阿里云数据库专家白宸揭秘:Redis如何让你体验极致流畅!
发表时间: 2020-03-17 15:35
本文为图灵社区对白宸的采访,访谈时间2017年4月。

访谈嘉宾:
郑明杭(花名白宸),现阿里云NoSQL数据库技术专家。先后从事Tair分布式系统、Memcached云服务及阿里云Redis数据库云服务开发,关注分布式系统及NoSQL存储技术前沿。
· 从事数据库工作的原因
· 阿里云Redis数据库跟其他有商相比的优势
· Redis最得意和最痛的点
· 分布式系统存储技术的前沿——NewSQL
· 数据库实现的方法
......
访谈记录:
数据库是产品应用的基础。直播、共享单车等每个火爆产品的背后都是大量关系型数据库、NoSQL类型数据库在支撑。另外,中小企业为了专注自身业务的发展都会选择云计算,将基础设置的建设交给云服务商。云服务商为了提供高性能、高可用的数据库产品需要投入足够多的研发精力。在数据库研发过程中,数据库研发者既可以深入内核、网络、存储设备进行深度的优化改进,又能够在数据库层面扩展出分布式、异地容灾等不同的产品形态,同时结合不同类型的业务进行不同的深度优化。
选择数据库开发工作主要是为了能够结合计算机理论知识,实践分布式、存储、数据库、内核,反过来在实践开发过程中巩固提高自己。
阿里云的Redis云服务整体架构在ApsaraDB上,具有完善的任务管理、监控运维、高可用体系,能够支撑海量的实例管理及不同的产品需求。阿里云Redis数据库提供了主从双副本、主从单副本、集群双副本等多样的产品供用户选择。
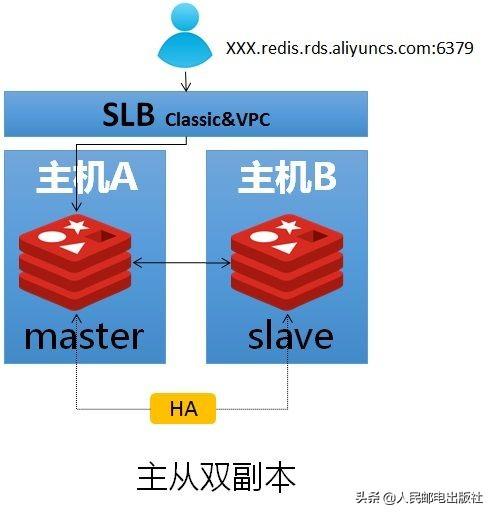
主从双副本版本要求主从双机热备,将数据持久化到磁盘,当主库发生故障的时候快速切换到备库上以保证服务的可用性。相比开源Redis及其他厂商的Redis,阿里云对Redis的故障探测进行了更深度地优化:通过专门的探测端口来避免Redis单线程阻塞的影响,通过对磁盘、CPU、内存等硬件的检测提前发现故障隐患进行主动切换,优化原生的主备复制机制,采用增量日志加内存buffer的方式进行同步,避免弱网情况下主备复制频繁断开及全量同步。
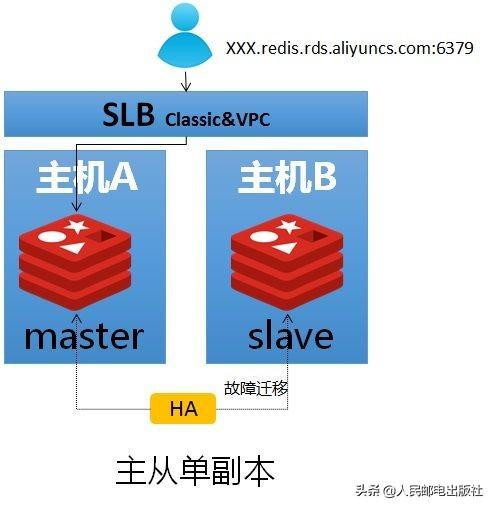
主从单副本是云数据库 Redis 推出的一种全新系列,采用单个数据库节点部署架构。与双副本版本相比,它只包含一个节点,没有备用节点实时同步数据,不提供数据持久化和备份策略,适用于对数据可靠性要求不高的纯缓存业务场景。与其他云厂商相比,阿里云Redis单副本能够保证在主库发生故障的时候快速切换到新节点,但是这个新节点是没有数据的,用户需要在切换完成之后进行数据预热避免数据库的打穿。
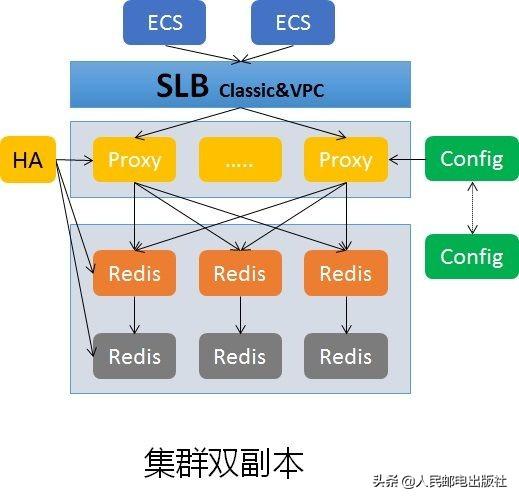
阿里云Redis集群完全采用自研的技术体系,设计的时候充分考虑到用户能够从主从版本平滑迁移过来的需求。Redis集群架构引入了Proxy、Config模块,Proxy负责数据的分发及路由,Config负责数据的迁移及路由表管理。多个无状态的Proxy、Config模块可以保证整个链路的高可用,避免单点问题。与其他云厂商相比,阿里云Redis集群能够保证更高的兼容性,用户可以在主从版本和Redis集群之间进行无缝切换,不需要去更改用户的代码。同时,阿里云Redis集群还支持多db的模式,相比大部分开源的Redis集群方案有较大的优势。
为了更好的服务用户,后续阿里云Redis产品还会推出读写分离、异地容灾、异地多活等产品形态供用户进行选择。最近阿里云Redis又推出了256MB的主从双副本实例,适用于PHP缓存、论坛加速、数据库加速等,随着业务的发展用户还可以进一步扩容。
作为基础服务开发工程师,数据库的稳定性、性能是第一要位的。用户对数据库的高可用及稳定性都有很高要求的,我们在开发过程中需要选用合理的架构,在架构上避免单点问题,避免故障无法恢复问题。对于云服务需要做到足够的隔离,避免不同租户的互相影响,同时在设计云服务过程中需要考虑到可扩展性。公有云服务的每个业务都有自己的特点,会催生出不同的业务需求,所以在初步设计的时候需要保留支持多种业务模式的能力。
阿里内部大量使用了阿里云Redis服务,比如手淘、高德、CDN业务、菜鸟等都大量使用了Redis以实现不同的业务。微淘社区承载了亿级淘宝用户的社交关系链,其中每个用户都有自己的关注列表,每个商家都有自己的粉丝信息。我用下面的图来展示整个微淘社区承载的关系链。
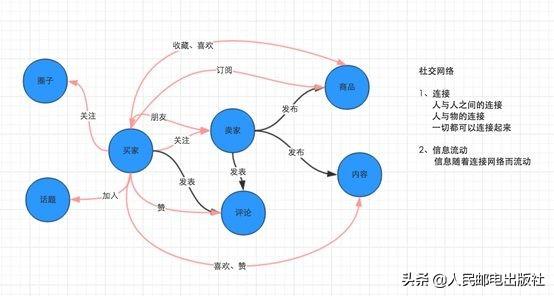
如果选用传统的关系型数据库模型表达上面的关系信息,业务设计会变得异常繁杂,也不能获得良好的性能体验。使用Redis集群,微淘社区缓存了存储社区的关注链,简化了关注信息的存储,并保证了双11业务丝滑一般的体验。微淘社区使用了Hashes存储用户之间的关注信息,存储结构如下图所示。

随着业务规模的壮大,用户需要后端Redis云服务能够做到动态扩容。阿里云Redis集群实例提供了资源变配功能,用户可以在需要的时候进行变配以应对容量的增加。另外,对于淘宝业务来说,每年的双11都是重中之重,我们在双11之前都会跟业务方确认当年的访问量和业务量,同时提前进行双11的全链路压测,保证业务丝滑般的体验。
在使用开源Redis的过程中,我们也碰到了很多问题,比如原生Redis的同步依赖于内存buffer,这会带来一个问题:在弱网情况下,如果内存buffer溢出,原生Redis需要进行一次全量同步。为此阿里云Redis对主备同步进行了优化,通过binlog日志加内存buffer的形式解决掉弱网全量同步的缺陷。另外,在云服务开发运维过程中难免需要对Redis服务进行升级管理,但原生的Redis内核不能很好地支持热升级机制,如果直接重启会对用户的访问产生很大的影响。阿里云Redis通过拆分动态库的形式做到了3ms内对一个实例进行热升级,而且升级过程中对用户的访问不会有任何影响。
简单来说,关系型数据库是指采用关系模型来组织的数据库。传统的关系型数据库由二维表模型来组织,表与表之间具有一定联系,业务可以通过SQL语句对数据库进行更新、查找、删除。非关系型数据库(NoSQL)的最初定义是没有SQL的轻量级数据库,并且不保证遵循ACID原则的数据存储系统。
关系型和非关系型最大的区别在于是否保持事务的一致性,虽然像Redis这样的非关系型数据库也有事务的说法,不过Redis事务是相对简单的事务模型,而传统关系型的数据库是要求读写操作来保证事务一致性的,因为关系型的数据库具有更多的应用场景,并且多用于对数据一致性有强烈要求的系统中。非关系型数据库里的key—value结构具有极高的并发读写性能,所以常常用于高速缓存中,作为传统数据库的缓存提供更高的并发访问。
两种数据库类型是相辅相成的,关系型数据库可以用于对数据一致性有更高要求的场景,同时能够支撑复杂类型的关联查询,而非关系型的数据库可以用于数据库的缓存,或者用于结构简单的业务场景。另外,由于Redis提供了更多复杂类型的数据结构,所以也可以将Redis用于更丰富的业务场景,比如用List结构来实现推送系统、弹幕系统等。

如果要研究数据库的实现可以先从应用层的应用开始,先熟悉数据库的应用场景,也可以先阅读数据库相关的基础知识,了解数据库的SQL解析、持久化机制、数据同步、数据库索引等掌握数据库实现的设计原理。学习过程中,我们可以阅读优秀开源数据库的源码实现,跟踪调试了解整个数据库命令执行的过程;根据数据库命令的每一步执行,在代码跟进过程中思考如何优化和增加新功能。积极融入开源社区的各种活动,定期查看社区的问题。在解决社区用户汇报问题的过程中,对数据库知识做到整体地把握,着重深入某一具体方面的知识。
以NOSQL数据库的学习为例,我们可以通过阅读Redis数据库源码,了解每种数据结构在内存里的组织方式,思考如何更好地存储复杂类型的数据结构。跟Memcached进行比较,分析两种做法的优劣。
为了更好地研究数据库的实现,我们需要多动手,在实际项目中了解数据库的实现,通过开发新功能、优化老功能来巩固知识,同时兼顾数据库理论知识的学习。
在大数据、高并发的情况下,很多业务系统都会采用“缓存+数据库”的方式,对缓存副本和数据库数据做同步处理。同步的方式主要有以下几种。
由于传统单机数据库在可扩展性上面临着巨大的挑战,而NoSQL并不能很好地支持关系型的数据库模型,NewSQL成为了目前分布式数据库存储技术最前沿的一个方向。NewSQL具有海量数据的存储管理并且能够保持传统数据库的ACID及SQL特性。
NewSQL采用了大量的新技术。在存储方面,NewSQL采用以内存为主的存储,将主要的数据缓存于内存中,能够维持内存和持久化存储的数据比例,提高系统的性能;为了支持数据库的可扩展性,NewSQL通过数据分片的模式将数据分布到不同的group中,同时能够支持不同group的数据进行热迁移以达到数据的负载均衡;NewSQL在复制方面需要保证数据的一致性,事务的写入必须在被确认提交之前被确认并安装到所有副本;要做到高可用就需要从崩溃中恢复,相比传统的故障恢复,NewSQL还希望尽量减少故障恢复的时间。
从技术角度来讲,NewSQL与传统数据库并不是完全不同的架构,NewSQL的新特点在于能够融合多方的技术,在一个独立的系统中进行实现,同时随着硬件技术的发展能够提供更可靠更具有扩展性的数据库服务。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号