深入理解Redis网络:从源码出发的必备知识
发表时间: 2021-12-28 16:07
本篇文章将讲一下redis的网络架构,来揭秘redis接收数据的全过程
再具体研究redis的代码之前,我们得首先得有一个大体的服务器如何接收到客户端数据的全过程。
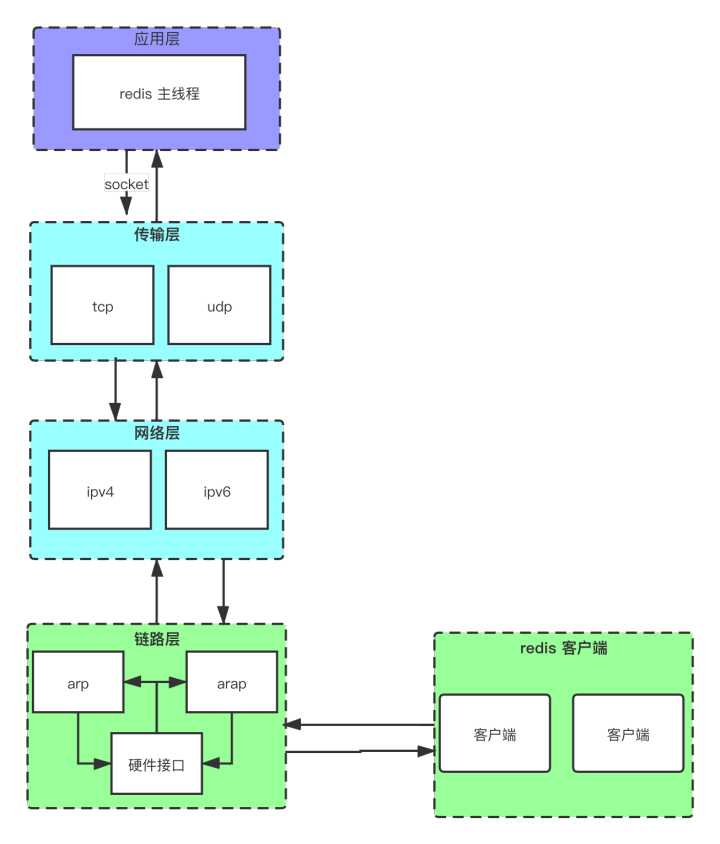
因为redis 主要是用tcp在传输数据,所以是四层网络。
那么具体在应用层,我们又如何通过套接字接收一个客户端的数据了。
请看以下代码分析
server.c
/* Open the TCP listening socket for the user commands. */ //普通tcp的监听启动 if (server.port != 0 && //server.ipfd ip绑定地址 ipfd 数组长度为16,每一项表示一个绑定地址对应的句柄。 //ipfd_count 这里指的是监听地址的个数,具体跟你配置的地址有关系,一般我们配置127.0.0.1 那么他就是只会去和本机的服务进行通信 //ipfd 是一个整型数组,在这个方法里面会被赋值,ipfd[0] 等于文件描述符号,也可以理解为socket的id号 listenToPort(server.port,server.ipfd,&server.ipfd_count) == C_ERR) exit(1); //tls的监听启动 if (server.tls_port != 0 && listenToPort(server.tls_port,server.tlsfd,&server.tlsfd_count) == C_ERR) exit(1); /* Open the listening Unix domain socket. */ //适配unix if (server.unixsocket != NULL) { unlink(server.unixsocket); /* don't care if this fails */ server.sofd = anetUnixServer(server.neterr,server.unixsocket, server.unixsocketperm, server.tcp_backlog); if (server.sofd == ANET_ERR) { serverLog(LL_WARNING, "Opening Unix socket: %s", server.neterr); exit(1); } anetNonBlock(NULL,server.sofd); }我们拿linux系统做为例子
从第一个listenToPort进入后的代码如下:
server.cint listenToPort(int port, int *fds, int *count) { int j; /* Force binding of 0.0.0.0 if no bind address is specified, always * entering the loop if j == 0. */ //强制绑定 0.0.0.0 表示任何ip 可否问 if (server.bindaddr_count == 0) server.bindaddr[0] = NULL; //可以看到绑定的地址是一个集合 for (j = 0; j < server.bindaddr_count || j == 0; j++) { if (server.bindaddr[j] == NULL) { int unsupported = 0; /* Bind * for both IPv6 and IPv4, we enter here only if * server.bindaddr_count == 0. */ //如果绑定的地址为空,则初始化 ipv6 和 ipv4 //第一个是错误网络信息,提供的一个buffer //现实启动绑定ipv6的socket //fds 是一个整型数组, fds[*count] 表示这个地址下的,文件描述符 //server.tcp_backlog 指的是tcp协议里面,三次握手里面,服务端在tcp //握手的第三个阶段完成后,会将这些standby的 //连接放入这个accept queue 里面 //anetTcp6Server和anetTcpServer 会给这个监听的地址和端口分配一个fd fds[*count] = anetTcp6Server(server.neterr,port,NULL, server.tcp_backlog); if (fds[*count] != ANET_ERR) { //设置为非阻塞 //fds[*count] 应该等于设置的 server.tcp_backlog anetNonBlock(NULL,fds[*count]); (*count)++; } else if (errno == EAFNOSUPPORT) { unsupported++; serverLog(LL_WARNING,"Not listening to IPv6: unsupported"); } if (*count == 1 || unsupported) { /* Bind the IPv4 address as well. */ //下面的逻辑相同 fds[*count] = anetTcpServer(server.neterr,port,NULL, server.tcp_backlog); if (fds[*count] != ANET_ERR) { anetNonBlock(NULL,fds[*count]); (*count)++; } else if (errno == EAFNOSUPPORT) { unsupported++; serverLog(LL_WARNING,"Not listening to IPv4: unsupported"); } } /* Exit the loop if we were able to bind * on IPv4 and IPv6, * otherwise fds[*count] will be ANET_ERR and we'll print an * error and return to the caller with an error. */ if (*count + unsupported == 2) break; } //如果是ipv6的地址类型,单独做ipv6地址的监听 else if (strchr(server.bindaddr[j],':')) { /* Bind IPv6 address. */ fds[*count] = anetTcp6Server(server.neterr,port,server.bindaddr[j], server.tcp_backlog); } else { /* Bind IPv4 address. */ // ipv4的地址的绑定 fds[*count] = anetTcpServer(server.neterr,port,server.bindaddr[j], server.tcp_backlog); } if (fds[*count] == ANET_ERR) { //这里是打印日志的地方 serverLog(LL_WARNING, "Could not create server TCP listening socket %s:%d: %s", server.bindaddr[j] ? server.bindaddr[j] : "*", port, server.neterr); if (errno == ENOPROTOOPT || errno == EPROTONOSUPPORT || errno == ESOCKTNOSUPPORT || errno == EPFNOSUPPORT || errno == EAFNOSUPPORT || errno == EADDRNOTAVAIL) continue; return C_ERR; } anetNonBlock(NULL,fds[*count]); (*count)++; } return C_OK;}anet.cstatic int _anetTcpServer(char *err, int port, char *bindaddr, int af, int backlog){ int s = -1, rv; //最高的端口不超过65535 char _port[6]; /* strlen("65535") */ struct addrinfo hints, *servinfo, *p; snprintf(_port,6,"%d",port); memset(&hints,0,sizeof(hints)); //ipv6或者ipv4 两者主要区别在于,地址的位数不同,且格式也不同, //本质的用处都一样 hints.ai_family = af; //流式socket 即tcp 传输协议 hints.ai_socktype = SOCK_STREAM; //获取地址,即当bindaddr为null的时候,返回0.0.0.0 hints.ai_flags = AI_PASSIVE; /* No effect if bindaddr != NULL */ //IPv4中使用gethostbyname()函数完成主机名到地址解析,这个函数仅仅支持IPv4,且不允许调用者指定所需地址类型的任何信息,返回的结构只包含了用于存储IPv4地址的空间。 // IPv6中引入了getaddrinfo()的新API,它是协议无关的,既可用于IPv4也可用于IPv6。 // getaddrinfo函数能够处理名字到地址以及服务到端口这两种转换,返回的是一个addrinfo的结构(列表)指针而不是一个地址清单。 // 这些addrinfo结构随后可由套接口函数直接使用。如此以来,getaddrinfo函数把协议相关性安全隐藏在这个库函数内部。 // 应用程序只要处理由getaddrinfo函数填写的套接口地址结构。该函数在 POSIX规范中定义了。 if ((rv = getaddrinfo(bindaddr,_port,&hints,&servinfo)) != 0) { anetSetError(err, "%s", gai_strerror(rv)); return ANET_ERR; } for (p = servinfo; p != NULL; p = p->ai_next) { //如果socket 初始化不成功则跳过,比如端口被占用 if ((s = socket(p->ai_family,p->ai_socktype,p->ai_protocol)) == -1) continue; //如果ipv6初始化失败 而且仅仅只初始化ipv6 则进入error if (af == AF_INET6 && anetV6Only(err,s) == ANET_ERR) goto error; //设置地址复用,地址复用的意思就是可以允许进程复用端口 if (anetSetReuseAddr(err,s) == ANET_ERR) goto error; //绑定地址,初始化accept queue的长度 if (anetListen(err,s,p->ai_addr,p->ai_addrlen,backlog) == ANET_ERR) s = ANET_ERR; goto end; } if (p == NULL) { anetSetError(err, "unable to bind socket, errno: %d", errno); goto error; }error: if (s != -1) close(s); s = ANET_ERR;end: freeaddrinfo(servinfo); return s;}上面的代码就是一个socket 初始化的过程,
上面的整个过程就是,redis socket初始化的过程,下面要开始说redis socket 的监听环节。
推荐视频:
为什么C/C++程序员一定要阅读redis源码?腾讯面试教你做人
c++后端绕不开的7个开源项目,每一个源码值得深入研究
学习地址:C/C++Linux服务器开发/后台架构师【零声教育】-学习视频教程-腾讯课堂
需要更多C/C++ Linux服务器架构师学习资料加群812855908(资料包括C/C++,Linux,golang技术,内核,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg,大厂面试题 等)
上面的步骤可以让客户端发动信息到,redis绑定的端口上来了,但是连接千千万万,我们又如何采用合适的策略知道那些现在需要被处理的连接了,那就需要配置socket的相关监听了。
server.c //这里开始对我们监听的地址分配handler 事件 //一般情况下ipfd_count=1 for (j = 0; j < server.ipfd_count; j++) { //为这个socket创建一个只读事件 //并且为事件处理准备了一个handler,就是acceptTcpHandler if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE, acceptTcpHandler,NULL) == AE_ERR) { serverPanic( "Unrecoverable error creating server.ipfd file event."); } } int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask, aeFileProc *proc, void *clientData){ //fd 可以看成一个自增数, if (fd >= eventLoop->setsize) { errno = ERANGE; return AE_ERR; } //创建一个file event的引用 aeFileEvent *fe = &eventLoop->events[fd]; //将fd 放入到io监听事件里面去 if (aeApiAddEvent(eventLoop, fd, mask) == -1) return AE_ERR; fe->mask |= mask; //指定读handler和写handler if (mask & AE_READABLE) fe->rfileProc = proc; if (mask & AE_WRITABLE) fe->wfileProc = proc; //给予一个客户端data 的引用 fe->clientData = clientData; if (fd > eventLoop->maxfd) //更新当前最大文件描述符 eventLoop->maxfd = fd; return AE_OK;}/* Include the best multiplexing layer supported by this system. * The following should be ordered by performances, descending. */// 根据不同的系统 选用不同的io实现, 以下实现的性能按照上下排序, 1, ae_evport.c ,2 ae_epoll.c ,3 ae_kqueue.c ,4,ae_select.c// 在linux 系统会优先用到epoll#ifdef HAVE_EVPORT#include "ae_evport.c"#else #ifdef HAVE_EPOLL #include "ae_epoll.c" #else #ifdef HAVE_KQUEUE #include "ae_kqueue.c" #else #include "ae_select.c" #endif #endif#endif这里面的知识点会比较多,比如epoll 的工作机制是如何,select 工作机制又是如何,但是这里重点讲的使用整个过程
可以看到这里我们会把刚刚的socket 相关的文件描述符放入到整个io事件监听体系里面去,在Linux 系统里面会默认用到epoll 这个模型,这里稍微再介绍下ae_epoll.c里面的几个方法
typedef struct aeApiState { int epfd; struct epoll_event *events;} aeApiState;// redis epoll的初始化static int aeApiCreate(aeEventLoop *eventLoop) { // epoll 模型结构分配空间 aeApiState *state = zmalloc(sizeof(aeApiState)); if (!state) return -1; //根据setSize 分配事件空间,一个事件对应一个fd state->events = zmalloc(sizeof(struct epoll_event)*eventLoop->setsize); if (!state->events) { zfree(state); return -1; } //创建一个epoll的模型, 1024 这个️代表的epoll 可能会处理的fd 数目,高核版本这个参数没有什么意义,epoll创建也会得到一个文件描述符,表示打开了一个文件,所以当不用的时候也是需要对其进行关闭。 state->epfd = epoll_create(1024); /* 1024 is just a hint for the kernel */ if (state->epfd == -1) { zfree(state->events); zfree(state); return -1; } eventLoop->apidata = state; return 0;}//将目标fd的读写事件注册到epoll里面,让epoll的线程帮助那些可读可写的fd准备好,而不需要主线程阻塞式的去寻找。static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) { aeApiState *state = eventLoop->apidata; struct epoll_event ee = {0}; /* avoid valgrind warning */ /* If the fd was already monitored for some event, we need a MOD * operation. Otherwise we need an ADD operation. */ //判断当前文件描述符 是否已经被创建 int op = eventLoop->events[fd].mask == AE_NONE ? EPOLL_CTL_ADD : EPOLL_CTL_MOD; ee.events = 0; mask |= eventLoop->events[fd].mask; /* Merge old events */ if (mask & AE_READABLE) ee.events |= EPOLLIN; if (mask & AE_WRITABLE) ee.events |= EPOLLOUT; ee.data.fd = fd; //为这个fd 注册 epollin 或者 epollout 事件,如果之前已经创建过,则增加事件类型,正因为有修改和删除的操作,epoll 内部维护了一棵红黑树使得增加,修改,删除的事件复杂度为logn if (epoll_ctl(state->epfd,op,fd,&ee) == -1) return -1; return 0;}//删除的逻辑,当可读,可写事件都存在的时候,删除操作也可以看作是一种修改。static void aeApiDelEvent(aeEventLoop *eventLoop, int fd, int delmask) { aeApiState *state = eventLoop->apidata; struct epoll_event ee = {0}; /* avoid valgrind warning */ int mask = eventLoop->events[fd].mask & (~delmask); ee.events = 0; if (mask & AE_READABLE) ee.events |= EPOLLIN; if (mask & AE_WRITABLE) ee.events |= EPOLLOUT; ee.data.fd = fd; if (mask != AE_NONE) { //如果只是消除可读可写的事件某一件的时候那就是修改 epoll_ctl(state->epfd,EPOLL_CTL_MOD,fd,&ee); } else { /* Note, Kernel < 2.6.9 requires a non null event pointer even for * EPOLL_CTL_DEL. */ epoll_ctl(state->epfd,EPOLL_CTL_DEL,fd,&ee); }}//通过epoll wait 拉到对应的可被读写的fdstatic int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp) { aeApiState *state = eventLoop->apidata; int retval, numevents = 0; //通过这个方法拉取到可读可写的fd, //第二个参数是拉取个中状态的事件,记住可以拉多种状态一次性 //第三个参数拉取事件最大数,一个fd对应一个事件,一个事件可以为即可读又可写的状态 //第四个参数为超时时间。-1 为一直等待。 retval = epoll_wait(state->epfd,state->events,eventLoop->setsize, tvp ? (tvp->tv_sec*1000 + tvp->tv_usec/1000) : -1); if (retval > 0) { int j; numevents = retval; for (j = 0; j < numevents; j++) { int mask = 0; struct epoll_event *e = state->events+j; //可以看到c语言常用位数来表示状态,这样的话多状态就可以表现出来了。 if (e->events & EPOLLIN) mask |= AE_READABLE; if (e->events & EPOLLOUT) mask |= AE_WRITABLE; if (e->events & EPOLLERR) mask |= AE_WRITABLE|AE_READABLE; if (e->events & EPOLLHUP) mask |= AE_WRITABLE|AE_READABLE; eventLoop->fired[j].fd = e->data.fd; eventLoop->fired[j].mask = mask; } } return numevents;}首先要明白epoll不是具体去与客户端的沟通的媒介, 而是一种对fd的监听架构,它主要运作在系统内核里面,当其监听下的fd的状态发生改变时,根据fd的注册事件类型,返回对应的fd,告诉主程序该fd需要处理。所以总结起来使用epoll 也非常简单,
1.初始化的时候,使用epoll_create
2.注册事件的时候,使用epoll_ctl
3. 拉取有状态改变的fd ,使用epoll_wait
events可以是以下几个宏的集合:
EPOLLIN :表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
EPOLLOUT:表示对应的文件描述符可以写;
EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
EPOLLERR:表示对应的文件描述符发生错误;
EPOLLHUP:表示对应的文件描述符被挂断;
EPOLLET: 将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的。
EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里
为了避免对redis代码理解引入新的问题,我们需要着重关注两个状态,即在redis里用到的EPOLLIN 和 EPOLLOUT。
其实看完上面的代码之后我们一定会有一个疑问,我们只注册了一个(默认情况下只有一个)fd到epoll 里面去,那我们为什么还要使用epoll了,下面继续分析
首先我们回到server.c的代码
void aeMain(aeEventLoop *eventLoop) { eventLoop->stop = 0; //这里进入死循环 while (!eventLoop->stop) { //启动事件 aeProcessEvents(eventLoop, AE_ALL_EVENTS| AE_CALL_BEFORE_SLEEP| AE_CALL_AFTER_SLEEP); }}可以看到上面进入aeMain 这个方法之后,主线程会循环调用处理事件方法。
/* Process every pending time event, then every pending file event * (that may be registered by time event callbacks just processed). * Without special flags the function sleeps until some file event * fires, or when the next time event occurs (if any). * * If flags is 0, the function does nothing and returns. * if flags has AE_ALL_EVENTS set, all the kind of events are processed. * if flags has AE_FILE_EVENTS set, file events are processed. * if flags has AE_TIME_EVENTS set, time events are processed. * if flags has AE_DONT_WAIT set the function returns ASAP until all * the events that's possible to process without to wait are processed. * if flags has AE_CALL_AFTER_SLEEP set, the aftersleep callback is called. * if flags has AE_CALL_BEFORE_SLEEP set, the beforesleep callback is called. * * The function returns the number of events processed. */ // 可以看到redis 是一个事件驱动型的设计模式,会循环调用时间事件 //(如cycle 之前提到的过期键的处理) 然后还有文件事件(其实就是处理客户端的请求), // 每次循环完还有一些回调的策略方法放在我们的beforesleep,aftersleep 里面。 // 下面这段代码,我们首先关注文件型事件。int aeProcessEvents(aeEventLoop *eventLoop, int flags){ int processed = 0, numevents; /* Nothing to do? return ASAP */ if (!(flags & AE_TIME_EVENTS) && !(flags & AE_FILE_EVENTS)) return 0; /* Note that we want call select() even if there are no * file events to process as long as we want to process time * events, in order to sleep until the next time event is ready * to fire. */ if (eventLoop->maxfd != -1 || ((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) { int j; aeTimeEvent *shortest = NULL; struct timeval tv, *tvp; if (flags & AE_TIME_EVENTS && !(flags & AE_DONT_WAIT)) shortest = aeSearchNearestTimer(eventLoop); if (shortest) { long now_sec, now_ms; aeGetTime(&now_sec, &now_ms); tvp = &tv; /* How many milliseconds we need to wait for the next * time event to fire? */ long long ms = (shortest->when_sec - now_sec)*1000 + shortest->when_ms - now_ms; if (ms > 0) { tvp->tv_sec = ms/1000; tvp->tv_usec = (ms % 1000)*1000; } else { tvp->tv_sec = 0; tvp->tv_usec = 0; } } else { /* If we have to check for events but need to return * ASAP because of AE_DONT_WAIT we need to set the timeout * to zero */ if (flags & AE_DONT_WAIT) { tv.tv_sec = tv.tv_usec = 0; tvp = &tv; } else { /* Otherwise we can block */ tvp = NULL; /* wait forever */ } } if (eventLoop->flags & AE_DONT_WAIT) { tv.tv_sec = tv.tv_usec = 0; tvp = &tv; } if (eventLoop->beforesleep != NULL && flags & AE_CALL_BEFORE_SLEEP) eventLoop->beforesleep(eventLoop); /* Call the multiplexing API, will return only on timeout or when * some event fires. */ // 获取事件个数 numevents = aeApiPoll(eventLoop, tvp); /* After sleep callback. */ if (eventLoop->aftersleep != NULL && flags & AE_CALL_AFTER_SLEEP) eventLoop->aftersleep(eventLoop); //这里是开始处理网络请求的地方。 for (j = 0; j < numevents; j++) { aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd]; int mask = eventLoop->fired[j].mask; int fd = eventLoop->fired[j].fd; int fired = 0; /* Number of events fired for current fd. */ /* Normally we execute the readable event first, and the writable * event laster. This is useful as sometimes we may be able * to serve the reply of a query immediately after processing the * query. * * However if AE_BARRIER is set in the mask, our application is * asking us to do the reverse: never fire the writable event * after the readable. In such a case, we invert the calls. * This is useful when, for instance, we want to do things * in the beforeSleep() hook, like fsynching a file to disk, * before replying to a client. */ // 这个fe 是代表这个事件的总状态,首先要保证读事件,要before 于写事件,这样的好处在于我们能够将处理好的命令回滚, // 而不至于一些同步问题导致数据无法回滚,给予客户端错误的状态,比如我们 fsyching 数据到硬盘,我们想成功之后才将数据返回给客户端 int invert = fe->mask & AE_BARRIER; /* Note the "fe->mask & mask & ..." code: maybe an already * processed event removed an element that fired and we still * didn't processed, so we check if the event is still valid. * * Fire the readable event if the call sequence is not * inverted. */ if (!invert && fe->mask & mask & AE_READABLE) { //在这里调用我们的readder handler fe->rfileProc(eventLoop,fd,fe->clientData,mask); fired++; fe = &eventLoop->events[fd]; /* Refresh in case of resize. */ } /* Fire the writable event. */ if (fe->mask & mask & AE_WRITABLE) { if (!fired || fe->wfileProc != fe->rfileProc) { fe->wfileProc(eventLoop,fd,fe->clientData,mask); fired++; } } /* If we have to invert the call, fire the readable event now * after the writable one. */ if (invert) { fe = &eventLoop->events[fd]; /* Refresh in case of resize. */ if ((fe->mask & mask & AE_READABLE) && (!fired || fe->wfileProc != fe->rfileProc)) { fe->rfileProc(eventLoop,fd,fe->clientData,mask); fired++; } } processed++; } } /* Check time events */ if (flags & AE_TIME_EVENTS) processed += processTimeEvents(eventLoop); return processed; /* return the number of processed file/time events */}从上面代码可以看到如何处理file event的过程
1.我们先调用到aeApiPoll,获取需要被处理的event个数,
2.我们传入的eventloop 里面放入了需要被处理的事件。
3.遍历eventloop里面的每一项。
4.对于可读事件调用read handler 来处理。
5.对于可写事件调用write handler 来处理。
上面还有一些回滚的处理流程,这个再后续功能模块再继续讨论。
// 这个是服务端fd注册的读事件响应,它的作用主要用于接收到新的客户端连接,然后将它注册到epoll里面去,后面接收客户端数据的handler 就不在这边处理了。void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) { int cport, cfd, max = MAX_ACCEPTS_PER_CALL; char cip[NET_IP_STR_LEN]; UNUSED(el); UNUSED(mask); UNUSED(privdata); while(max--) { //跟客户端建立通道,为客户端分配一个fd. cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport); if (cfd == ANET_ERR) { if (errno != EWOULDBLOCK) serverLog(LL_WARNING, "Accepting client connection: %s", server.neterr); return; } serverLog(LL_VERBOSE,"Accepted %s:%d", cip, cport); //connCreateAcceptedSocket 主要用于初始化客户端的连接 //acceptCommonHandler 这个方法适用于接收数据的地方 acceptCommonHandler(connCreateAcceptedSocket(cfd),0,cip); }}//初始化一个连接,connection *connCreateAcceptedSocket(int fd) { connection *conn = connCreateSocket(); conn->fd = fd; conn->state = CONN_STATE_ACCEPTING; return conn;}//初始化连接connection *connCreateSocket() { //分配空间 connection *conn = zcalloc(sizeof(connection)); //CT_Socket 是一个结构体 conn->type = &CT_Socket; conn->fd = -1; return conn;}connection *connCreateSocket() { connection *conn = zcalloc(sizeof(connection)); conn->type = &CT_Socket; conn->fd = -1; return conn;}//可以看到新的socket 里面分配了各种handlerConnectionType CT_Socket = { .ae_handler = connSocketEventHandler, .close = connSocketClose, .write = connSocketWrite, .read = connSocketRead, .accept = connSocketAccept, .connect = connSocketConnect, .set_write_handler = connSocketSetWriteHandler, .set_read_handler = connSocketSetReadHandler, .get_last_error = connSocketGetLastError, .blocking_connect = connSocketBlockingConnect, .sync_write = connSocketSyncWrite, .sync_read = connSocketSyncRead, .sync_readline = connSocketSyncReadLine, .get_type = connSocketGetType};static void acceptCommonHandler(connection *conn, int flags, char *ip) {...... //为客户端连接分配一个接收数据的结构体 // 并将新的连接放入epoll 里面 if ((c = createClient(conn)) == NULL) { serverLog(LL_WARNING, "Error registering fd event for the new client: %s (conn: %s)", connGetLastError(conn), connGetInfo(conn, conninfo, sizeof(conninfo))); connClose(conn); /* May be already closed, just ignore errors */ return; }...... client *createClient(connection *conn) { client *c = zmalloc(sizeof(client)); /* passing NULL as conn it is possible to create a non connected client. * This is useful since all the commands needs to be executed * in the context of a client. When commands are executed in other * contexts (for instance a Lua script) we need a non connected client. */ if (conn) { connNonBlock(conn); connEnableTcpNoDelay(conn); if (server.tcpkeepalive) connKeepAlive(conn,server.tcpkeepalive); //设置readhandler ,readQueryFromClient // 就是我们上篇我们讲的io多线程读的地方了 connSetReadHandler(conn, readQueryFromClient); connSetPrivateData(conn, c); } ...... static inline int connSetReadHandler(connection *conn, ConnectionCallbackFunc func) { //这个地方将会调用到connSocketSetReadHandler, //func 就是上面的readQueryFromClient return conn->type->set_read_handler(conn, func);} //设置新的reader handlerstatic int connSocketSetReadHandler(connection *conn, ConnectionCallbackFunc func) { // if (func == conn->read_handler) return C_OK; //将readhandler 覆盖成readQueryFromClient conn->read_handler = func; if (!conn->read_handler) aeDeleteFileEvent(server.el,conn->fd,AE_READABLE); else //将新的fd放入到epoll里面 //新的fd有可读事件的时候回调函数是connSocketEventHandler if (aeCreateFileEvent(server.el,conn->fd, AE_READABLE,conn->type->ae_handler,conn) == AE_ERR) return C_ERR; return C_OK;} ...... //这个地方是接收数据处理 if (connAccept(conn, clientAcceptHandler) == C_ERR) { char conninfo[100]; if (connGetState(conn) == CONN_STATE_ERROR) serverLog(LL_WARNING, "Error accepting a client connection: %s (conn: %s)", connGetLastError(conn), connGetInfo(conn, conninfo, sizeof(conninfo))); freeClient(connGetPrivateData(conn)); return; } }....//这里会调用到CT_Socket 里面的connSocketAccept方法static inline int connAccept(connection *conn, ConnectionCallbackFunc accept_handler) { return conn->type->accept(conn, accept_handler);}static int connSocketAccept(connection *conn, ConnectionCallbackFunc accept_handler) { int ret = C_OK; //判断状态 if (conn->state != CONN_STATE_ACCEPTING) return C_ERR; conn->state = CONN_STATE_CONNECTED; connIncrRefs(conn); //这里又会调用到clientAcceptHandler // 而clientAcceptHandler 看作者注释主要对于一些安全模式的验证, // 在这个环节暂时不研究 if (!callHandler(conn, accept_handler)) ret = C_ERR; connDecrRefs(conn); return ret;}以上代码总结下来主线主要就是看了以下几件事
1,当有新连接过来的时候,分配一个fd给这个客户端。
2,将这个新的fd加入到epoll体系里面,即上面的handler 只负责新的连接初始化的工作。
3,一些安全验证,还有redis额外模块加载(丰富其拓展性)等事情。
初始化新的连接后又可以回到下一轮的epoll_wait,这个时候就能从刚刚连接里面把数据给读上来了。
/** * 可以看到下面的流程就是标准的读写流程,这边暂时来研究读的这部分 * @param el * @param fd * @param clientData * @param mask */static void connSocketEventHandler(struct aeEventLoop *el, int fd, void *clientData, int mask){ UNUSED(el); UNUSED(fd);....... int call_write = (mask & AE_WRITABLE) && conn->write_handler; int call_read = (mask & AE_READABLE) && conn->read_handler; /* Handle normal I/O flows */ if (!invert && call_read) { //这里就会调用到readQueryFromClient if (!callHandler(conn, conn->read_handler)) return; } /* Fire the writable event. */ if (call_write) { if (!callHandler(conn, conn->write_handler)) return; } /* If we have to invert the call, fire the readable event now * after the writable one. */ if (invert && call_read) { if (!callHandler(conn, conn->read_handler)) return; }.......}当新的fd有可读事件的时候,会从这里把数据读到client buffer
这篇文章讲述了从redis如何通过网络监听的方式到建立连接到读取数据的整个流程。能够学习到的知识点就是redis如何去使用网络初始化,如何去监听端口,又如何使用io多路复用的方式,全篇干货比较多,需要细心阅读,本篇文章最好能够对着代码,延着作者思路对照着读,文中也给出了比较详细的注释,希望能为你读源码的时候提供帮助
可以看到上面的文章里面其实还有一些判断和其它分支,并没有给出详细的解释,因为作者并不是redis的源码编写者,编写者本身对其有很多细节思考,但是我们不必对每个细节都去展开深入,这样会妨碍对于主线的探索,可以通过读懂其主线代码,然后再返回过去看其分支细节,这样就会有茅塞顿开的感觉。
声明:本站内容部分源于网络转载,出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。文章内容仅供参考,请咨询相关专业人士。
如果无意之中侵犯了您的版权,或有意见、反馈或投诉等情况, 请联系本站,[qq:]
Copyright ©2025 编程密语 All rights reserved 版权所有 鲁ICP备09004228号-12
 鲁公网安备37020202000738号
鲁公网安备37020202000738号