浅析Golang的垃圾回收机制
发表时间: 2022-06-29 18:00
作者:lajipeng,腾讯TEG未成年人服务产品开发组员工
GC ,全称 Garbage Collection ,即垃圾回收,是一种自动内存管理的机制。 当程序向操作系统申请的内存不再需要时,垃圾回收主动将其回收并供其他代码进行内存申请时候复用,或者将其归还给操作系统,这种针对内存级别资源的自动回收过程,即为垃圾回收。而负责垃圾回收的程序组件,即为垃圾回收器。
也就是说,GC是一个过程,而golang gc是一个垃圾回收器,是一个程序组件,当然,还有很多问题没有得到答案,我就尝试着带着问题,去寻求答案,慢慢的去理解和分析golang gc。
优点: 1、引用计数法可以在对象不活跃时(引用计数为0)立刻回收其内存。因此可以保证堆上时时刻刻都没有垃圾对象的存在(先不考虑循环引用导致无法回收的情况)。 2、引用计数法的最大暂停时间短。由于没有了独立的GC过程,而且不需要遍历整个堆来标记和清除对象,取而代之的是在对象引用计数为0时立即回收对象,这相当于将GC过程“分摊”到了每个对象上,不会有最大暂停时间特别长的情况发生。
劣势:
优点:
缺点:
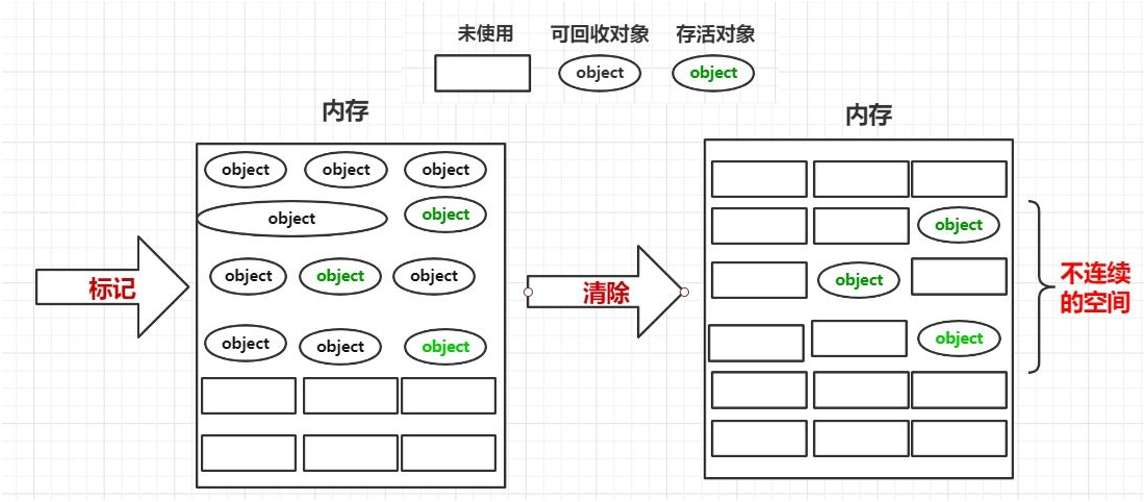
首先,Go 的 GC 目前使用的是无分代(对象没有代际之分)、不整理(回收过程中不对对象进行移动与整理)、并发(与用户代码并发执行)的三色标记清扫算法。可见,go在追踪式的GC模式中,引入了并发和三色标记清扫算法(V1.5),在go的不断调优下,已经是做到了准实时(1ms以内)的gc过程。
我们知道,在追踪式的GC过程中,我们需要进行两步操作,分别是标记和清除,为了避免程序本身运行给GC标记和清除带来不一致性,导致误删,为了保证一致性,golang会停止除了GC模块程序之外的程序运行,这个过程被称为STW。
在这个过程中整个用户代码被停止或者放缓执行, STW 越长,对用户代码造成的影响(例如延迟)就越大,早期 Go 对垃圾回收器的实现中 STW 的停顿时间甚至是达到s级,对时间敏感的实时通信等应用程序会造成巨大的影响。举例:
package mainimport ( "runtime" "time")func main() { go func() { for { } }() time.Sleep(time.Millisecond) runtime.GC() println("OK")}在这行代码中,程序步骤大概如下:
结果:不会有打印结果(v1.14以前)。 v1.14之后可以打印。
原因就在于GC中,会试图去等待其他goroutine所有的用户代码停止,但显然,示例中的代码因为for {}无法停止,导致始终无法进入 STW 阶段,造成程序卡死。
可见,如果实际业务中在,当某个goroutine的代码一直得不到停止,就会导致程序一直停留在STW阶段而无法执行GC,造成程序卡死或其他问题。
既然gc stw的持续时间,直接影响到程序中因为gc所带来的负面影响,那我们需要想办法去缩短stw所持续的时间,所以,go在各个版本中,便对gc的过程做了一定的优化。
go V1.1
在这个过程中,gc过程是串行的,stw的时间 = mark时间+ sweep时间
go V1.3版本的优化就是Mark和Sweep分离. Mark STW, Sweep并发。 也就是大致变成了一下流程:
go V1.5 再次将mark也变成了并发的。
go1.8 整合插入屏障和删除屏障为混合写屏障,将STW的停顿时间真正进入到毫秒级。
go 1.14:替引入了异步抢占,解决了由于密集循环导致的 STW 时间过长的问题。也就是上文示例所示的因为GC等待用户代码停止时间过长的问题。
从上文可知,mark所作的事情,是识别出内存中的垃圾,我们也知道,当一个被声明的对象,我们可以确定已经没有程序需要使用到它的时候,他就可以被判定为垃圾。 而go是基于追踪式方法又引入了三色标记法,实现了垃圾的识别问题。
从垃圾回收器的视角来看,三色标记法是一种抽象,它规定了三种不同类型的对象,并用不同的颜色相称:
回收器(Collector):负责执行垃圾回收的代码。对应的还有赋值器。
赋值器(Mutator):这一名称本质上是在指代用户态的代码。因为对垃圾回收器而言,用户态的代码仅仅只是在修改对象之间的引用关系,也就是在对象图(对象之间引用关系的一个有向图)上进行操作。
根对象在垃圾回收的术语中又叫做根集合,它是垃圾回收器在标记过程时最先检查的对象,包括:
也就是说,三色标记法是从根对象出发,不断地把白色对象(可能死亡)一步步标记为灰色(确认存活,还需要扫描)、黑色对象(存活)的过程。
可以简单理解为(不是真正的go gc的逻辑):
动图示例(图中的颜色不是黑灰白,而是使用蓝黄白相对应):
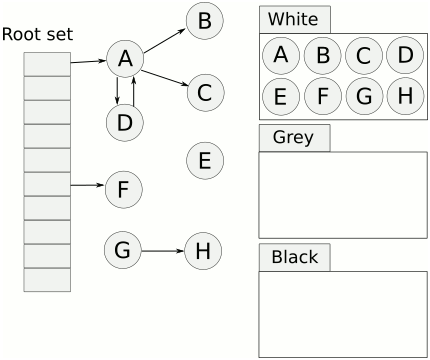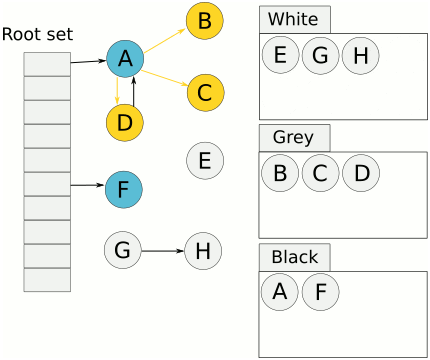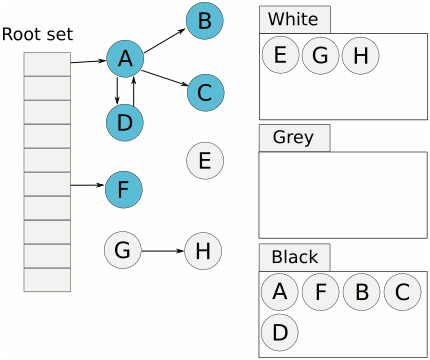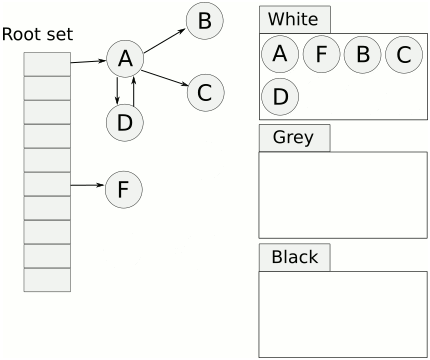
可以看到,以上的mark过程即2-9的过程,同样处于一个stw的过程中,也就是说,Golang GC真正运行的时候,用户程序是不能够运行的。
为什么需要这样呢,因为GC mark的时候,如果不关闭用户程序的操作,那我们就可能出现以下情况导致错误标记和清除:
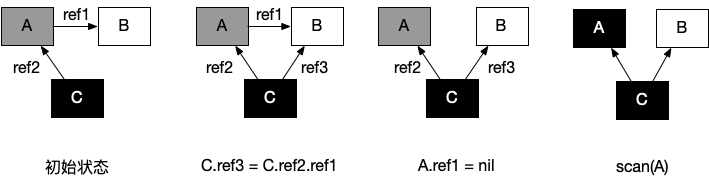
其中C是根节点,在gc开始的准备阶段被标记为灰色
时序 | 回收器 | 赋值器 |
1 | A是C的子节点,A着色为灰色 | |
2 | C的所有子节点遍历完毕,C被着色为黑色 | |
3 | C.ref3 = C.ref2.ref1 C关联B | |
4 | A断开于B的关联 | |
5 | 遍历灰色节点A的所有子节点,因为此时 A.ref1 为 nil ,所以没有子节点 | |
6 | A被着色为黑色 | |
7 | 回收器:由于所有子节点均已标记,回收器也不会重新扫描已经被标记为黑色的对象,此时 A 被着色为黑色, scan(A) 什么也不会发生,进而 B 在此次回收过程中永远不会被标记为黑色,进而错误地被回收。 |
结果:虽然根节点有指向B的关系,但是B被错误的回收了。
为什么会出现这个情况?很明显,根本原因是当回收器在执行标记的时候,赋值器也在不断的更改对象之间的关系。所以在mark标记过程中,我们依旧要STW这个过程。
有办法解决这个问题吗?也就是我在mark标记的过程中,赋值器同样可以执行,也就是用户程序可以运行。
写屏障是一个在并发垃圾回收器中才会出现的概念,垃圾回收器的正确性体现在:不应出现对象的丢失,也不应错误的回收还不需要回收的对象。 大佬们已经证明,当以下两个条件同时满足时会破坏垃圾回收器的正确性:
只要能够避免其中任何一个条件,则不会出现对象丢失的情况,因为:
也就是说,在上面举例中,C黑色节点不能直接指向一个白色节点"B",或者灰色节点A不能删除白色节点"B"的引用,就不会导致错误回收的问题。
很显然,在go想要把mark过程从stw中分离出来,与业务程序并行,就要解决整个问题,写屏障是go团队最开始的方法。
写屏障是针对赋值器改变对象间引用关系改变时的一种同步机制,有两种非常经典的写屏障:Dijkstra 插入屏障和 Yuasa 删除屏障。
插入屏障旨在破坏正确性的条件一,也就是黑色对象建立于白色对象的链接。
// 灰色赋值器 Dijkstra 插入屏障func DijkstraWritePointer(slot *unsafe.Pointer, ptr unsafe.Pointer) {` shade(ptr) *slot = ptr}因为黑色对象不会再被扫描标记,那如果一旦有未扫描的对象被关联到一个黑色对象上,且整个白色对象没有其他关联,就会导致白色对象被标记清除。
所以Dijkstra 插入屏障在建立关系之前,把指针本身着色成灰色,放入待扫描的灰色节点池中,我们知道,mark会扫描标记所有灰色池,所有灰色最终都会变成黑色而不会被清除。
显然,这可以解决并发mark和用户程序赋值器的不一致性问题,但是它的缺点就是可能会导致应该被删除的对象,在mark过程中因为存在赋值操作,而在本次gc过程中未被回收。
网图说明:
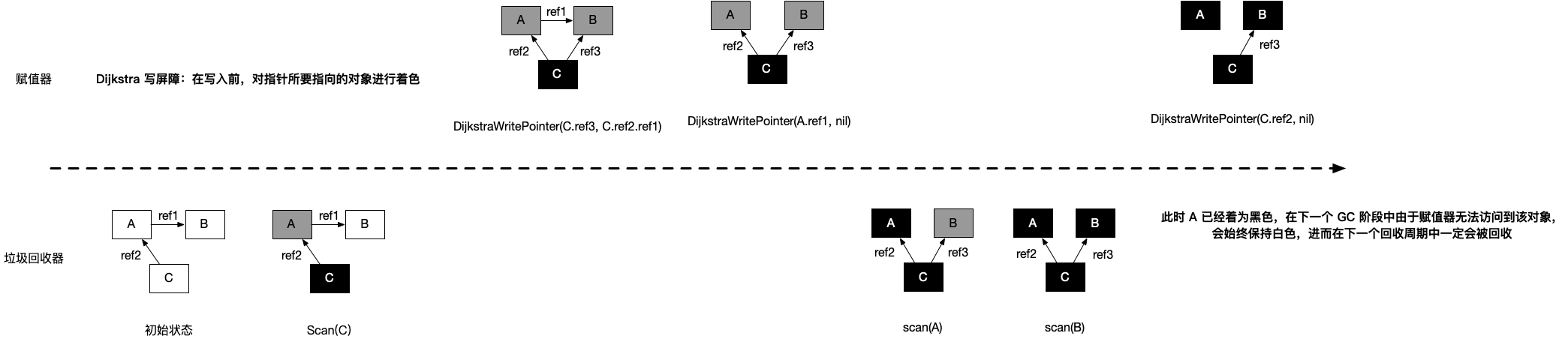
可以看见,在C于B建立关系ref3的时候,A并未扫描到B,但是B已经变成灰色,进而最终被标记成黑色。
插入屏障针对的是条件1,那么删除屏障就是针对的条件2:从灰色对象出发,到达白色对象的、未经访问过的路径被赋值器破坏。。
1. `// 黑色赋值器 Yuasa 屏障` 2. `func YuasaWritePointer(slot *unsafe.Pointer, ptr unsafe.Pointer) {` 3. ` shade(*slot)` 4. ` *slot = ptr` 5. `}`通过代码可以看到,当赋值器需要删除节点的关联时,会将父节点的颜色shade(*slot)着色成灰色,也就是需要重新扫描。
网图说明:
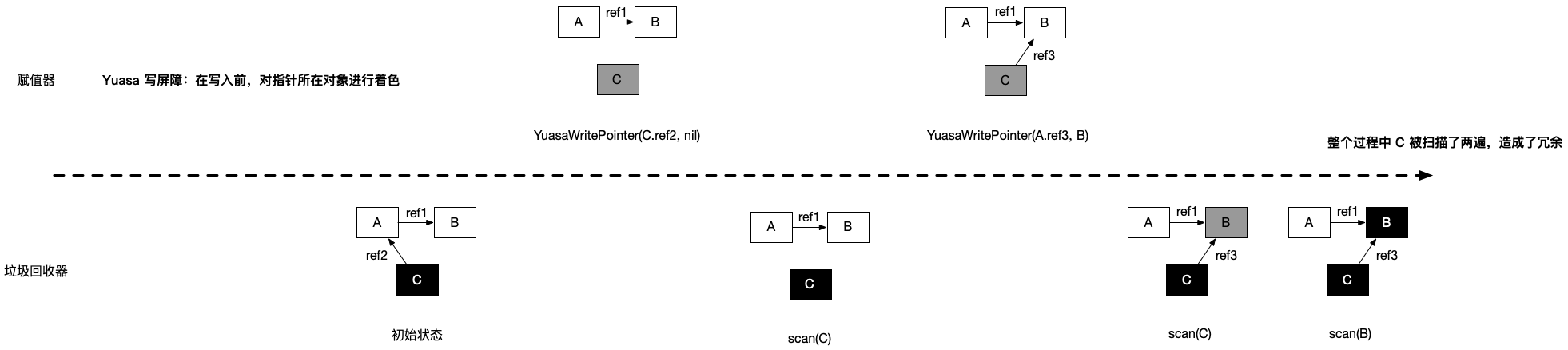
很明显,删除屏障的缺点就是会带来重复扫描的问题,因为一旦存在删除关系的操作,就需要重新扫描。
但是有缺点没关系,相对优秀就可以。在三色标记法+写屏障的保证下,我们就可以让mark的大部分过程从stw中解放出来,并且可以对mark进行并发操作。
这时候,我们理解的gc流程就可以优化成:
也就是说,stw的过程仅包含了2-4这几个步骤,那stw的时间相对的减少很多,并且mark、sweep的并发操作,可以让整个流程都缩短很多。
很显然,golang的开发者们知道自己选择的写屏障的优缺点,所以也在版本的更迭中不断的去优化,使其能做到更好。
如上版本迭代所示,golang团队的人员在V1.5进入mark的并发版本(普通写屏障)之后,V1.8就优化了写屏障变成混合写屏障,于其他的GC优化一起,把Golang GC真正的带入了毫秒级时代。
当然,这只是我们所梳理出来的GC过程,真正的Golang GC流程应该是有出入的,比如mark结束之后应该会有写屏障关闭的阶段,而这个阶段应该也会有一个stw。
当前版本的 Go 以 STW 为界限,可以将 GC 划分为五个阶段(来自:https://www.bookstack.cn/read/qcrao-Go-Questions/GC-GC.md )
阶段 | 说明 | 赋值器状态 |
SweepTermination | 清扫终止阶段,为下一个阶段的并发标记做准备工作,启动写屏障 | STW |
Mark | 扫描标记阶段,与赋值器并发执行,写屏障开启 | 并发 |
MarkTermination | 标记终止阶段,保证一个周期内标记任务完成,停止写屏障 | STW |
GCoff | 内存清扫阶段,将需要回收的内存归还到堆中,写屏障关闭 | 并发 |
第一个阶段 gc开始 (stw)
第二阶段 marking(这个阶段,用户程序跟标记携程是并行的)
第三阶段 处理marking过程中修改的指针 (stw)
第四阶段 sweep 清除白色的对象 到这一阶段,所有内存要么是黑色的要么是白色的,清楚所有白色的即可
首先,我们可以先了解一下GC在那些语言里面有涉及。
有GC模块的语言:
没有GC的语言:
看到这样的集合分类,大致就明白,没有GC的优势:
劣势应该就是需要手动管理内存,开发周期和开发所需要的技术知识储备会要求高一些。
相对的,有GC的优势就是 开发人员可以专心完成业务代码,而不用在内存管理这块花太多心思。同样的,GC所带来的开销肯定会让程序相对没那么快。各有优劣,根据实际情况选择就好。
我倒是没怎么使用过Java,因为学习GC简单了解了一下。
java的GC也是基于追踪式方式的,它本身实现的Java GC完成了分代GC的具体实现。
简单说,分代GC的目的是减少需要频繁扫描的节点数量,希望每一次标注的扫描都是有意义的。
他的背景是:大多数的对象是不会持久活跃的,而真正持久活跃的对象不用每一次都去参与正常的GC。
他的实现:所以使用新生代、老年代进行对象进行区分,然后根据不同的频率对不同类型的对象进行扫描回收。
几乎所有新生成的对象首先都是放在年轻代的。当一个变量在新生代经历一次GC之后,他的年龄+1。
在年轻代中经历了N次垃圾回收后仍然存活的对象,就会被放到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象。
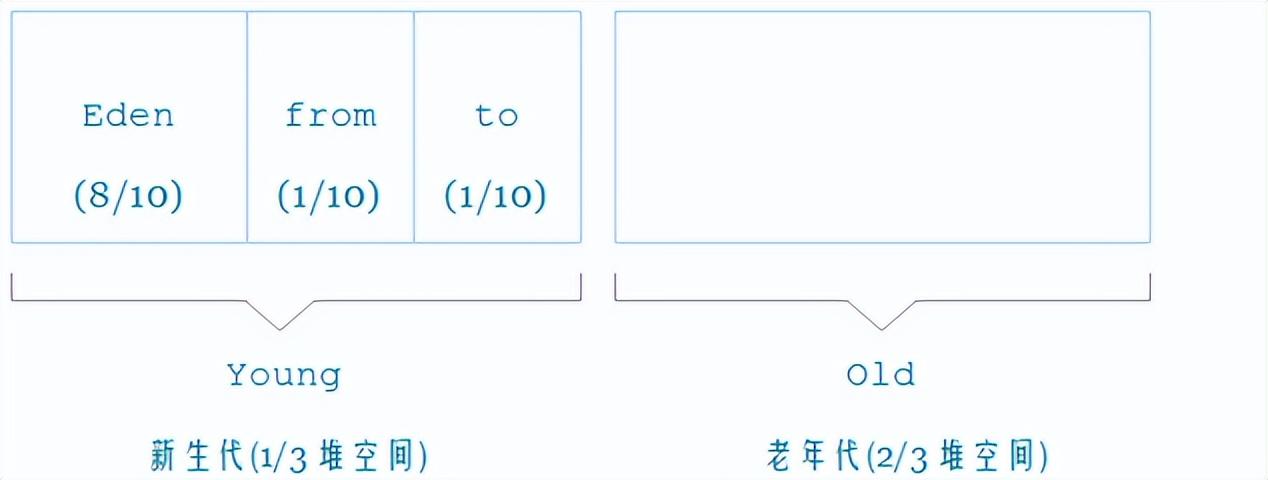
很明显,当对象经过分代后,我们可以用不同的GC,以不同的频率去清理对应代的对象。新生代的就需要频繁一些,而老年代的就可以间隔长一些,不用每次都去扫描,这样可以减少GC过程中需要扫描的对象的额数量。
当然,不管是Java还是Golang的GC,都是需要经过STW这个过程的, 不过经过不断的迭代更新,都已经已达到了用户代码几乎无法感知到的状态。
可以通过各种参数调优,所以Java的GC好像是必须要熟悉的。
Go 的 GC 被设计为极致简洁,与较为成熟的 Java GC 的数十个可控参数相比,严格意义上来讲,Go 可供用户调整的参数只有 GOGC 环境变量,他简单来说就是一个阈值,数值越大,GC执行的频率越低。
当然GC调优的核心还是:
看网上的有人说,go的GC优化或许就会基于当前的GC引入分代GC的内容,因为当前GC虽然效率上去了,但是却是用CPU的开销来撑起来的,所以还有优化的空间。
也有一些人说,分代假设并不适用于 Go 的运行栈机制,年轻代对象在栈上就已经死亡,扫描本就该回收的执行栈并没有为由于分代假设带来明显的性能提升。这也是这一设计最终没有被采用的主要原因。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号