Redis的发展历程:从单机到集群
发表时间: 2023-01-06 11:55
简介: Redis架构演进 1.为什么需要主从 2.为什么需要哨兵 3.有了主从又有了哨兵,为什么有需要分片集群呢
刚接触redis的时候,为了能快速学习和了解这门技术,我们通常会在自己的电脑上部署一个redis服务,以此来开启redis学习之路
随着对redis的进一步深入,很快就会发现这门技术在很多场景下都能得到应用,比如:并发场景下对共享资源的控制(分布式锁)、高并发场景下对系统的保护(限流)、高并发场景下对响应时间的要求(缓存)
在生产环境使用redis服务是否能像当初我们学习时那样,仅仅部署一个单实例redis就可以呢?如果选择单实例部署,当该实例出现故障,使用redis的业务场景都会随之受影响。为了降低单实例故障带来的影响,通常会选择冗余的方式来保证服务的高可靠性,在redis中,我们称之为主-从
redis进行主-从部署后是不是就可以高枕无忧了呢?当然不是,你还需要时时刻刻监控redis主的健康状态,当其出现故障后能第一时间发现并能在从库中完成选主任务,否则同样会给相关业务带来影响。在redis中,我们通常会使用哨兵机制来帮我们完成监控、选主和通知操作,从而使我们的redis服务具备一定的高可靠性
随着业务的飞速发展,redis实例中存放的数据也越来越多,当需要存储25G以上的数据时,估计你会选择一台32G的机器进行部署这个看似简单的选择题却隐藏着很严重的问题:
面对此类问题我们通常会基于大而化小、分而治之的思想进行解决,在redis中我们称之为集群分片技术
开篇对单机、主从、哨兵、分片进行了简单介绍,下文将结合实战展开细说。
磨刀不误砍柴工,在开始之前首先要保证我们的redis服务可以正常启动并能提供指令操作。
wget https://download.redis.io/redis-stable.tar.gztar -zxvf redis-stable.tar.gz➜ redis-stable make & make installredis-serverredis-cli127.0.0.1:6379> set name boboOK127.0.0.1:6379> get name"bobo"完成服务的安装与测试,接下来就可以放手进行实战,实战的第一部分主从
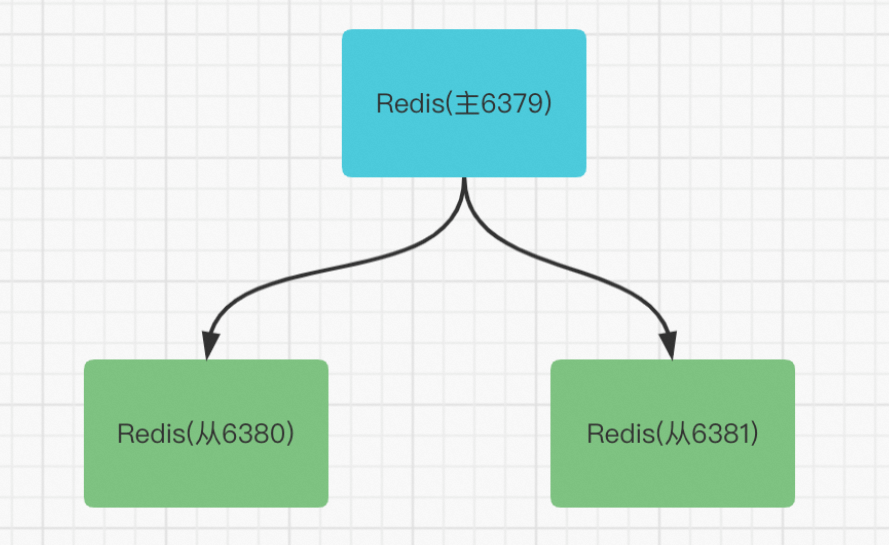
主从一共由3台机器组成,演示环境通过端口号进行区分
主从由3个redis服务组成,每个redis服务对应的配置都不相同,因此需要创建conf文件夹用于存放配置文件
➜ redis-stable mkdir conf默认情况下redis.conf配置文件会有很多注释说明,为了让配置文件看上去清晰明了,使用如下命令来去除配置文件中的注释以及空行
➜ redis-stable cat redis.conf | grep -v "#" | grep -v "^$" > ./conf/redis-6379.conf主从方式,从需要知道应该从哪一个主进行数据复制,因此需要在从再配置文件中添加如下配置
replicaof 127.0.0.1 6380之前也有过说明,演示环境通过端口号进行区分,因此配置文件中除了端口号以及数据保存路径不一样之外,其它的都一样,这里可以通过如下命令进行配置文件拷贝
➜ redis-stable sed 's/6379/6380/g' conf/redis-6379.conf > conf/redis-6380.conf➜ redis-stable sed 's/6379/6381/g' conf/redis-6379.conf > conf/redis-6381.conf万事俱备,只欠东风,准备工作完成之后,只需要逐个启动服务即可
从在启动的时候需要和主建立连接,因此应先启动主6379
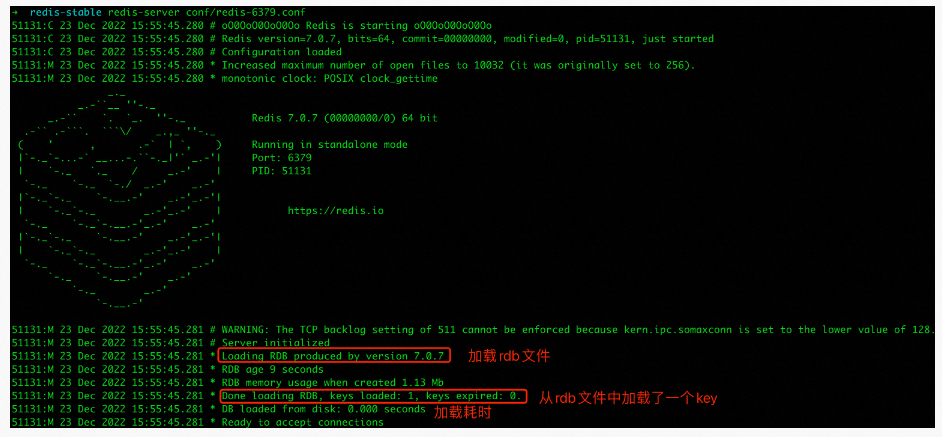
通过日志文件可以了解到主6379在启动的过程中会去加载rdb文件用于数据恢复,并且从rdb文件中加载了一个key
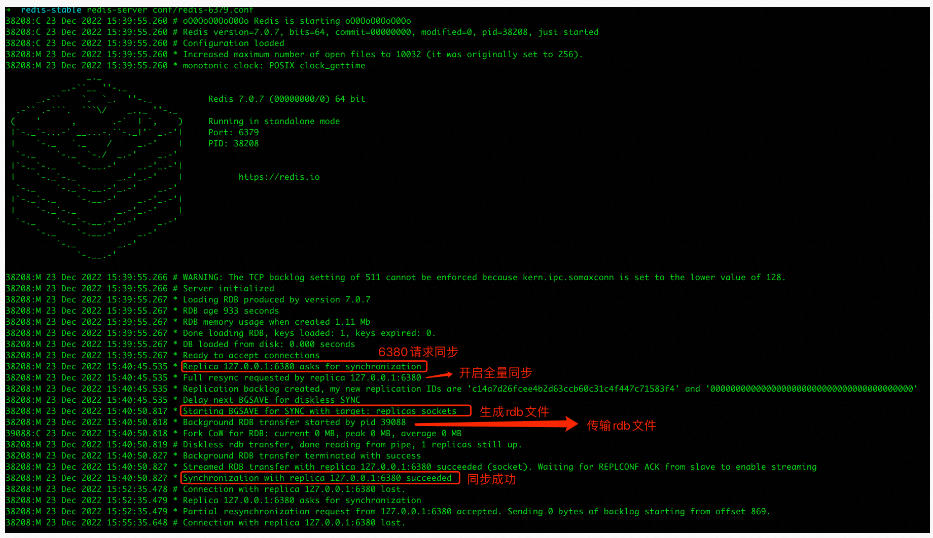
从6380启动后,可以看到主6379的日志内容有所增加
从6380向主6379请求数据同步,由于是第一次会进行全量同步,主6379 fork进程生成rdb文件,然后将生成好的rdb文件传输给6380
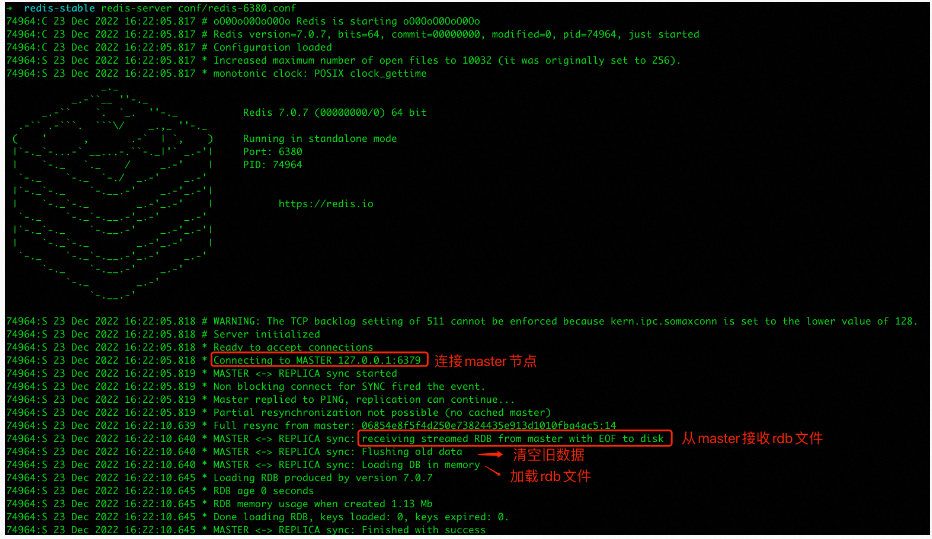
从6380启动过程中会去连接主6379,接收主6379传过来的rdb文件,在清空旧数据之后加载rdb文件进行数据同步
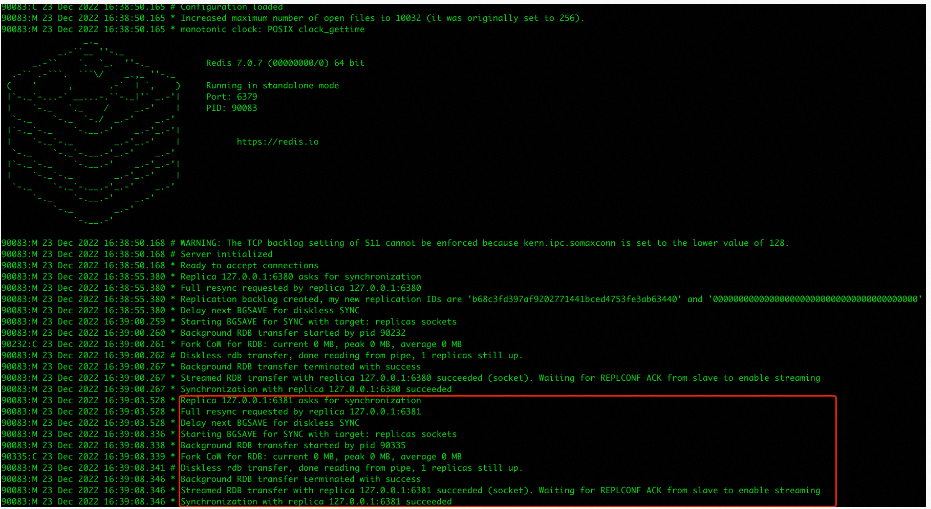
从6381启动和从6380启动是一样的流程,不再进行细说
到这里,你已经知道从在第一次连接主后会进行全量同步,估计也会好奇非第一次连接会如何进行同步。想知道结果,只需要重启其中一个从即可,这里选择重启从6381
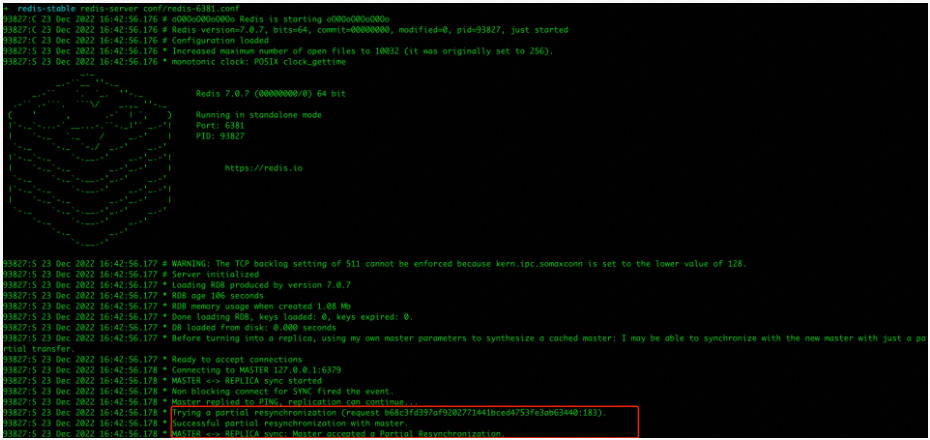
重启后,会发现从6381请求的是增量同步而非全量同步
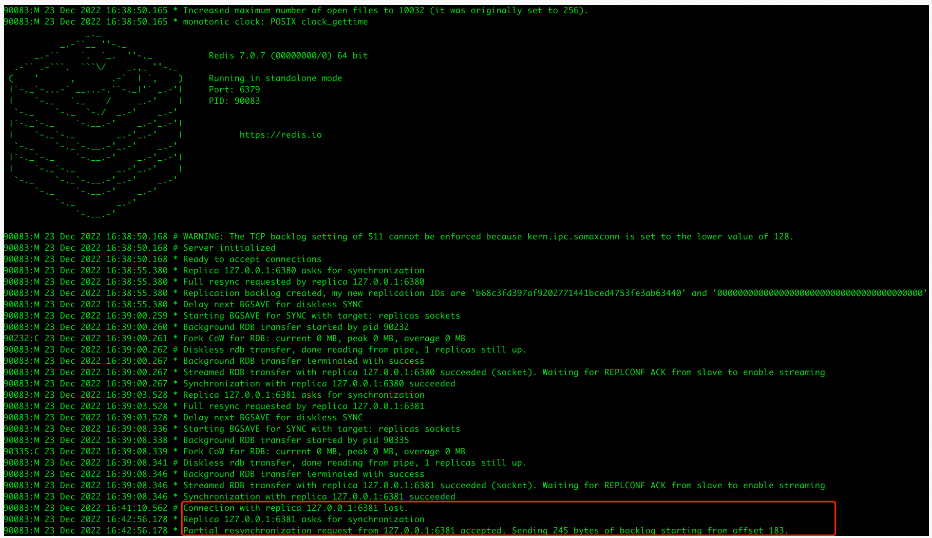
通过主6379的日志可以看到其接受了从6381增量同步的请求,并从backlog偏移量183开始发送了245字节的数据
这里可以猜想一下,主6379若想知道应该增量同步哪些数据给从6381,那么它一定得知道从6381上一次同步到哪里,因此重启再次连接的时候,从6381应该会将上一次同步到哪了的信息发给了主6379
关于数据同步部分,可以得出不知道从哪开始同步就选择全量同步,知道从哪开始同步就选择增量同步的结论
前面提到过,主6379在接到从的全量同步请求后会生成rdb文件,在生成rdb文件的过程中以及将rdb文件传给从并且从使用rdb文件恢复数据的过程中都没有新命令产生,那么主从的数据就可以保持一致。
如果这期间产生了新的命令会不会导致主从数据不一致?
根据官方文档 How Redis replication works中的介绍,我们可以知道期间产生的新命令会被主缓存起来,在从加载完rdb文件数据之后,主会将这期间缓存的命令发送给从,从在接受并执行完这些新命令后,就可以继续保持与主数据的一致性

redis主从固然可以提升服务的高可靠性,却依然需要人为去进行监控、选主和通知。看上去似乎不是很靠谱,因为我们不可能做到7 * 24小时盯着redis服务,在其出问题后手动进行故障转移并通知客户端新主的地址。
redis中我们可以通过哨兵机制来实现监控、选主、通知流程自动化,一来可以减轻开发人员压力;二来可以降低人为误操作率;三来可以提升故障恢复时效性。
接下来会展示如何去搭建哨兵集群以及如何进行选主和通知客户端新主地址
➜ redis-stable cat sentinel.conf | grep -v "#" | grep -v "^$" > ./conf/sentinel-26379.conf➜ redis-stable sed 's/26379/26380/g' conf/sentinel-26379.conf > conf/sentinel-26380.conf➜ redis-stable sed 's/26379/26381/g' conf/sentinel-26379.conf > conf/sentinel-26381.conf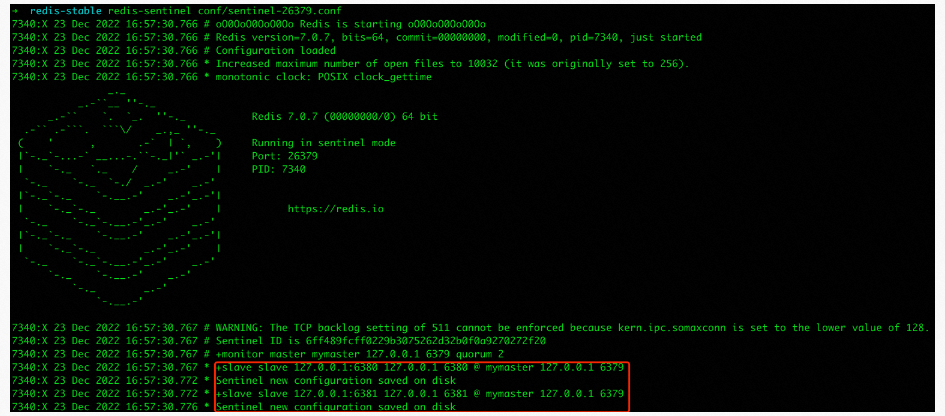
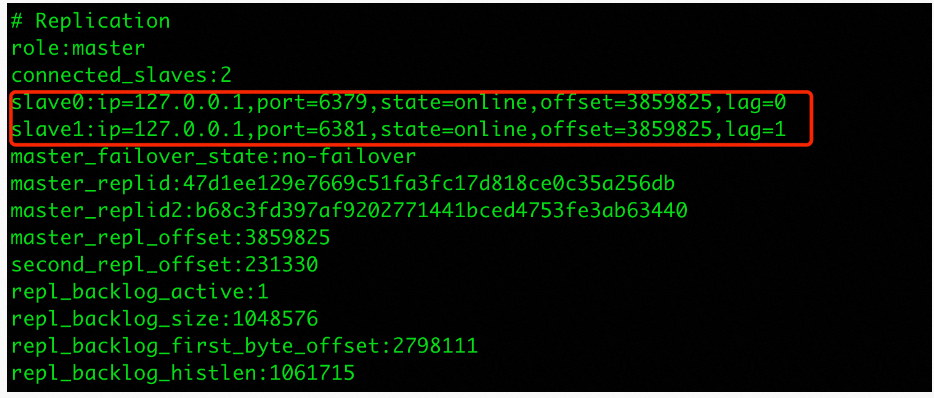
通过日志可以看到sentinel在启动的时候会生成一个唯一id,也就是Sentinel Id,并且还打印出了redis主从中从的相关信息,可是根据sentinel配置文件中的配置sentinel monitor mymaster 127.0.0.1 6379 2,sentine是不知道从的相关信息,那么它是从哪得到这些信息的呢?
要想获得这些信息,sentinel只需要给监控的主发送info命令即可
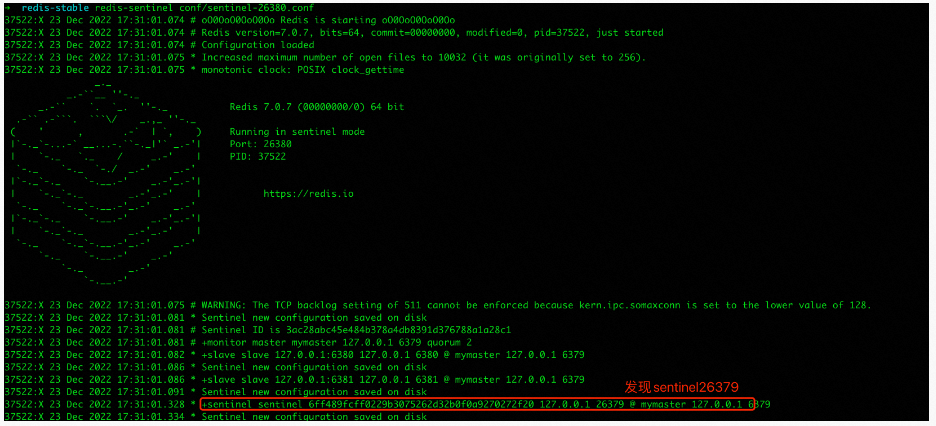
启动sentinel26380的时候通过日志可以看到其发现了sentinel26379的存在
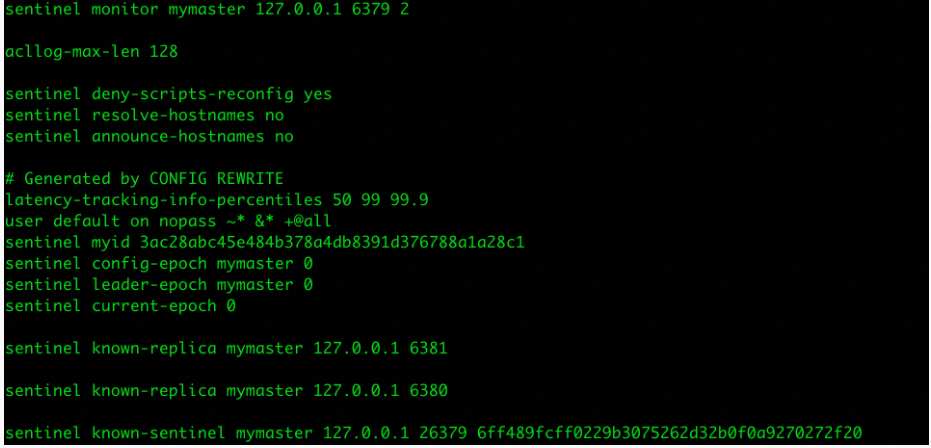
查看配置文件,可以看到配置文件中新增了从和其它sentitnel相关配置
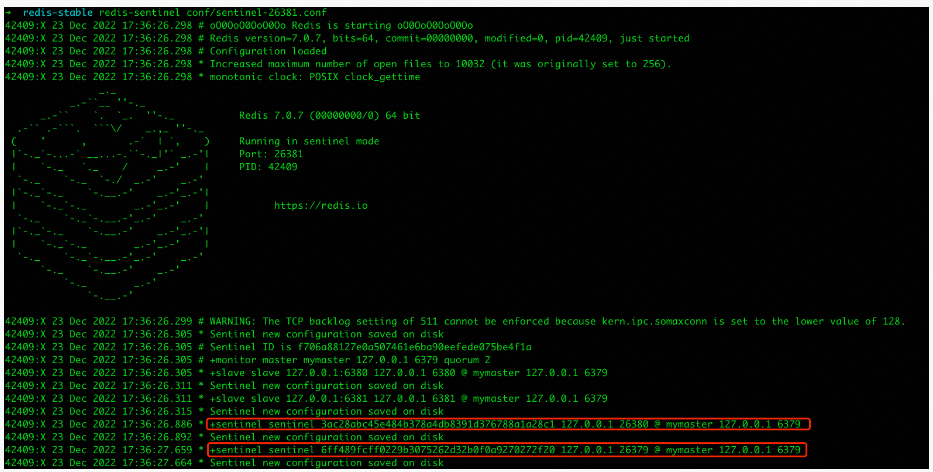
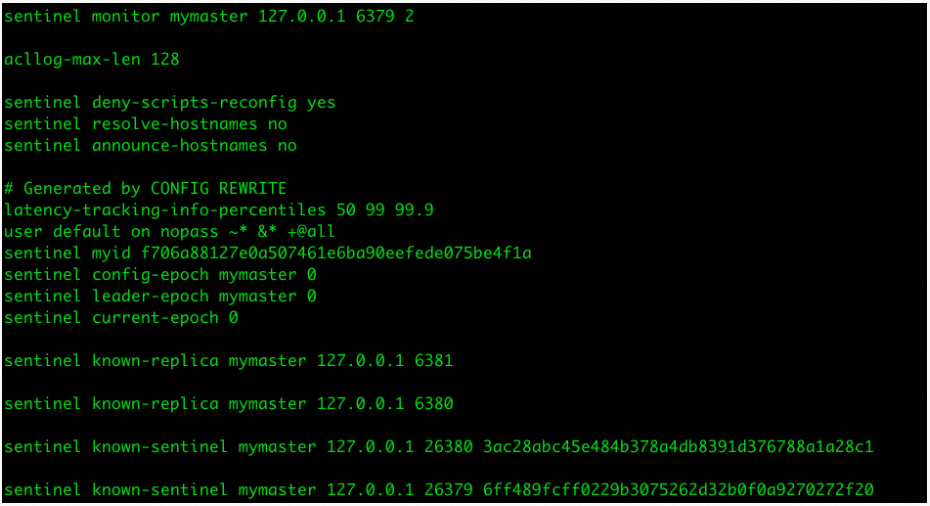
同理sentinel26381启动的时候发现了sentinel26379和sentinel26380的存在并在配置文件中新增了相关配置
在sentinel26381启动完成后,sentinel集群也就搭建完成了,在搭建的过程中也留下了一个疑问:sentinel是如何发现彼此的存在?
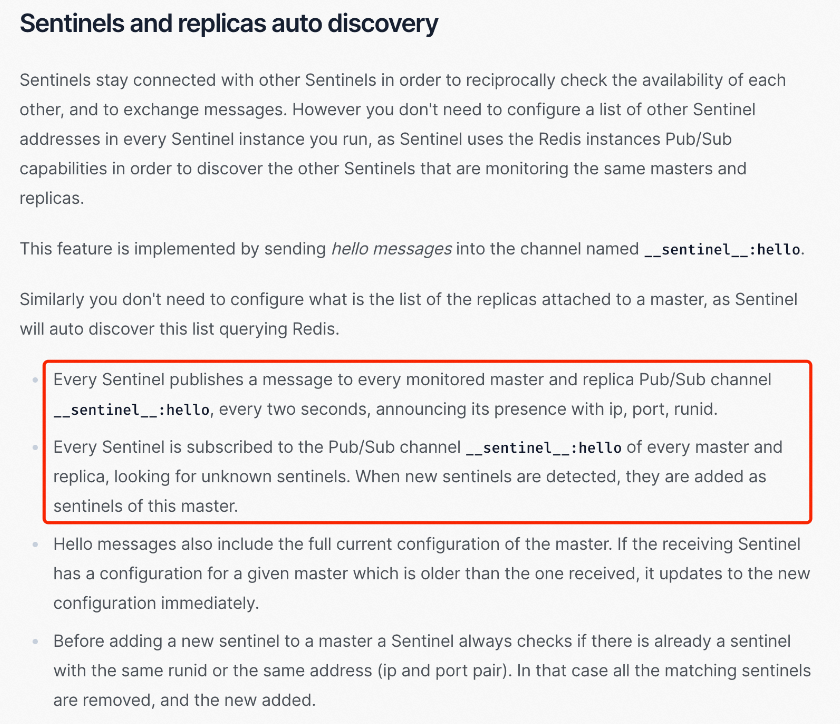
根据官方文档High availability with Redis Sentinel中Sentinels and replicas auto discovery的介绍,可以了解到sentinel是通过Pub/Sub 机制来发现彼此的存在,当一个sentinel与主连接后,可以在__sentinel__:hello通道中发布其对应的ip、port和runid,同时订阅__sentinel__:hello通道,这样其它sentinel发布消息的时候就可以得知对应的ip和port。
sentinel集群搭建完成后,我们需要停掉主来验证其是否完成监控、选主和通知任务。
首先停掉主6379,分别观察3个sentinel的变化
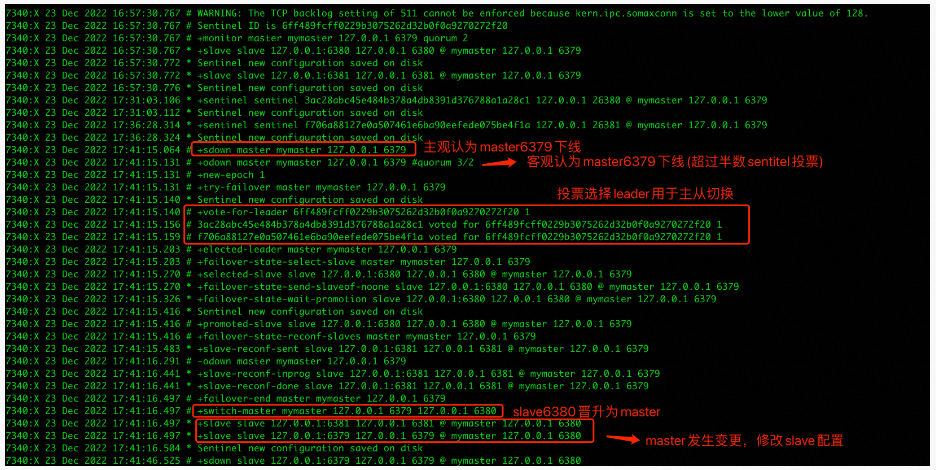
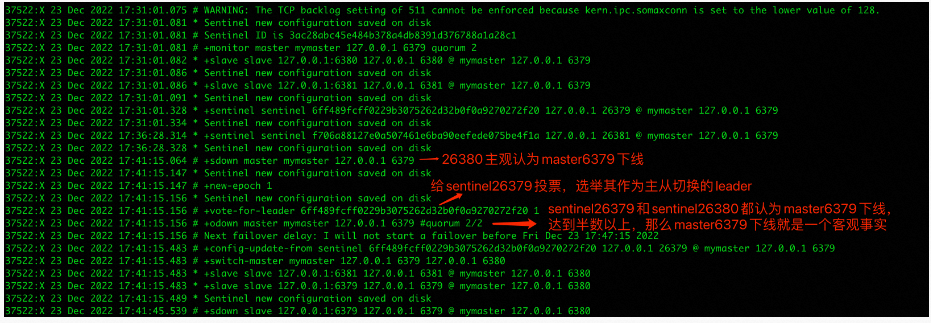
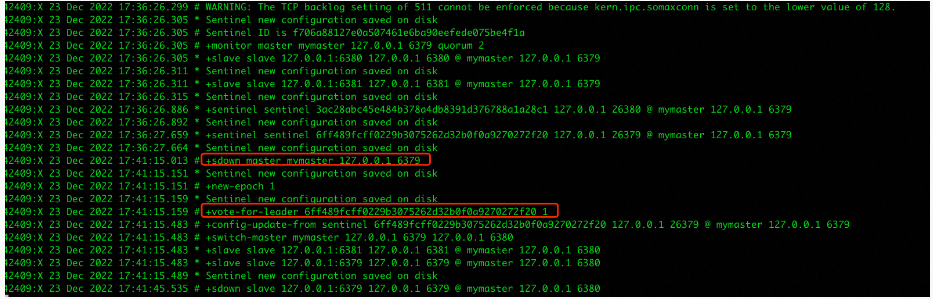
通过观察日志可以看到主6379下线后的一些变化:
点击查看原文,获取更多福利!
https://developer.aliyun.com/article/1126307?utm_content=g_1000366928
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号