要, 重要的是思想. 算法可以用多种语言来实现, 这里我选择使用python来描述.
def second(): start_time = time.time() for a in range(1000): for b in range(1000): c = 1000 - a - b if a**2 + b**2 == c**2: print ('a:b:c;%d, %d, %d' % (a, b, c)) end_time = time.time() print ('花费的时间:', start_time - end_time) print ("finished!!!!!")if __name__ = '__main__': second()运行结果:
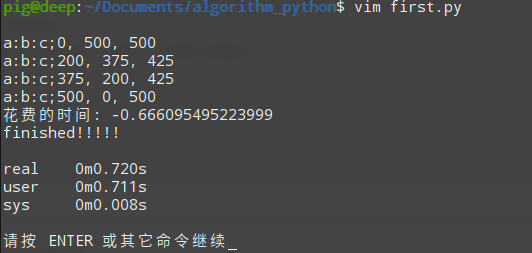
第二次尝试运行结果
这次的时间只有0.6秒
通过这两种方法的比较得到一个算法效率衡量的问题
对于同一个问题, 以上给出的两种解决算法, 通过对时间进行了测算,发现程序执行的时间相差悬殊(一个需要69秒,一个需要0.6秒), 由此推断出: 实现算法程序的执行时间可以反应出算法的效率, 即算法的优劣
单纯的依靠运行的时间来比较算法的优劣并不一定是客观准确的 ,程序的运行离不开计算机环境(如果两次运行程序的计算机环境不一样, 时间就不一定了, 一个在i9-9900K跑,一个在大屁股上跑, 谁比谁快不一定.完全没有可比性). 不同的计算机环境影响程序的执行时间. 所以引入时间复杂度和"大O记法"来客观反应算法的时间效率.
我们假定计算机执行算法每一个基本操作的时间是固定的一个时间单位,那么有多少个基本操作就代表会花费多少时间单位。算然对于不同的机器环境而言,确切的单位时间是不同的,但是对于算法进行多少个基本操作(即花费多少时间单位)在规模数量级上却是相同的,由此可以忽略机器环境的影响而客观的反应算法的时间效率。
时间效率, 可以使用"大O记法"来表示.
"大O记法": **对于单调的整数函数f,如果存在一个整数函数g和实常数c>0,使得对于充分大的n总有f(n)<=c*g(n),就说函数g是f的一个渐近函数(忽略常数),记为f(n)=O(g(n))。也就是说,在趋向无穷的极限意义下,函数f的增长速度受到函数g的约束,亦即函数f与函数g的特征相似.
时间复杂度: 假设存在函数g,使得算法A处理规模为n的问题示例所用时间为T(n)=O(g(n)),则称O(g(n))为算法A的渐近时间复杂度,简称时间复杂度,记为T(n)
简单举例:
for a in range(n): # a要执行n次操作 for b in range(n):# b也要执行n次操作 # 综合起来要执行n*n次操作 也就是这两次的时间复杂度为n**2 # 可以认为2n**2和100n**2是属于同一个数量级的.都是属于n**2级第一次尝试的算法核心部分复杂度:T(n)=O(n*n*n)=O(n**3)
第二次尝试:T(n) = O(n*n*(1+1)) = O(n*n) = O(n**2)
所以第二次算法时间复杂度好, 程序时间相对块点.
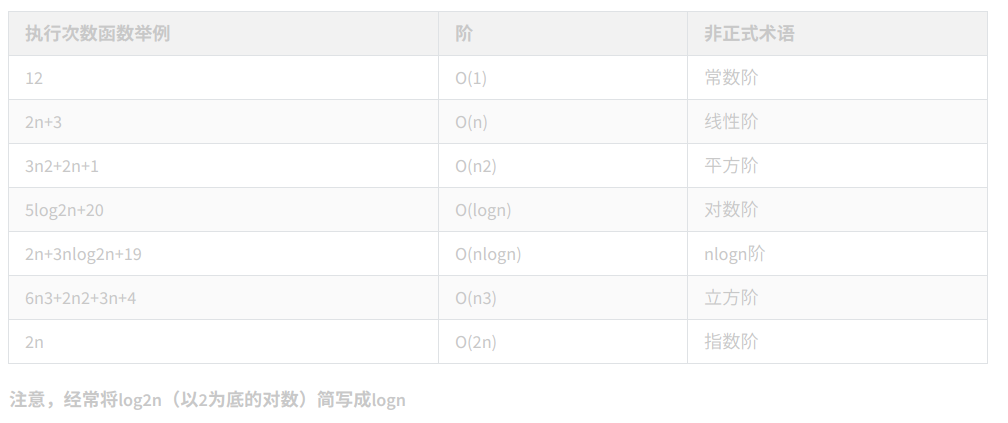
常见的时间复杂度
他们之间的关系如下
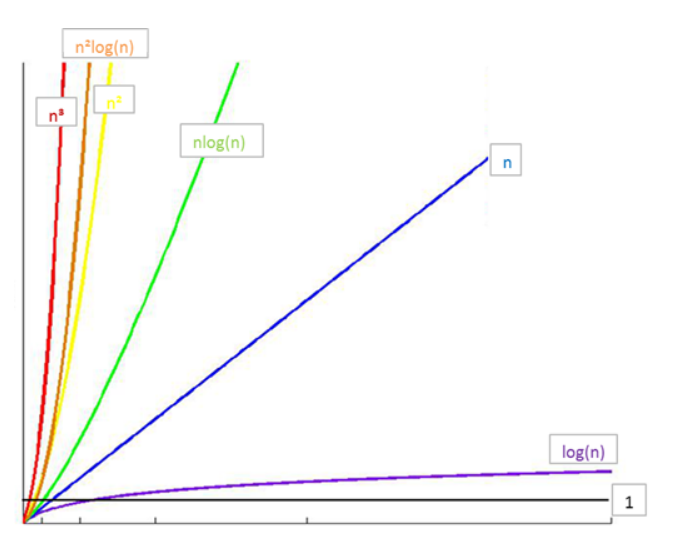
复杂度之间的关系
所以消耗时间的排序也就有了
O(1) < O(logn) < O(n) < O(nlogn) < O(n**2) < O(n**3) < O(2**n) < O(n!) < O(n**n)
python内部timeit模块可以用来测试python代码的执行速度
class timeit.Time(stmt='pass', setup='pass', timer=<timer function>)timer是测量小段代码执行速度的类
stmt参数是要测试的代码语句(statment)
setup参数是运行代码需要的设置
timer参数是一个定时器函数, 与平台有关.
timer.Timer.timeit(number=100000)Timer类中测试语句执行速度的对象方法. number参数是测试代码是的测试次数, 默认为1000000次, 方法返回执行代码的平均耗时, 一个float类型的秒数.
代码如下:
#!/usr/bin/python3# -*- coding=utf8 -*-"""# @Author : pig# @CreatedTime:2020-03-18 14:38:37# @Description : """from timeit import Timerdef tt1(): l = [] for i in range(10000): l = l + []def tt2(): l = [] for i in range(10000): l.append(i)def tt3(): l = [i for i in range(10000)]def tt4(): l = list(range(10000))t1 = Timer("tt1()", "from __main__ import tt1")print ("[]+:", t1.timeit(number=1000))t2 = Timer('tt2()', "from __main__ import tt2")print ("append:", t2.timeit(number=1000))t3 = Timer("tt3()", "from __main__ import tt3")print ("[i for i in range(10000)]:", t3.timeit(number=1000))t4 = Timer("tt4()", "from __main__ import tt4")print ("list(range)", t4.timeit(number=1000))结果如下:
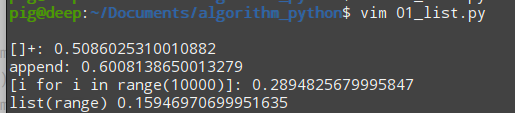
常见列表的性能分析运行结果
对于其他指定位置的插入, 列表的生成方法测试如下:
def tt5(): l = [] for i in range(10000): l.extend([i])def tt6(): l = [] for i in range(10000): l.append(i)def tt7(): l = [] for i in range(10000): l.insert(0, i)def tt8(): l = [] for i in range(10000): l += [i]t5 = Timer("tt5()", "from __main__ import tt5")print ("extend:", t5.timeit(number=1000))t6 = Timer("tt6", "from __main__ import tt6")print ("append()", t6.timeit(number=1000))t7 = Timer("tt7()", "from __main__ import tt7")print ("insert", t7.timeit(number=1000))t8 = Timer("tt8()", "from __main__ import tt8")print ("+= :", t8.timeit(number=1000))总体运行结果:
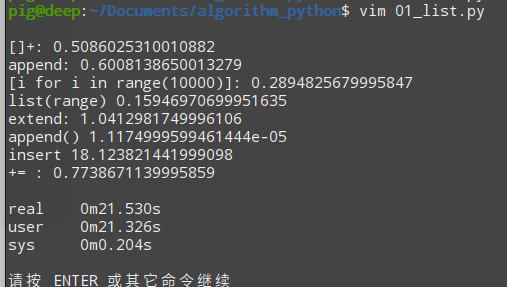
总体运行结果
可以自行测试pop操作, 看看pop操作的效率如何

list时间操作复杂度
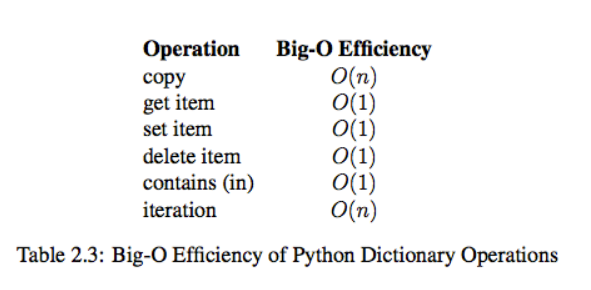
dict内置时间操作复杂度
我们如何使用python中的类型来保存一个班的学生信息? 如果想要快速通过学生姓名获取其信息呢?实际上我们考虑这个问题就需要数据结构了. 列表和字典都可以存储一个班的信息, 但是想要在列表中获取一名同学的信息时, 就要遍历这个列表, 时间复杂度为n, 而使用字典存储时, 可以通过字典的键值查询,其时间复杂度为O(1). 为了解决问题, 需要将数据保存下来, 数据的存储方式不同就需要不同的算法进行处理.效率越高越好. 列表和字典就是python内建帮我们封装好的两种数据结构.
数据是一个抽象的概念,将其进行分类后得到程序设计语言中的基本类型。如:int,float,char等。数据元素之间不是独立的,存在特定的关系,这些关系便是结构。数据结构指数据对象中数据元素之间的关系。
Python给我们提供了很多现成的数据结构类型,这些系统自己定义好的,不需要我们自己去定义的数据结构叫做Python的内置数据结构,比如列表、元组、字典。而有些数据组织方式,Python系统里面没有直接定义,需要我们自己去定义实现这些数据的组织方式,这些数据组织方式称之为Python的扩展数据结构,比如栈,队列等。
数据结构只是静态的描述了数据元素之间的关系. 高效的程序需要在数据结构的基础上设计和选择算法.
程序 = 数据结构 + 算法
算法是为了解决实际问题而设计的, 数据结构是算法需要处理的问题载体
抽象数据类型(ADT)的含义是指一个数学模型以及定义在此数学模型上的一组操作。即把数据类型和数据类型上的运算捆在一起,进行封装。引入抽象数据类型的目的是把数据类型的表示和数据类型上运算的实现与这些数据类型和运算在程序中的引用隔开,使它们相互独立。
常用的数据运算有五种:
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号